scikit-learn-compatible cross-validation for time-series and financial machine learning: purging, embargoes, combinatorial purged CV, and deflated Sharpe ratios.

Project description
Purged cross validation
scikit-learn-compatible cross-validation for time-series machine learning: purging, embargoes, and combinatorial backtest paths.










Documentation → · Example notebooks → · 
Cite this software: see CITATION.cff and paper/paper.md (JOSS paper).
API summary
| Symbol | Domain | Description |
|---|---|---|
purge |
D2 | Remove overlapping-horizon training rows |
apply_embargo |
D3 | Remove post-test buffer rows |
WalkForwardSplit |
D5.1 | Sliding / expanding walk-forward CV |
PurgedKFold |
D5.2 | Contiguous test folds with purge + embargo |
PurgedGroupKFold |
D5.3 | Group-aware purged k-fold |
CombinatorialPurgedCV |
D5.4 | C(N,K) combinatorial folds |
CombinatoriallySymmetricCV |
D5.4 | CSCV: symmetric IS/OOS folds, the PBO substrate |
reconstruct_paths |
D6 | Assemble CPCV folds into backtest paths |
path_metrics |
D6 | Per-path Sharpe / Calmar / drawdown / return table |
probabilistic_sharpe_ratio |
D7 | PSR: P(true SR > benchmark) |
deflated_sharpe_ratio |
D7 | DSR: PSR corrected for multiple testing |
deflated_sharpe_ratio_full |
D7 | DSR plus the intermediate deflation quantities |
probability_of_backtest_overfitting |
D7 | PBO via CSCV: how often in-sample selection overfits |
min_track_record_length |
D7 | Minimum observations to establish SR |
minimum_backtest_length |
D7 | MinBTL: backtest years below which a Sharpe is selection luck |
effective_n_trials |
D7 | Independent-trial count for a correlated search, for DSR |
optuna_integration.TrialSharpeRecorder |
D7 | Collect per-trial Sharpe variance + effective count for DSR |
diagnostics.* |
D8 | Leakage and embargo audit functions |
Contents
- The problem
- Does it actually catch leakage?
- Does an honest CV deploy better?
- What about a market with no real edge?
- Installation
- Quickstart
- Methodology references
- License
The problem
Standard k-fold cross-validation assumes the rows are independent. Time-series data is not. When a label resolves over the next few days, it overlaps the labels sitting right next to it, so an ordinary shuffle-split leaks tomorrow's answer back into training. The rows immediately after a test window leak too, because they are serially correlated with it. Both effects quietly inflate backtested Sharpe ratios and hand you strategies that look great on a chart and bleed money once they go live. This library removes both.
Why write another one? People have asked scikit-learn, auto-sklearn, and mlpack for purging and embargo support and been turned down or left waiting for years. The one mature implementation, mlfinlab, went closed-source and paid. The free alternative has been unmaintained since 2018. That gap is the reason this exists.
Does it actually catch leakage?
A controlled check on synthetic data whose target is built so that no feature can predict it. The honest out-of-sample score must never be positive. Naive shuffled k-fold runs against PurgedKFold side by side (examples/synthetic_leakage_proof.ipynb, deterministic, no downloads):
| model | naive shuffled KFold R² | PurgedKFold R² |
|---|---|---|
| predict-the-mean (reference) | -0.01 | -0.13 |
| k-NN | 0.83 | -1.48 |
| RandomForest | 0.91 | -1.87 |
Train/test label overlap: 100% under naive → 0% under PurgedKFold.
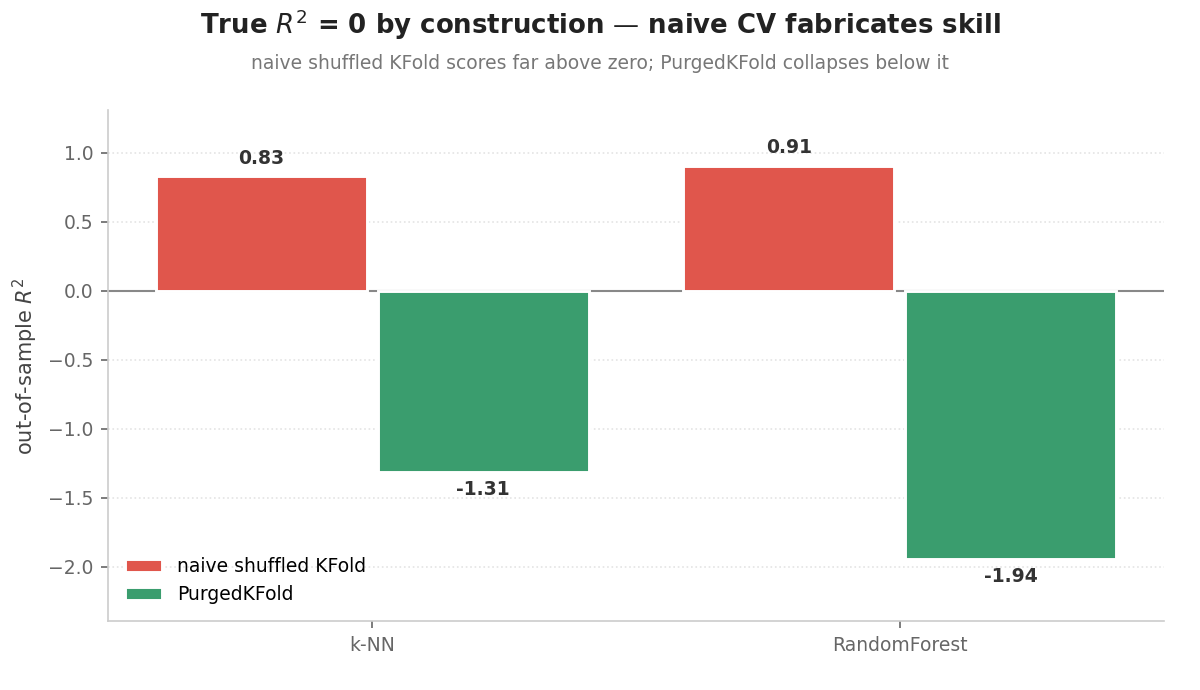
Naive CV reports R² ≈ 0.83–0.91 on a target nothing can predict. That is pure leakage from the overlap. PurgedKFold removes the overlap and the fabricated skill collapses below a predict-the-mean baseline. The negative number is not the point; no positive skill is the correct answer, and only the purged split reports it. The library does not make models look better; it stops them looking better than they are.
Does an honest CV deploy better?
Same kind of question, opposite framing: on a partially predictable real task, does PurgedGroupKFold pick a model that deploys better than naive shuffled KFold? UK Low Carbon London smart meters, 48 households for model selection, 12 truly held-out households for deployment (examples/selection_regret_lcl.ipynb):
| selection method | picked model | deployment MAE | deployment R² |
|---|---|---|---|
| naive shuffled KFold | RF d=None | 2.638 kWh | +0.759 |
| PurgedGroupKFold | Ridge α=0.01 | 2.464 kWh | +0.783 |
The honest-selected model deploys at 6.6% lower MAE on the 12 unseen households. Across 30 random 48/12 household partitions, honest wins every single one: naive picks deep RandomForest in all 30, honest picks Ridge in all 30, and the honest selection deploys better in all 30:
| value | |
|---|---|
| Honest deploys better | 30 / 30 partitions |
| Naive selector regret, median (IQR) | 0.28 kWh (0.18 to 0.52) |
| Honest selector regret, median (IQR) | 0 (exactly zero) |
| Naive − honest MAE, median | 0.28 kWh (13.3% relative) |
| Range | 0.11 to 1.79 kWh |
Plain sklearn.GroupKFold gives the same selection as PurgedGroupKFold here: the effect is a property of group-aware validation, not of a specific package (examples/selection_regret_lcl_seeds.py).
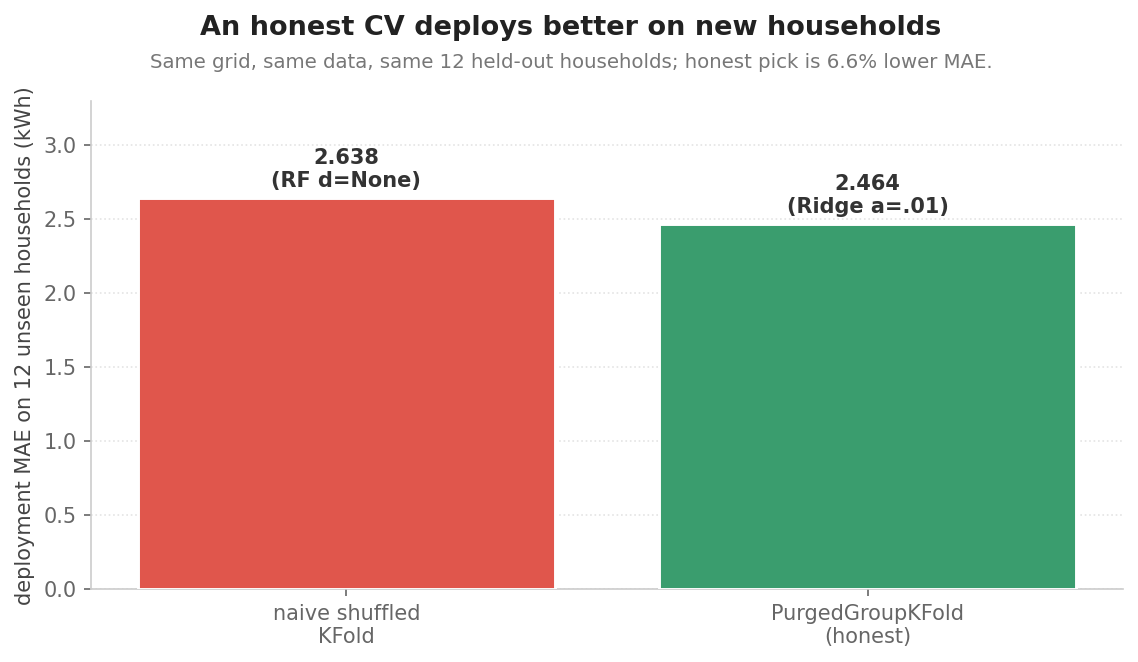
The naive selector picks deep RandomForest because the household-identifier feature lets it memorise per-household baselines inside the shuffled CV. On truly unseen households that feature is useless and the model collapses. An ablation that removes the identifier flattens the gap to zero. A second variant replaces the raw identifier with a causal target-mean encoding of the customer's average load (the kind of feature a careful practitioner would use): the gap reproduces at median 0.2154 kWh (10.1% relative, 29/30 wins), confirming the effect is not an artifact of the contrived identifier (examples/selection_regret_lcl_targetenc.py).
What about a market with no real edge?
