Python Rate-Limiter using Leaky-Bucket Algorithm
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Project description

PyrateLimiter
The request rate limiter using Leaky-bucket Algorithm.
Full project documentation can be found at pyratelimiter.readthedocs.io.





Upgrading from v3.x? See the Migration Guide for breaking changes.
Contents
- Features
- Installation
- Web Requests
- Quickstart
- Basic usage
- Advanced Usage
Features
- Supports unlimited rate limits and custom intervals.
- Separately tracks limits for different services or resources.
- Manages limit breaches with configurable blocking or non-blocking behavior.
- Offers multiple usage modes: direct calls or decorators.
- Fully compatible with both synchronous and asynchronous workflows.
- Provides SQLite and Redis backends for persistent limit tracking across threads or restarts.
- Includes MultiprocessBucket and SQLite File Lock backends for multiprocessing environments.
Installation
PyrateLimiter supports python ^3.8
Install using pip:
pip install pyrate-limiter
Or using conda:
conda install --channel conda-forge pyrate-limiter
Quickstart
To limit 5 requests within 2 seconds:
from pyrate_limiter import Duration, Rate, Limiter
limiter = Limiter(Rate(5, Duration.SECOND * 2))
# Blocking mode (default) - waits until permit available
for i in range(6):
limiter.try_acquire(str(i))
print(f"Acquired permit {i}")
# Non-blocking mode - returns False if bucket full
for i in range(6):
success = limiter.try_acquire(str(i), blocking=False)
if not success:
print(f"Rate limited at {i}")
limiter_factory
limiter_factory.py provides several functions to simplify common cases:
- create_sqlite_limiter(rate_per_duration: int, duration: Duration, ...)
- create_inmemory_limiter(rate_per_duration: int, duration: Duration, ...)
-
- more to be added...
Examples
- Rate limiting asyncio tasks: asyncio_ratelimit.py
- Rate limiting asyncio tasks w/ a decorator: asyncio_decorator.py
- HTTPX rate limiting - asyncio, single process and multiprocess examples httpx_ratelimiter.py
- Multiprocessing using an in-memory rate limiter - in_memory_multiprocess.py
- Multiprocessing using SQLite and a file lock - this can be used for distributed processes not created within a multiprocessing sql_filelock_multiprocess.py
Web Request Rate Limiting
pyrate_limiter provides three extras for popular web request libraries:
AIOHTTP
from pyrate_limiter import limiter_factory
from pyrate_limiter.extras.aiohttp_limiter import RateLimitedSession
limiter = limiter_factory.create_inmemory_limiter(rate_per_duration=2, duration=Duration.SECOND)
session = RateLimitedSession(limiter)
Example: aiohttp_ratelimiter.py
HTTPX
from pyrate_limiter import limiter_factory
from pyrate_limiter.extras.httpx_limiter import AsyncRateLimiterTransport, RateLimiterTransport
import httpx
limiter = limiter_factory.create_inmemory_limiter(rate_per_duration=1, duration=Duration.SECOND, max_delay=Duration.HOUR)
url = "https://example.com"
with httpx.Client(transport=RateLimiterTransport(limiter=limiter)) as client:
client.get(url)
# or async
async with httpx.AsyncClient(transport=AsyncRateLimiterTransport(limiter=limiter)) as client:
client.get(url)
...
Example: httpx_ratelimiter.py
Requests
from pyrate_limiter import limiter_factory
from pyrate_limiter.extras.requests_limiter import RateLimitedRequestsSession
limiter = limiter_factory.create_inmemory_limiter(rate_per_duration=2, duration=Duration.SECOND)
session = RateLimitedRequestsSession(limiter)
....
Example: requests_ratelimiter.py
Basic Usage
Key concepts
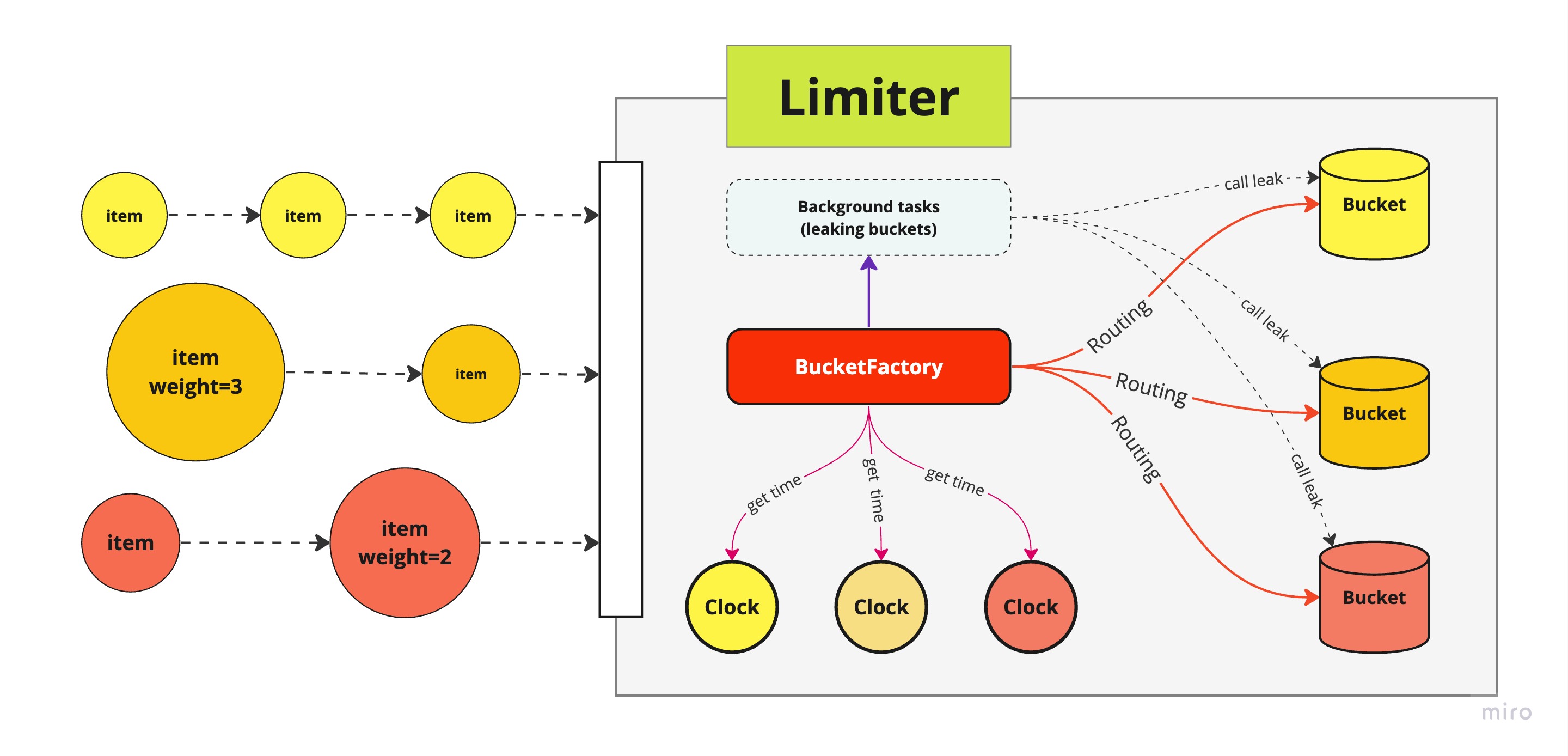
Clock
- Timestamps incoming items
Bucket
- Stores items with timestamps.
- Functions as a FIFO queue.
- Can
leakto remove outdated items.
BucketFactory
- Manages buckets and clocks, routing items to their appropriate buckets.
- Schedules periodic
leakoperations to prevent overflow. - Allows custom logic for routing, conditions, and timing.
Limiter
- Provides a simple, intuitive API by abstracting underlying logic.
- Seamlessly supports both sync and async contexts.
- Offers multiple interaction modes: direct calls, decorators, and (future) context managers.
- Ensures thread-safety via RLock, and if needed, asyncio concurrency via asyncio.Lock
Defining rate limits and buckets
For example, an API (like LinkedIn or GitHub) might have these rate limits:
- 500 requests per hour
- 1000 requests per day
- 10000 requests per month
You can define these rates using the Rate class. Rate class has 2 properties only: limit and interval
from pyrate_limiter import Duration, Rate
hourly_rate = Rate(500, Duration.HOUR) # 500 requests per hour
daily_rate = Rate(1000, Duration.DAY) # 1000 requests per day
monthly_rate = Rate(10000, Duration.WEEK * 4) # 10000 requests per month
rates = [hourly_rate, daily_rate, monthly_rate]
Rates must be properly ordered:
- Rates' intervals & limits must be ordered from least to greatest
- Rates' ratio of limit/interval must be ordered from greatest to least
Buckets validate rates during initialization. If using a custom implementation, use the built-in validator:
from pyrate_limiter import validate_rate_list
assert validate_rate_list(my_rates)
Then, add the rates to the bucket of your choices
from pyrate_limiter import InMemoryBucket, RedisBucket
basic_bucket = InMemoryBucket(rates)
# Or, using redis
from redis import Redis
redis_connection = Redis(host='localhost')
redis_bucket = RedisBucket.init(rates, redis_connection, "my-bucket-name")
# Async Redis would work too!
from redis.asyncio import Redis
redis_connection = Redis(host='localhost')
redis_bucket = await RedisBucket.init(rates, redis_connection, "my-bucket-name")
If you only need a single Bucket for everything, and python's built-in time() is enough for you, then pass the bucket to Limiter then ready to roll!
from pyrate_limiter import Limiter
# Limiter constructor accepts single bucket as the only parameter,
# the rest are 3 optional parameters with default values as following
# Limiter(bucket, clock=MonotonicClock(), raise_when_fail=True, max_delay=None)
limiter = Limiter(bucket)
# Limiter is now ready to work!
limiter.try_acquire("hello world")
If you want to have finer grain control with routing & clocks etc, then you should use BucketFactory.
Defining Clock & routing logic with BucketFactory
When multiple bucket types are needed and items must be routed based on certain conditions, use BucketFactory.
First, define your clock (time source). Most use cases work with the built-in clocks:
from pyrate_limiter.clock import MonotonicClock, SQLiteClock
base_clock = MonotonicClock()
PyrateLimiter does not assume routing logic, so you implement a custom BucketFactory. At a minimum, these two methods must be defined:
from pyrate_limiter import BucketFactory
from pyrate_limiter import AbstractBucket
class MyBucketFactory(BucketFactory):
# You can use constructor here,
# nor it requires to make bucket-factory work!
def wrap_item(self, name: str, weight: int = 1) -> RateItem:
"""Time-stamping item, return a RateItem"""
now = clock.now()
return RateItem(name, now, weight=weight)
def get(self, _item: RateItem) -> AbstractBucket:
"""For simplicity's sake, all items route to the same, single bucket"""
return bucket
Creating buckets dynamically
If more than one bucket is needed, the bucket-routing logic should go to BucketFactory get(..) method.
When creating buckets dynamically, it is needed to schedule leak for each newly created buckets.
To support this, BucketFactory comes with a predefined method call self.create(..). It is meant to create the bucket and schedule that bucket for leaking using the Factory's clock
def create(
self,
clock: AbstractClock,
bucket_class: Type[AbstractBucket],
*args,
**kwargs,
) -> AbstractBucket:
"""Creating a bucket dynamically"""
bucket = bucket_class(*args, **kwargs)
self.schedule_leak(bucket, clock)
return bucket
By utilizing this, we can modify the code as following:
class MultiBucketFactory(BucketFactory):
def __init__(self, clock):
self.clock = clock
self.buckets = {}
def wrap_item(self, name: str, weight: int = 1) -> RateItem:
"""Time-stamping item, return a RateItem"""
now = clock.now()
return RateItem(name, now, weight=weight)
def get(self, item: RateItem) -> AbstractBucket:
if item.name not in self.buckets:
# Use `self.create(..)` method to both initialize new bucket and calling `schedule_leak` on that bucket
# We can create different buckets with different types/classes here as well
new_bucket = self.create(YourBucketClass, *your-arguments, **your-keyword-arguments)
self.buckets.update({item.name: new_bucket})
return self.buckets[item.name]
Wrapping all up with Limiter
Pass your bucket-factory to Limiter, and ready to roll!
from pyrate_limiter import Limiter
limiter = Limiter(
bucket_factory,
raise_when_fail=False, # Default = True
max_delay=1000, # Default = None
)
item = "the-earth"
limiter.try_acquire(item)
heavy_item = "the-sun"
limiter.try_acquire(heavy_item, weight=10000)
asyncio and event loops
To ensure the event loop isn't blocked, use try_acquire_async with an async bucket, which leverages asyncio.Lock for concurrency control.
If your bucket isn't async, wrap it with BucketAsyncWrapper. This ensures asyncio.sleep is used instead of time.sleep, preventing event loop blocking:
await limiter.try_acquire_async(item)
Example: asyncio_ratelimit.py
as_decorator(): use limiter as decorator
Limiter can be used as a decorator with name and weight parameters.
The decorator works with both synchronous and asynchronous functions:
from pyrate_limiter import Rate, Duration, Limiter
limiter = Limiter(Rate(5, Duration.SECOND))
@limiter.as_decorator(name="api_call", weight=1)
def handle_something(*args, **kwargs):
"""function logic"""
@limiter.as_decorator(name="background_job", weight=2)
async def handle_something_async(*args, **kwargs):
"""async function logic"""
For full example see asyncio_decorator.py
Limiter API
bucket(): get list of all active buckets
Return list of all active buckets with limiter.buckets()
dispose(bucket: int | BucketObject): dispose/remove/delete the given bucket
Method signature:
def dispose(self, bucket: Union[int, AbstractBucket]) -> bool:
"""Dispose/Remove a specific bucket,
using bucket-id or bucket object as param
"""
Example of usage:
active_buckets = limiter.buckets()
assert len(active_buckets) > 0
bucket_to_remove = active_buckets[0]
assert limiter.dispose(bucket_to_remove)
If a bucket is found and get deleted, calling this method will return True, otherwise False. If there is no more buckets in the limiter's bucket-factory, all the leaking tasks will be stopped.
Context Manager
Limiter supports the context manager protocol for automatic cleanup:
from pyrate_limiter import Limiter, RequestRate, Duration, InMemoryBucket
# Define a simple rate and create a bucket
rate = RequestRate(5, Duration.SECOND)
bucket = InMemoryBucket(rate)
# Use Limiter as a context manager
with Limiter(bucket) as limiter:
limiter.try_acquire("item")
# Resources automatically released
# Or manually close
limiter = Limiter(bucket)
try:
limiter.try_acquire("item")
finally:
limiter.close()
Weight
Item can have weight. By default item's weight = 1, but you can modify the weight before passing to limiter.try_acquire.
Item with weight W > 1 when consumed will be multiplied to (W) items with the same timestamp and weight = 1. Example with a big item with weight W=5, when put to bucket, it will be divided to 5 items with weight=1 + following names
BigItem(weight=5, name="item", timestamp=100) => [
item(weight=1, name="item", timestamp=100),
item(weight=1, name="item", timestamp=100),
item(weight=1, name="item", timestamp=100),
item(weight=1, name="item", timestamp=100),
item(weight=1, name="item", timestamp=100),
]
Yet, putting this big, heavy item into bucket is expected to be transactional & atomic - meaning either all 5 items will be consumed or none of them will. This is made possible as bucket put(item) always check for available space before ingesting. All of the Bucket's implementations provided by PyrateLimiter follows this rule.
Any additional, custom implementation of Bucket are expected to behave alike - as we have unit tests to cover the case.
See Advanced Usage below for more details.
Handling exceeded limits
When a rate limit is exceeded, you can choose between blocking and non-blocking behavior.
Bucket analogy
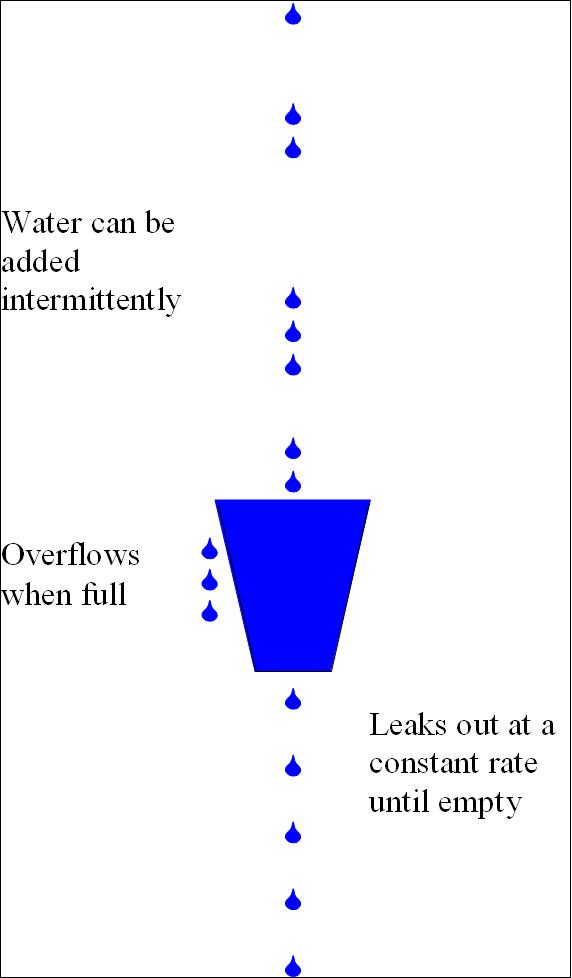
At this point it's useful to introduce the analogy of "buckets" used for rate-limiting. Here is a quick summary:
- This library implements the Leaky Bucket algorithm.
- It is named after the idea of representing some kind of fixed capacity -- like a network or service -- as a bucket.
- The bucket "leaks" at a constant rate. For web services, this represents the ideal or permitted request rate.
- The bucket is "filled" at an intermittent, unpredicatble rate, representing the actual rate of requests.
- When the bucket is "full", it will overflow, representing canceled or delayed requests.
- Item can have weight. Consuming a single item with weight W > 1 is the same as consuming W smaller, unit items - each with weight=1, with the same timestamp and maybe same name (depending on however user choose to implement it)
Blocking vs Non-blocking
By default, try_acquire blocks until a permit becomes available:
from pyrate_limiter import Rate, Limiter, Duration
rate = Rate(3, Duration.SECOND)
limiter = Limiter(rate)
# Blocking (default) - waits until permit is available
for i in range(5):
limiter.try_acquire("item") # blocks if bucket is full
print(f"Acquired {i}")
For non-blocking behavior, set blocking=False to return immediately:
# Non-blocking - returns False immediately if bucket is full
for i in range(5):
success = limiter.try_acquire("item", blocking=False)
if not success:
print(f"Rate limited at request {i}")
break
For async code, use try_acquire_async with optional timeout:
# Async with timeout (in seconds)
success = await limiter.try_acquire_async("item", timeout=5)
if not success:
print("Timed out waiting for permit")
The buffer_ms parameter (default 50ms) adds a small delay buffer to account for timing variations:
from pyrate_limiter import Duration, InMemoryBucket, Limiter, RequestRate
rate = RequestRate(5, Duration.SECOND)
bucket = InMemoryBucket(rate)
limiter = Limiter(bucket, buffer_ms=100) # 100ms buffer
Backends
A few different bucket backends are available:
- InMemoryBucket: using python built-in list as bucket
- MultiprocessBucket: uses a multiprocessing lock for distributed concurrency with a ListProxy as the bucket
- RedisBucket, using err... redis, with both async/sync support
- PostgresBucket, using
psycopg2 - SQLiteBucket, using sqlite3
- BucketAsyncWrapper: wraps an existing bucket with async interfaces, to avoid blocking the event loop
InMemoryBucket
The default bucket is stored in memory, using python list
from pyrate_limiter import InMemoryBucket, Rate, Duration
rates = [Rate(5, Duration.MINUTE * 2)]
bucket = InMemoryBucket(rates)
This bucket only availabe in sync mode. The only constructor argument is List[Rate].
MultiprocessBucket
MultiprocessBucket uses a ListProxy to store items within a python multiprocessing pool or ProcessPoolExecutor. Concurrency is enforced via a multiprocessing Lock.
The bucket is shared across instances.
An example is provided in in_memory_multiprocess
Whenever multiprocessing, bucket.waiting calculations will be often wrong because of the concurrency involved. Set Limiter.retry_until_max_delay=True so that the item keeps retrying rather than returning False when contention causes an extra delay.
RedisBucket
RedisBucket uses Sorted-Set to store items with key being item's name and score item's timestamp
Because it is intended to work with both async & sync, we provide a classmethod init for it
from pyrate_limiter import RedisBucket, Rate, Duration
# Using synchronous redis
from redis import ConnectionPool
from redis import Redis
rates = [Rate(5, Duration.MINUTE * 2)]
pool = ConnectionPool.from_url("redis://localhost:6379")
redis_db = Redis(connection_pool=pool)
bucket_key = "bucket-key"
bucket = RedisBucket.init(rates, redis_db, bucket_key)
# Using asynchronous redis
from redis.asyncio import ConnectionPool as AsyncConnectionPool
from redis.asyncio import Redis as AsyncRedis
pool = AsyncConnectionPool.from_url("redis://localhost:6379")
redis_db = AsyncRedis(connection_pool=pool)
bucket_key = "bucket-key"
bucket = await RedisBucket.init(rates, redis_db, bucket_key)
The API are the same, regardless of sync/async. If AsyncRedis is being used, calling await bucket.method_name(args) would just work!
SQLiteBucket
If you need to persist the bucket state, a SQLite backend is available. The SQLite bucket works in sync manner.
Manully create a connection to Sqlite and pass it along with the table name to the bucket class:
from pyrate_limiter import SQLiteBucket, Rate, Duration
import sqlite3
rates = [Rate(5, Duration.MINUTE * 2)]
bucket = SQLiteBucket.init_from_file(rates)
from pyrate_limiter import Rate, Limiter, Duration, SQLiteBucket
requests_per_minute = 5
rate = Rate(requests_per_minute, Duration.MINUTE)
bucket = SQLiteBucket.init_from_file([rate], use_file_lock=False) # set use_file_lock to True if using across multiple processes
limiter = Limiter(bucket, raise_when_fail=False, max_delay=max_delay)
You can also pass custom arguments to the init_from_file following its signature:
class SQLiteBucket(AbstractBucket):
@classmethod
def init_from_file(
cls,
rates: List[Rate],
table: str = "rate_bucket",
db_path: Optional[str] = None,
create_new_table = True,
use_file_lock: bool = False
) -> "SQLiteBucket":
...
Options:
db_path: If not provided, usestempdir / "pyrate-limiter.sqlite"use_file_lock: Should be False for single process workloads. For multi process, uses a filelock to ensure single access to the SQLite bucket across multiple processes, allowing multi process rate limiting on a single host.
Example: limiter_factory.py::create_sqlite_limiter()
PostgresBucket
Postgres is supported, but you have to install psycopg[pool] either as an extra or as a separate package. The PostgresBucket currently does not support async.
You can use Postgres's built-in CURRENT_TIMESTAMP as the time source with PostgresClock, or use an external custom time source.
from pyrate_limiter import PostgresBucket, Rate, PostgresClock
from psycopg_pool import ConnectionPool
connection_pool = ConnectionPool('postgresql://postgres:postgres@localhost:5432')
clock = PostgresClock(connection_pool)
rates = [Rate(3, 1000), Rate(4, 1500)]
bucket = PostgresBucket(connection_pool, "my-bucket-table", rates)
BucketAsyncWrapper
The BucketAsyncWrapper wraps a sync bucket to ensure all its methods return awaitables. This allows the Limiter to detect asynchronous behavior and use asyncio.sleep() instead of time.sleep() during delay handling, preventing blocking of the asyncio event loop.
Example: limiter_factory.py::create_inmemory_limiter()
Async or Sync or Multiprocessing
The Limiter is basically made of a Clock backend and a Bucket backend. The backends may be async or sync, which determines the Limiters internal behavior, regardless of whether the caller enters via a sync or async function.
try_acquire_async: When calling from an async context, use try_acquire_async. This uses a thread-local asyncio lock to ensure only one asyncio task is acquiring, followed by a global RLock so that only one thread is acquiring.
try_acquire: When called directly, the global RLock enforces only one thread at a time.
Multiprocessing: If using MultiprocessBucket, two locks are used in Limiter: a top level multiprocessing lock, then a thread level RLock
Advanced Usage
Component level diagram
Time sources
Time source can be anything from anywhere: be it python's built-in time, or monotonic clock, sqliteclock, or crawling from world time server(well we don't have that, but you can!).
from pyrate_limiter import MonotonicClock # use python time.monotonic()
Clock's abstract interface only requires implementing a method now() -> int. And it can be both sync or async.
Leaking
Typically bucket should not hold items forever. Bucket's abstract interface requires its implementation must be provided with leak(current_timestamp: Optional[int] = None).
The leak method when called is expected to remove any items considered outdated at that moment. During Limiter lifetime, all the buckets' leak should be called periodically.
BucketFactory provide a method called schedule_leak to help deal with this matter. Basically, it will run as a background task for all the buckets currently in use, with interval between leak call by default is 10 seconds.
# Runnning a background task (whether it is sync/async - doesnt matter)
# calling the bucket's leak
factory.schedule_leak(bucket, clock)
You can change this calling interval by overriding BucketFactory's leak_interval property. This interval is in miliseconds.
class MyBucketFactory(BucketFactory):
def __init__(self, *args):
self.leak_interval = 300
When dealing with leak using BucketFactory, the author's suggestion is, we can be pythonic about this by implementing a constructor
class MyBucketFactory(BucketFactory):
def constructor(self, clock, buckets):
self.clock = clock
self.buckets = buckets
for bucket in buckets:
self.schedule_leak(bucket, clock)
Concurrency
Generally, Lock is provided at Limiter's level, except SQLiteBucket case.
Custom backends
If these don't suit your needs, you can also create your own bucket backend by implementing pyrate_limiter.AbstractBucket class.
One of PyrateLimiter design goals is powerful extensibility and maximum ease of development.
It must be not only be a ready-to-use tool, but also a guide-line, or a framework that help implementing new features/bucket free of the most hassles.
Due to the composition nature of the library, it is possbile to write minimum code and validate the result:
- Fork the repo
- Implement your bucket with
pyrate_limiter.AbstractBucket - Add your own
create_bucketmethod intests/conftest.pyand pass it to thecreate_bucketfixture - Run the test suite to validate the result
If the tests pass through, then you are just good to go with your new, fancy bucket!
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pyrate_limiter-4.0.2.tar.gz.
File metadata
- Download URL: pyrate_limiter-4.0.2.tar.gz
- Upload date:
- Size: 301.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b678841e2215f114ef6f98c7093755ca3b466de83cb5a881231fd6e321fa14b5
|
|
| MD5 |
ca25886443b3df36fa305c2357977147
|
|
| BLAKE2b-256 |
03982b3dc1ba6bdf2efaeaa3e102124cbd2636a4ccec241ffeb8a1de207f5cd4
|
Provenance
The following attestation bundles were made for pyrate_limiter-4.0.2.tar.gz:
Publisher:
build_test.yml on vutran1710/PyrateLimiter
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pyrate_limiter-4.0.2.tar.gz -
Subject digest:
b678841e2215f114ef6f98c7093755ca3b466de83cb5a881231fd6e321fa14b5 - Sigstore transparency entry: 845970415
- Sigstore integration time:
-
Permalink:
vutran1710/PyrateLimiter@634d16686b7707bca8ed3534051982791b9ef355 -
Branch / Tag:
refs/tags/v4.0.2 - Owner: https://github.com/vutran1710
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
build_test.yml@634d16686b7707bca8ed3534051982791b9ef355 -
Trigger Event:
push
-
Statement type:
File details
Details for the file pyrate_limiter-4.0.2-py3-none-any.whl.
File metadata
- Download URL: pyrate_limiter-4.0.2-py3-none-any.whl
- Upload date:
- Size: 36.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
35ec42b9bb9cfabcafab14d0c5c6523f48378c3da2949e534ce3cbdfea71eadd
|
|
| MD5 |
bc34dd478318e16eaf78d4b3a4d4d0fa
|
|
| BLAKE2b-256 |
13b980ffe3f2c34d3247186d74b1d08c1fed1e3ad4127ff6a8a5501b7bf16a97
|
Provenance
The following attestation bundles were made for pyrate_limiter-4.0.2-py3-none-any.whl:
Publisher:
build_test.yml on vutran1710/PyrateLimiter
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
pyrate_limiter-4.0.2-py3-none-any.whl -
Subject digest:
35ec42b9bb9cfabcafab14d0c5c6523f48378c3da2949e534ce3cbdfea71eadd - Sigstore transparency entry: 845970423
- Sigstore integration time:
-
Permalink:
vutran1710/PyrateLimiter@634d16686b7707bca8ed3534051982791b9ef355 -
Branch / Tag:
refs/tags/v4.0.2 - Owner: https://github.com/vutran1710
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
build_test.yml@634d16686b7707bca8ed3534051982791b9ef355 -
Trigger Event:
push
-
Statement type:







