A package for simulating population protocols.


Project description
ppsim Python package
The ppsim package is used for simulating population protcols. The core of the simulator uses a batching algorithm which gives significant asymptotic gains for protocols with relatively small reachable state sets. The package is designed to be run in a Python notebook, to concisely describe complex protocols, efficiently simulate their dynamics, and provide helpful visualization of the simulation.
Installation
The package can be installed with pip via
pip install ppsim
Found existing installation: ppsim 0.0.5
Can't uninstall 'ppsim'. No files were found to uninstall.
Note: you may need to restart the kernel to use updated packages.
The most important part of the package is the Simulation class, which is responsible for parsing a protocol, performing the simulation, and giving data about the simulation.
from ppsim import Simulation
Example protcol
A state can be any hashable Python object. The simplest way to describe a protocol is a dictionary mapping pairs of input states to pairs of output states.
For example, here is a description of the classic 3-state approximate majority protocol. There are two initial states A and B, and the protocol converges with high probability to the majority state with the help of a third "undecided" state U.
a, b, u = 'A', 'B', 'U'
approximate_majority = {
(a,b): (u,u),
(a,u): (a,a),
(b,u): (b,b)
}
Example Simulation
To instantiate a Simulation, we must specify a protocol along with an initial condition, which is a dictionary mapping states to counts. Let's simulate approximate majority with in a population of one billion agents with a slight majority of A agents.
n = 10 ** 9
init_config = {a: 0.501 * n, b: 0.499 * n}
sim = Simulation(init_config, approximate_majority)
Now let's run this simulation for 10 units of parallel time (10 * n interactions). We will record the configuration every 0.1 units of time.
sim.run(10, 0.1)
Time: 10.002
The Simulation class can display all these configurations in a pandas dataframe in the attribute history.
sim.history
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| A | B | U | |
|---|---|---|---|
| time | |||
| 0.000000 | 501000000 | 499000000 | 0 |
| 0.100019 | 478280568 | 476279336 | 45440096 |
| 0.200020 | 459452270 | 457437245 | 83110485 |
| 0.300020 | 443657844 | 441619960 | 114722196 |
| 0.400038 | 430275369 | 428209473 | 141515158 |
| ... | ... | ... | ... |
| 9.601563 | 352383237 | 314710447 | 332906316 |
| 9.701567 | 353031342 | 314085559 | 332883099 |
| 9.801585 | 353699490 | 313442830 | 332857680 |
| 9.901613 | 354400478 | 312787765 | 332811757 |
| 10.001624 | 355119662 | 312104917 | 332775421 |
101 rows × 3 columns
sim.history.plot()
<AxesSubplot:xlabel='time'>

Without specifying an end time, run will run the simulation until the configuration is silent (all interactions are null). In this case, that will be when the protcol reaches a silent majority consensus configuration.
sim.run()
sim.history.plot()
Time: 44.593
<AxesSubplot:xlabel='time'>

As currently described, this protocol is one-way, where these interactions only take place if the two states meet in the specified order. We can see this by printing sim.reactions.
print(sim.reactions)
A, B --> U, U with probability 0.5
A, U --> A, A with probability 0.5
B, U --> B, B with probability 0.5
Here we have unorder pairs of reactants, and the probability 0.5 is because these interactions as written depended on the order of the agents. If we wanted to consider the more sensible symmetric variant of the protocol, one approach would explicitly give all non-null interactions:
approximate_majority_symmetric = {
(a,b): (u,u), (b,a): (u,u),
(a,u): (a,a), (u,a): (a,a),
(b,u): (b,b), (u,b): (b,b)
}
sim = Simulation(init_config, approximate_majority_symmetric)
But a quicker equivalent approach is to tell Simulation that all interactions should be interpreted as symmetric, so if we specify interaction (a,b) but leave (b,a) as null, then (b,a) will be interpreted as having the same output pair.
sim = Simulation(init_config, approximate_majority, transition_order='symmetric')
print(sim.reactions)
sim.run()
sim.history.plot()
A, B --> U, U
A, U --> A, A
B, U --> B, B
Time: 23.383
<AxesSubplot:xlabel='time'>

A key result about this protocol is it converges in expected O(log n) time, which surprisingly is very nontrivial to prove. We can use this package to very quickly gather some convincing data that the convergence really is O(log n) time, with the function time_trials.
from ppsim import time_trials
import numpy as np
ns = [int(n) for n in np.geomspace(10, 10 ** 8, 20)]
def initial_condition(n):
return {'A': n // 2, 'B': n // 2}
df = time_trials(approximate_majority, ns, initial_condition, num_trials=100, max_wallclock_time = 30, transition_order='symmetric')
df
0%| | 0/20 [00:00<?, ?it/s]
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| n | time | |
|---|---|---|
| 0 | 10 | 5.600000 |
| 1 | 10 | 3.900000 |
| 2 | 10 | 5.400000 |
| 3 | 10 | 6.000000 |
| 4 | 10 | 2.900000 |
| ... | ... | ... |
| 1501 | 42813323 | 31.818947 |
| 1502 | 100000000 | 31.928544 |
| 1503 | 100000000 | 25.953497 |
| 1504 | 100000000 | 24.025694 |
| 1505 | 100000000 | 25.495013 |
1506 rows × 2 columns
This dataframe collected time from up to 100 trials for each population size n across a many orders of magnitude, limited by the budget of 30 seconds of wallclock time that we gave it.
We can now use the seaborn library to get a convincing plot of the data.
import seaborn as sns
lp = sns.lineplot(x='n', y='time', data=df)
lp.set_xscale('log')

Larger state protocol
For more complicated protocols, it would be very tedious to use this dictionary format. Instead we can give an arbitrary Python function which takes a pair of states as input (along with possible other protocol parameters) and returns a pair of states as output (or if we wanted a randomized transition, it would output a dictionary which maps pairs of states to probabilities).
As a quick example, let's take a look at the discrete averaging dynamics, as analyzed here and here, which have been a key subroutine used in counting and majority protocols.
from math import ceil, floor
def discrete_averaging(a, b):
avg = (a + b) / 2
return floor(avg), ceil(avg)
n = 10 ** 8
sim = Simulation({0: n // 2, 100: n // 2}, discrete_averaging)
We did not need to explicitly describe the state set. Upon initialization, Simulation used breadth first search to find all states reachable from the initial configuration.
print(sim.state_list)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100]
This enumeration will call the function rule we give it O(q^2) times, where q is the number of reachable states. This preprocessing step also builds an internal representation of the transition function, so it will not need to continue calling rule. Thus we don't need to worry too much about our code for rule being efficient.
Rather than the dictionary format used to input the configuration, internally Simulation represents the configuration as an array of counts, where the ordering of the indices is given by state_list.
sim.config_dict
{0: 50000000, 100: 50000000}
sim.config_array
array([50000000, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 50000000], dtype=int64)
A key result about these discrete averaging dynamics is that they converge in O(log n) time to at most 3 consecutive values. It could take longer to reach the ultimate silent configuration with only 2 consecutive values, so if we wanted to check for the faster convergence condition, we could use a function that checks for the condition. This function takes a configuration dictionary (mapping states to counts) as input and returns True if the convergence criterion has been met.
def three_consecutive_values(config):
states = config.keys()
return max(states) - min(states) <= 2
Now we can run until this condition is met (or also use time_trials as above to generate statistics about this convergence time).
sim.run(three_consecutive_values, 0.1)
sim.history
Time: 18.394
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | 100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| time | |||||||||||||||||||||
| 0.000000 | 50000000 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 50000000 |
| 0.100112 | 45011237 | 1 | 3 | 82 | 16 | 0 | 1688 | 568 | 4 | 50 | ... | 48 | 0 | 594 | 1689 | 1 | 13 | 81 | 1 | 1 | 45011888 |
| 0.200576 | 40102576 | 53 | 67 | 1627 | 270 | 77 | 18565 | 6305 | 138 | 1345 | ... | 1367 | 151 | 6180 | 18431 | 86 | 275 | 1601 | 70 | 61 | 40103660 |
| 0.301440 | 35366286 | 366 | 455 | 7533 | 1453 | 653 | 62958 | 21070 | 1029 | 7166 | ... | 7359 | 1069 | 21291 | 62942 | 720 | 1489 | 7401 | 433 | 382 | 35368065 |
| 0.402708 | 30886350 | 1310 | 1633 | 20116 | 4446 | 2507 | 133956 | 45872 | 3950 | 20640 | ... | 20753 | 3886 | 45857 | 133427 | 2571 | 4287 | 19822 | 1550 | 1233 | 30888463 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 17.993288 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 18.093388 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 18.193590 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 18.293700 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 18.393828 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
183 rows × 101 columns
With a much larger number of states, the history dataframe is more unwieldly, so trying to directly call history.plot() would be very messy and not very useful.
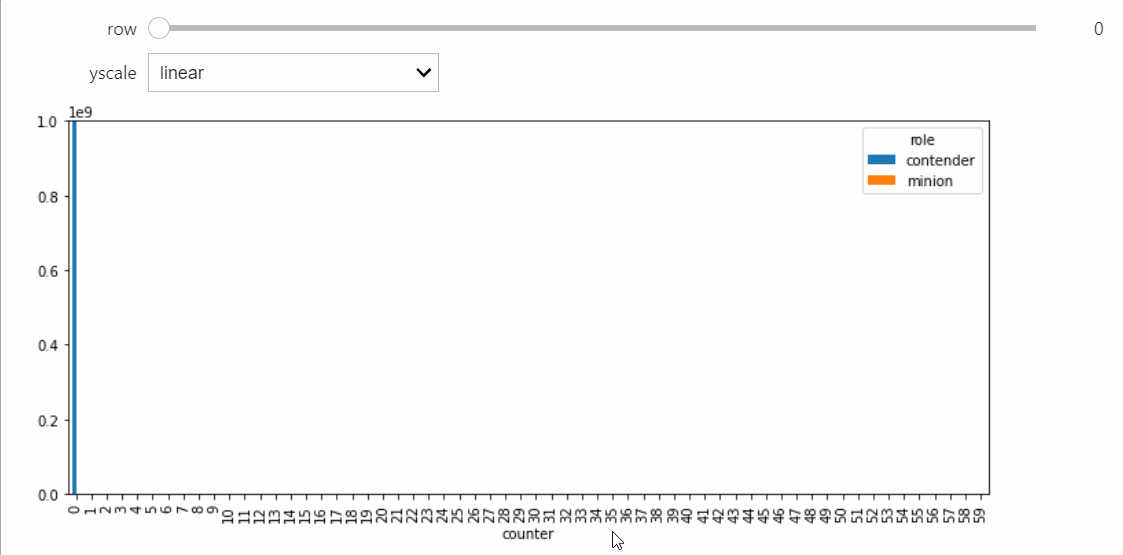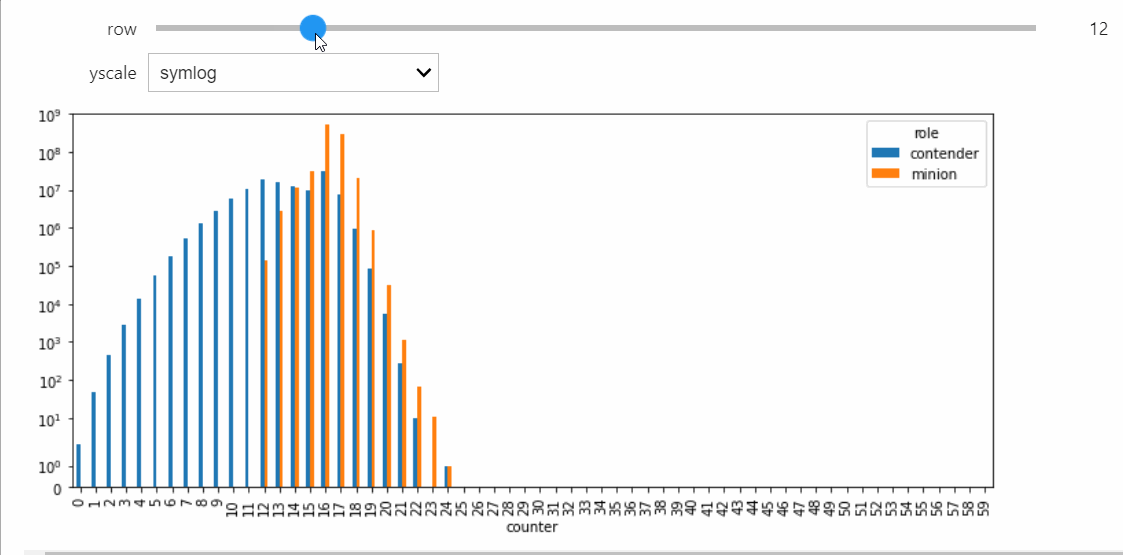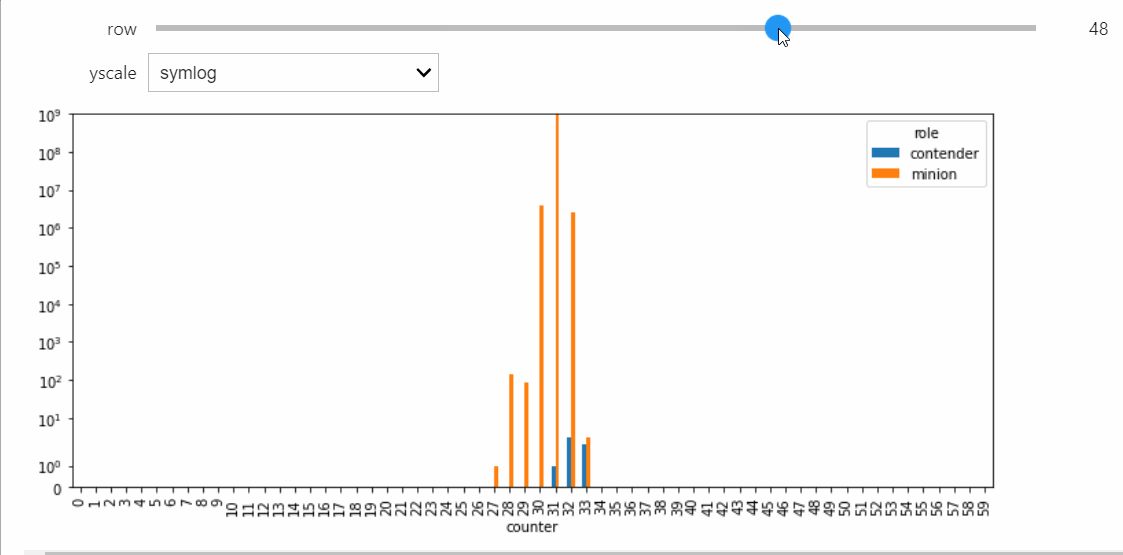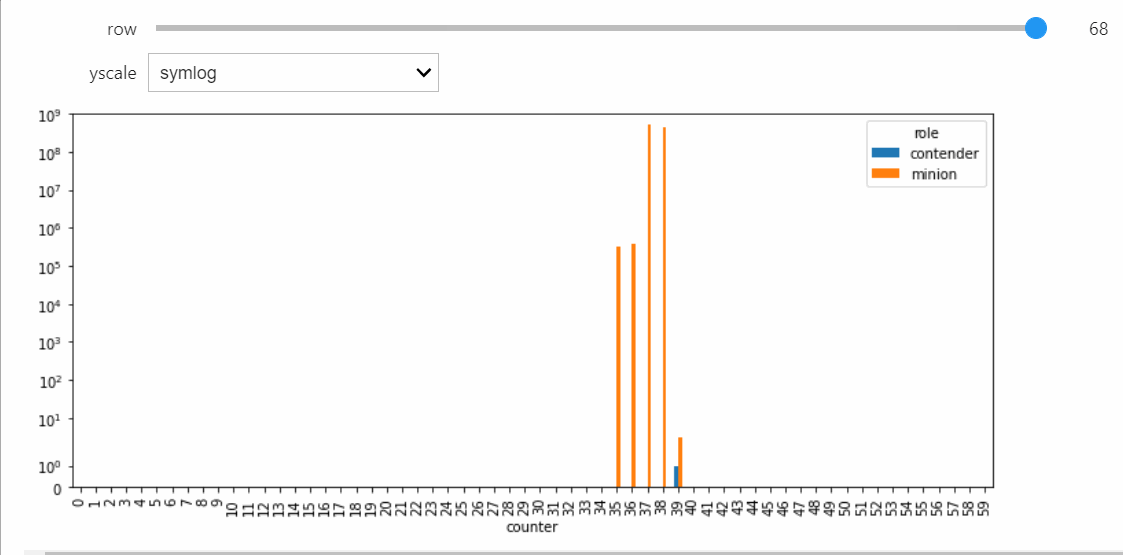
Instead we will bring in a Snapshot object that makes a bar plot with the counts of each state, and lets us visualize the way the distribution evolves over time.
For this StatePlotter object to work as intended, we need to be using an interactive matplotlib backend, such as %matplotlib widget or %matplotlib qt.
%matplotlib widget
from ppsim import StatePlotter
sp = StatePlotter()
sim.add_snapshot(sp)
sim.snapshot_slider('time')
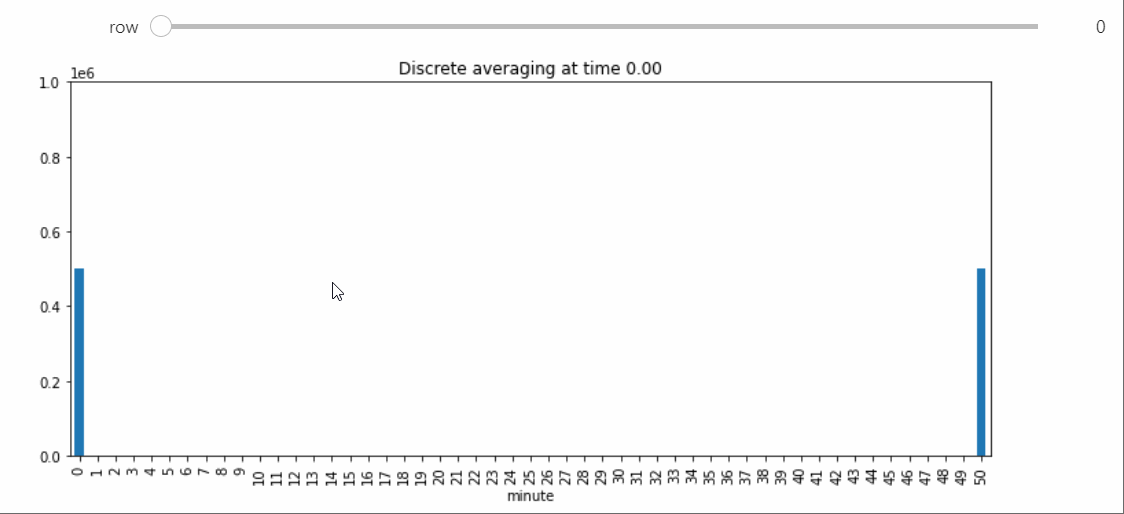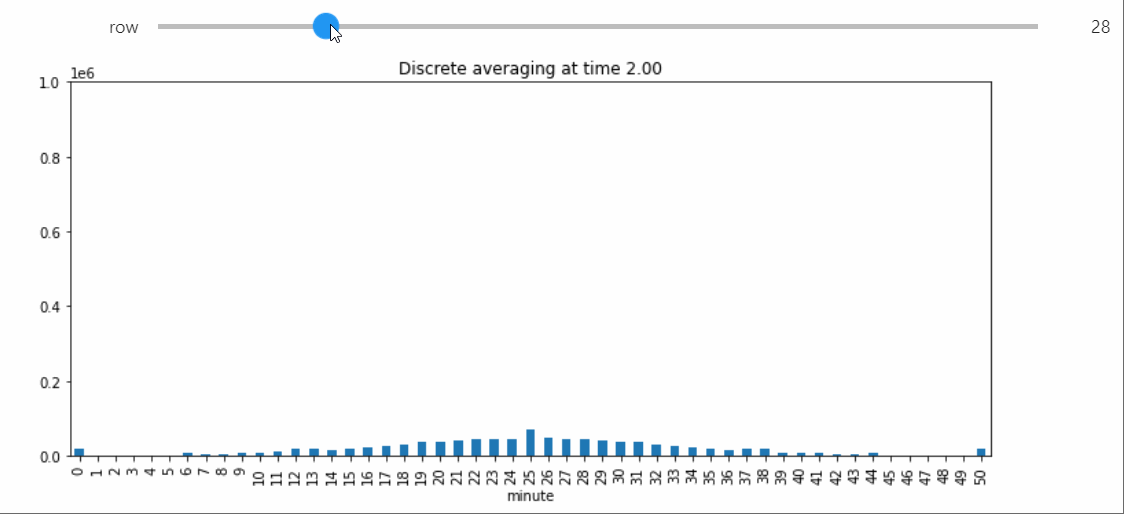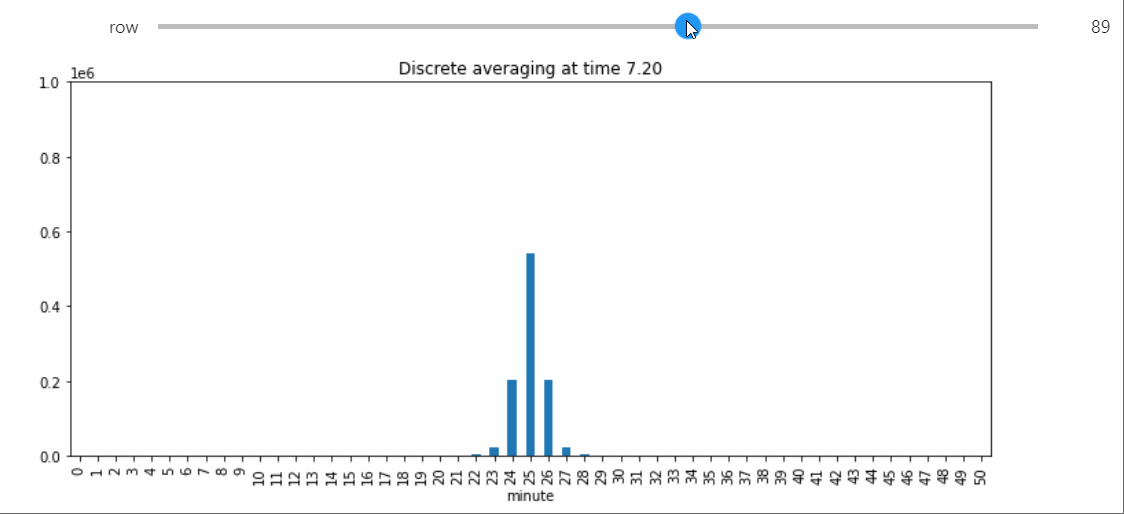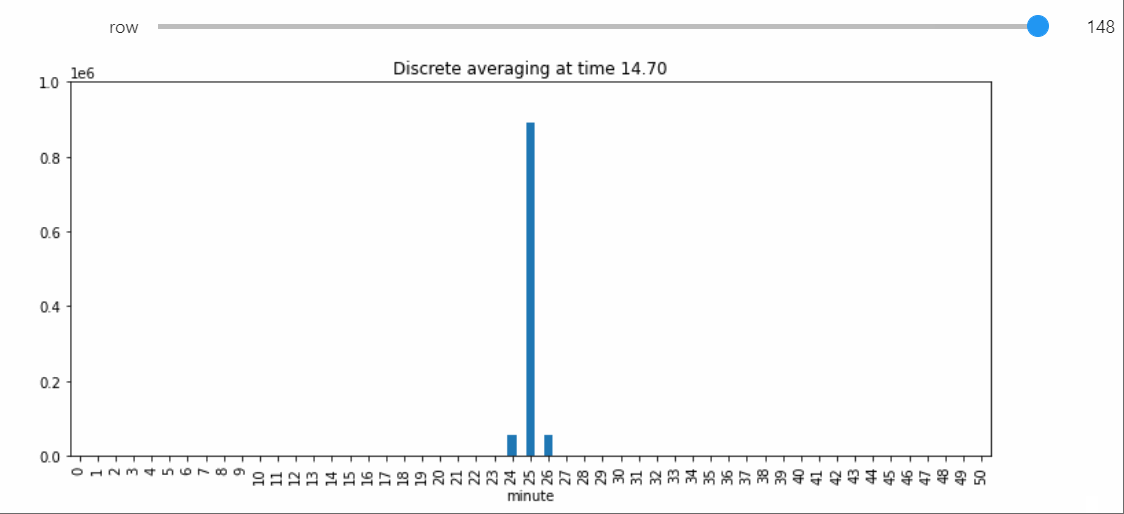
To better visualize small count states, let's change yscale to symlog.
sp.ax.set_yscale('symlog')
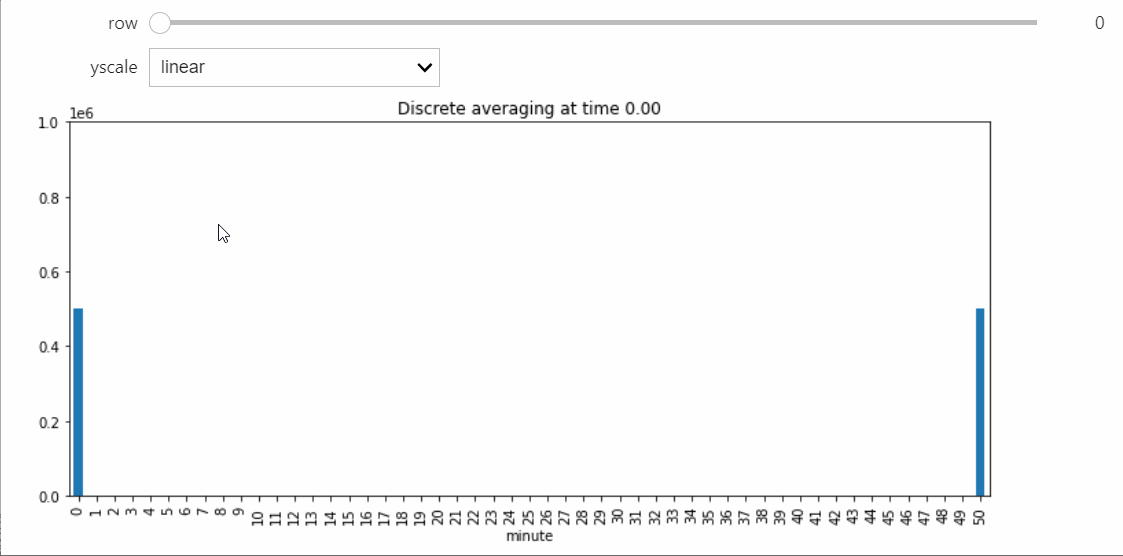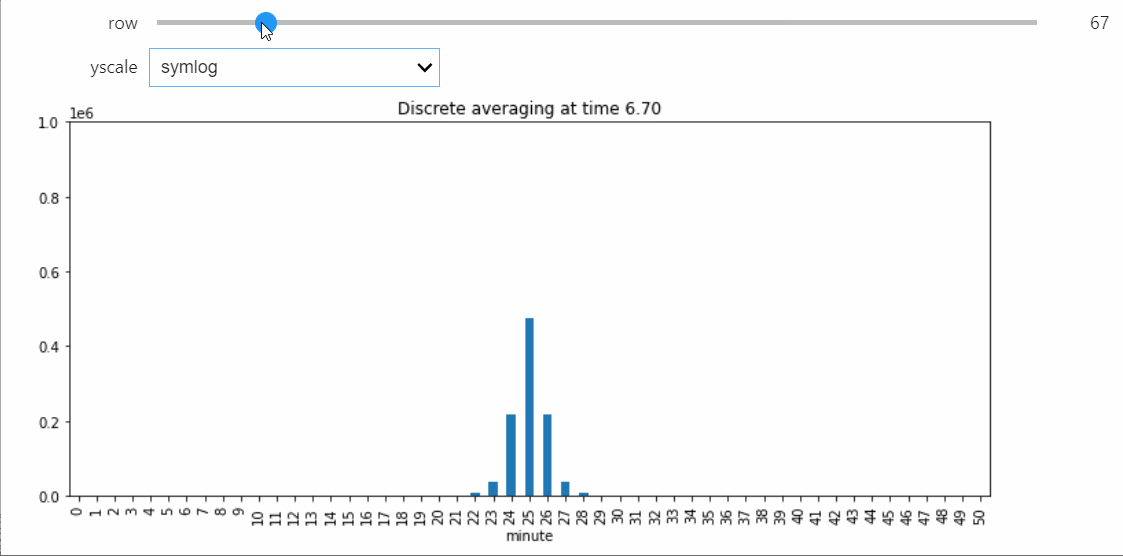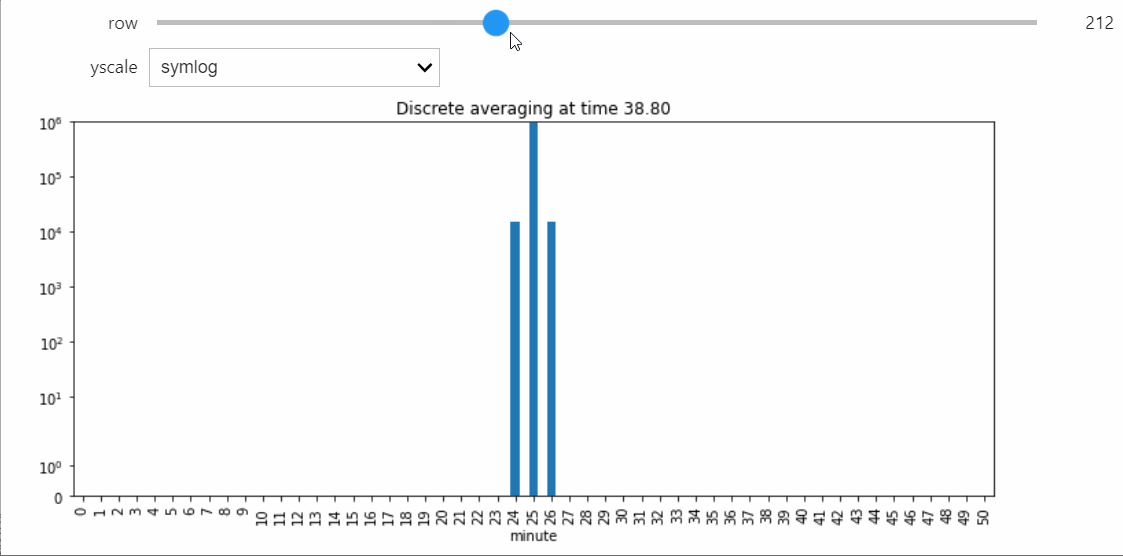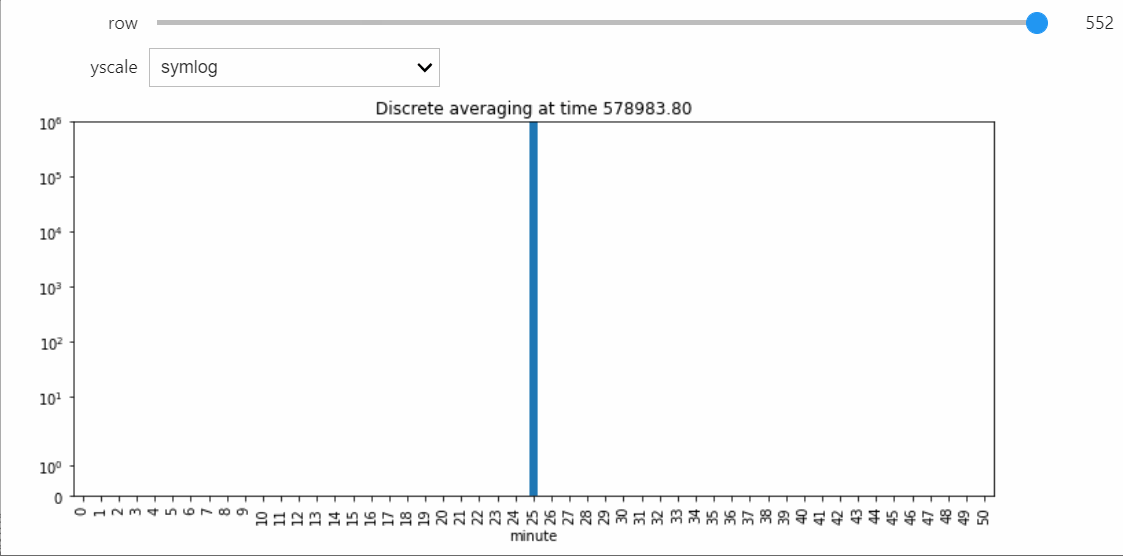
If we run the Simulation while this Snapshot has already been created, it will update while the simulation runs. Because the population average was exactly 50, the ultimate silent configuration will have every agent in state 50, but it will take a a very long time to reach, as we must wait for pairwise interactions between dwindling counts of states 49 and 51. We can check that this reaction is now the only possible non-null interaction.
print(sim.enabled_reactions)
49, 51 --> 50, 50
As a result, the probability of a non-null interaction will grow very small, upon which the simulator will switch to the Gillespie algorithm. This allows it to relatively quickly run all the way until silence, which we can confirm takes a very long amount of parallel time.
sim.run()
Since the timescale of the whole simulation is now very long, we should have the slider range across recorded indices rather than parallel time.
display(sp.fig.canvas)
sim.snapshot_slider('index')
For more examples see https://github.com/UC-Davis-molecular-computing/population-protocols-python-package/tree/main/examples/
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ppsim-0.0.6.tar.gz.
File metadata
- Download URL: ppsim-0.0.6.tar.gz
- Upload date:
- Size: 233.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/3.7.3 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cfba257cfc149a101bb8aa6454e5083d9a16f9c0b8759f6ddd1ba1c14596a0ca
|
|
| MD5 |
daff06b98c48e63c281cc0310a9862e9
|
|
| BLAKE2b-256 |
d4ab65d361a0b78a9dd0f647ac59619e4c0ddbb6e52df5a5d0457ec2b6329f1e
|
File details
Details for the file ppsim-0.0.6-cp37-cp37m-win_amd64.whl.
File metadata
- Download URL: ppsim-0.0.6-cp37-cp37m-win_amd64.whl
- Upload date:
- Size: 279.9 kB
- Tags: CPython 3.7m, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/3.7.3 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dc05e8dbeca3884efed0c900a1a4fc1b575775d877bd2794c0a51301f20bd78f
|
|
| MD5 |
2e302ea6e8fc5b21fefdac978d235ce8
|
|
| BLAKE2b-256 |
9866b8cb11750a6dbe52e7dbc56f96ae5f8c9ec387903a7052470e480a2978ca
|







