scikit-learn-compatible cross-validation for time-series and financial machine learning: purging, embargoes, combinatorial purged CV, and deflated Sharpe ratios.

Project description
Purged cross validation
scikit-learn-compatible cross-validation for time-series machine learning: purging, embargoes, and combinatorial backtest paths.











Example notebooks → — purge/embargo, walk-forward, and CPCV with PSR/DSR worked end to end on real ICU-mortality, turbofan-RUL, rainfall, and electricity-demand data.
The problem
Standard k-fold cross-validation assumes the rows are independent. Time-series data is not. When a label resolves over the next few days, it overlaps the labels sitting right next to it, so an ordinary shuffle-split leaks tomorrow's answer back into training. The rows immediately after a test window leak too, because they are serially correlated with it. Both effects quietly inflate backtested Sharpe ratios and hand you strategies that look great on a chart and bleed money once they go live. This library removes both.
Why write another one? People have asked scikit-learn, auto-sklearn, and mlpack for purging and embargo support and been turned down or left waiting for years. The one mature implementation, mlfinlab, went closed-source and paid. The free alternative has been unmaintained since 2018. That gap is the reason this exists.
Does it actually catch leakage?
A controlled check on synthetic data whose target is built so that no feature can predict it. The honest out-of-sample score must never be positive. Naive shuffled k-fold runs against PurgedKFold side by side (examples/synthetic_leakage_proof.ipynb, deterministic, no download):
| model | naive shuffled KFold R² | PurgedKFold R² |
|---|---|---|
| predict-the-mean (reference) | -0.01 | -0.13 |
| k-NN | 0.83 | -1.31 |
| RandomForest | 0.91 | -1.94 |
Train/test label overlap: 100% under naive → 0% under PurgedKFold.
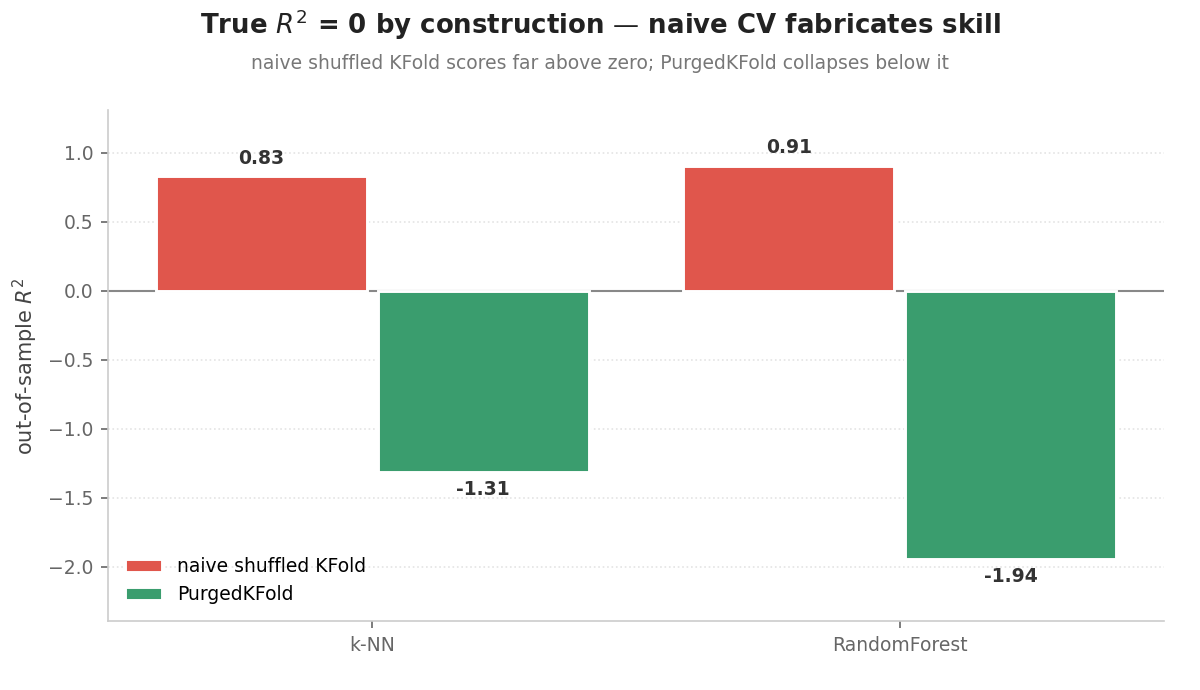
Naive CV reports R² ≈ 0.83–0.91 on a target nothing can predict. That is pure leakage from the overlap. PurgedKFold removes the overlap and the fabricated skill collapses below a predict-the-mean baseline. The negative number is not the point; no positive skill is the correct answer, and only the purged split reports it. The library does not make models look better; it stops them looking better than they are.
Installation
pip install purgedcv
# Directly from the repository
pip install git+https://github.com/eslazarev/purged-cross-validation.git
Quickstart
1. Foundation primitives: purge, apply_embargo, and diagnostics
Build a manual split, clean it with the purge and embargo primitives, then audit it with the diagnostics submodule.
import numpy as np
import pandas as pd
from purgedcv import purge, apply_embargo
from purgedcv.diagnostics import assert_no_temporal_leakage, assert_embargo_respected
# 30 daily bars; each bar's label resolves 2 days later
pred = pd.Series(pd.date_range("2024-01-01", periods=30, freq="D"))
evalu = pred + pd.Timedelta(days=2)
train_idx = np.arange(0, 20)
test_idx = np.arange(20, 30)
# Remove training rows whose label horizon overlaps the test window
clean_train = purge(train_idx, test_idx, pred, evalu)
# Drop the 3-day post-test buffer from training
clean_train = apply_embargo(
clean_train, test_idx, pred, evalu, embargo=pd.Timedelta(days=3)
)
# Assert the split is now leak-free (raises TemporalLeakageError if not)
assert_no_temporal_leakage(clean_train, test_idx, pred, evalu)
assert_embargo_respected(clean_train, test_idx, pred, evalu, embargo="3D")
print(f"Clean training rows: {len(clean_train)}") # 19
2. Splitters with scikit-learn: PurgedKFold inside cross_val_score
Drop-in replacement for KFold that applies purge and embargo automatically on every fold.
import numpy as np
import pandas as pd
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
from purgedcv import PurgedKFold
rng = np.random.default_rng(0)
n = 200
pred = pd.Series(pd.date_range("2022-01-01", periods=n, freq="D"))
evalu = pred + pd.Timedelta(days=3)
X = rng.standard_normal((n, 5))
y = X @ rng.standard_normal(5) + rng.standard_normal(n) * 0.5
cv = PurgedKFold(
n_splits=5,
prediction_times=pred,
evaluation_times=evalu,
purge_horizon="3D", # matches label horizon
embargo="1D", # 1-day post-test buffer
)
scores = cross_val_score(Ridge(), X, y, cv=cv, scoring="r2")
print(f"R² per fold: {scores.round(3)}")
All four splitters (WalkForwardSplit, PurgedKFold, PurgedGroupKFold, CombinatorialPurgedCV) satisfy the sklearn splitter protocol and work inside GridSearchCV and Pipeline.
3. CPCV + path reconstruction + metrics: the full workflow
Combinatorial Purged CV produces C(N, K) folds that tile into multiple out-of-sample backtest paths. Use PSR and DSR to evaluate them with corrections for non-normality and selection bias.
import numpy as np
import pandas as pd
from sklearn.dummy import DummyRegressor
from purgedcv import (
CombinatorialPurgedCV,
probabilistic_sharpe_ratio,
deflated_sharpe_ratio,
min_track_record_length,
)
rng = np.random.default_rng(42)
n = 120
pred = pd.Series(pd.date_range("2023-01-01", periods=n, freq="D"))
evalu = pred + pd.Timedelta(days=2)
X = rng.standard_normal((n, 3))
y = X @ np.array([0.5, -0.3, 0.2]) + rng.standard_normal(n) * 0.1
# N=6, K=2 → C(6,2) = 15 folds → 6-2 = 4 backtest paths
cv = CombinatorialPurgedCV(
n_splits=6,
n_test_groups=2,
prediction_times=pred,
evaluation_times=evalu,
)
# paths.shape == (n_paths, n_samples); NaN where a sample was not OOS
paths = cv.backtest_paths(DummyRegressor(strategy="mean"), X, y)
print(f"Backtest paths: {paths.shape}") # (5, 120)
# Derive a toy "return" series and compute per-path PSR
per_path_returns = paths - y[np.newaxis, :]
per_path_psr = [
probabilistic_sharpe_ratio(row[np.isfinite(row)], benchmark_skill=0.0)
for row in per_path_returns
]
print(f"PSR per path: {[round(p, 3) for p in per_path_psr]}")
# DSR corrects for testing 5 paths simultaneously
first = per_path_returns[0]
dsr = deflated_sharpe_ratio(first[np.isfinite(first)], n_trials=5, var_sharpe=0.01**2)
print(f"Deflated SR (first path): {dsr:.3f}")
# Minimum observations needed to prove SR=0.7 beats benchmark SR=0.5 at 95% confidence
n_min = min_track_record_length(
observed_sharpe=0.7, target_sharpe=0.5, alpha=0.05, skew=0.0, kurtosis=3.0
)
print(f"MinTRL: {int(n_min)} observations")
API summary
| Symbol | Domain | Description |
|---|---|---|
purge |
D2 | Remove overlapping-horizon training rows |
apply_embargo |
D3 | Remove post-test buffer rows |
WalkForwardSplit |
D5.1 | Sliding / expanding walk-forward CV |
PurgedKFold |
D5.2 | Contiguous test folds with purge + embargo |
PurgedGroupKFold |
D5.3 | Group-aware purged k-fold |
CombinatorialPurgedCV |
D5.4 | C(N,K) combinatorial folds |
reconstruct_paths |
D6 | Assemble CPCV folds into backtest paths |
probabilistic_sharpe_ratio |
D7 | PSR: P(true SR > benchmark) |
deflated_sharpe_ratio |
D7 | DSR: PSR corrected for multiple testing |
min_track_record_length |
D7 | Minimum observations to establish SR |
diagnostics.* |
D8 | Leakage and embargo audit functions |
Methodology references
- Lopez de Prado, M. (2018). Advances in Financial Machine Learning. Wiley. Chapters 7 (purge/embargo) and 12 (CPCV).
- Bailey, D. H., & Lopez de Prado, M. (2012). The Sharpe Ratio Efficient Frontier. Journal of Risk, 15(2).
- Bailey, D. H., & Lopez de Prado, M. (2014). The Deflated Sharpe Ratio: Correcting for Selection Bias, Backtest Overfitting and Non-Normality. Journal of Portfolio Management, 40(5).
License
MIT. See LICENSE.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file purgedcv-0.0.4.tar.gz.
File metadata
- Download URL: purgedcv-0.0.4.tar.gz
- Upload date:
- Size: 1.1 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
63c3687f2050004dd103626bf6131fa7f08923698da142164328707806b48570
|
|
| MD5 |
fa980793f2cd0e5a068607a847c0eb53
|
|
| BLAKE2b-256 |
7d68ba8e87671dc86e0cd8b305ad4a1f5574911840408ac41306481065e05ba1
|
File details
Details for the file purgedcv-0.0.4-py3-none-any.whl.
File metadata
- Download URL: purgedcv-0.0.4-py3-none-any.whl
- Upload date:
- Size: 29.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2986bccb0c0b6c50a7e4818c05090cf19d36d13c0d53e7fa6706c237ccb830b6
|
|
| MD5 |
50141c7c2c1a93a248539769a7be74d3
|
|
| BLAKE2b-256 |
0a352f61f4e668d2ac6b650ceafbb1efaee736cf2dba9d8762fd6ba463a53d1e
|







