Transcribe (whisper) and translate (gpt) voice into LRC file.

Project description
Open-Lyrics




Open-Lyrics is a Python library that transcribes audio with
faster-whisper, then translates/polishes the text
into .lrc subtitles with LLMs such as
OpenAI and Anthropic.
Key Features
- Audio preprocessing to reduce hallucinations (loudness normalization and optional noise suppression).
- Context-aware translation to improve translation quality. Check prompt for details.
- Check here for an overview of the architecture.
New 🚨
- 2024.5.7:
- Added custom endpoint (
base_url) support for OpenAI and Anthropic:lrcer = LRCer( translation=TranslationConfig( base_url_config={'openai': 'https://api.chatanywhere.tech', 'anthropic': 'https://example/api'} ) )
- Added bilingual subtitle generation:
lrcer.run('./data/test.mp3', target_lang='zh-cn', bilingual_sub=True)
- Added custom endpoint (
- 2024.5.11: Added glossary support in prompts to improve domain-specific translation. Check here for details.
- 2024.5.17: You can route models to arbitrary chatbot SDKs (OpenAI or Anthropic) by setting
chatbot_modeltoprovider: model_nametogether withbase_url_config:lrcer = LRCer( translation=TranslationConfig( chatbot_model='openai: claude-3-haiku-20240307', base_url_config={'openai': 'https://api.g4f.icu/v1/'} ) )
- 2024.6.25: Added Gemini as a translation model (for example,
gemini-1.5-flash):lrcer = LRCer(translation=TranslationConfig(chatbot_model='gemini-1.5-flash'))
- 2024.9.10: Now openlrc depends on
a specific commit of
faster-whisper, which is not published on PyPI. Install it from source:
pip install "faster-whisper @ https://github.com/SYSTRAN/faster-whisper/archive/8327d8cc647266ed66f6cd878cf97eccface7351.tar.gz"
- 2024.12.19: Added
ModelConfigfor model routing. It is more flexible than plain model-name strings.TranslationConfigremains serialization-friendly and string-based; useModelConfigin lower-level programmatic APIs when you need richer routing metadata.ModelConfigcan beModelConfig(provider='<provider>', name='<model-name>', base_url='<url>', proxy='<proxy>'), e.g.:from openlrc import ModelConfig, ModelProvider from openlrc.agents import create_chatbot from openlrc.translate import LLMTranslator chatbot_model1 = ModelConfig( provider=ModelProvider.OPENAI, name='deepseek-chat', base_url='https://api.deepseek.com/beta', api_key='sk-APIKEY' ) chatbot_model2 = ModelConfig( provider=ModelProvider.OPENAI, name='gpt-4o-mini', api_key='sk-APIKEY' ) chatbot = create_chatbot(chatbot_model1) retry_chatbot = create_chatbot(chatbot_model2) translator = LLMTranslator(chatbot=chatbot, retry_chatbot=retry_chatbot)
Installation ⚙️
-
Install CUDA and cuDNN according to https://opennmt.net/CTranslate2/installation.html to enable
faster-whisper.faster-whisperalso needs cuBLAS installed.For Windows Users (click to expand)
(Windows only) You can download the libraries from Purfview's repository:
Purfview's whisper-standalone-win provides the required NVIDIA libraries for Windows in a single archive. Decompress the archive and place the libraries in a directory included in the
PATH. -
Add LLM API keys (recommended for most users:
OPENROUTER_API_KEY):- Add your OpenAI API key to environment variable
OPENAI_API_KEY. - Add your Anthropic API key to environment variable
ANTHROPIC_API_KEY. - Add your Google API Key to environment variable
GOOGLE_API_KEY. - Add your OpenRouter API key to environment variable
OPENROUTER_API_KEY.
- Add your OpenAI API key to environment variable
-
Install ffmpeg and add
bindirectory to yourPATH. -
Install from PyPI:
pip install openlrc
or install directly from GitHub:
pip install git+https://github.com/zh-plus/openlrc
-
(Optional) If you need noise suppression (
noise_suppress=True), install the full extras which includes torch and DeepFilterNet:pip install 'openlrc[full]'
Lightweight Imports
OpenLRC keeps several package-root APIs lightweight to import.
The following imports are guaranteed not to eagerly load heavyweight runtime dependencies such as
torch, spacy, faster-whisper, tiktoken, or lingua:
import openlrc
from openlrc import LRCer
from openlrc import TranscriptionConfig, TranslationConfig
from openlrc import ModelConfig, ModelProvider, list_chatbot_models
This is useful when you only need configuration objects, model metadata, or the LRCer type itself
without immediately starting transcription or language-processing work.
Heavy dependencies are loaded only when the corresponding features are first used. For example:
faster-whisperis loaded when transcription is first needed.torchanddf.enhanceare loaded when noise suppression is used.spacyis loaded when sentence segmentation or related NLP helpers are used.tiktokenis loaded when token counting is used.linguais loaded when language detection helpers are used.
[!NOTE] The base
pip install openlrcdoes not include torch or DeepFilterNet. These are only installed withpip install 'openlrc[full]'and are only needed for noise suppression (noise_suppress=True).
Usage 🐍
Python code
from openlrc import LRCer, TranscriptionConfig, TranslationConfig
if __name__ == '__main__':
lrcer = LRCer()
# Single file
lrcer.run('./data/test.mp3',
target_lang='zh-cn') # Generate translated ./data/test.lrc with default translate prompt.
# Multiple files
lrcer.run(['./data/test1.mp3', './data/test2.mp3'], target_lang='zh-cn')
# Note we run the transcription sequentially, but run the translation concurrently for each file.
# Path can contain video
lrcer.run(['./data/test_audio.mp3', './data/test_video.mp4'], target_lang='zh-cn')
# Generate translated ./data/test_audio.lrc and ./data/test_video.srt
# Use glossary to improve translation
lrcer = LRCer(translation=TranslationConfig(glossary='./data/aoe4-glossary.yaml'))
# To skip translation process
lrcer.run('./data/test.mp3', target_lang='en', skip_trans=True)
# Change asr_options or vad_options (see openlrc.defaults for details)
vad_options = {"threshold": 0.1}
lrcer = LRCer(transcription=TranscriptionConfig(vad_options=vad_options))
lrcer.run('./data/test.mp3', target_lang='zh-cn')
# Enhance the audio using noise suppression (requires openlrc[full], consumes more time).
lrcer.run('./data/test.mp3', target_lang='zh-cn', noise_suppress=True)
# Change the translation model
lrcer = LRCer(translation=TranslationConfig(chatbot_model='claude-3-sonnet-20240229'))
lrcer.run('./data/test.mp3', target_lang='zh-cn')
# Clear temp folder after processing done
lrcer.run('./data/test.mp3', target_lang='zh-cn', clear_temp=True)
# Use a custom OpenAI-compatible endpoint
lrcer = LRCer(
translation=TranslationConfig(
chatbot_model='gpt-4.1-nano',
base_url_config={'openai': 'https://example.com/v1'}
)
)
# Bilingual subtitle
lrcer.run('./data/test.mp3', target_lang='zh-cn', bilingual_sub=True)
LRCer supports the context manager protocol, which automatically closes
the underlying LLM connections when the block exits:
with LRCer() as lrcer:
lrcer.run(['./data/file1.mp3', './data/file2.mp3'], target_lang='zh-cn')
# Connections are closed automatically here.
This is recommended when processing multiple files, as the LLM connection
pool is shared across all files within the same LRCer instance.
Check more details in Documentation.
Glossary
Add glossary to improve domain specific translation. For example aoe4-glossary.json:
{
"aoe4": "帝国时代4",
"feudal": "封建时代",
"2TC": "双TC",
"English": "英格兰文明",
"scout": "侦察兵"
}
lrcer = LRCer(translation=TranslationConfig(glossary='./data/aoe4-glossary.json'))
lrcer.run('./data/test.mp3', target_lang='zh-cn')
To keep TranslationConfig serialization-friendly, save in-memory glossary data to
a JSON file and pass the file path via TranslationConfig(glossary=...).
Pricing 💰
pricing data from OpenAI and Anthropic
| Model Name | Pricing for 1M Tokens (Input/Output) (USD) |
Cost for 1 Hour Audio (USD) |
|---|---|---|
gpt-3.5-turbo |
0.5, 1.5 | 0.01 |
gpt-4o-mini |
0.5, 1.5 | 0.01 |
gpt-4-0125-preview |
10, 30 | 0.5 |
gpt-4-turbo-preview |
10, 30 | 0.5 |
gpt-4o |
5, 15 | 0.25 |
claude-3-haiku-20240307 |
0.25, 1.25 | 0.015 |
claude-3-sonnet-20240229 |
3, 15 | 0.2 |
claude-3-opus-20240229 |
15, 75 | 1 |
claude-3-5-sonnet-20240620 |
3, 15 | 0.2 |
gemini-1.5-flash |
0.175, 2.1 | 0.01 |
gemini-1.0-pro |
0.5, 1.5 | 0.01 |
gemini-1.5-pro |
1.75, 21 | 0.1 |
deepseek-chat |
0.18, 2.2 | 0.01 |
Note the cost is estimated based on the token count of the input and output text. The actual cost may vary due to the language and audio speed.
Recommended translation model
For English audio, we recommend deepseek-chat, gpt-4o-mini, or gemini-1.5-flash.
For non-English audio, we recommend claude-3-5-sonnet-20240620.
How it works
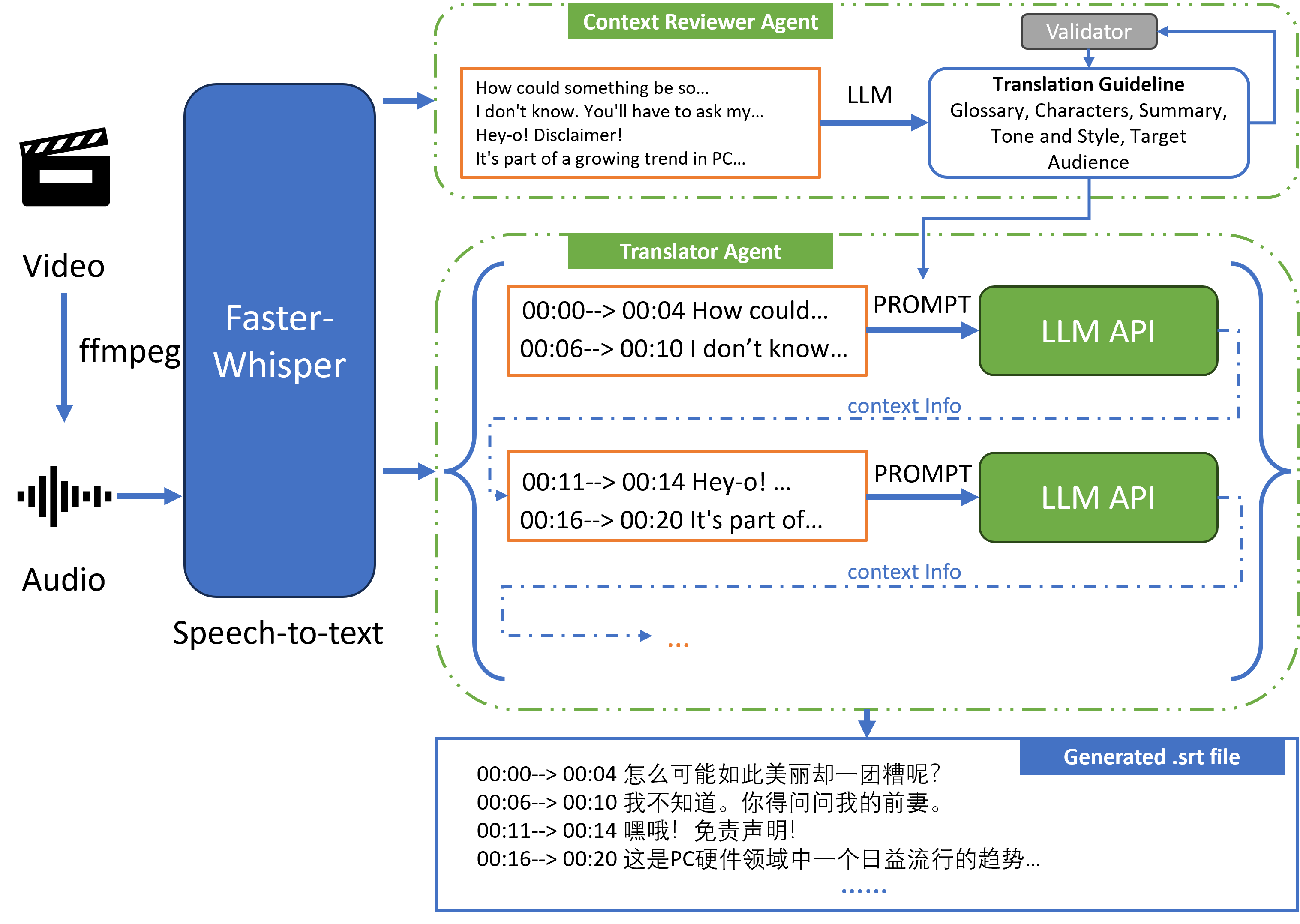
To maintain context between translation segments, the process is sequential for each audio file.
Development Guide
This project uses uv for package management.
Install uv with the standalone installer:
On macOS and Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
On Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
Install dependencies
uv venv
uv sync
Code quality checks
Before committing, please make sure the following checks pass locally:
# Lint
uv run ruff check openlrc/ tests/
# Format
uv run ruff format --check openlrc/ tests/
# To auto-fix formatting:
# uv run ruff format openlrc/ tests/
# Type check
uv run pyright openlrc/
For live translation testing as a developer (and for CI usage), set:
export OPENROUTER_API_KEY="your-openrouter-api-key"
Build and publish a release
Use uv end-to-end for release builds and publishing:
# Build source and wheel distributions
uv build
# Validate the generated metadata before uploading
uvx twine check dist/*
# Publish to PyPI
# Preferred for local publishing:
uv publish
#
# Or publish with an explicit token:
# uv publish --token <pypi-token>
If you prefer GitHub Actions publishing, configure PyPI trusted publishing for this repository and push a version tag such as v1.6.3.
Todo
- [Efficiency] Batched translate/polish for GPT request (enable contextual ability).
- [Efficiency] Concurrent support for GPT request.
- [Translation Quality] Make translate prompt more robust according to https://github.com/openai/openai-cookbook.
- [Feature] Automatically fix json encoder error using GPT.
- [Efficiency] Asynchronously perform transcription and translation for multiple audio inputs.
- [Quality] Improve batched translation/polish prompt according to gpt-subtrans.
- [Feature] Input video support.
- [Feature] Multiple output format support.
- [Quality] Speech enhancement for input audio.
- [Feature] Preprocessor: Voice-music separation.
- [Feature] Align ground-truth transcription with audio.
- [Quality] Use multilingual language model to assess translation quality.
- [Efficiency] Add Azure OpenAI Service support.
- [Quality] Use claude for translation.
- [Feature] Add local LLM support.
- [Feature] Multiple translate engine (Anthropic, Microsoft, DeepL, Google, etc.) support.
- [Feature] Build a electron + fastapi GUI for cross-platform application.
- [Feature] Web-based streamlit GUI.
- Add fine-tuned whisper-large-v2 models for common languages.
- [Feature] Add custom OpenAI & Anthropic endpoint support.
- [Feature] Add local translation model support (e.g. SakuraLLM).
- [Quality] Construct translation quality benchmark test for each patch.
- [Quality] Split subtitles using LLM (ref).
- [Quality] Trim extra long subtitle using LLM (ref).
- [Others] Add transcribed examples.
- Song
- Podcast
- Audiobook
Credits
- https://github.com/guillaumekln/faster-whisper
- https://github.com/m-bain/whisperX
- https://github.com/openai/openai-python
- https://github.com/openai/whisper
- https://github.com/machinewrapped/gpt-subtrans
- https://github.com/MicrosoftTranslator/Text-Translation-API-V3-Python
- https://github.com/streamlit/streamlit
Star History

Citation
@book{openlrc2024zh,
title = {zh-plus/openlrc},
url = {https://github.com/zh-plus/openlrc},
author = {Hao, Zheng},
date = {2024-09-10},
year = {2024},
month = {9},
day = {10},
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file openlrc-1.6.3.tar.gz.
File metadata
- Download URL: openlrc-1.6.3.tar.gz
- Upload date:
- Size: 66.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9fd88e3e2201cbfb7cc8b1448c58cc7f6450d4c62eb8cca94f36980f437b3358
|
|
| MD5 |
9de0bdc92eaee3c95ae740458573e69b
|
|
| BLAKE2b-256 |
ad73eff3db46ace45fd324028790d8e7be294863d9000fdd668fa01667fee09d
|
File details
Details for the file openlrc-1.6.3-py3-none-any.whl.
File metadata
- Download URL: openlrc-1.6.3-py3-none-any.whl
- Upload date:
- Size: 72.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
76d6d80dd0e337c4b12e6e1ab325892d8a22697f3fd700d00a054eb03664b404
|
|
| MD5 |
06dfc53cb6f63126931f6e35db28016d
|
|
| BLAKE2b-256 |
7486e4e4338ab03bf4ba7a1cbe5a2ec005b9221463e88150ab4747e26877c478
|







