Adaptation of differential privacy algorithms applied to learning analytics.

Project description
Local Privacy in Learning Analytics
This repository contains an adaptation of differential privacy algorithms applied to learning analytics.
Index
Project Description
Learning analytics involves collecting and analyzing data about learners to improve educational outcomes. However, this process raises concerns about the privacy of individual data. To address these concerns, this project implements differential privacy algorithms, which add controlled noise to data, ensuring individual privacy while maintaining the overall utility of the dataset. This approach aligns with recent advancements in safeguarding data privacy in learning analytics.
In this project, we explore two local differential privacy (LDP) algorithms designed for sketching with privacy considerations:
-
Single-User Dataset Algorithm: This algorithm is tailored for scenarios where data is collected from individual users. Each user's data is perturbed locally before aggregation, ensuring that their privacy is preserved without relying on a trusted central authority. Techniques such as randomized response and local perturbation are employed to achieve this.
-
Multi-User Dataset Algorithm: In situations involving data from multiple users, this algorithm aggregates the perturbed data to compute global statistics while preserving individual privacy. Methods like private sketching and frequency estimation are utilized to handle the complexities arising from multi-user data aggregation
For the Single-User Dataset Algorithm, the next figure provides a high-level overview of the proposal workflow. At the end, an interest third party could ask the server a query over the frequency of certain events related to an individual. The estimation phase is simulated on the user side in order to adjust the ratio between privacy and utility before sending the information to the server. The algorithm first filters the information (Filter), then encodes the relevant events extracted (Data Processing) in order to be received for the PLDP-CSM method.
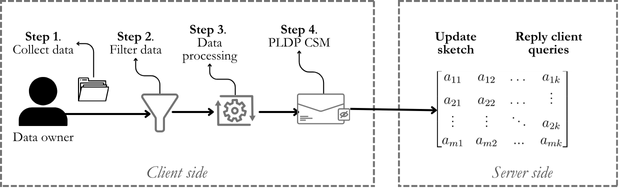
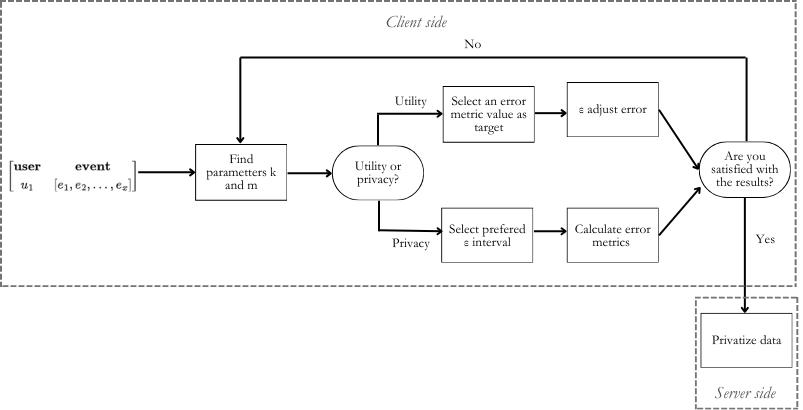
Then, the Cont Sketch based Personalized-LDP (PLDP-CSM) enables the adjustment of the relation between utility and privacy by iterating over data until the output of the simulator satisfies the constraints of users. This part of the algorithm produces the privatize dataset, which will be sent to the server.
Repository Structure
The repository is organized as follows:
Local_Privacy
┣ 📂 src
┣ ┣ 📂 privadjust
┃ ┃ ┣ 📂 count mean
┃ ┃ ┣ 📂 hadamard mean
┃ ┃ ┣ 📂 main
┃ ┃ ┃ ┣ individual_method.py # Single-user dataset algorithm
┃ ┃ ┃ ┗ general_method.py # Multi-user dataset algorithm
┃ ┃ ┣ 📂 scripts
┃ ┃ ┃ ┣ preprocess.py # Data preprocessing routines
┃ ┃ ┃ ┗ parameter_fitting.py # Parameter tuning for algorithms
┃ ┗ ┗ 📂 utils
┗ 📂 tests
Online Execution
You can execute the code online using Google Colab. Google Colab sessions are intended for individual users and have limitations such as session timeouts after periods of inactivity and maximum session durations.
-
For single-user dataset scenarios, click this link to execute the method: Execute in Google Colab (Single-User)
-
For multi-user dataset scenarios, click this link to execute the method: Execute in Google Colab (Multi-User)
Usage
These methods are included in PyPI as you can view here, and can be installed on your device with:
pip install privadjust
Once installed, you can execute the following commands to run the privacy adjustment methods.
For single-user dataset analysis:
To adjust the privacy of a single-user dataset, use the following command:
individualmethod /path/to/dataset.xlsx /path/to/output
dataset: path to the input dataset (.xlsx) you want to privatize.output: path to where the privatized dataset will be saved.
Example:
individualmethod <dataset> <output>
For multi-user dataset analysis:
To adjust the privacy of a multi-user dataset, use the following command:
generalmethod <database>
dataset: Path to the input dataset you want to privatize.
Important Notes
- Ensure that the paths provided are correct, and that the necessary permissions are granted for writing to the output location.
- In the single-user dataset analysis, the output will be a new file
.csvcontaining the privatized data.
Documentation
The complete documentation for this project is available online. You can access it at the following link:
This documentation includes detailed explanations of the algorithms, methods, and the overall structure of the project.
Authors
 Marta Jones 💻 |
 Anailys Hernandez 💡 |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file privadjust-1.0.11.tar.gz.
File metadata
- Download URL: privadjust-1.0.11.tar.gz
- Upload date:
- Size: 11.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
23ae10f7642c27c115f3570371112a05d0973b1d1dea1ee521bc6585044996a1
|
|
| MD5 |
0143e93bdc76a8b21f943503b441f83b
|
|
| BLAKE2b-256 |
960c87f235615551ce0b09afd6af610c81258f1774f5041629ac9e90f8c06b1d
|
File details
Details for the file privadjust-1.0.11-py3-none-any.whl.
File metadata
- Download URL: privadjust-1.0.11-py3-none-any.whl
- Upload date:
- Size: 27.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
724a68e5da2dc1b7c19c5eaefcfb1744ebc76b523364bf7fc100497bf310173d
|
|
| MD5 |
bc516e9fe5d50ac88bb3ec3e28f0b0c4
|
|
| BLAKE2b-256 |
a30ed038719b509b859e41755a084ead60b9fe4691883c35f683d82fc082c33b
|







