All-in-one pandoc filter for highly flexible numbering and cross referencing of everything in LaTeX.

Project description
pandoc-tex-numbering
This is an all-in-one pandoc filter for converting your LaTeX files to any format while keeping numbering, hyperlinks, caption formats and (clever) cross references in (maybe multi-line) equations, sections, figures, tables, theorems and appendices. The formating is highly customizable, easy-to-use, and even more flexible than the LaTeX default.
Contents
- pandoc-tex-numbering
- Contents
- What do we support?
- Installation
- Quick Start
- Customization
- Details
- Examples
- Development
- FAQ
- TODO
What do we support?
- Multi-line Equations: Multi-line equations in LaTeX math block such as
align,casescan be numbered line by line.\nonumbercommands are supported to turn off the numbering of a specific line. cleverefPackage:crefandCrefcommands are supported. You can customize the prefix of the references.- Subfigures:
subcaptionpackage is supported. Subfigures can be numbered with customized symbols and formats. - Theorems: Theorems are supported with customized formats.
- Appendices: Appendices are supported with customized formats.
- Non-Arabic Numbers: Various non-arabic numbers are supported, such as Latin letters, Chinese, Roman, Greek, Cyrillic, etc.
- Custom List of Figures and Tables: Short captions as well as custom lof/lot titles are supported for figures and tables.
- Custom Formatting of Everything: You can customize the format of the numbering and references with python f-string format based on various fields we provide.
Installation
First, install pandoc and python3 if you haven't. Then you can install the filter via one of the following methods:
From PyPI (Recommended)
In Python>=3.8 pandoc-tex-numbering can be installed via pip:
pip install pandoc-tex-numbering
From Source
Only in case you want to use the filter with a lower version of Python (under 3.8), you can download the source code (i.e. all files under src/pandoc_tex_numbering) manually and put it in the same directory as your source file. In this case, when using the filter, you should specify the filter file via -F pandoc-tex-numbering.py instead of -F pandoc-tex-numbering.
Quick Start
Take .docx as an example:
pandoc -F pandoc-tex-numbering -o output.docx input.tex
Customization
You can set the following variables in the metadata of your LaTeX file to customize the behavior of the filter:
General
number-figures: Whether to number the figures. Default istrue.number-tables: Whether to number the tables. Default istrue.number-equations: Whether to number the equations. Default istrue.number-sections: Whether to number the sections. Default istrue.number-theorems: Whether to number the theorems. Default istrue. You MUST set the metadatatheorem-namesto the names of the theorems you defined in the LaTeX source code to make it work.number-reset-level: The level of the section that will reset the numbering. Default is 1. For example, if the value is 2, the numbering will be reset at every second-level section and shown as "1.1.1", "3.2.1" etc.section-max-levels: The maximum level of the section numbering. Default is 10.data-export-path: Where to export the filter data. Default isNone, which means no data will be exported. If set, the data will be exported to the specified path in the JSON format. This is useful for further usage of the filter data in other scripts or filter-debugging.auto-labelling: Whether to automatically add identifiers (labels) to figures and tables without labels. Default istrue. This has no effect on the output appearance but can be useful for cross-referencing in the future (for example, in the.docxoutput this will ensure that all your figures and tables have a unique auto-generated bookmark).
Numbering System
{item_type}-numstyle: The style of the numbering of figures, tables, equations, sections, theorems, subfigures. For examplefigure-numstylerepresents the style of the numbering of figures.{item_type}-numstyle-{i}: The style of the i-th level of the numbering of sections or appendices. For example,section-numstyle-1represents the style of the first level of the numbering of sections.
Possible values are:
arabic: Arabic numbers (1, 2, 3, ...)roman: Lowercase Roman numbers (i, ii, iii, ...)Roman: Uppercase Roman numbers (I, II, III, ...)latin: Lowercase Latin numbers (a, b, c, ...)Latin: Uppercase Latin numbers (A, B, C, ...)greek: Lowercase Greek numbers (α, β, γ, ...)Greek: Uppercase Greek numbers (Α, Β, Γ, ...)cyrillic: Lowercase Cyrillic numbers (а, б, в, ...)Cyrillic: Uppercase Cyrillic numbers (А, Б, В, ...)zh: Chinese numbers (一, 二, 三, ...)
Default values of most of the items are arabic. Exceptions are:
- Default value of
subfigure-numstyleislatin. - Default value of
appendix-numstyle-1isLatin.
Numbering Offset
You can add an offset to any type of numbering so that the numbering starts from a specific number instead of 1.
{item_type}-offset: The offset of the numbering of figures, tables, equations, subfigures. For examplefigure-offsetrepresents the offset of the numbering of figures.{item-type}-offset-{i}: The offset of the i-th level of the numbering of sections or appendices. For example,section-offset-1represents the offset of the first level of the numbering of sections.theorem-{theorem_name}-offset: The offset of the theorem numbering. Default is0. For example, if you have\newtheorem{thm}{Theorem}, when you set the metadatatheorem-thm-offsetto1, the first theorem will be numbered as "Theorem 2" instead of "Theorem 1".
Formatting System
We support a very flexible formatting system for the numbering and references. There are two different formatting systems for the numbering and references. You can use them together. The two systems are:
- Prefix-based System: This is lightweight and easy to use. When referenced, a corresponding prefix will automatically added to the number.
- Custom Formatting System: This is more flexible and powerful. You can customize the format of the numbering and references with python f-string format based on various fields we provide.
Prefix-based System
The following metadata are used for the prefix-based system:
figure-prefix: The prefix of the figure reference. Default is "Figure".table-prefix: The prefix of the table reference. Default is "Table".equation-prefix: The prefix of the equation reference. Default is "Equation".section-prefix: The prefix of the section reference. Default is "Section".theorem-{theorem_name}-prefix: The prefix of the theorem reference. Default is capitalizedtheorem_name. For example, if you defined\newtheorem{thm}{Theorem}, you should set the metadatatheorem-thm-prefixto "Theorem" (and the default isThm).prefix-space: Whether to add a space between the prefix and the number. Default istrue(for some languages, the space may not be needed).
Custom Formatting System (f-string formatting)
Metadata Names
For now, we support 5+x types of items and 4 types of formatting:
- Item types:
fig(figure),tab(table),eq(equation),sec(section),subfig(subfigure),thm-{theorem_name}(theorem). For example, if you defined\newtheorem{lem}{Lemma}, the item type isthm-lem. - Formatting types:
src(source): The format of the numbering where the item appears. For figures and tables, this is the format used in the captions. For equations, this is the format used after the equations. For sections, this is the format used at the beginning of the section titles.ref(reference): The format of numbering used in\refcommand.cref(cleveref reference)/Cref(Cleveref reference with capital letter): The format of numbering used in\crefand\Crefcommands.
You can customize the formatting type b of the item type a by setting the metadata a-b-format. For example, to customize the numbering format of figure captions, you set the fig-src-format metadata.
By default, if not specified, the Cref format will be the capitalized version of the cref format, the src format will be the same as the Cref format, the ref format will be "{num}", and the cref format will be "{prefix}{num}".
For sections, every level has its own formatting. You can set the metadata, for example, section-src-format-1, section-cref-format-2, etc.
For equations, the default src format (i.e. equation-src-format) is "\\qquad({num})". \qquad is used to offer a little space between the equation and the number. You can customize it as you like.
Metadata Values
The metadata values are python f-string format strings. Various fields are provided for you to customize the format. For example, if you have the following settings:
number-reset-level:2figure-prefix:"figure"prefix-spacetoTrue.section-numstyle-1:"Roman"figure-numstyle:"latin"
Then, the fifth figure under subsection 2.3 will have the following fields:
num:II.3.eparent_num:II.3this_num:e(note that the fields ended with_numwill keep the numbering style settings)fig_id:5prefix:figure(note the space at the end)Prefix:Figureh1:2h2:3(note thath2is accessible only when thenumber-reset-level>= 2 and so on)h1_zh:二h1_roman:iih1_Roman:IIh1_latin:bh1_Latin:B- ... (any supported languages or symbols, see the Numbering System section)
Here are some examples of the metadata values:
- set the
fig-src-formatmetadata to"{prefix}{num}", the numbering before its caption will be shown as "Figure 2.3.5" - set the
fig-cref-formatmetadata to"{Prefix} {fig_id} (in Section {parent_num})", when referred to by\Cref, it will be shown as"Figure 5 (in Section 2.3)". - set the
section-src-format-1metadata to"第{h1_zh}章"andsection-cref-format-1to"第{h1_zh}章"to use Chinese numbers for the first level sections. - set the
thm-thm-cref-formatmetadata to"Theorem {thm-thm_id}"to use the format "Theorem 1" for the theorem environment "thm" while"Theorem {num}"for "Theorem 1.1".
For more non-arabic number support, see the Custom Non-Arabic Numbers Support section.
For more examples, see also the Customized Metadata Examples.
Equations
multiline-environments: Possible multiline environment names separated by commas. Default is "cases,align,aligned,gather,gathered,multline,flalign". The equations under these environments will be numbered line by line.
Theorems
theorem-names: The names of the theorems separated by commas. Default is "". For example, if you have\newtheorem{thm}{Theorem}and\newtheorem{lem}{Lemma}, you should set the metadatatheorem-namesto "thm,lem".
List of Figures and Tables
To support short captions and custom titles in the list of figures and tables, you can set the following metadata to turn on the custom list of figures and tables:
custom-lof: Whether to use a custom list of figures. Default isfalse.custom-lot: Whether to use a custom list of tables. Default isfalse.
You can customize the list of figures and tables by setting the following metadata:
lof-title: The title of the list of figures. Default is "List of Figures".lot-title: The title of the list of tables. Default is "List of Tables".list-leader-type: The type of leader used in the list of figures and tables (placeholders between the caption and the page number). Default is "dots". Possible values are "dot", "hyphen", "underscore", "middleDot" and "none".
For more details, see the List of Figures and Tables section.
Multiple References
multiple-ref-suppress: Whether to suppress the multiple references. Default istrue. If set totrue, the multiple references will be suppressed. For example, if you have\cref{eq1,eq2,eq3,eq4}, it will be shown as "equations 1-4" instead of "equations 1, 2, 3 and 4".multiple-ref-separator: The separator between the multiple references. Default is ", ". For example, if you set it to "; ", the multiple references will be shown as "equations 1; 2; 3 and 4".multiple-ref-last-separator: The separator between the last two references. Default is " and ". For example, if you set it to " & ", the multiple references will be shown as "equations 1, 2, 3 & 4".multiple-ref-to: The separator between suppressed multiple references. Default is "-". For example, if you set it to " to ", the multiple references will be shown as "equations 1 to 4".multiple-ref-style: The style of the multiple references. Default is "simple". Possible values are "full" and "simple". If set to "full", the multiple references will be shown as "equation 1, equation 2, equation 3 and equation 4" instead of "equations 1, 2, 3 and 4" (simple style).
NOTE: in case of setting metadata in a yaml file, the spaces at the beginning and the end of the values are by default stripped. Therefore, if you want to keep the spaces in the yaml metadata file, you should mannually escape those spaces via double slashes. For example, if you want set multiple-ref-last-separator to " and " (spaces appear at the beginning and the end), you should set it as "\\ and\\ " in the yaml file. See pandoc's issue #10539 for more further discussions.
Appendix
appendix-names: The names of the appendices separated by "/,". If you have this in your tex file:\appendix \chapter{First Appendix} \chapter{Second Appendix}
You should set the metadata appendix-names to "First Appendix/,Second Appendix". Note that the names should be separated by "/,", not by "," (so as to avoid conflicts with the commas in the names).
Details
Equations Details
If metadata number-equations is set to true, all the equations will be numbered. The numbers are added at the end of the equations and the references to the equations are replaced by their numbers.
Equations under multiline environments (specified by metadata multiline-environments ) such as align, cases etc. are numbered line by line, and the others are numbered as a whole block. In multiline environments, \nonumber commands are supported to turn off the numbering of a specific line.
However, you should keep in mind this: currently we CANNOT support some environments such as aligned and gathered very well, because pandoc will parse all align and gather environments into aligned and gathered environments internally.
Currently, we recommend two approaches to achieve block numbered multiline equations:
- (mostly recommended) Use
splitenvironment. - Use
alignedorgatheredenvironments, and\labelit outside the environment.
For example, as shown in test_data/test.tex:
\begin{equation}
\begin{aligned}
f(x) &= x^2 + 2x + 1 \\
g(x) &= \sin(x)
\end{aligned}
\label{eq:quadratic}
\end{equation}
This equation will be numbered as a whole block, say, (1.1), while:
\begin{align}
a &= b + c \label{eq:align1} \\
d &= e - f \label{eq:align2} \\
g &= h \nonumber \\
i &= j + k \label{eq:align3}
\end{align}
This equation will be numbered line by line, say, (1.2), (1.3) and (1.4), while the third line will not be numbered.
NOTE: the pandoc filters have no access to the difference of align and align* environments. Therefore, you CANNOT turn off the numbering of a specific align environment via the * mark. If you do want to turn off the numbering of a specific align environment, a temporary solution is to manually add \nonumber commands to every line of the environment. This may be fixed by a custom lua reader to keep those information in the future.
List of Figures and Tables Details
Currently, this feature is only available for docx output with Python>=3.8.
If you set the metadata custom-lof and custom-lot to true, the filter will generate a custom list of figures and tables.
The captions used in the list of figures and tables are the short captions if they are defined in the LaTeX source code. If not, the full captions are used. The short captions are defined in the LaTeX source code as \caption[short caption]{full caption}.
The list of figures and tables will be put at the beginning of the document, since we cannot access the locations of the LaTeX command \listoffigures and \listoftables in the pandoc filters.
Data Export
If you set the metadata data-export-path to a path, the filter will export the filter data to the specified path in the JSON format. This is useful for further usage of the filter data in other scripts or filter debugging. The output data is a dictionary with identifiers (labels) as keys and the corresponding data as values. The info dict contains the following keys: nums: list[int], item_type: Literal["fig", "tab", "eq", "sec", "subfig"], caption: Optional[str], short_caption: Optional[str], src: str, ref: str, cref: str, Cref: str.
Log
Some warning message will be shown in the log file named pandoc-tex-numbering.log in the same directory as the output file. You can check this file if you encounter any problems or report those messages in the issues.
org file support
org files are supported by adding an additional lua filter src\org_helper.lua to the pandoc command. The usage is as follows:
pandoc --lua-filter org_helper.lua --filter pandoc-tex-numbering input.org -o output.docx
Be sure to use --lua-filter org_helper.lua before --filter pandoc-tex-numbering.
Reason for this is the default org reader of pandoc does not parse LaTeX codes by default, for example, LaTeX equations in equation environments and cross references via \ref{} macros are parsed as RawBlock and RawInline nodes, while we desire Math nodes and Link nodes respectively. The org_helper.lua filter helps read these blocks via latex reader and after that, the pandoc-tex-numbering filter can work as expected.
Related discussions can also be found in pandoc issue #1764 (codes in org_helper.lua are based on comments from @tarleb in this issue) and pandoc-tex-numbering issue #1.
Examples
With the testing file tests/test.tex:
Default Metadata
pandoc test.tex -o output.docx -F pandoc-tex-numbering -M theorem-names="thm,lem" -M appendix-names="Appendix"
The results are shown as follows:



Customized Metadata
In the following example, we custom the following silly items only for the purpose of demonstration:
- Reset the numbering at the second level sections, such that the numbering will be shown as "1.1.1", "3.2.1" etc.
- The formattings are set as follows:
- For sections:
- at the beginning of sections, use Chinese numbers "第一章" for the first level sections and English numbers "Section 1.1" for the second level sections.
- when referred to, use, in turn, "Chapter 1", "第1.1节" etc.
- add an offset of 5 to the second level sections, such that the first second level section will be numbered as "Section 1.6".
- For tables:
- at the beginning of captions, use styles like
Table 1-1-1 - when referred to, use styles like
table 1 (in Section 1.1)
- at the beginning of captions, use styles like
- For figures:
- at the beginning of captions, use styles like
Figure 1.1:1 - when referred to, use styles like
as shown in Fig. 1.1.1, - add an offset of 3 to the figures, such that the first figure will be numbered as
Figure 1.1:4.
- at the beginning of captions, use styles like
- For equations, suppress the parentheses and use the format
1.1.1 - For subfigures:
- use greek letters for symbols
- at the beginning of captions, use styles like
[β(1)]
- For theorems:
- Theorem environment "thm" uses "Theorem" as the prefix
- Lemma environment "lem" uses "Lemma" as the prefix
- For appendices:
- Suppress the top level appendix number
- Use (upper case) Roman numbers for the second level appendices
- Suppress the top level numbering in all references
- For sections:
- Turn on custom list of figures and tables and:
- Use custom titles as "图片目录" and "Table Lists" respectively.
- Use hyphens as the leader in the lists.
- For multiple references:
- Stop suppressing the multiple references.
- Use "、" as the separator between the multiple references.
- Use " & "(spaces at both ends) as the last separator between the last two references.
- Export the filter data to a file named
data.json.
Run the following command with corresponding metadata in a metadata.yaml file (recommended):
pandoc -o output.docx -F pandoc-tex-numbering --metadata-file test.yaml test.tex
# test.yaml
number-reset-level: 2
theorem-names: "thm,lem"
appendix-names: "Appendix"
section-offset-2: 5
figure-offset: 3
# Prefix Settings
figure-prefix: Fig
table-prefix: Tab
equation-prefix: Eq
theorem-thm-prefix: Theorem
theorem-lem-prefix: Lemma
# Numbering Style Settings
subfigure-numstyle: "greek"
appendix-numstyle-2: "Roman"
# Formatting Settings
section-src-format-1: "第{h1_zh}章"
section-src-format-2: "Section {num}."
section-cref-format-1: "chapter {h1}"
section-cref-format-2: "第{num}节"
table-src-format: "Table {h1}-{h2}-{this_num}"
table-cref-format: "table {this_num} (in Section {parent_num})"
figure-src-format: "Figure {parent_num}:{this_num}"
figure-cref-format: "as shown in Fig. {num}"
equation-src-format: "\\qquad {num}"
subfigure-src-format: "[{this_num}({subfig_id})]"
appendix-src-format-1: "" # Suppress the top level appendix number
appendix-ref-format-2: "{this_num}"
appendix-src-format-2: "Appendix {this_num}"
# List of Figures and List of Tables Settings
custom-lot: true
custom-lof: true
lot-title: "Table List"
lof-title: "图片目录"
list-leader-type: "hyphen"
data-export-path: "data.json"
# Multiple Reference Settings
multiple-ref-suppress: false
multiple-ref-separator: "、"
multiple-ref-last-separator: "\\ &\\ "
multiple-ref-to: "\\ to\\ "
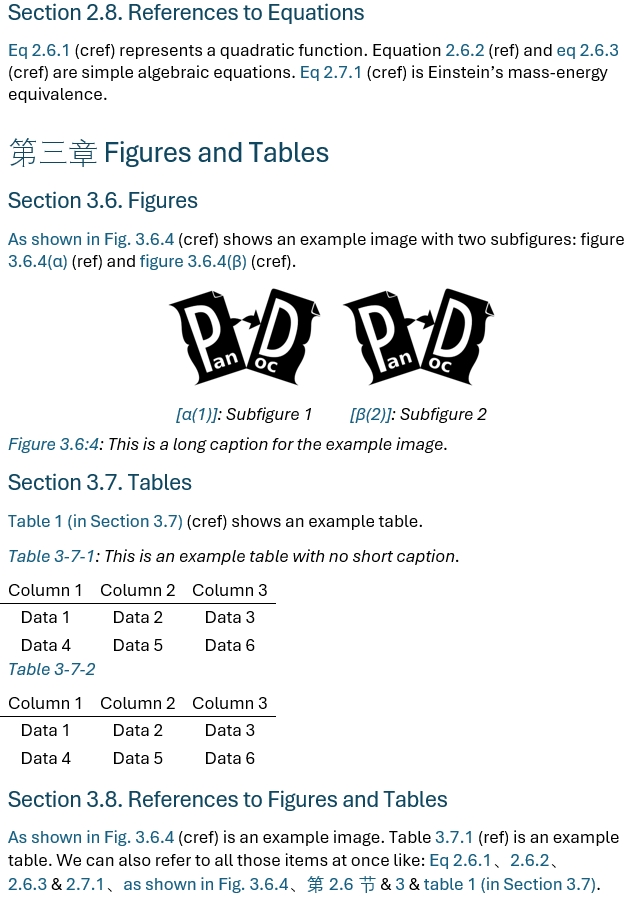
The results are shown as follows:


Development
Basic Structure of the Filter
If you want to extend the filter or understand the core logic of the filter, before and while reading the source code, you may want to read this.
pandoc-tex-numbering is designed with an OOP style to support a flexible and extensible formatting system. The core objects are as follows:
Formaterobjects: represents a specific formatting logic. It defines all possible formats of a specific type of item.- Data: a series of format presets (a dict mapping format names to a fstring or a callable)
- Usage: call with a detailed
numslist to generate the formatted string.
Numberingobjects: represents a specific numbering identity, i.e. an unique item which can be referred to.- Data: numbering information of the item (a
numslist per se), its corresponding formater object and other metadata (e.g. captions). - Usage:
- Generate formatted string: built-in format presets (
ref,cref,Cref,src) of this item can be accessed directly by calling the corresponding property of the numbering object (e.g.num_obj.ref). - Compare: two numbering objects can be directly compared based on the
numslist.
- Generate formatted string: built-in format presets (
- Data: numbering information of the item (a
NumberingStateobject: core object to manage the numbering of all items in the document. It mangages numbering increment, reset, generate newNumberintgobjects and assign properFormaterobjects to them.- Data: current numbering information of all types of items, and formater objects for all types of items.
- Usage:
- Increment numbering: call
next_{item_type}method to increment the numbering of a specific type of item (numbering reset will be handled automatically). - Get current (newest) numbering objects of a specific type: call
current_{item_type}method to get the current numbering object of a specific type.
- Increment numbering: call
The core logic of the pandoc-tex-numbering filter can be roughly illustrated as follows:
- Prepare the global settings and variables (
preparefunction). - Construct the Formater objects for various types of items: figures, tables, equations, sections, theorems, etc. (
preparefunction). - Initialize a core NumberingState object (
doc.num_state) with the Formater objects (preparefunction). - Walk through the document to construct the reference dictionary (
doc.ref_dict) (a series offind_label_{item_type}functions):- Call
next_{item_type}method of the NumberingState object to increment the numbering of a specific type of item. - Save the
Numberingobject to the reference dictionary (doc.ref_dict) with the label as the key. - Modify some inplace numbering elements with
num.src(e.g. add numbering to the caption of a figure, add numbering to the math block).
- Call
- Walk through the document again to replace all references with the formatted strings (mainly
labels2refsfunction). - Finalize the document (
finalizefunction):- Wrap the math blocks and some tables with div elements to add identifiers.
- Export the reference dictionary to a json file if needed.
- Clean up the global variables.
Custom Non-Arabic Numbers Support
Currently, the filter supports only Chinese non-arabic numbers. If you want to support other languages, you can modify the lang_num.py file. For example, if you want to support the non-arabic numbers in the language foo, you can:
- Define a new function
arabic2foo(num:int)->strthat converts the arabic number to the corresponding non-arabic number. - Add the function to the
language_functionsdictionary with the corresponding language name as the key, for example{"foo":arabic2foo}.
Then you can set the metadata section-format-1="Chapter {h1_foo}." to enable the non-arabic numbers in the filter.
Advanced docx Support
In oxml.py, I added a built-in framework to support high-level OOXML operations. If you're familiar with OOXML, you can utilize this framework to embed OOXML codes directly into the output (into RawBlock nodes with openxml format).
FAQ
- Q: Can the filter work with xxx package?
- A: It depends. If the package is supported by pandoc, then it should work. If not, you may need to a custom filter or reader to parse the LaTeX codes correctly. In the latter case, this is out of the scope of this filter. For example, the macro
\cein themhchempackage is not supported by pandoc, so we cannot parse the chemical equations correctly. - Q: Can the filter support complex caption macros such as
\bicaption? - A: No for now. Caption macros such as
\bicaptionare not supported by the defaultlatexreader of pandoc. Therefore, we cannot parse them correctly. You may need a custom reader to parse them correctly or modify the source code before using this filter. - Q: Can
docxoutput support the short captions in the list of figures and tables? - A: Now supported.
That said, however, functionalities mentioned above can never be supported easily since they are not, and maybe never will be, supported by native pandoc framework.
TODO
There are some known issues and possible improvements:
- Support multiple references in
cleverefpackage. - Add empty caption for figures and tables without captions (currently, they have no caption and therefore links to them cannot be located).
- Directly support
align*and other non-numbered environments. - Subfigure support.
- Support short captions in
docxoutput. - Support right-aligned equation numbers.
- A separate documentation page.
- Testing scripts.
- How-tos.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pandoc_tex_numbering-1.3.3.tar.gz.
File metadata
- Download URL: pandoc_tex_numbering-1.3.3.tar.gz
- Upload date:
- Size: 1.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
36410f5a5075fdecf90e3ceb16ce084d16deca5bd505b7f1e37219ecb177724f
|
|
| MD5 |
930b0be66ffa768e523214bc7b875f15
|
|
| BLAKE2b-256 |
a05129e9ceed07f6de79561cc36391b0fa5271ed566c0cfada1fdb65d522285c
|
File details
Details for the file pandoc_tex_numbering-1.3.3-py3-none-any.whl.
File metadata
- Download URL: pandoc_tex_numbering-1.3.3-py3-none-any.whl
- Upload date:
- Size: 49.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
abe0583b1262ae125f42ba7283f70704c2102bdb7383bd7147ce9f0259b0f71e
|
|
| MD5 |
89dac82edbf494b89838fd5cbeb9cf86
|
|
| BLAKE2b-256 |
0d7a87669faa13f783aec61ea080c58f5706dc71f0f902f3d19506c2673a3260
|







