Execute composable AI methods declared in the MTHDS open standard
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

Executable AI Methods
Pipelex is the reference Python runtime and Claude Code plugin for the MTHDS open standard.
Readable by humans, executable by agents. No boilerplate, no lock-in.
An AI method is a multi-step workflow that chains LLMs, OCR, image generation, and more — each step typed and validated.
Executable means each method becomes a new tool — agents and skills can call it, and it also runs standalone via CLI, Python, or REST API.









Quick Start
Path A: With Claude Code (Recommended)
Install the MTHDS skills plugin:
/plugin marketplace add mthds-ai/skills
/plugin install mthds@mthds-ai-skills
Build your first method:
/mthds-build A method to analyze a Job offer to build a scorecard, then batch process CVs to score them, if a CV fits, generate 5 questions for the interview, otherwise draft a rejection email
Run it:
/mthds-run
Path B: Without Claude Code
pip install pipelex
pipelex init
Then:
- Install the VS Code extension for
.mthdssyntax highlighting - Browse methods on the MTHDS Hub for inspiration
- Author your own
.mthdsmethods based on these examples - Validate with
pipelex validate bundle your_method.mthds - Run them with
pipelex run bundle your_method.mthds - View the flowchart in VS Code thanks to the extension
- Use the
mthdsnpm package to package and publish methods on the hub
Configure AI Access
To run methods with AI models, choose one of these options:
Option A: Pipelex Gateway (Recommended)
Get free credits with a single API key for LLMs, document extraction, and image generation across all major providers (OpenAI, Anthropic, Google, Azure, and more).
- Get your API key at app.pipelex.com
- Add it to your
.envfile:PIPELEX_GATEWAY_API_KEY=your-key-here - Run
pipelex initand accept the Gateway terms of service
Option B: Bring Your Own Keys
Use your existing API keys from OpenAI, Anthropic, Google, Mistral, etc. See Configure AI Providers.
Option C: Local AI
Run models locally with Ollama, vLLM, LM Studio, or llama.cpp — no API keys required. See Configure AI Providers.
Example: CV Batch Screening
cv_batch_screening.mthds
[concept.CandidateProfile]
description = "A structured summary of a job candidate's professional background extracted from their CV."
[concept.CandidateProfile.structure]
skills = { type = "text", description = "Technical and soft skills possessed by the candidate", required = true }
experience = { type = "text", description = "Work history and professional experience", required = true }
education = { type = "text", description = "Educational background and qualifications", required = true }
achievements = { type = "text", description = "Notable accomplishments and certifications" }
[concept.JobRequirements]
description = "A structured summary of what a job position requires from candidates."
[concept.JobRequirements.structure]
required_skills = { type = "text", description = "Skills that are mandatory for the position", required = true }
responsibilities = { type = "text", description = "Main duties and tasks of the role", required = true }
qualifications = { type = "text", description = "Required education, certifications, or experience levels", required = true }
nice_to_haves = { type = "text", description = "Preferred but not mandatory qualifications" }
[concept.CandidateMatch]
description = "An evaluation of how well a candidate fits a job position."
[concept.CandidateMatch.structure]
match_score = { type = "number", description = "Numerical score representing overall fit percentage between 0 and 100", required = true }
strengths = { type = "text", description = "Areas where the candidate meets or exceeds requirements", required = true }
gaps = { type = "text", description = "Areas where the candidate falls short of requirements", required = true }
overall_assessment = { type = "text", description = "Summary evaluation of the candidate's suitability", required = true }
[pipe.batch_analyze_cvs_for_job_offer]
type = "PipeSequence"
description = """
Main orchestrator pipe that takes a bunch of CVs and a job offer in PDF format, and analyzes how they match.
"""
inputs = { cvs = "Document[]", job_offer_pdf = "Document" }
output = "CandidateMatch[]"
steps = [
{ pipe = "prepare_job_offer", result = "job_requirements" },
{ pipe = "process_cv", batch_over = "cvs", batch_as = "cv_pdf", result = "match_analyses" },
]
Click to view the supporting pipes implementation
[pipe.prepare_job_offer]
type = "PipeSequence"
description = """
Extracts and analyzes the job offer PDF to produce structured job requirements.
"""
inputs = { job_offer_pdf = "Document" }
output = "JobRequirements"
steps = [
{ pipe = "extract_one_job_offer", result = "job_offer_pages" },
{ pipe = "analyze_job_requirements", result = "job_requirements" },
]
[pipe.extract_one_job_offer]
type = "PipeExtract"
description = "Extracts text content from the job offer PDF document"
inputs = { job_offer_pdf = "Document" }
output = "Page[]"
model = "@default-text-from-pdf"
[pipe.analyze_job_requirements]
type = "PipeLLM"
description = """
Parses and summarizes the job requirements from the extracted job offer content, identifying required skills, responsibilities, qualifications, and nice-to-haves
"""
inputs = { job_offer_pages = "Page" }
output = "JobRequirements"
model = "$writing-factual"
system_prompt = """
You are an expert HR analyst specializing in parsing job descriptions. Your task is to extract and summarize job requirements into a structured format.
"""
prompt = """
Analyze the following job offer content and extract the key requirements for the position.
@job_offer_pages
"""
[pipe.process_cv]
type = "PipeSequence"
description = "Processes one application"
inputs = { cv_pdf = "Document", job_requirements = "JobRequirements" }
output = "CandidateMatch"
steps = [
{ pipe = "extract_one_cv", result = "cv_pages" },
{ pipe = "analyze_one_cv", result = "candidate_profile" },
{ pipe = "analyze_match", result = "match_analysis" },
]
[pipe.extract_one_cv]
type = "PipeExtract"
description = "Extracts text content from the CV PDF document"
inputs = { cv_pdf = "Document" }
output = "Page[]"
model = "@default-text-from-pdf"
[pipe.analyze_one_cv]
type = "PipeLLM"
description = """
Parses and summarizes the candidate's professional profile from the extracted CV content, identifying skills, experience, education, and achievements
"""
inputs = { cv_pages = "Page" }
output = "CandidateProfile"
model = "$writing-factual"
system_prompt = """
You are an expert HR analyst specializing in parsing and summarizing candidate CVs. Your task is to extract and structure the candidate's professional profile into a structured format.
"""
prompt = """
Analyze the following CV content and extract the candidate's professional profile.
@cv_pages
"""
[pipe.analyze_match]
type = "PipeLLM"
description = """
Evaluates how well the candidate matches the job requirements, calculating a match score and identifying strengths and gaps
"""
inputs = { candidate_profile = "CandidateProfile", job_requirements = "JobRequirements" }
output = "CandidateMatch"
model = "$writing-factual"
system_prompt = """
You are an expert HR analyst specializing in candidate-job fit evaluation. Your task is to produce a structured match analysis comparing a candidate's profile against job requirements.
"""
prompt = """
Analyze how well the candidate matches the job requirements. Evaluate their fit by comparing their skills, experience, and qualifications against what the position demands.
@candidate_profile
@job_requirements
Provide a comprehensive match analysis including a numerical score, identified strengths, gaps, and an overall assessment.
"""
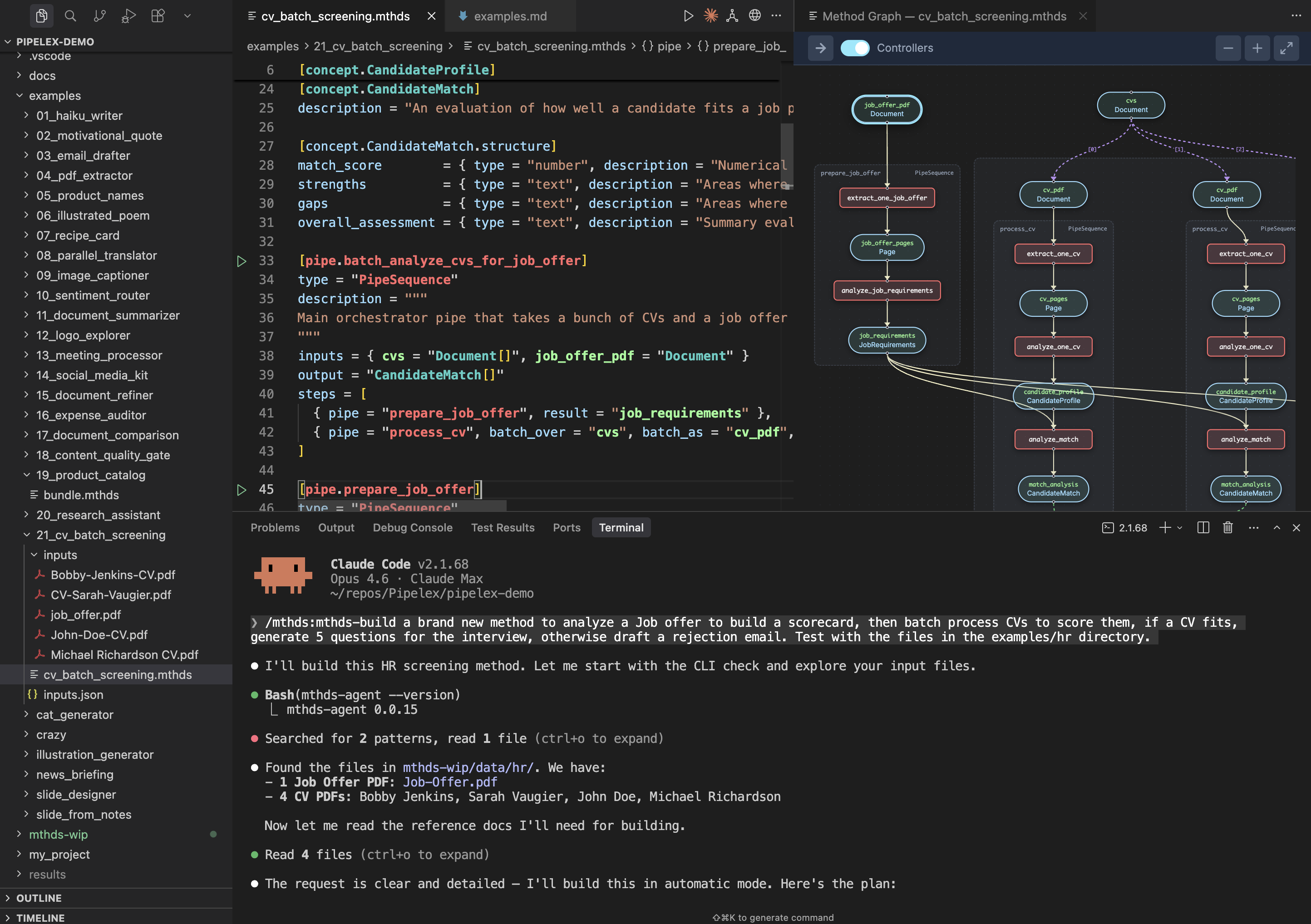
View the pipeline flowchart:
flowchart LR
%% Pipe and stuff nodes within controller subgraphs
subgraph sg_n_8b2136e3fe["batch_analyze_cvs_for_job_offer"]
subgraph sg_n_91d5d6dc7c["prepare_job_offer"]
n_fde22777cb["analyze_job_requirements"]
s_f9f703fbb4(["job_requirements<br/>JobRequirements"]):::stuff
n_b8469c838f["extract_one_job_offer"]
s_d998350046(["job_offer_pages<br/>Page"]):::stuff
end
subgraph sg_n_f8d5afb7cd["process_cv_batch"]
subgraph sg_n_6e53e16369["process_cv"]
n_c18aded200["analyze_match"]
s_5c911f7e54(["match_analysis<br/>CandidateMatch"]):::stuff
n_a7ed00ac24["analyze_one_cv"]
s_c5ae714e89(["candidate_profile<br/>CandidateProfile"]):::stuff
n_d24f39aa60["extract_one_cv"]
s_427beb5195(["cv_pdf<br/>Document"]):::stuff
s_f1f80289df(["cv_pages<br/>Page"]):::stuff
end
subgraph sg_n_2cfb7a32c8["process_cv"]
n_f6a25d1769["analyze_match"]
s_ea99eee6ed(["match_analysis<br/>CandidateMatch"]):::stuff
n_f48b73fbee["analyze_one_cv"]
s_e1ffee913e(["candidate_profile<br/>CandidateProfile"]):::stuff
n_d16f2fe381["extract_one_cv"]
s_041bb18fb4(["cv_pdf<br/>Document"]):::stuff
s_5fbba7194a(["cv_pages<br/>Page"]):::stuff
end
subgraph sg_n_08a7186be9["process_cv"]
n_937e750ea4["analyze_match"]
s_bb41a103f0(["match_analysis<br/>CandidateMatch"]):::stuff
n_786a2969d5["analyze_one_cv"]
s_c47fe821d7(["candidate_profile<br/>CandidateProfile"]):::stuff
n_38f0cfd11c["extract_one_cv"]
s_2634ece93d(["cv_pdf<br/>Document"]):::stuff
s_44e253b325(["cv_pages<br/>Page"]):::stuff
end
end
end
%% Pipeline input stuff nodes (no producer)
s_9b7e74ac51(["job_offer_pdf<br/>Document"]):::stuff
%% Data flow edges: producer -> stuff -> consumer
n_a7ed00ac24 --> s_c5ae714e89
n_b8469c838f --> s_d998350046
n_f48b73fbee --> s_e1ffee913e
n_d16f2fe381 --> s_5fbba7194a
n_fde22777cb --> s_f9f703fbb4
n_d24f39aa60 --> s_f1f80289df
n_38f0cfd11c --> s_44e253b325
n_786a2969d5 --> s_c47fe821d7
n_c18aded200 --> s_5c911f7e54
n_f6a25d1769 --> s_ea99eee6ed
n_937e750ea4 --> s_bb41a103f0
s_c5ae714e89 --> n_c18aded200
s_9b7e74ac51 --> n_b8469c838f
s_d998350046 --> n_fde22777cb
s_e1ffee913e --> n_f6a25d1769
s_427beb5195 --> n_d24f39aa60
s_041bb18fb4 --> n_d16f2fe381
s_2634ece93d --> n_38f0cfd11c
s_5fbba7194a --> n_f48b73fbee
s_f9f703fbb4 --> n_c18aded200
s_f9f703fbb4 --> n_f6a25d1769
s_f9f703fbb4 --> n_937e750ea4
s_f1f80289df --> n_a7ed00ac24
s_44e253b325 --> n_786a2969d5
s_c47fe821d7 --> n_937e750ea4
%% Batch edges: list-item relationships
s_52d84618d0(["match_analyses<br/>CandidateMatch"]):::stuff
s_5c911f7e54 -."[0]".-> s_52d84618d0
s_ea99eee6ed -."[1]".-> s_52d84618d0
s_bb41a103f0 -."[2]".-> s_52d84618d0
%% Style definitions
classDef failed fill:#ffcccc,stroke:#cc0000
classDef stuff fill:#fff3e6,stroke:#cc6600,stroke-width:2px
classDef controller fill:#e6f3ff,stroke:#0066cc
%% Subgraph depth-based coloring
style sg_n_08a7186be9 fill:#fffde6
style sg_n_2cfb7a32c8 fill:#fffde6
style sg_n_6e53e16369 fill:#fffde6
style sg_n_8b2136e3fe fill:#e6f3ff
style sg_n_91d5d6dc7c fill:#e6ffe6
style sg_n_f8d5afb7cd fill:#e6ffe6
Run Your Method
Via CLI:
pipelex run bundle cv_batch_screening.mthds --inputs inputs.json
Create an inputs.json file with your PDF URLs:
{
"cvs": {
"concept": "native.Document",
"content": [
{ "url": "https://pipelex-web.s3.amazonaws.com/demo/John-Doe-CV.pdf" },
{ "path": "inputs/Jane-Smith-CV.pdf" }
]
},
"job_offer_pdf": {
"concept": "native.Document",
"content": {
"url": "https://pipelex-web.s3.amazonaws.com/demo/Job-Offer.pdf"
}
}
}
Via Python:
import asyncio
from pipelex.core.stuffs.document_content import DocumentContent
from pipelex.pipelex import Pipelex
from pipelex.pipeline.runner import PipelexRunner
# Generated by: `pipelex build structures bundle cv_batch_screening.mthds`
from structures.cv_batch_screening__candidate_match import CandidateMatch
async def run_pipeline() -> list[CandidateMatch]:
runner = PipelexRunner()
response = await runner.execute_pipeline(
pipe_code="batch_analyze_cvs_for_job_offer",
inputs={
"cvs": {
"concept": "Document",
"content": [
DocumentContent(url="https://pipelex-web.s3.amazonaws.com/demo/John-Doe-CV.pdf"),
DocumentContent(path="inputs/Jane-Smith-CV.pdf"),
],
},
"job_offer_pdf": {
"concept": "native.Document",
"content": DocumentContent(url="https://pipelex-web.s3.amazonaws.com/demo/Job-Offer.pdf"),
},
},
)
pipe_output = response.pipe_output
print(pipe_output)
return pipe_output.main_stuff_as_items(item_type=CandidateMatch)
Pipelex.make()
asyncio.run(run_pipeline())
What is Pipelex?
Pipelex is the reference Python runtime for executing AI methods defined in the MTHDS open standard. It separates what a method does from how it runs — you declare intent, the runtime handles execution.
MTHDS is a typed, declarative language built on two primitives:
- Concepts — semantically typed data, named after real domain things (
ContractClause,CandidateProfile,Invoice) - Pipes — typed transformations with explicit inputs and outputs (LLM calls, extraction, image generation, branching, batching)
Methods are readable by domain experts, executable by agents, versionable in Git, and portable across runtimes. The .mthds format is TOML-based — no framework lock-in, no boilerplate.
The sweet spot between code and agent skills:
| Code | MTHDS | Agent Skills | |
|---|---|---|---|
| Control | Total control, total effort | Structured freedom, open standard | Total freedom, no guarantees |
| Time to production | Days, 80% boilerplate | Minutes, zero boilerplate | Minutes, different result every run |
| Validation | Deterministic, testable | Typed schemas, validated before runtime | No validation, no audit trail |
| Audience | Developers only | Engineers and domain experts | Anyone |
Agent-first by design: The Claude Code plugin lets agents write, edit, run, and compose methods. A domain expert who can describe what they need in plain language can have Claude author the method, which then runs consistently, is testable, and lives in version control.
The MTHDS Ecosystem
| Description | Link | |
|---|---|---|
| MTHDS Standard | The open standard specification — language, package system, and typed concepts | mthds.ai |
| MTHDS Hub | Discover and share methods — browse packages, search by signature | mthds.sh |
| Skills Plugin | Claude Code plugin — 11 commands to build, run, edit, check, fix, and publish methods | github.com/mthds-ai/skills |
| Package System | Versioned dependencies, lock files with SHA-256 integrity, cross-package references via -> |
Packages docs |
| Know-How Graph | Typed discovery — "I have X, I need Y" — find methods or chains by typed signature | Know-How Graph |
Skills Plugin Commands
| Command | Description |
|---|---|
/mthds-build |
Build new AI method bundles from scratch |
/mthds-run |
Execute methods and interpret their JSON output |
/mthds-edit |
Modify existing methods — change pipes, update prompts, add steps |
/mthds-check |
Validate bundles for issues (read-only) |
/mthds-fix |
Auto-fix validation errors |
/mthds-explain |
Walk through execution flow in plain language |
/mthds-inputs |
Prepare inputs: templates, synthetic data, user files |
/mthds-install |
Install method packages from GitHub or local dirs |
/mthds-pkg |
Package management — init, deps, lock, install, update |
/mthds-publish |
Publish methods to the hub |
/mthds-share |
Share methods on social media |
See Pipelex in Action
Claude Code builds your AI Method
|
IDE Extension
We highly recommend installing our extension for .mthds syntax highlighting in your IDE:
- VS Code: Install from the VS Code Marketplace
- Cursor, Windsurf, and other VS Code forks: Install from the Open VSX Registry, or search for "Pipelex" directly in your extensions tab
Running pipelex init will also offer to install the extension automatically if it detects your IDE.
Examples & Cookbook
Explore real-world examples in our Cookbook repository:
Clone it, fork it, and experiment with production-ready methods for various use cases.
Run Anywhere
The same .mthds file runs from multiple execution targets:
| Target | How |
|---|---|
| CLI | pipelex run bundle method.mthds --inputs inputs.json |
| Python | PipelexRunner().execute_pipeline(...) |
| REST API | Self-hosted API server |
| MCP | Model Context Protocol — agents call methods as tools |
| n8n | Pipelex node for workflow automation |
Optional Features
The package supports the following additional features:
anthropic: Anthropic/Claude support for text generationgoogle: Google models (Vertex) support for text generationmistralai: Mistral AI support for text generation and OCRbedrock: Amazon Bedrock support for text generationfal: Image generation with Black Forest Labs "FAL" servicelinkup: Web search with Linkupdocling: OCR with Docling
Install all extras:
pip install "pipelex[anthropic,google,google-genai,mistralai,bedrock,fal,linkup,docling]"
Privacy & Telemetry
Pipelex supports two independent telemetry streams:
- Gateway Telemetry: When using Pipelex Gateway, telemetry must be enabled (tied to your hashed API key) to monitor service quality and enforce fair usage. Learn more
- Custom Telemetry: User-controlled via
.pipelex/telemetry.tomlfor your own observability systems (Langfuse, PostHog, OTLP). Learn more
We only collect technical data (model names, token counts, latency, error rates) — never your prompts, completions, or business data. Set DO_NOT_TRACK=1 to disable all telemetry (note: Gateway requires telemetry to function).
For more details, see the Telemetry Documentation or read our Privacy Policy.
Contributing
We welcome contributions! Please see our Contributing Guidelines for details on how to get started, including development setup and testing information.
Join the Community
Join our vibrant Discord community to connect with other developers, share your experiences, and get help with your Pipelex projects!
Support
- GitHub Issues: For bug reports and feature requests
- Discussions: For questions and community discussions
- Documentation
Star Us!
If you find Pipelex helpful, please consider giving us a star! It helps us reach more developers and continue improving the tool.
License
This project is licensed under the MIT license. Runtime dependencies are distributed under their own licenses via PyPI.
"Pipelex" is a trademark of Evotis S.A.S.
© 2026 Evotis S.A.S.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pipelex-0.20.3.tar.gz.
File metadata
- Download URL: pipelex-0.20.3.tar.gz
- Upload date:
- Size: 721.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
eb8ce553e2c6ef6d47cc9eef8ab29d458a03058e29cea73be523986dec428469
|
|
| MD5 |
65fb57f7e71d8ec31c19094364b7d3b5
|
|
| BLAKE2b-256 |
e7e6af22553b7ffb8331fbc86bb09041d15fc9dfefbdbf243952c9baee27b491
|
Provenance
The following attestation bundles were made for pipelex-0.20.3.tar.gz:
Publisher:
publish-pypi.yml on Pipelex/pipelex
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pipelex-0.20.3.tar.gz -
Subject digest:
eb8ce553e2c6ef6d47cc9eef8ab29d458a03058e29cea73be523986dec428469 - Sigstore transparency entry: 1032981857
- Sigstore integration time:
-
Permalink:
Pipelex/pipelex@7e918910e5c4b376992dda9e764c84f0ea7d162f -
Branch / Tag:
refs/heads/main - Owner: https://github.com/Pipelex
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@7e918910e5c4b376992dda9e764c84f0ea7d162f -
Trigger Event:
pull_request
-
Statement type:
File details
Details for the file pipelex-0.20.3-py3-none-any.whl.
File metadata
- Download URL: pipelex-0.20.3-py3-none-any.whl
- Upload date:
- Size: 1.1 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4c1eb25ef135b18a49a8708b36824e098b45273a9687fab10d6e23ad9f047da3
|
|
| MD5 |
6a1fd1941b37f21209af95523d1b6da0
|
|
| BLAKE2b-256 |
15122b95fe8bf20365df91359f2cf670d60a7e32bebc96baf3a7b0d71975929b
|
Provenance
The following attestation bundles were made for pipelex-0.20.3-py3-none-any.whl:
Publisher:
publish-pypi.yml on Pipelex/pipelex
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pipelex-0.20.3-py3-none-any.whl -
Subject digest:
4c1eb25ef135b18a49a8708b36824e098b45273a9687fab10d6e23ad9f047da3 - Sigstore transparency entry: 1032981925
- Sigstore integration time:
-
Permalink:
Pipelex/pipelex@7e918910e5c4b376992dda9e764c84f0ea7d162f -
Branch / Tag:
refs/heads/main - Owner: https://github.com/Pipelex
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@7e918910e5c4b376992dda9e764c84f0ea7d162f -
Trigger Event:
pull_request
-
Statement type:







