Efficient pitch estimation with self-supervised learning


Project description
🌿 PESTO: Pitch Estimation with Self-supervised Transposition-equivariant Objective
tl;dr: 🌿 PESTO is a fast and powerful pitch estimator based on machine learning.
This repository provides a minimal code implementation for inference only. For full training details and research experiments, please refer to the full implementation or the paper 📝(arXiv).
Table of Contents
- Installation
- Usage
- 🚀NEW: Streaming Implementation
- 🚀NEW: Export Compiled Model
- Performance and Speed Benchmarks
- Contributing
- Citation
- Credits
Installation
pip install pesto-pitch
That's it!
Dependencies
- PyTorch: For model inference.
- numpy: For basic I/O operations.
- torchaudio: For audio loading.
- matplotlib: For exporting pitch predictions as images (optional).
Note: It is recommended to install PyTorch before PESTO following the official guide if you're working in a clean environment.
Usage
Command-line Interface
To use the CLI, run the following command in a terminal to estimate the pitch of an audio file using a pretrained model:
pesto my_file.wav
or
python -m pesto my_file.wav
Note: You can use pesto -h to get help on output formats and additional options.
Output Formats
By default, the predicted pitch is saved in a .csv file:
time,frequency,confidence
0.00,185.616,0.907112
0.01,186.764,0.844488
0.02,188.356,0.798015
0.03,190.610,0.746729
0.04,192.952,0.771268
0.05,195.191,0.859440
...
This structure is voluntarily the same as in CREPE repo for easy comparison between both methods.
Alternatively, you can specify the output format with the -e/--export_format option:
- .npz: Timesteps, pitch, confidence, and activations.
- .png: Visualization of pitch predictions (requires matplotlib).
Here is an example output of using the '-e .png' option:
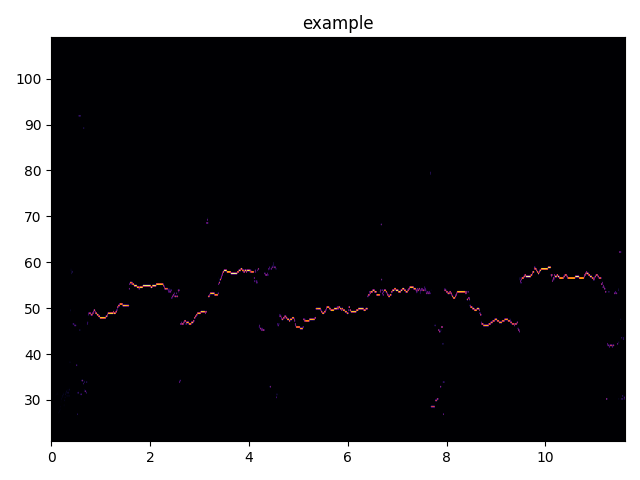
Multiple formats can be specified after the -e option.
Batch Processing
To estimate the pitch for multiple files:
pesto my_folder/*.mp3
Audio Format
PESTO uses torchaudio for audio loading, supporting various formats and sampling rates without needing resampling.
Pitch Decoding Options
By default, the model outputs a probability distribution over pitch bins, which is converted to pitch using Argmax-Local Weighted Averaging decoding (similar to CREPE)
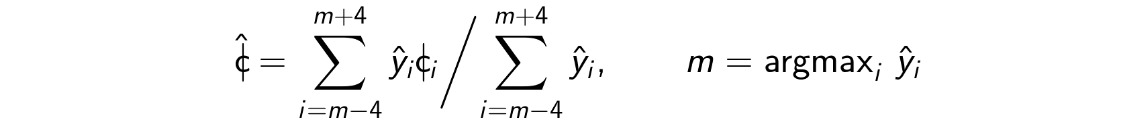
Alternatively, basic argmax or weighted average can be used with the -r/--reduction option.
Miscellaneous
- Step Size: Set with
-s(in milliseconds). The actual hop length might differ slightly due to integer conversion. - Output Units: Use
-Fto return pitch in semitones instead of frequency. - GPU Inference: Specify the GPU with
--gpu <gpu_id>. The default--gpu -1uses the CPU.
Python API
You can also call functions defined in pesto/predict.py directly in your Python code. predict_from_files is the the function used by default when running the CLI.
Basic Usage
import torchaudio
import pesto
# Load audio (ensure mono; stereo channels are treated as separate batch dimensions)
x, sr = torchaudio.load("my_file.wav")
x = x.mean(dim=0) # PESTO takes mono audio as input
# Predict pitch. x can be (num_samples) or (batch, num_samples)
timesteps, pitch, confidence, activations = pesto.predict(x, sr)
# Using a custom checkpoint:
predictions = pesto.predict(x, sr, model_name="/path/to/checkpoint.ckpt")
# Predicting from multiple files:
pesto.predict_from_files(["example1.wav", "example2.mp3"], export_format=["csv"])
Note: If you forget to convert a stereo to mono, channels will be treated as batch dimensions and you will get predictions for each channel separately.
Advanced Usage
pesto.predict will first load the CQT kernels and the model before performing
any pitch estimation. To avoid reloading the model for every prediction, instantiate the model once using load_model:
import torch
from pesto import load_model
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
pesto_model = load_model("mir-1k_g7", step_size=20.).to(device)
for x, sr in your_audio_loader:
x = x.to(device)
predictions, confidence, amplitude, activations = pesto_model(x, sr)
# Process predictions as needed
Since PESTO is a subclass of nn.Module, it supports batched inputs, making integration into custom architectures straightforward.
Example:
import torch
import torch.nn as nn
from pesto import load_model
class MyGreatModel(nn.Module):
def __init__(self, step_size, sr=44100, **kwargs):
super(MyGreatModel, self).__init__()
self.f0_estimator = load_model("mir-1k_g7", step_size, sampling_rate=sr)
def forward(self, x):
with torch.no_grad():
f0, conf, amp = self.f0_estimator(x, convert_to_freq=True, return_activations=False)
# Further processing with f0, conf, and amp
return f0, conf, amp
NEW: Streaming Implementation
PESTO now supports streaming audio processing. To enable streaming, load the model with streaming=True:
import time
import torch
from pesto import load_model
pesto_model = load_model(
'mir-1k_g7',
step_size=5.,
sampling_rate=48000,
streaming=True, # Enable streaming mode
max_batch_size=4
)
while True:
buffers = torch.randn(3, 240) # Acquire a batch of 3 audio buffers
pitch, conf, amp = pesto_model(buffers, return_activations=False)
print(pitch)
time.sleep(0.005)
Note: The streaming implementation uses an internal circular buffer per batch dimension. Do not use the same model for different streams sequentially.
NEW: Export Compiled Model
For reduced latency and easier integration into other applications, you can export a compiled version of the model:
python -m realtime.export_jit --help
Note: When using the compiled model, parameters like sampling rate and step size become fixed and cannot be modified later.
Performance and Speed Benchmarks
PESTO outperforms other self-supervised baselines on datasets such as MIR-1K and MDB-stem-synth and achieves performance close to supervised methods like CREPE (with 800x more parameters).

Benchmark Example:
- Audio File:
wav(2m51s) - Hardware: Intel i7-1185G7 (11th Gen, 8 cores)
- Speed: With a 10ms step size, PESTO would perform pitch estimation of the file in 13 seconds (~12 times faster than real-time) while CREPE would take 12 minutes!.
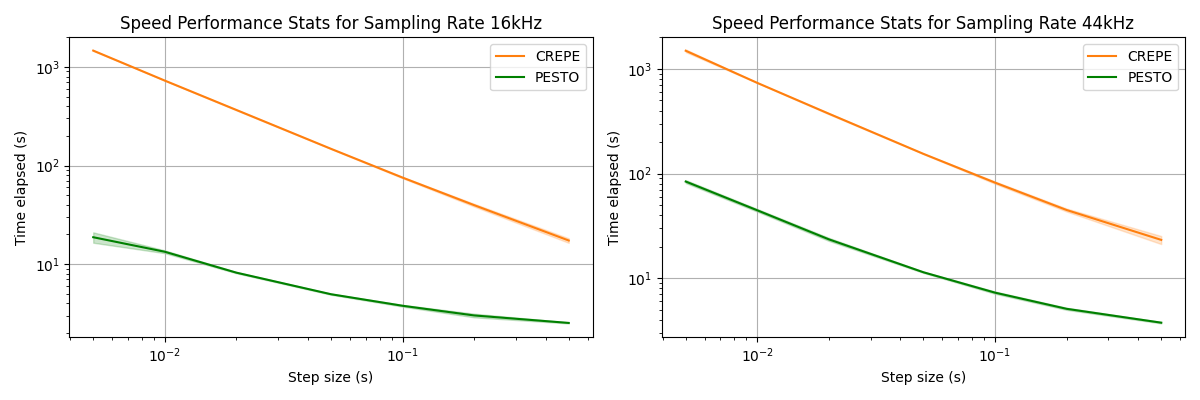
The y-axis in the speed graph is log-scaled.
Inference on GPU
Under the hood, the input is passed to the model as a single batch of CQT frames, so pitch is estimated for the whole track in parallel, making inference extremely fast.
However, when dealing with very large audio files, processing the whole track at once can lead to OOM errors.
To circumvent this, one can split the batch of CQT frames into multiple chunks by setting option -c/--num_chunks.
Chunks will be processed sequentially, thus reducing memory usage.
As an example, a 48kHz audio file of 1 hour can be processed in 20 seconds only on a single GTX 1080 Ti when split into 10 chunks.
Contributing
- Currently, only a single model trained on MIR-1K is provided.
- Contributions to model architectures, training data, hyperparameters, or additional pretrained checkpoints are welcome.
- Despite PESTO being significantly faster than real-time, it is currently implemented as standard PyTorch and may be further accelerated.
- Suggestions for improving inference speed aree more than welcome!
Feel free to contact us with any ideas to enhance PESTO.
Citation
If you use this work, please cite:
@inproceedings{PESTO,
author = {Riou, Alain and Lattner, Stefan and Hadjeres, Gaëtan and Peeters, Geoffroy},
booktitle = {Proceedings of the 24th International Society for Music Information Retrieval Conference, ISMIR 2023},
publisher = {International Society for Music Information Retrieval},
title = {PESTO: Pitch Estimation with Self-supervised Transposition-equivariant Objective},
year = {2023}
}
Credits
- nnAudio for the original CQT implementation
- multipitch-architectures for the original architecture of the model
@ARTICLE{9174990,
author={K. W. {Cheuk} and H. {Anderson} and K. {Agres} and D. {Herremans}},
journal={IEEE Access},
title={nnAudio: An on-the-Fly GPU Audio to Spectrogram Conversion Toolbox Using 1D Convolutional Neural Networks},
year={2020},
volume={8},
number={},
pages={161981-162003},
doi={10.1109/ACCESS.2020.3019084}}
@ARTICLE{9865174,
author={Weiß, Christof and Peeters, Geoffroy},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
title={Comparing Deep Models and Evaluation Strategies for Multi-Pitch Estimation in Music Recordings},
year={2022},
volume={30},
number={},
pages={2814-2827},
doi={10.1109/TASLP.2022.3200547}}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pesto_pitch-2.0.1.tar.gz.
File metadata
- Download URL: pesto_pitch-2.0.1.tar.gz
- Upload date:
- Size: 631.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9ea0690be863e929af73de3653f09567c9d6583951fd75281bf16a6fa85f427e
|
|
| MD5 |
76088ee588b8626635968a1d65d23968
|
|
| BLAKE2b-256 |
65bcb79b34944bff2e9868c7f162b61f186cc006e51bd1452013d971aee74e31
|
File details
Details for the file pesto_pitch-2.0.1-py3-none-any.whl.
File metadata
- Download URL: pesto_pitch-2.0.1-py3-none-any.whl
- Upload date:
- Size: 627.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2eb1e5ac1c2f78f7563f4800cccd73daf04d52717ff0d95ea30257a56f3f9d37
|
|
| MD5 |
3beb28fc55191cfdfc24d79d84700805
|
|
| BLAKE2b-256 |
558546cc8ad5bf44a8f8626336ad3ffcd171c60002189b8b6dd0fdb80a7d444d
|







