ParoQuant — Pairwise Rotation Quantization for LLMs
Project description
ParoQuant
Pairwise Rotation Quantization for Efficient Reasoning LLM Inference




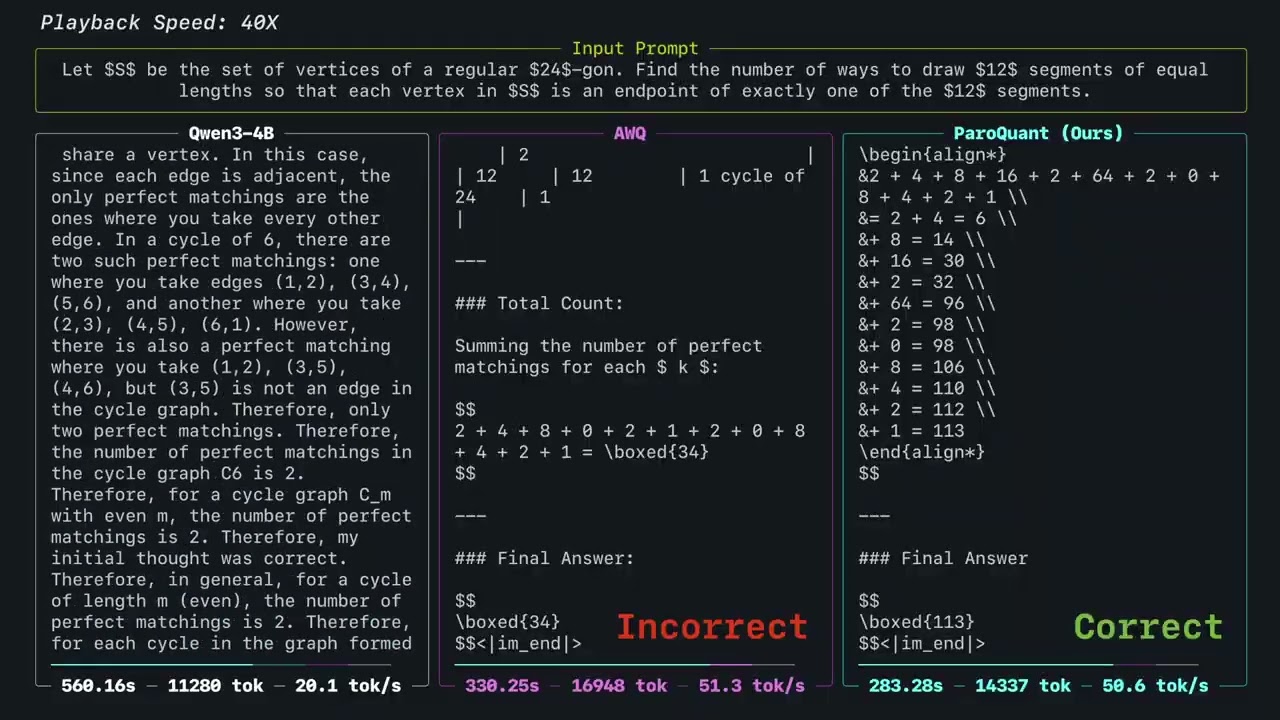
State-of-the-art INT4 quantization for LLMs. ParoQuant uses learned pairwise rotations to suppress weight outliers, closing the accuracy gap with FP16 while running at near-AWQ speed. Supports NVIDIA GPUs (vLLM, Transformers) and Apple Silicon (MLX).
Quick Start
Installation
# NVIDIA GPU (CUDA 12.9)
pip install "paroquant[vllm]"
# NVIDIA GPU (CUDA 13.0)
pip install "paroquant[vllm]" "vllm==0.17.1" \
--extra-index-url https://wheels.vllm.ai/0.17.1/cu130 \
--extra-index-url https://download.pytorch.org/whl/cu130
# Apple Silicon
pip install "paroquant[mlx]"
Pick a model from our Hugging Face collection:
export MODEL=z-lab/Qwen3.5-4B-PARO
Interactive Chat
python -m paroquant.cli.chat --model $MODEL
OpenAI-Compatible API Server
python -m paroquant.cli.serve --model $MODEL --port 8000
For vLLM, the arguments are passed to vLLM directly. See vLLM docs for more details.
For MLX, add --vlm if you wish to load the VLM components and use the model's multimodal features. For vLLM, VLM components are loaded by default and can be skipped with the server argument --language-model-only.
Docker (NVIDIA GPU)
[!NOTE] The following commands map the local cache directory to the container in order to persist kernel cache across runs. Remove
-v ...to disable this behaviour.
# Interactive chat
docker run --pull=always --rm -it --gpus all --ipc=host \
-v $HOME/.cache/paroquant:/root/.cache/paroquant \
ghcr.io/z-lab/paroquant:chat --model $MODEL
# API server (port 8000)
docker run --pull=always --rm -it --gpus all --ipc=host -p 8000:8000 \
-v $HOME/.cache/paroquant:/root/.cache/paroquant \
ghcr.io/z-lab/paroquant:serve --model $MODEL
Models
All models are available on Hugging Face. Swap the model name in the commands above to try any of them.
Qwen3.5
| Model | Checkpoint |
|---|---|
| Qwen3.5-0.8B | z-lab/Qwen3.5-0.8B-PARO |
| Qwen3.5-2B | z-lab/Qwen3.5-2B-PARO |
| Qwen3.5-4B | z-lab/Qwen3.5-4B-PARO |
| Qwen3.5-9B | z-lab/Qwen3.5-9B-PARO |
| Qwen3.5-27B | z-lab/Qwen3.5-27B-PARO |
Qwen3
| Model | Checkpoint |
|---|---|
| Qwen3-0.6B | z-lab/Qwen3-0.6B-PARO |
| Qwen3-1.7B | z-lab/Qwen3-1.7B-PARO |
| Qwen3-4B | z-lab/Qwen3-4B-PARO |
| Qwen3-8B | z-lab/Qwen3-8B-PARO |
| Qwen3-14B | z-lab/Qwen3-14B-PARO |
Llama
| Model | Checkpoint |
|---|---|
| Llama-2-7B | z-lab/Llama-2-7b-hf-PARO |
| Llama-3-8B | z-lab/Meta-Llama-3-8B-PARO |
| Llama-3.1-8B-Instruct | z-lab/Llama-3.1-8B-Instruct-PARO |
Want a model that's not listed? Open an issue and let us know.
Reproduction
[!NOTE] The main branch of this repository is under active development, and reproducibility is not guaranteed. Please use the
legacybranch to reproduce results from the paper.
Quantize Your Own Model
git clone https://github.com/z-lab/paroquant && cd paroquant
pip install -e ".[optim,eval]"
# 1. Optimize rotation parameters
experiments/optimize/4bit.sh Qwen/Qwen3-8B
# 2. Export to HF checkpoint (--mode real for INT4, --mode pseudo for FP16)
python -m paroquant.cli.convert \
--model Qwen/Qwen3-8B \
--result-dir output/Qwen3-8B \
--output-path models/Qwen3-8B-PARO
Docker Images
| Image | Purpose |
|---|---|
ghcr.io/z-lab/paroquant:chat |
Interactive chat |
ghcr.io/z-lab/paroquant:chat-cu129 |
Interactive chat (CUDA 12.9) |
ghcr.io/z-lab/paroquant:serve |
OpenAI-compatible API server |
ghcr.io/z-lab/paroquant:latest |
Optimization & evaluation |
ghcr.io/z-lab/paroquant:eval |
Reasoning task evaluation |
Citation
@inproceedings{liang2026paroquant,
title = {{ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference}},
author = {Liang, Yesheng and Chen, Haisheng and Zhang, Zihan and Han, Song and Liu, Zhijian},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026}
}
Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file paroquant-0.1.10.tar.gz.
File metadata
- Download URL: paroquant-0.1.10.tar.gz
- Upload date:
- Size: 44.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d8de90c57887422dcf8fb82e39eeae15be2d69dd12125fd96f51f43e8db67f48
|
|
| MD5 |
1be828ef4192f263412e150555be0674
|
|
| BLAKE2b-256 |
151ca8a7365da0c39010e059d3bea7da62a32ec86064e8ceee9abb381d4e5cfa
|
Provenance
The following attestation bundles were made for paroquant-0.1.10.tar.gz:
Publisher:
publish-to-pypi.yml on z-lab/paroquant
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
paroquant-0.1.10.tar.gz -
Subject digest:
d8de90c57887422dcf8fb82e39eeae15be2d69dd12125fd96f51f43e8db67f48 - Sigstore transparency entry: 1114859332
- Sigstore integration time:
-
Permalink:
z-lab/paroquant@dae2cb60c7aea244ae214cd7c41c62ef37c435e1 -
Branch / Tag:
refs/tags/v0.1.10 - Owner: https://github.com/z-lab
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-to-pypi.yml@dae2cb60c7aea244ae214cd7c41c62ef37c435e1 -
Trigger Event:
push
-
Statement type:
File details
Details for the file paroquant-0.1.10-py3-none-any.whl.
File metadata
- Download URL: paroquant-0.1.10-py3-none-any.whl
- Upload date:
- Size: 52.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cee45713d414e64f384617fe570f870a8624aa374cdb0faa1e8c25ac33a264c2
|
|
| MD5 |
4509171982cbac7108d16e6f56814533
|
|
| BLAKE2b-256 |
fa66bba3fe0f69fc415cad5750a681f0c86e18c3bf5ed6c8333752073c031fc6
|
Provenance
The following attestation bundles were made for paroquant-0.1.10-py3-none-any.whl:
Publisher:
publish-to-pypi.yml on z-lab/paroquant
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
paroquant-0.1.10-py3-none-any.whl -
Subject digest:
cee45713d414e64f384617fe570f870a8624aa374cdb0faa1e8c25ac33a264c2 - Sigstore transparency entry: 1114859333
- Sigstore integration time:
-
Permalink:
z-lab/paroquant@dae2cb60c7aea244ae214cd7c41c62ef37c435e1 -
Branch / Tag:
refs/tags/v0.1.10 - Owner: https://github.com/z-lab
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-to-pypi.yml@dae2cb60c7aea244ae214cd7c41c62ef37c435e1 -
Trigger Event:
push
-
Statement type:







