Generate multi-table relational datasets with behavioral trajectories, correlations, and causal lags. Config-driven, deterministic, no real data required
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description






Python library to generate synthetic multi-table relational datasets — star schema, correlated metrics, dbt-seed-ready CSV & Parquet. Config-driven, deterministic, no real data required
pip install plotsim
plotsim generates multi-table relational datasets from a behavioral description. You define metrics, segments, and how entities behave over time — the engine produces a star schema where every value traces back to one trajectory. shape: every entity follows a behavioral trajectory, and every metric across every table reads from the same trajectory position. When engagement rises, revenue follows. When it declines, churn fires.
Quick start
from plotsim import create, generate_tables
cfg = create(
about="Subscription customers",
unit="customer",
window=("2024-01", "2024-12", "monthly"),
metrics=[
{"name": "engagement", "type": "score", "polarity": "positive"},
{"name": "payments", "type": "count", "polarity": "positive"},
],
segments=[
{"name": "active", "count": 50, "archetype": "growth"},
{"name": "inactive", "count": 30, "archetype": "decline"},
],
)
tables = generate_tables(cfg)
for name, df in tables.items():
print(f"{name}: {len(df)} rows")
# dim_date: 12 rows
# dim_customer: 80 rows
# fct_customer: 960 rows
Generate multi-table synthetic data
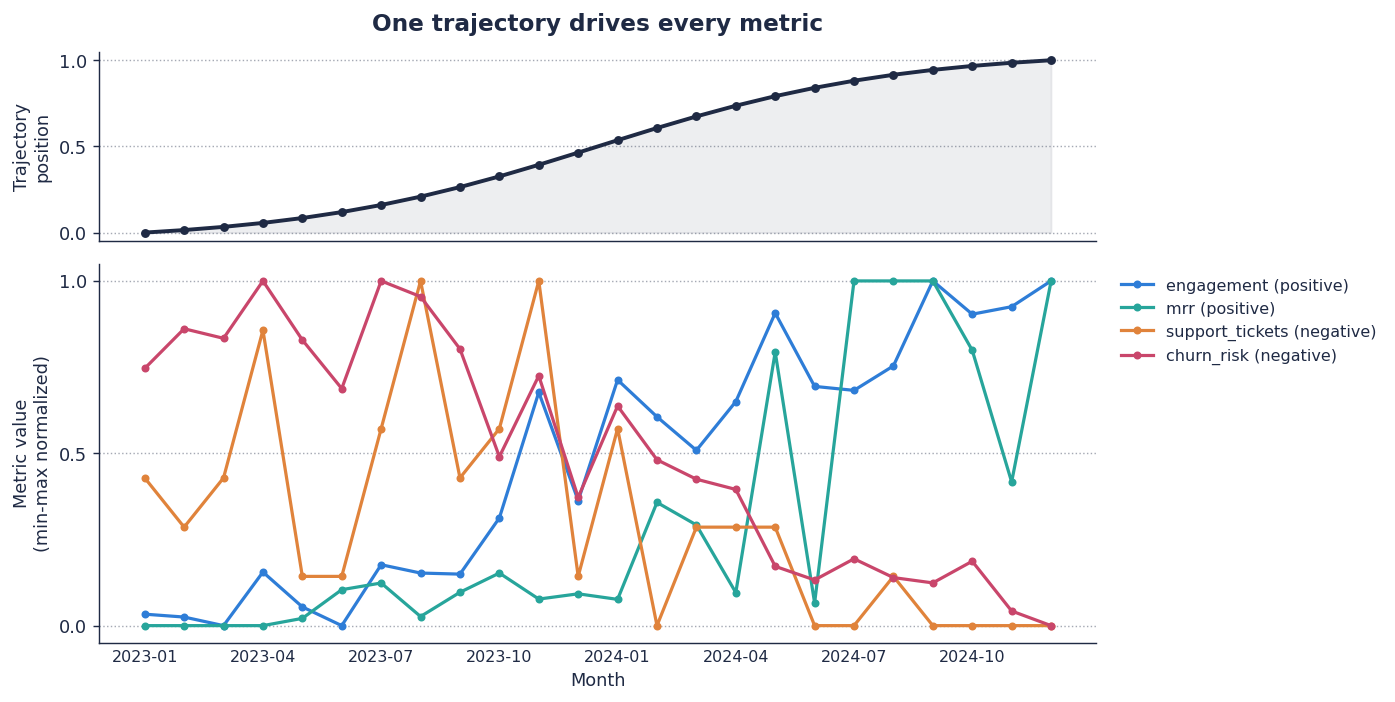
Top panel: one trajectory for one customer, 24 months. Bottom panel: four metrics on the same x-axis. Engagement and MRR rise with the trajectory; support tickets and churn risk fall as it rises. Every value reads from that one curve.
The same idea in tables — one company, twelve months, the same SaaS schema generated two ways:
Random columns (Faker-style) — every column is independent. The numbers don't agree.
| month | engagement | mrr | tickets | churn_risk |
|---|---|---|---|---|
| 2024-01 | 0.842 | $483 | 7 | 0.611 |
| 2024-02 | 0.117 | $4,201 | 0 | 0.043 |
| 2024-03 | 0.674 | $1,089 | 11 | 0.892 |
| 2024-04 | 0.298 | $112 | 2 | 0.355 |
| 2024-05 | 0.951 | $7,733 | 4 | 0.018 |
| 2024-06 | 0.024 | $964 | 9 | 0.477 |
| 2024-07 | 0.560 | $2,154 | 1 | 0.802 |
| 2024-08 | 0.405 | $328 | 6 | 0.220 |
| 2024-09 | 0.789 | $617 | 0 | 0.998 |
| 2024-10 | 0.131 | $5,440 | 8 | 0.156 |
| 2024-11 | 0.847 | $192 | 3 | 0.501 |
| 2024-12 | 0.334 | $3,876 | 12 | 0.063 |
Engagement at 0.95 with churn risk near zero, then 0.79 at the highest churn risk in the table. No story — only fields filled.
plotsim (trajectory-correlated) — plotsim run saas. Same dim_company row, twelve monthly rows from fct_engagement, fct_revenue, fct_support_tickets.
| month | engagement | mrr | tickets | churn_risk |
|---|---|---|---|---|
| 2024-01 | 0.587 | $1,191 | 0 | 0.261 |
| 2024-02 | 0.807 | $1,265 | 1 | 0.189 |
| 2024-03 | 1.000 | $3,532 | 2 | 0.129 |
| 2024-04 | 0.593 | $818 | 0 | 0.171 |
| 2024-05 | 0.904 | $3,567 | 2 | 0.237 |
| 2024-06 | 0.956 | $4,264 | 1 | 0.257 |
| 2024-07 | 1.000 | $302 | 2 | 0.000 |
| 2024-08 | 0.917 | $1,507 | 0 | 0.000 |
| 2024-09 | 1.000 | $890 | 1 | 0.000 |
| 2024-10 | 0.783 | $512 | 1 | 0.264 |
| 2024-11 | 0.956 | $837 | 0 | 0.000 |
| 2024-12 | 0.827 | $351 | 1 | 0.248 |
Engagement is climbing toward its plateau. MRR moves with it. Support tickets stay low. Churn risk stays near zero. All four columns read from the same underlying trajectory position — not from four independent random generators.
The contrast is the entire product.
Star schema output
A plotsim run produces a complete star schema in the chosen output directory:
output/
├── dim_date.csv # complete date spine
├── dim_company.csv # entity attributes (with SCD2 plan_tier)
├── dim_user.csv # sub-entity attributes
├── dim_plan.csv # reference lookup
├── fct_engagement.csv # entity × period metrics
├── fct_revenue.csv # entity × period metrics
├── fct_support_tickets.csv # entity × period metrics
├── evt_login.csv # proportional events
├── evt_churn.csv # threshold-triggered events
├── config.yaml # frozen copy of the input config
└── validation_report.txt # FK + PK + spine integrity checks
If a company's engagement trajectory declines, its login rows decrease in evt_login.csv and churn events appear in evt_churn.csv — both event tables read from the same trajectory the fact tables do.
Same config + same seed produces byte-identical output every time. CSV is the default; Parquet is one config flag away. See the output guide for format details and the manifest schema.
Who is this for
Educators and students who need realistic datasets for SQL courses, data modeling workshops, analytics training, or portfolio projects — six bundled templates ready to go, same seed produces the same data every time.
Data engineers who need test fixtures that behave like production data — with FK integrity, realistic distributions, and configurable corruption — without copying production or hand-rolling three-row CSVs.
Data scientists who need labeled training data with known ground truth — archetype labels, trajectory positions, and temporal holdout splits — to validate models before touching real data.
Analytics engineers who need a star schema to build dbt models, test transformations, or demonstrate a pipeline end-to-end without waiting for upstream data.
BI and analytics teams who need a populated star schema to build dashboards, test reports, or demo a new tool to stakeholders — dims, facts, events, and SCD versioning out of the box.
Demo builders who need a convincing dataset for a conference talk, a product walkthrough, or a proof of concept — correlated metrics that tell a realistic story, not random noise.
How it works

Every entity in the dataset follows a behavioral trajectory — a curve shape like growth, decline, seasonal, or spike-then-crash. At each time period, the entity's position on that curve determines every metric value across every table. Revenue, engagement, churn risk, and support tickets all read from the same position, so they move together the way real business metrics do.
Metric relationships are enforced through a Gaussian copula —
declare engagement opposes churn_risk and the engine delivers the
configured correlation coefficient regardless of whether one metric
is beta-distributed and the other is Poisson. Causal lags compose:
if A → B (lag 2) → C (lag 3), then C reflects A from 5 periods ago.
Output is deterministic. Every random draw flows through a single
seeded numpy.Generator. Same config + same seed = byte-identical
tables within the same Python and dependency versions. The manifest records
every generation decision — archetype assignments, trajectory
positions, correlation adjustments, quality injections — so any
cell value can be traced back to its origin.
Config-time validation catches problems before generation starts: circular causal chains, non-positive-definite correlation matrices, broken foreign key references, duplicate metric names, and SQL-unsafe identifiers all surface as parse errors with fix suggestions.
See the docs site for the full pipeline.
Docs
mohossam01.github.io/plotsim — quickstart, user guide, tutorials, API reference, cookbooks.
Contributing
See CONTRIBUTING.md for dev setup, test commands, and how to add templates.
License
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file plotsim-0.7.0.tar.gz.
File metadata
- Download URL: plotsim-0.7.0.tar.gz
- Upload date:
- Size: 770.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
24e80b0f568f758568d563c070fe7a9a11683eb5371f8cae8ffe31314f49c140
|
|
| MD5 |
9c69e8606db45e084a1907065397d664
|
|
| BLAKE2b-256 |
ca9e8d59de9eedeb9e6efe7e68ef8120f9fbe379c4a65b15cc525c67a9ee2fac
|
Provenance
The following attestation bundles were made for plotsim-0.7.0.tar.gz:
Publisher:
release.yml on mohossam01/plotsim
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
plotsim-0.7.0.tar.gz -
Subject digest:
24e80b0f568f758568d563c070fe7a9a11683eb5371f8cae8ffe31314f49c140 - Sigstore transparency entry: 1606637389
- Sigstore integration time:
-
Permalink:
mohossam01/plotsim@d7954a82e1b0c41cfe57cdb1b89e543853c1c28e -
Branch / Tag:
refs/heads/main - Owner: https://github.com/mohossam01
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@d7954a82e1b0c41cfe57cdb1b89e543853c1c28e -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file plotsim-0.7.0-py3-none-any.whl.
File metadata
- Download URL: plotsim-0.7.0-py3-none-any.whl
- Upload date:
- Size: 405.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
47d171a6779f23a7045eb8f1a98dd9b9be98b8be181f08dd8ae1ac3d3cb11424
|
|
| MD5 |
c471227e8c5fa80f2fc664f220f13721
|
|
| BLAKE2b-256 |
86fb2924da7bbc2b7df81c3dd56a62d29167a8869c516fea92ee57a78dd7b968
|
Provenance
The following attestation bundles were made for plotsim-0.7.0-py3-none-any.whl:
Publisher:
release.yml on mohossam01/plotsim
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
plotsim-0.7.0-py3-none-any.whl -
Subject digest:
47d171a6779f23a7045eb8f1a98dd9b9be98b8be181f08dd8ae1ac3d3cb11424 - Sigstore transparency entry: 1606637562
- Sigstore integration time:
-
Permalink:
mohossam01/plotsim@d7954a82e1b0c41cfe57cdb1b89e543853c1c28e -
Branch / Tag:
refs/heads/main - Owner: https://github.com/mohossam01
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@d7954a82e1b0c41cfe57cdb1b89e543853c1c28e -
Trigger Event:
workflow_dispatch
-
Statement type:







