Positive-unlabeled learning with Python
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description






Positive-unlabeled learning with Python.
Website: https://pulearn.github.io/pulearn/
Documentation: https://pulearn.github.io/pulearn/doc/pulearn/
from pulearn import ElkanotoPuClassifier
from sklearn.svm import SVC
svc = SVC(C=10, kernel='rbf', gamma=0.4, probability=True)
pu_estimator = ElkanotoPuClassifier(estimator=svc, hold_out_ratio=0.2)
pu_estimator.fit(X, y)1 Documentation
This is the repository for the pulearn package. The readme file is aimed at helping contributors to the project.
To learn more about how to use pulearn, either visit pulearn’s homepage or read the documentation at <https://pulearn.github.io/pulearn/doc/pulearn/>`_.
2 Installation
Install pulearn with:
pip install pulearn3 Implemented Classifiers
3.1 Elkanoto
Scikit-Learn wrappers for both the methods mentioned in the paper by Elkan and Noto, “Learning classifiers from only positive and unlabeled data” (published in Proceeding of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, ACM, 2008).
These wrap the Python code from a fork by AdityaAS (with implementation to both methods) to the original repository by Alexandre Drouin implementing one of the methods.
PU labels are normalized to a canonical internal representation (1 = labeled positive, 0 = unlabeled). Accepted input conventions include {1, -1}, {1, 0}, and {True, False}.
3.1.1 Classic Elkanoto
To use the classic (unweighted) method, use the ElkanotoPuClassifier class:
from pulearn import ElkanotoPuClassifier
from sklearn.svm import SVC
svc = SVC(C=10, kernel='rbf', gamma=0.4, probability=True)
pu_estimator = ElkanotoPuClassifier(estimator=svc, hold_out_ratio=0.2)
pu_estimator.fit(X, y)3.1.2 Weighted Elkanoto
To use the weighted method, use the WeightedElkanotoPuClassifier class:
from pulearn import WeightedElkanotoPuClassifier
from sklearn.svm import SVC
svc = SVC(C=10, kernel='rbf', gamma=0.4, probability=True)
pu_estimator = WeightedElkanotoPuClassifier(
estimator=svc, labeled=10, unlabeled=20, hold_out_ratio=0.2)
pu_estimator.fit(X, y)See the original paper for details on how the labeled and unlabeled quantities are used to weigh training examples and affect the learning process: https://cseweb.ucsd.edu/~elkan/posonly.pdf.
3.2 Bagging-based PU-learning
Based on the paper A bagging SVM to learn from positive and unlabeled examples (2013) by Mordelet and Vert. The implementation is by Roy Wright (roywright on GitHub), and can be found in his repository.
Accepted PU label conventions match the package-wide contract: 1/True for labeled positives and 0/-1/False for unlabeled examples.
from pulearn import BaggingPuClassifier
from sklearn.svm import SVC
svc = SVC(C=10, kernel='rbf', gamma=0.4, probability=True)
pu_estimator = BaggingPuClassifier(
estimator=svc, n_estimators=15)
pu_estimator.fit(X, y)3.3 Bayesian PU Classifiers
Bayesian classifiers for PU learning based on the MIT-licensed Bayesian Classifiers for PU Learning project by Chengning Zhang.
All four classifiers accept PU labels in either the {1, 0} convention (1 = labeled positive, 0 = unlabeled) or the {1, -1} convention (1 = labeled positive, -1 = unlabeled). Continuous features are automatically discretized into equal-width bins.
3.3.1 Positive Naive Bayes (PNB)
The simplest Bayesian PU classifier. Class-conditional distributions \(P(x|y=1)\) and \(P(x|y=0)\) are estimated from the labeled positives and the unlabeled set (treated as approximate negatives) respectively, with Laplace smoothing controlled by alpha.
from pulearn import PositiveNaiveBayesClassifier
clf = PositiveNaiveBayesClassifier(alpha=1.0, n_bins=10)
clf.fit(X_train, y_pu) # y_pu: 1 = labeled positive, 0 = unlabeled
proba = clf.predict_proba(X_test) # shape (n_samples, 2): [P(y=0|x), P(y=1|x)]
labels = clf.predict(X_test)3.3.2 Weighted Naive Bayes (WNB)
Extends PNB by weighting each feature’s log-likelihood contribution by its empirical mutual information with the PU label. Features that are more informative receive higher weights; all weights are non-negative and sum to 1.
from pulearn import WeightedNaiveBayesClassifier
clf = WeightedNaiveBayesClassifier(alpha=1.0, n_bins=10)
clf.fit(X_train, y_pu)
print(clf.feature_weights_) # normalized MI weight per feature (sums to 1)
proba = clf.predict_proba(X_test)3.3.3 Positive Tree-Augmented Naive Bayes (PTAN)
Extends PNB by replacing the naive feature-independence assumption with a tree structure learned via the Chow-Liu algorithm. Pairwise conditional mutual information \(I(X_i; X_j \mid S)\) is computed for all feature pairs, and a maximum spanning tree is built with Prim’s algorithm. Each non-root feature depends on exactly one parent feature in addition to the class label.
from pulearn import PositiveTANClassifier
clf = PositiveTANClassifier(alpha=1.0, n_bins=10)
clf.fit(X_train, y_pu)
print(clf.tan_parents_) # parent index per feature; -1 for the root
proba = clf.predict_proba(X_test)3.3.4 Weighted Tree-Augmented Naive Bayes (WTAN)
Combines PTAN’s tree structure with WNB’s per-feature MI weighting.
from pulearn import WeightedTANClassifier
clf = WeightedTANClassifier(alpha=1.0, n_bins=10)
clf.fit(X_train, y_pu)
print(clf.feature_weights_) # normalized MI weight per feature
print(clf.tan_parents_) # learned tree structure
proba = clf.predict_proba(X_test)A complete end-to-end example on the Wisconsin breast cancer dataset can be found in the examples directory:
python examples/BayesianPULearnersExample.py4 Evaluation Metrics
Standard binary classification metrics (precision, recall, F1) are systematically biased in PU settings: a trivial classifier that predicts positive for every sample achieves recall = 1.0 with no penalty for false positives in the unlabeled pool. pulearn.metrics provides unbiased estimators that cover the full evaluation lifecycle under the SCAR (Selected Completely At Random) assumption.
4.1 Calibration
Before computing confusion-matrix metrics you must map the model’s observed output \(P(s=1|x)\) to the calibrated posterior \(P(y=1|x)\).
from pulearn.metrics import estimate_label_frequency_c, calibrate_posterior_p_y1
# 1. Estimate the propensity score c = P(s=1 | y=1)
c_hat = estimate_label_frequency_c(y_pu, s_proba)
# 2. Calibrate: P(y=1|x) ≈ P(s=1|x) / c
p_y1 = calibrate_posterior_p_y1(s_proba, c_hat)estimate_label_frequency_c implements the Elkan-Noto estimator \(\hat{c} \approx \mathbb{E}[P(s=1|x) \mid s=1]\). calibrate_posterior_p_y1 clips \(P(s=1|x) / \hat{c}\) to \([0, 1]\).
4.2 Expected-Confusion Metrics
These metrics reconstruct the confusion matrix from calibrated posteriors rather than treating unlabeled data as confirmed negatives.
from pulearn.metrics import (
pu_recall_score,
pu_precision_score,
pu_f1_score,
pu_specificity_score,
)
# Recall on labeled positives (no class prior needed)
rec = pu_recall_score(y_pu, y_pred)
# Unbiased precision and F1 require the class prior π
prec = pu_precision_score(y_pu, y_pred, pi=0.3)
f1 = pu_f1_score(y_pu, y_pred, pi=0.3)
# Expected specificity — returns 0.0 for any all-positive classifier
spec = pu_specificity_score(y_pu, y_score)pu_specificity_score is particularly useful as a sanity-check guard: a degenerate classifier that assigns every sample to the positive class obtains \(\text{spec} = 0\), immediately flagging the model as trivial.
4.3 Ranking Metrics
Two AUC-based metrics correct for the absence of ground-truth negatives.
from pulearn.metrics import pu_roc_auc_score, pu_average_precision_score
# Sakai (2018) adjustment: AUC_pn = (AUC_pu − 0.5π) / (1 − π)
auc = pu_roc_auc_score(y_pu, y_score, pi=0.3)
# Area Under Lift: AUL = 0.5π + (1 − π) · AUC_pu
aul = pu_average_precision_score(y_pu, y_score, pi=0.3)pu_roc_auc_score maps the biased \(AUC_{pu}\) (computed against PU labels) to an unbiased estimator of the true positive-vs-negative AUC. pu_average_precision_score returns the Area Under Lift (AUL), which is more robust to severe class imbalance.
4.4 Risk Estimators
For flexible models such as deep networks, raw risk estimators are suitable for early stopping and model selection in lieu of black-box accuracy metrics.
from pulearn.metrics import pu_unbiased_risk, pu_non_negative_risk
# uPU: pi * R_p+ + R_u- - pi * R_p- (du Plessis et al., 2015)
risk_upu = pu_unbiased_risk(y_pu, y_score, pi=0.3)
# nnPU: clamps negative component to zero to prevent over-fitting
# (Kiryo et al., 2017)
risk_nnpu = pu_non_negative_risk(y_pu, y_score, pi=0.3)Both functions accept a loss argument (currently "logistic").
4.5 Diagnostics
Two utility functions help detect why a model may be performing poorly.
from pulearn.metrics import pu_distribution_diagnostics, homogeneity_metrics
# KL divergence between labeled and unlabeled score distributions
# Near-zero divergence → model cannot separate positives from unlabeled
diag = pu_distribution_diagnostics(y_pu, y_score)
print(diag["kl_divergence"])
# STD and IQR of predicted-negative scores
# Low STD/IQR → model may be over-relying on trivial features
hom_metrics = homogeneity_metrics(y_pu, y_score)
print(hom_metrics["std"], hom_metrics["iqr"])4.6 Scikit-learn Integration
make_pu_scorer wraps any PU metric as a make_scorer-compatible callable, enabling direct use with GridSearchCV and RandomizedSearchCV.
from sklearn.model_selection import GridSearchCV
from pulearn.metrics import make_pu_scorer
scorer = make_pu_scorer("pu_f1", pi=0.3)
gs = GridSearchCV(estimator, param_grid, scoring=scorer)
gs.fit(X_train, y_pu_train)Supported metric names for make_pu_scorer:
"lee_liu" |
Lee & Liu score (no pi required) |
"pu_recall" |
PU recall (no pi required) |
"pu_precision" |
Unbiased PU precision |
"pu_f1" |
Unbiased PU F1 |
"pu_specificity" |
Expected specificity |
"pu_roc_auc" |
Adjusted ROC-AUC (Sakai 2018) |
"pu_average_precision" |
Area Under Lift (AUL) |
"pu_unbiased_risk" |
uPU risk (lower is better) |
"pu_non_negative_risk" |
nnPU risk (lower is better) |
Risk metrics are wrapped with greater_is_better=False so that GridSearchCV correctly minimises them.
4.7 Complete Example
An end-to-end demo comparing naive F1 inflation vs. corrected metrics on synthetic SCAR data can be found in the examples directory:
python examples/PUMetricsEvaluationExample.py5 Examples
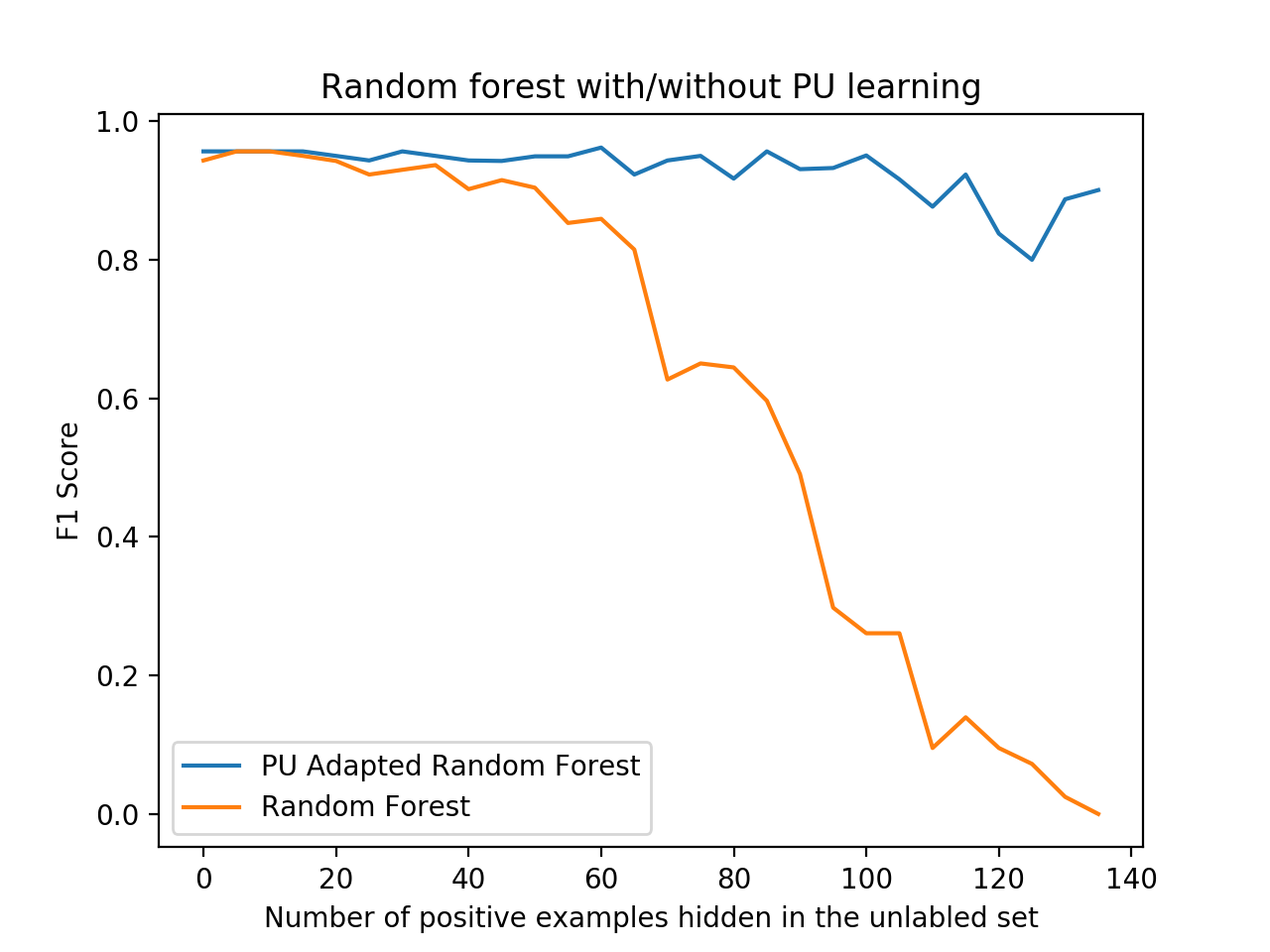
A nice code example of the classic Elkan-Noto classifier used for classification on the Wisconsin breast cancer dataset , comparing it to a regular random forest classifier, can be found in the examples directory.
To run it, clone the repository, and run the following command from the root of the repository, with a python environment where pulearn is installed:
python examples/BreastCancerElkanotoExample.pyYou should see a nice plot like the one below, comparing the F1 score of the PU learner versus a naive learner, demonstrating how PU learning becomes more effective - or worthwhile - the more positive examples are “hidden” from the training set.
6 Contributing
Package author and current maintainer is Shay Palachy (shay.palachy@gmail.com); You are more than welcome to approach him for help. Contributions are very welcomed, especially since this package is very much in its infancy and many other PU Learning methods can be added.
6.1 Installing for development
Clone:
git clone git@github.com:pulearn/pulearn.gitInstall in development mode with test dependencies:
cd pulearn
pip install -e ".[test]"6.2 Running the tests
To run the tests, use:
python -m pytestNotice pytest runs are configured by the pytest.ini file. Read it to understand the exact pytest arguments used.
6.3 Adding tests
At the time of writing, pulearn is maintained with a test coverage of 100%. Although challenging, I hope to maintain this status. If you add code to the package, please make sure you thoroughly test it. Codecov automatically reports changes in coverage on each PR, and so PR reducing test coverage will not be examined before that is fixed.
Tests reside under the tests directory in the root of the repository. Each model has a separate test folder, with each class - usually a pipeline stage - having a dedicated file (always starting with the string “test”) containing several tests (each a global function starting with the string “test”). Please adhere to this structure, and try to separate tests cases to different test functions; this allows us to quickly focus on problem areas and use cases. Thank you! :)
6.4 Code style
pulearn code is written to adhere to the coding style dictated by flake8. Practically, this means that one of the jobs that runs on the project’s Travis for each commit and pull request checks for a successful run of the flake8 CLI command in the repository’s root. Which means pull requests will be flagged red by the Travis bot if non-flake8-compliant code was added.
To solve this, please run flake8 on your code (whether through your text editor/IDE or using the command line) and fix all resulting errors. Thank you! :)
6.5 Adding documentation
This project is documented using the numpy docstring conventions, which were chosen as perhaps the most widelspread conventions both supported by common tools such as Sphinx and resulting in human-readable docstrings (in my personal opinion, of course). When documenting code you add to this project, please follow these conventions.
Additionally, if you update this README.rst file, use python setup.py checkdocs to validate it compiles.
7 License
This package is released as open-source software under the BSD 3-clause license. See LICENSE_NOTICE.md for the different copyright holders of different parts of the code.
8 Credits
Implementations code by:
Elkan & Noto - Alexandre Drouin and AditraAS.
Bagging PU Classifier - Roy Wright.
Bayesian PU Classifiers (PNB, WNB, PTAN, WTAN) - ported from Bayesian Classifiers for PU Learning by Chengning Zhang (MIT License).
Packaging, testing and documentation by Shay Palachy.
Fixes and feature contributions by:
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pulearn-0.1.1.tar.gz.
File metadata
- Download URL: pulearn-0.1.1.tar.gz
- Upload date:
- Size: 41.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
08c071c2874a24ac53a2d027e0397c52a0ffbea24bcd55c0ae43b7e1a6ed9f62
|
|
| MD5 |
d98979907ecbda791723c86575076eb3
|
|
| BLAKE2b-256 |
6342438e728c8610f998147728b9a85b4c90fbcb2ef79f2dc56c34dc091529c1
|
Provenance
The following attestation bundles were made for pulearn-0.1.1.tar.gz:
Publisher:
release.yml on pulearn/pulearn
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pulearn-0.1.1.tar.gz -
Subject digest:
08c071c2874a24ac53a2d027e0397c52a0ffbea24bcd55c0ae43b7e1a6ed9f62 - Sigstore transparency entry: 1042767855
- Sigstore integration time:
-
Permalink:
pulearn/pulearn@ef2ed6650ff0d012b73417a067d259bb6113504b -
Branch / Tag:
refs/heads/master - Owner: https://github.com/pulearn
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@ef2ed6650ff0d012b73417a067d259bb6113504b -
Trigger Event:
push
-
Statement type:
File details
Details for the file pulearn-0.1.1-py3-none-any.whl.
File metadata
- Download URL: pulearn-0.1.1-py3-none-any.whl
- Upload date:
- Size: 37.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0cabf3ae6157f75cbbc68454203d529da651a30fae56a164fa2b55a6528c9cfd
|
|
| MD5 |
d6e248ddeb3a42a323b83e3810ff5844
|
|
| BLAKE2b-256 |
500c02d8a69c44389ebc07960c81f87f85e42037eb30353d538411a7b3f6ef0a
|
Provenance
The following attestation bundles were made for pulearn-0.1.1-py3-none-any.whl:
Publisher:
release.yml on pulearn/pulearn
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pulearn-0.1.1-py3-none-any.whl -
Subject digest:
0cabf3ae6157f75cbbc68454203d529da651a30fae56a164fa2b55a6528c9cfd - Sigstore transparency entry: 1042767874
- Sigstore integration time:
-
Permalink:
pulearn/pulearn@ef2ed6650ff0d012b73417a067d259bb6113504b -
Branch / Tag:
refs/heads/master - Owner: https://github.com/pulearn
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@ef2ed6650ff0d012b73417a067d259bb6113504b -
Trigger Event:
push
-
Statement type:







