A Python library for generating and correcting exams using Playwright and OpenCV.

Project description
Pexams: Python Exam Generation and Correction
Pexams is a library for generating beautiful multiple-choice exam sheets and automatically correcting them from scans using computer vision. It is similar to R/exams, but written in Python and using Playwright for high-fidelity PDF generation instead of LaTeX. It has the following advantages: it has more features, is faster, is easier to install, easier to customize, and it is much less prone to compilation errors than R/exams.
NOTE: This library is still in development and is not yet ready for production use. Although everything should work, there may be some bugs, missing features, or breaking changes in future versions.
Visual examples
You can view an example of a fully generated exam PDF here.
Below is an example of a simulated answer sheet and the annotated, corrected version that the library produces.
| Simulated Scan | Corrected Scan |
|---|---|
 |
 |
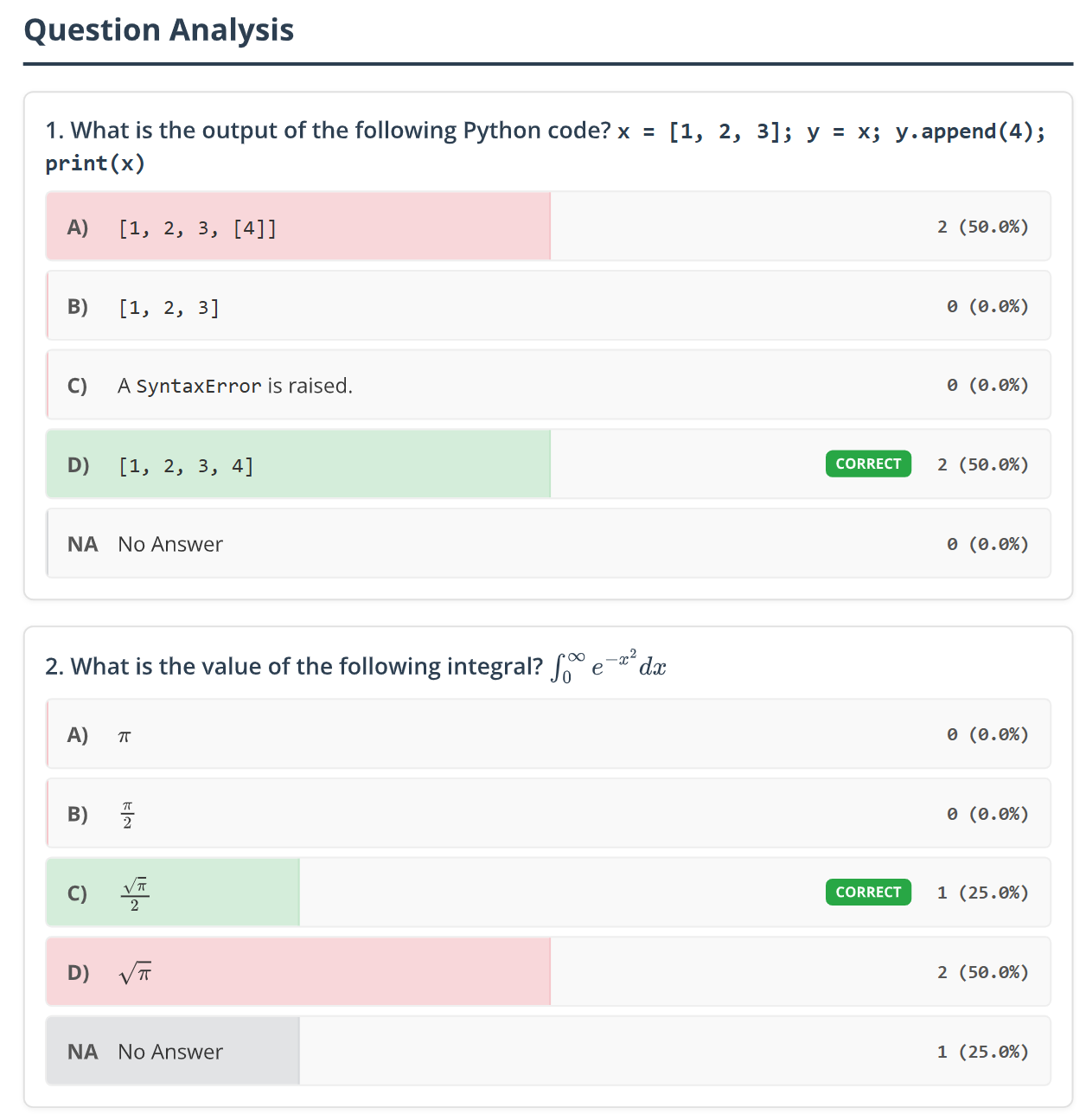
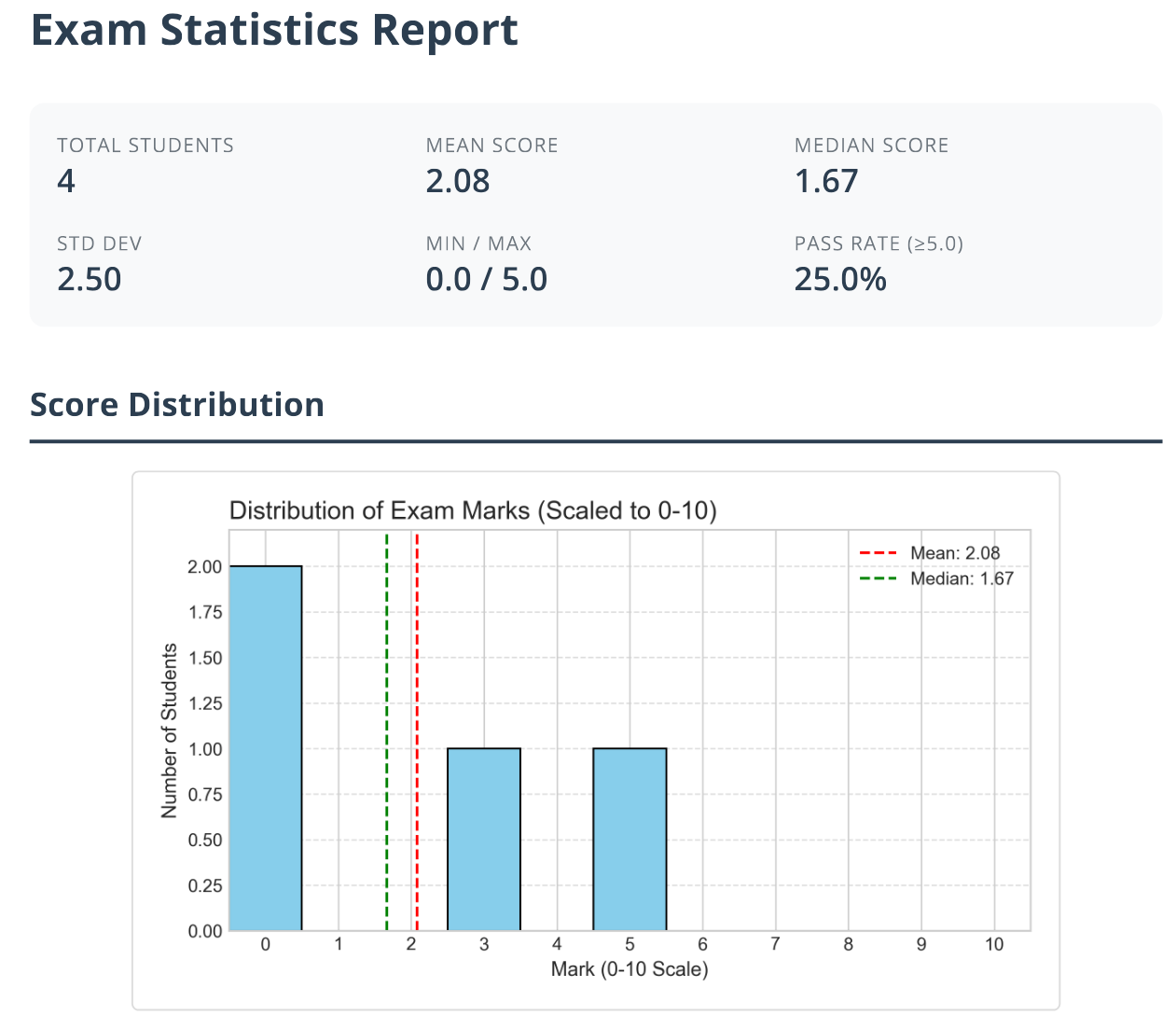
The analysis module also generates a plot showing the distribution of answers for each question, which helps in identifying problematic questions, as well as a plot showing the distribution of marks, which helps in assessing the fairness of the exam.
| Answer distribution | Marks distribution |
|---|---|
 |
 |
Features
Exam generation and Export
- Multiple exam models: Generate multiple unique exam models from a single source file, with automatic shuffling of questions and answers.
- Formats support:
- Input: Write questions in Markdown (preferred) or JSON.
- Export: Export questions to
rexams,wooclap,gift, ormdformats.
- Rich content support: Write questions in Markdown and include:
- LaTeX equations: Seamlessly render math formulas using MathJax (
$...$). - Images: Embed images in your questions from local files.
- Code snippets: Include code snippets (`...`).
- LaTeX equations: Seamlessly render math formulas using MathJax (
- Customizable layout:
- Arrange questions in one, two, or three columns.
- Adjust the base font size to fit your needs.
- Customizable answer sheet:
- Student ID field is a single box for handwritten ID, using OCR.
- Internationalization support for exam labels (supported:
en,es,ca,de,fr,it,nl,pt,ru,zh,ja).
- High-fidelity PDFs: Uses Playwright to produce clean, modern, and reliable PDF documents from HTML/CSS.
Correction & analysis
- Automated correction: Correct exams from a single PDF containing all scans or from a folder of individual images.
- Robust image processing: Uses
OpenCVwith fiducial markers for reliable, automatic perspective correction and alignment, theTrOCRvision transformer model for OCR of the student ID, name, and model ID, and custom position detection for the answers. - Detailed reports: Generates a
correction_results.csvfile with detailed scores and answers for each student. - Insightful visualizations: Automatically produces plots for:
- Mark distribution: A histogram to assess overall student performance.
- Answer distribution: A horizontal bar plot to analyze performance on each question and identify potential issues.
- Flexible scoring: Easily void specific questions during the analysis if needed, either by removing it from the score calculation completely or by voiding it "nicely" (can only increase the score if the question is correct, otherwise the question is removed from the score calculation).
- Mark Filling & Fuzzy Matching: Automatically fill an input CSV/Excel file with student marks, matching students by ID with fuzzy matching (Levenshtein distance) support for robustness against OCR errors.
Development & testing
- Simulated scans: Automatically generate a set of fake, filled-in answer sheets to test the full correction and analysis pipeline.
- End-to-end testing: A simple
pexams testcommand runs a full generate-correct-analyze cycle using bundled sample data and testing exports/fuzzy matching. - Easy debugging: Keep the intermediate HTML files to inspect the exam content and layout before PDF conversion, by setting the
--log-level DEBUGflag.
Installation
The library has been tested on Python 3.11.
1. Install the library
You can install the library from PyPI:
pip install pexams
Alternatively, you can clone the repository and install it in editable mode, which is useful for development:
git clone https://github.com/OscarPellicer/pexams.git
cd pexams
pip install -e .
2. Install Playwright browsers
pexams uses Playwright to convert HTML to PDF. You need to download the necessary browser binaries by running:
playwright install chromium
This command only needs to be run once.
3. Install Poppler
You may also need to install Poppler, which is needed for pdf2image to convert PDFs to images during correction, and also for generating simulated scans:
- Windows:
conda install -c conda-forge poppler - macOS:
brew install poppler - Debian/Ubuntu:
sudo apt-get install poppler-utils
Quick start
The pexams test command provides a simple way to run a full cycle and see the library in action. It uses a bundled sample file and media to generate, correct, and analyze a sample exam.
pexams test --output-dir ./my_test_output
This will create a my_test_output directory containing the generated exams, simulated scans, correction results, and analysis plots.
Usage
1. The questions file (Markdown)
The preferred input format is a Markdown file (.md) with the following structure:
## question_id
> 
Question text...
* Correct answer
* Wrong answer 1
* Wrong answer 2
**Explanation:**
Optional explanation text...
Notes:
- The first answer in the list is treated as the correct one (it will be shuffled during exam generation).
- Images must be in a blockquote
> ![...]. - Question ID can be a string or integer.
2. CLI commands
pexams generate
Generates exam PDFs or exports questions to other formats.
pexams generate <input_file> --to <format> --output-dir <path> [OPTIONS]
Arguments:
input_file: (Positional) Path to the input file (Markdown or JSON).--to <format>: Output format. Options:pexams(default, PDF generation),rexams,wooclap,gift,md.--output-dir <path>: Directory to save the output.
Common Options (for all formats):
--log-level <level>: Set the logging level (DEBUG, INFO, WARNING, ERROR).
Options for pexams format:
--num-models <int>: Number of different exam models to generate (default: 4).--exam-title <str>: Title of the exam (default: "Final Exam").--exam-course <str>: Course name for the exam (optional).--exam-date <str>: Date of the exam (optional).--columns <int>: Number of columns for the questions (1, 2, or 3; default: 1).--font-size <str>: Base font size for the exam (e.g., '10pt', '12px'; default: '10pt').--total-students <int>: Total number of students for mass PDF generation (default: 0).--extra-model-templates <int>: Number of extra template sheets (answer sheet only) to generate per model (default: 0).--lang <str>: Language for the answer sheet labels (e.g., 'en', 'es'; default: 'en').--keep-html: If set, keeps the intermediate HTML files used for PDF generation.--generate-fakes <int>: Generates a number of simulated scans with fake answers for testing the correction process (default: 0).--generate-references: If set, generates a reference scan with the correct answers marked for each model.
pexams correct
Corrects scanned exams, runs analysis, and optionally fills marks into a student list.
pexams correct --input-path <path> --exam-dir <path> --output-dir <path> [OPTIONS]
- The
--input-pathcan be a single PDF file or a folder of images (PNG, JPG). - The
--exam-dirmust contain theexam_model_*_questions.jsonfiles generated alongside the exam PDFs.
Mark Filling Arguments:
--input-csv <path>: Path to an input CSV/XLSX/TSV file containing student IDs.--id-column <name>: Column name in input file containing student IDs.--mark-column <name>: Column name to fill with marks (will be created if missing).--fuzzy-id-match <0-100>: Threshold for fuzzy matching of IDs (default 100 = exact match only).
Other Arguments:
--void-questions <str>: Comma-separated list of question numbers to exclude from scoring.--void-questions-nicely <str>: Comma-separated list of question IDs to void "nicely".
pexams test
Runs a full generate/correct/analyze cycle using bundled sample data, and tests exports and fuzzy matching.
pexams test [OPTIONS]
Python API Usage
In addition to the CLI, you can use pexams as a Python library.
1. Generating Exams
To generate exams, use the pexams.generate_exams.generate_exams function.
from pexams import generate_exams
from pexams.schemas import PexamQuestion, PexamExam
from pexams.main import _load_and_prepare_questions
# You can load questions from a MD file
# questions = _load_and_prepare_questions("path/to/your/questions.md")
# Or define them manually
questions = [
PexamQuestion(
id="q1",
text="What is 2+2?",
options=[
{"text": "4", "is_correct": True}, # First is correct
{"text": "3", "is_correct": False},
]
)
]
# Generate 2 exam models and save them in the ./my_exams directory
generate_exams.generate_exams(
questions=questions,
output_dir="./my_exams",
num_models=2,
exam_title="Quiz 1"
)
2. Correcting Exams
To correct exams, you first need to load the solutions that were generated, then call pexams.correct_exams.correct_exams.
from pexams import correct_exams, utils
exam_dir = "./my_exams" # The output from generate_exams
solutions_full, solutions_simple, max_score = utils.load_solutions(exam_dir)
correct_exams.correct_exams(
input_path="./my_exams/simulated_scans", # Path to PDF or folder of images
solutions_per_model=solutions_simple,
output_dir="./correction_output"
)
3. Analyzing Results
After correction, you can run the analysis using pexams.analysis.analyze_results.
from pexams import analysis
analysis.analyze_results(
csv_filepath="./correction_output/correction_results.csv",
exam_dir="./my_exams", # Automatically loads solutions
output_dir="./correction_output"
)
Contributing
Pull requests are welcome! Please feel free to submit an issue or pull request.
Contact
oscar.pellicer at uv dot es
TODO
- Create a set of layouts allowing for more answers per question, or overall more questions (more compact), etc.
- Allow to add extra content to the questions sheets either before or after them, such as images, code, a table, etc.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pexams-0.7.0.tar.gz.
File metadata
- Download URL: pexams-0.7.0.tar.gz
- Upload date:
- Size: 100.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
477bf0ba5c7670a34a0ec34400ce618f8568e9b64dbe5a150e38f9b91170f49b
|
|
| MD5 |
9af0844706daff0120078dc2d1b6d725
|
|
| BLAKE2b-256 |
f18f1726c468228e1c3dc7da288998b0c8514522a63bc24274521674d0881116
|
File details
Details for the file pexams-0.7.0-py3-none-any.whl.
File metadata
- Download URL: pexams-0.7.0-py3-none-any.whl
- Upload date:
- Size: 99.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
df610d8472ee516c5d31631e4ca6e887030cc834e892e704d2ad5094f9e9f290
|
|
| MD5 |
27e6b4b0f0202ef2233f190141bcf43d
|
|
| BLAKE2b-256 |
a60a267ab58e04862d17859b66754396af2924d25a05e4584c7a018d94ee365e
|