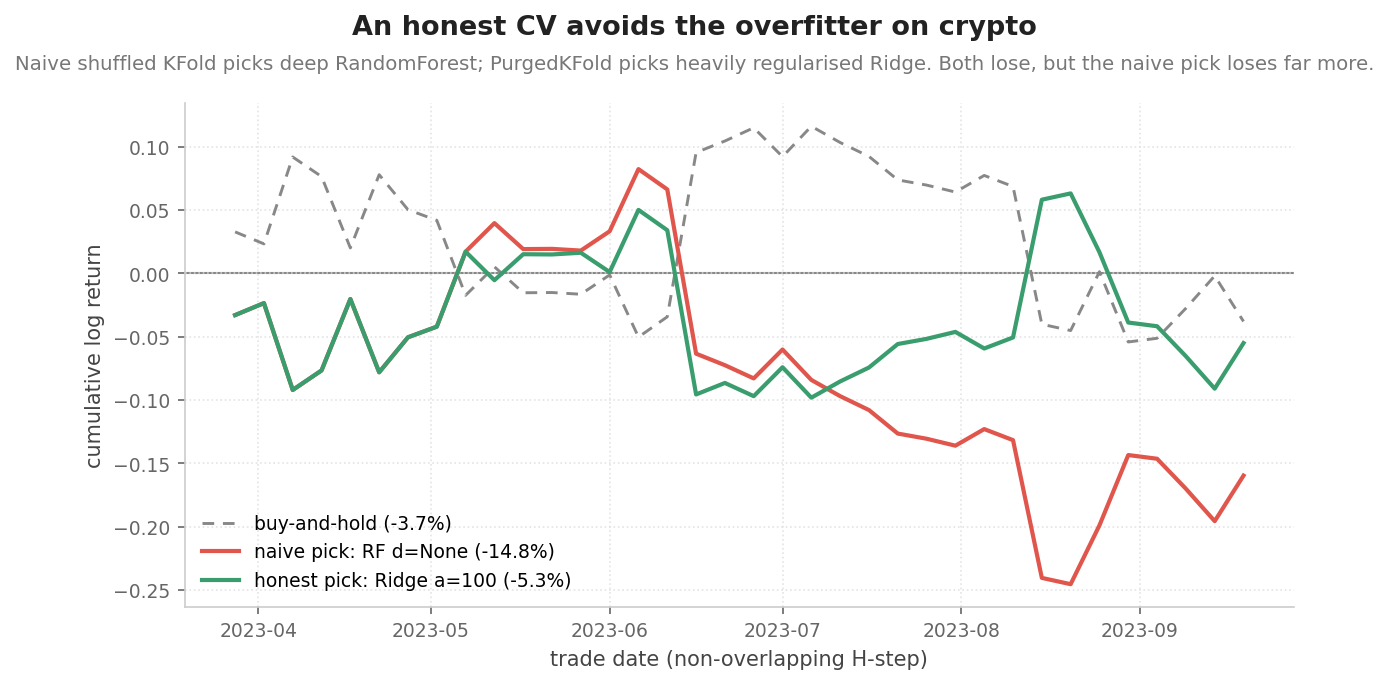
On a task where no honest model has predictive power (daily BTC/USDT 2021-2023 with ordinary technical features), the question changes from "does honest CV pick a better model" to "does honest CV stop me from picking a worse one" (examples/selection_regret_crypto.ipynb):
| naive shuffled KFold | PurgedKFold | |
|---|---|---|
| picked model | RF d=None | Ridge α=100 |
| deployment R² (180 held-out bars) | -1.64 | +0.011 |
| deployment Sharpe | -0.77 | -0.26 |
Both strategies lose money over the sideways-down deployment window; the naive pick loses three to five times more per unit of risk. Direction stable across 5 seeds. The library's value on a no-edge market is loss avoidance rather than gain.
Installation
pip install purgedcv
# Directly from the repository
pip install git+https://github.com/eslazarev/purged-cross-validation.git
Quickstart
1. The core primitive: purge
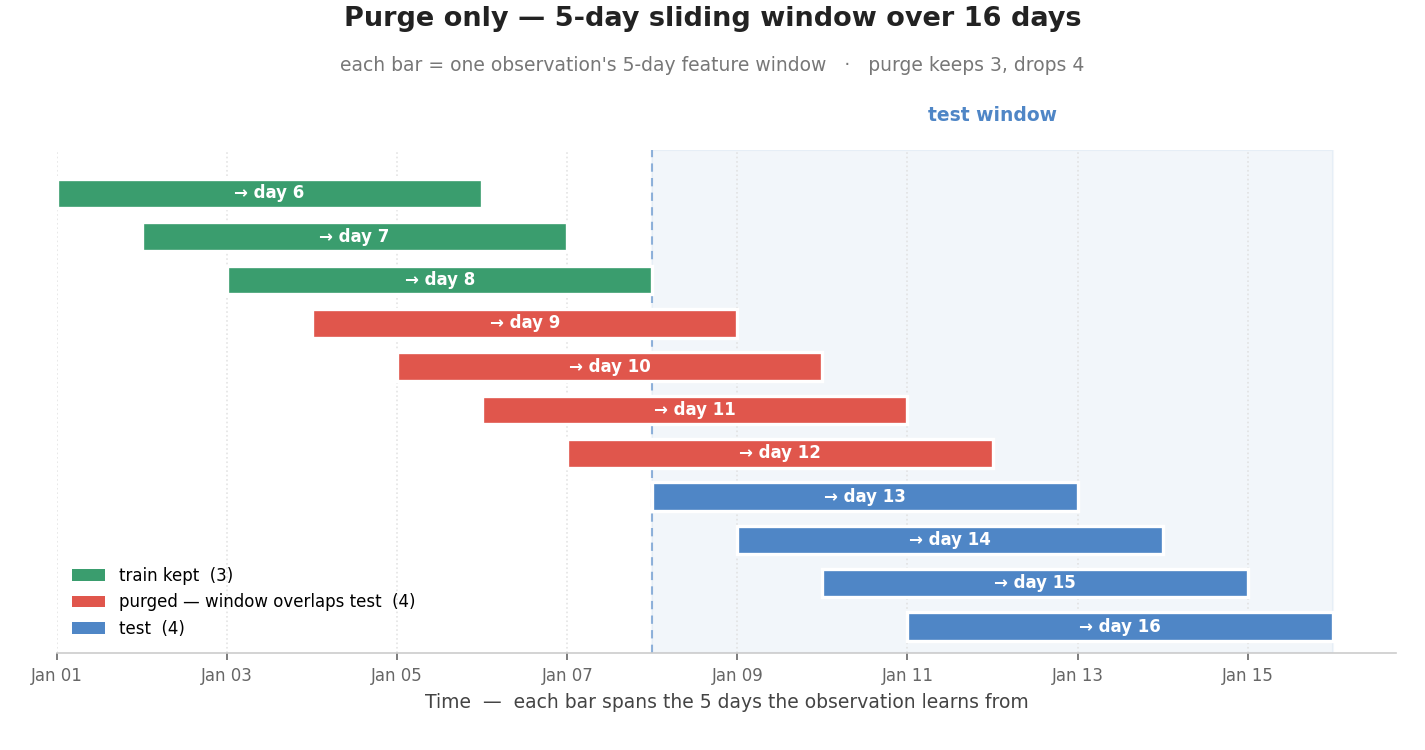
purge removes training observations that share data with the test set. Here a model uses a 5-day sliding feature window to predict the next day, so every observation occupies a 5-day span and the spans of neighbours overlap. Any training observation whose window reaches into the test period has already seen test data and must be dropped.
import numpy as np
import pandas as pd
from purgedcv import purge
WINDOW = 5 # feature look-back in days
# 16 days of data; each observation uses a 5-day window to predict the next day
days = pd.date_range("2024-01-01", periods=16, freq="D")
predict_day = np.arange(WINDOW + 1, len(days) + 1) # 11 observations
pred = pd.Series([days[d - WINDOW - 1] for d in predict_day]) # first feature day
evalu = pd.Series([days[d - 1] for d in predict_day]) # label day
train_idx = np.arange(0, 7) # observations predicting days 6..12
test_idx = np.arange(7, 11) # observations predicting days 13..16
# Drop training observations whose 5-day feature window overlaps the test window
kept_idx = purge(train_idx, test_idx, pred, evalu)
purged_idx = np.setdiff1d(train_idx, kept_idx)
print(f"Kept: {kept_idx.tolist()}") # [0, 1, 2] -> predict days 6, 7, 8
print(f"Purged: {purged_idx.tolist()}") # [3, 4, 5, 6] -> predict days 9, 10, 11, 12
Each bar below is one observation's 5-day feature window. The four red bars cross into the test window (dashed line): their features overlap the test period, so purge drops them. The three green bars stay fully before it; → day 8 only touches the boundary and is kept, because label horizons are half-open.
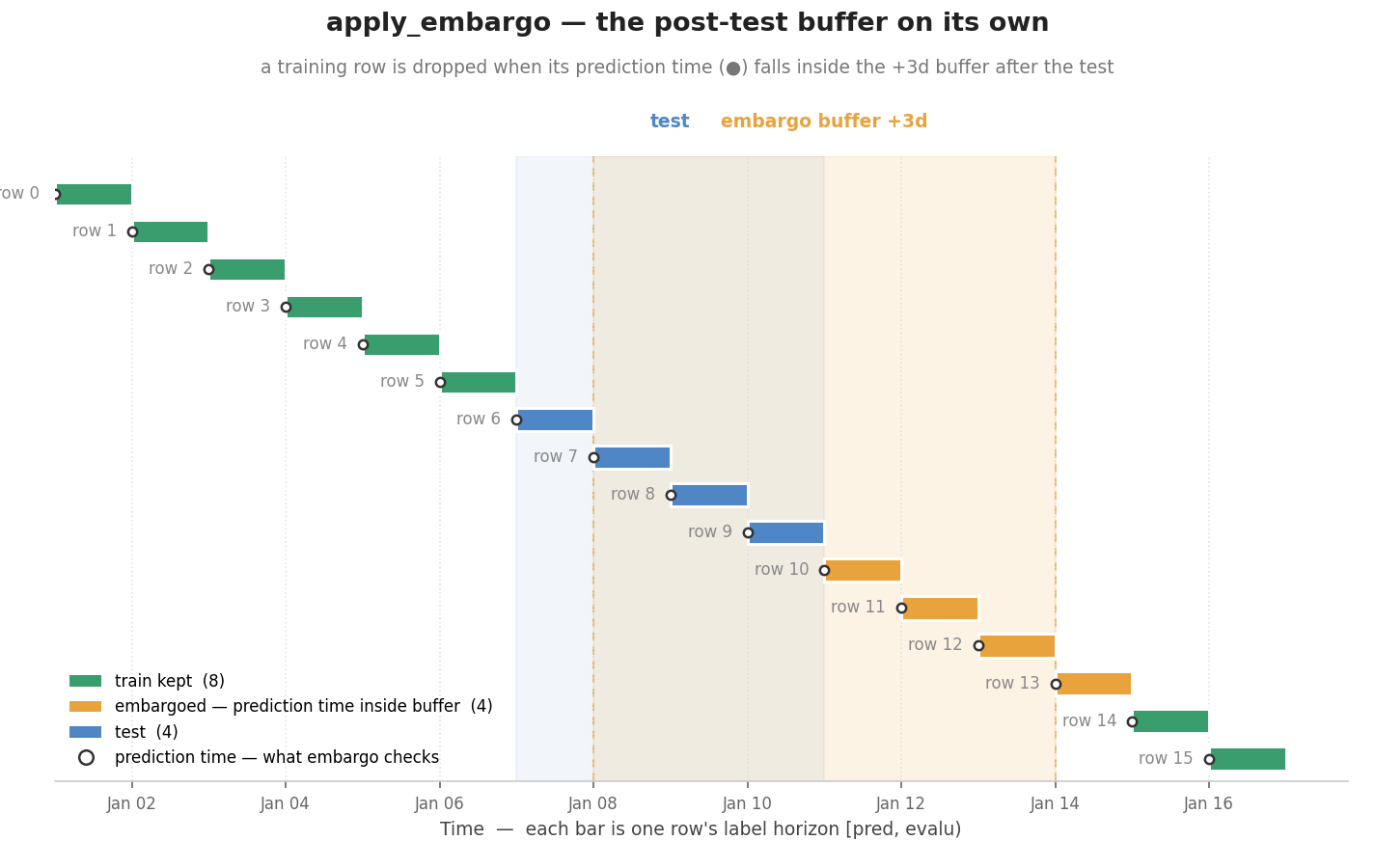
2. The post-test buffer: apply_embargo
apply_embargo is the second leakage guard. Where purge removes label overlap, embargo drops a fixed buffer of training rows right after the test fold; their features are still serially correlated with the test period, so they leak even when their labels do not. The buffer extends only after the test, never before it.
import numpy as np
import pandas as pd
from purgedcv import apply_embargo
# 16 daily rows; each label resolves 1 day later
n = 16
pred = pd.Series(pd.date_range("2024-01-01", periods=n, freq="D"))
evalu = pred + pd.Timedelta(days=1)
test_idx = np.arange(6, 10) # test block in the middle
train_idx = np.concatenate([np.arange(0, 6), np.arange(10, 16)]) # train before and after
# Drop training rows whose prediction time falls in the post-test buffer
kept_idx = apply_embargo(train_idx, test_idx, pred, evalu, embargo=pd.Timedelta(days=3))
embargoed_idx = np.setdiff1d(train_idx, kept_idx)
print(f"Kept: {kept_idx.tolist()}") # [0, 1, 2, 3, 4, 5, 14, 15]
print(f"Embargoed: {embargoed_idx.tolist()}") # [10, 11, 12, 13]
Each bar below is one row's label horizon. Every training row whose start falls inside the orange +3d buffer after the test is dropped; rows before the test are untouched. The 1-day label horizon leaves purge nothing to do here, so the split is cleaned by embargo alone.
3. Walk-forward CV: WalkForwardSplit
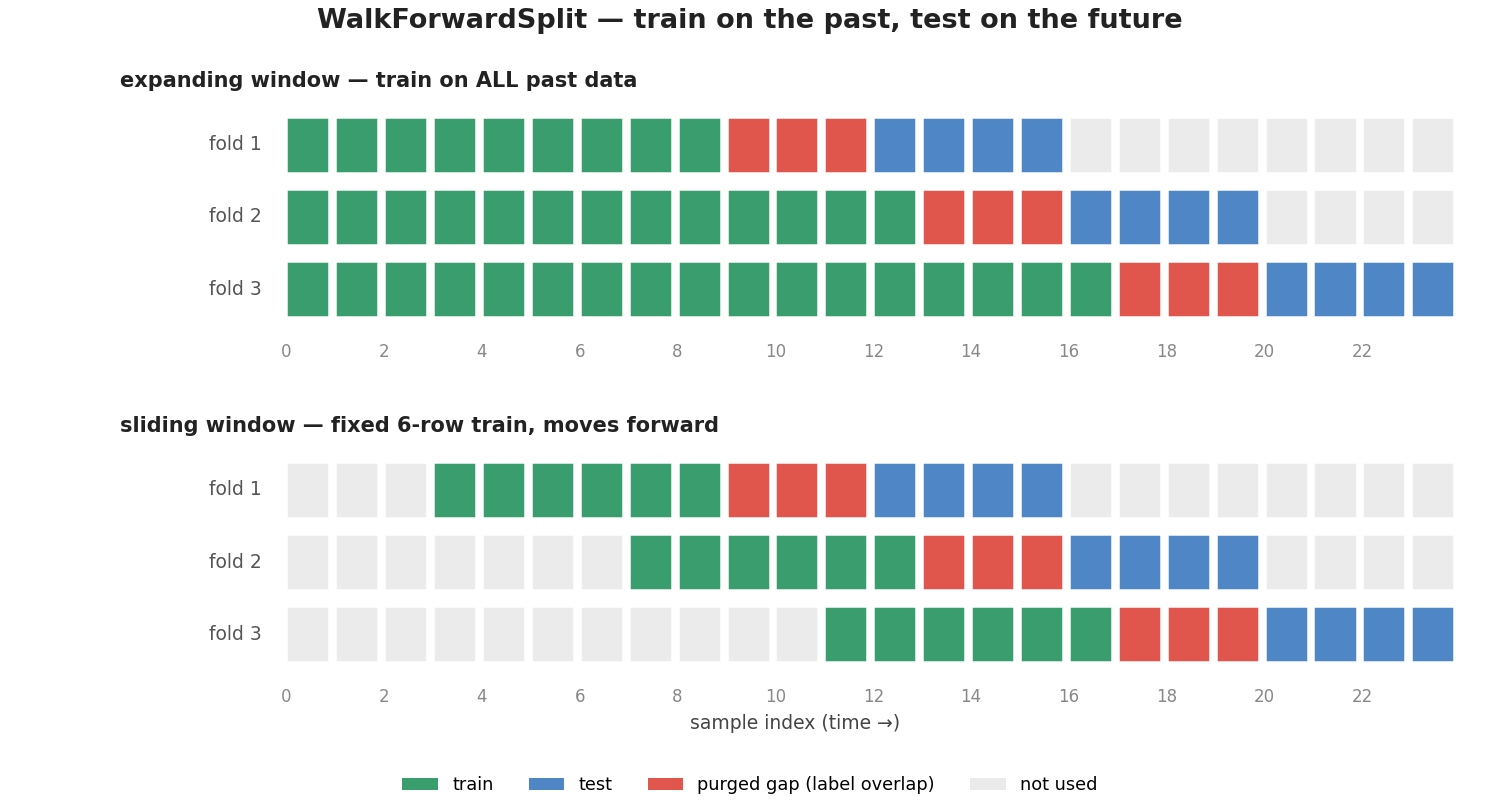
WalkForwardSplit walks the train/test split forward in time: every fold trains only on data before its test block, the way a model is actually deployed. Purge and embargo are applied automatically on each fold. Use window="expanding" to keep all history, or window="sliding" to cap training at a fixed-size recent window.
import numpy as np
import pandas as pd
from purgedcv import WalkForwardSplit
# 24 daily rows; each label resolves 2 days later
n = 24
pred = pd.Series(pd.date_range("2024-01-01", periods=n, freq="D"))
evalu = pred + pd.Timedelta(days=2)
X = np.zeros((n, 1))
# Expanding window: every fold trains on all data before its test block.
# purge_horizon drops the training rows whose label overlaps each test fold.
cv = WalkForwardSplit(
n_splits=3,
test_size=4,
window="expanding", # or "sliding" with train_size=...
prediction_times=pred,
evaluation_times=evalu,
purge_horizon="2D",
)
for i, (train_idx, test_idx) in enumerate(cv.split(X), 1):
print(f"fold {i}: train {train_idx[0]}..{train_idx[-1]} test {test_idx[0]}..{test_idx[-1]}")
# fold 1: train 0..8 test 12..15
# fold 2: train 0..12 test 16..19
# fold 3: train 0..16 test 20..23
Three folds tile the end of the series. Each fold trains on the past and tests on the next block; the red purge gap right before each test is removed automatically. Expanding grows the training set every fold; sliding keeps it a fixed size and moves it forward.
4. Purged k-fold: PurgedKFold
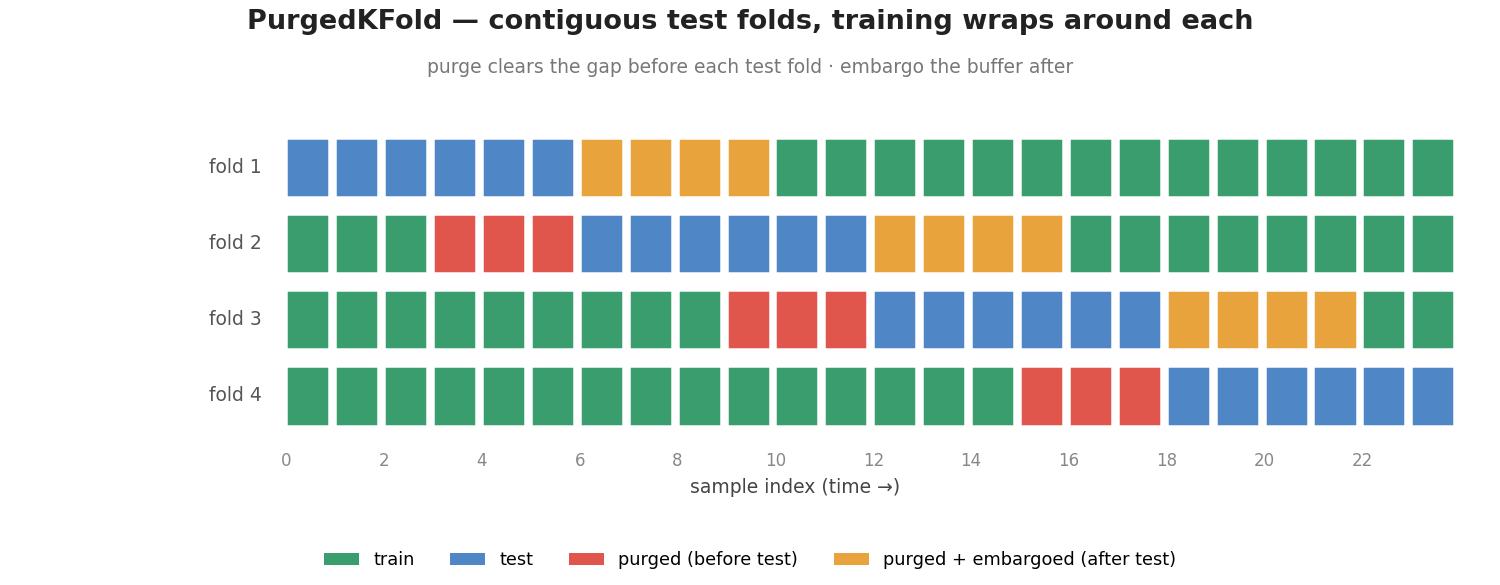
A drop-in replacement for KFold for time-series data. Test folds tile the whole series contiguously, so most folds sit inside the data and the training set wraps around them on both sides. Purge and embargo are applied automatically on every fold.
import numpy as np
import pandas as pd
from purgedcv import PurgedKFold
# 24 daily rows; each label resolves 2 days later
n = 24
pred = pd.Series(pd.date_range("2024-01-01", periods=n, freq="D"))
evalu = pred + pd.Timedelta(days=2)
X = np.zeros((n, 1))
# 4 contiguous test folds; purge + embargo applied automatically per fold
cv = PurgedKFold(
n_splits=4,
prediction_times=pred,
evaluation_times=evalu,
purge_horizon="2D",
embargo="2D",
)
for i, (train_idx, test_idx) in enumerate(cv.split(X), 1):
print(f"fold {i}: test {test_idx[0]}..{test_idx[-1]} train rows {len(train_idx)}")
# fold 1: test 0..5 train rows 14
# fold 2: test 6..11 train rows 11
# fold 3: test 12..17 train rows 11
# fold 4: test 18..23 train rows 15
Each test fold is a contiguous block. A middle fold trains on data both before and after it; the red purge gap before the test and the orange purge + embargo buffer after it are removed automatically, so no training row leaks into the fold.
All four splitters (WalkForwardSplit, PurgedKFold, PurgedGroupKFold, CombinatorialPurgedCV) satisfy the sklearn splitter protocol and work inside cross_val_score, GridSearchCV, and Pipeline.
5. CPCV + path reconstruction + metrics: the full workflow
Combinatorial Purged CV produces C(N, K) folds that tile into multiple out-of-sample backtest paths. The metric functions then evaluate a strategy's realised returns for statistical significance and selection bias.
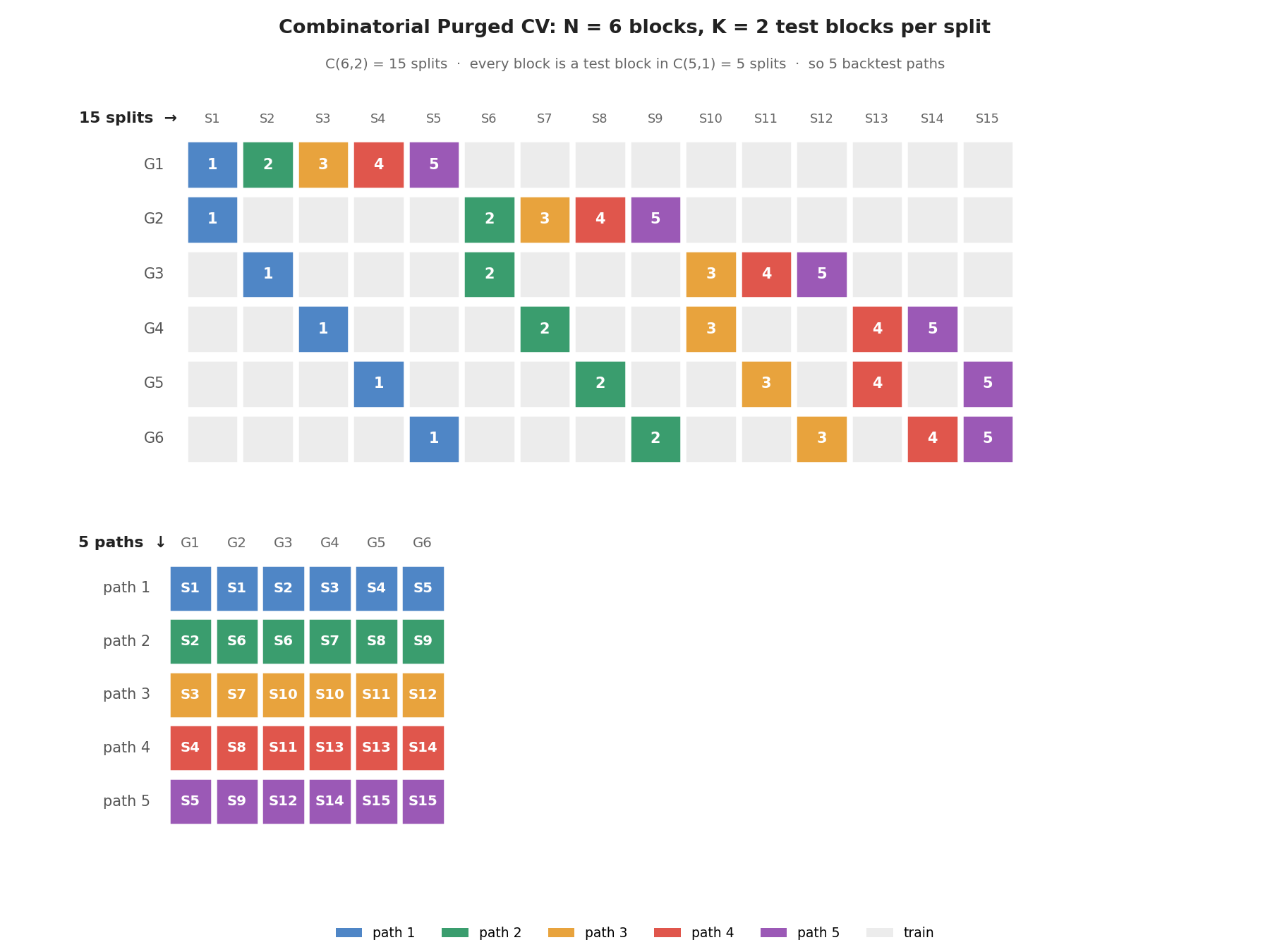
The split-to-path assignment in the figure comes straight from cv.split and reconstruct_paths, so it matches what the code below produces.
import numpy as np
import pandas as pd
from sklearn.dummy import DummyRegressor
from purgedcv import (
CombinatorialPurgedCV,
probabilistic_sharpe_ratio,
min_track_record_length,
)
rng = np.random.default_rng(42)
n = 120
pred = pd.Series(pd.date_range("2023-01-01", periods=n, freq="D"))
evalu = pred + pd.Timedelta(days=2)
X = rng.standard_normal((n, 3))
y = X @ np.array([0.5, -0.3, 0.2]) + rng.standard_normal(n) * 0.1
# N=6, K=2 → C(6,2) = 15 folds → C(5,1) = 5 backtest paths
cv = CombinatorialPurgedCV(
n_splits=6,
n_test_groups=2,
prediction_times=pred,
evaluation_times=evalu,
)
# paths.shape == (n_paths, n_samples); NaN where a sample was not OOS in that path
paths = cv.backtest_paths(DummyRegressor(strategy="mean"), X, y)
print(f"Backtest paths: {paths.shape}") # (5, 120)
# PSR evaluates one strategy's realised RETURN series (not the prediction paths
# above, which are model outputs, not returns). Shown on a synthetic daily series:
strategy_returns = rng.normal(0.0008, 0.01, 504)
psr = probabilistic_sharpe_ratio(strategy_returns, benchmark_skill=0.0)
print(f"PSR: {psr:.3f}") # P(true Sharpe > 0)
# MinTRL: observations needed to show an observed Sharpe beats a benchmark at
# 95% confidence. The Sharpes and the count share one frequency, so a high
# per-bar Sharpe (0.7) needs few bars.
n_min = min_track_record_length(
observed_sharpe=0.7, target_sharpe=0.5, alpha=0.05, skew=0.0, kurtosis=3.0
)
print(f"MinTRL: {int(n_min)} observations")
For the full selection-bias workflow on a real search, the Deflated Sharpe Ratio with the correct var_sharpe, effective_n_trials for correlated Optuna trials, minimum_backtest_length, and PBO are worked end to end on real BTC/USDT data in examples/backtest_overfitting_audit.ipynb. The Deflated Sharpe Ratio deflates by the number of strategy configurations searched (not the number of CPCV paths), with var_sharpe estimated from the spread of trial Sharpes rather than assumed.
Methodology references
- Lopez de Prado, M. (2018). Advances in Financial Machine Learning. Wiley. Chapters 7 (purge/embargo) and 12 (CPCV).
- Bailey, D. H., & Lopez de Prado, M. (2012). The Sharpe Ratio Efficient Frontier. Journal of Risk, 15(2).
- Bailey, D. H., & Lopez de Prado, M. (2014). The Deflated Sharpe Ratio: Correcting for Selection Bias, Backtest Overfitting and Non-Normality. Journal of Portfolio Management, 40(5).
Contributing and development
Bug reports, feature requests, and pull requests are welcome. The full
development setup, the local gates (ruff, black, mypy --strict,
pytest, mkdocs build --strict), the end-to-end test convention, and the
prose-quality gate are documented in CONTRIBUTING.md.
Conduct is governed by the Contributor Covenant;
security reports go through SECURITY.md.
Use of generative AI
This project was developed with the help of AI coding assistants.
They were used to draft and refactor implementation code, expand the test
suite, and edit documentation. The methodology, the public API design, the
choice and execution of every experiment, and all reported numbers are the
author's own: each empirical result in this repository comes from a script
in examples/ or tools/ that is committed and reproducible, and the
numbers were verified against those runs rather than generated as text.
License
MIT. See LICENSE.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file purgedcv-0.1.2.tar.gz.
File metadata
- Download URL: purgedcv-0.1.2.tar.gz
- Upload date:
- Size: 4.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5d8ec69aed8b95eb862bf30602cbc2547f6508437c3d89dd14e6d884fb454580
|
|
| MD5 |
589054927c3a891fa4145a83ca5df826
|
|
| BLAKE2b-256 |
143221efd8216756e57cd10a557c690ed1bdcc1966376c3e59ef0934dd0ef0be
|
File details
Details for the file purgedcv-0.1.2-py3-none-any.whl.
File metadata
- Download URL: purgedcv-0.1.2-py3-none-any.whl
- Upload date:
- Size: 53.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a3826981cc2094356891c923bc12158b2090a08c5b8e43feabd90a5cc6e340cd
|
|
| MD5 |
9052607581cd54b693ce01368911edbb
|
|
| BLAKE2b-256 |
85c8d43212a5109f4897a9e0819d0a44c629cc87449d446d421b1d1266d5cf35
|







