RAGWire — Production-grade RAG toolkit for document ingestion and retrieval with hybrid search support
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

RAGWire
Production-grade RAG toolkit for document ingestion and retrieval




Features
- Document Loading — PDF, DOCX, XLSX, PPTX and more via MarkItDown
- LLM Metadata Extraction — extracts company, doc type, fiscal period using your LLM; fully customisable via YAML
- Smart Text Splitting — markdown-aware and recursive chunking strategies
- Multiple Embedding Providers — Ollama, OpenAI, HuggingFace, Google, FastEmbed
- Qdrant Vector Store — dense, sparse, and hybrid search
- Advanced Retrieval — similarity, MMR, and hybrid search with metadata filtering
- SHA256 Deduplication — at both file and chunk level
- Directory Ingestion — ingest an entire folder with one call, with optional recursive scan
- Env Var Substitution — use
${VAR}inconfig.yamlfor secrets
Architecture
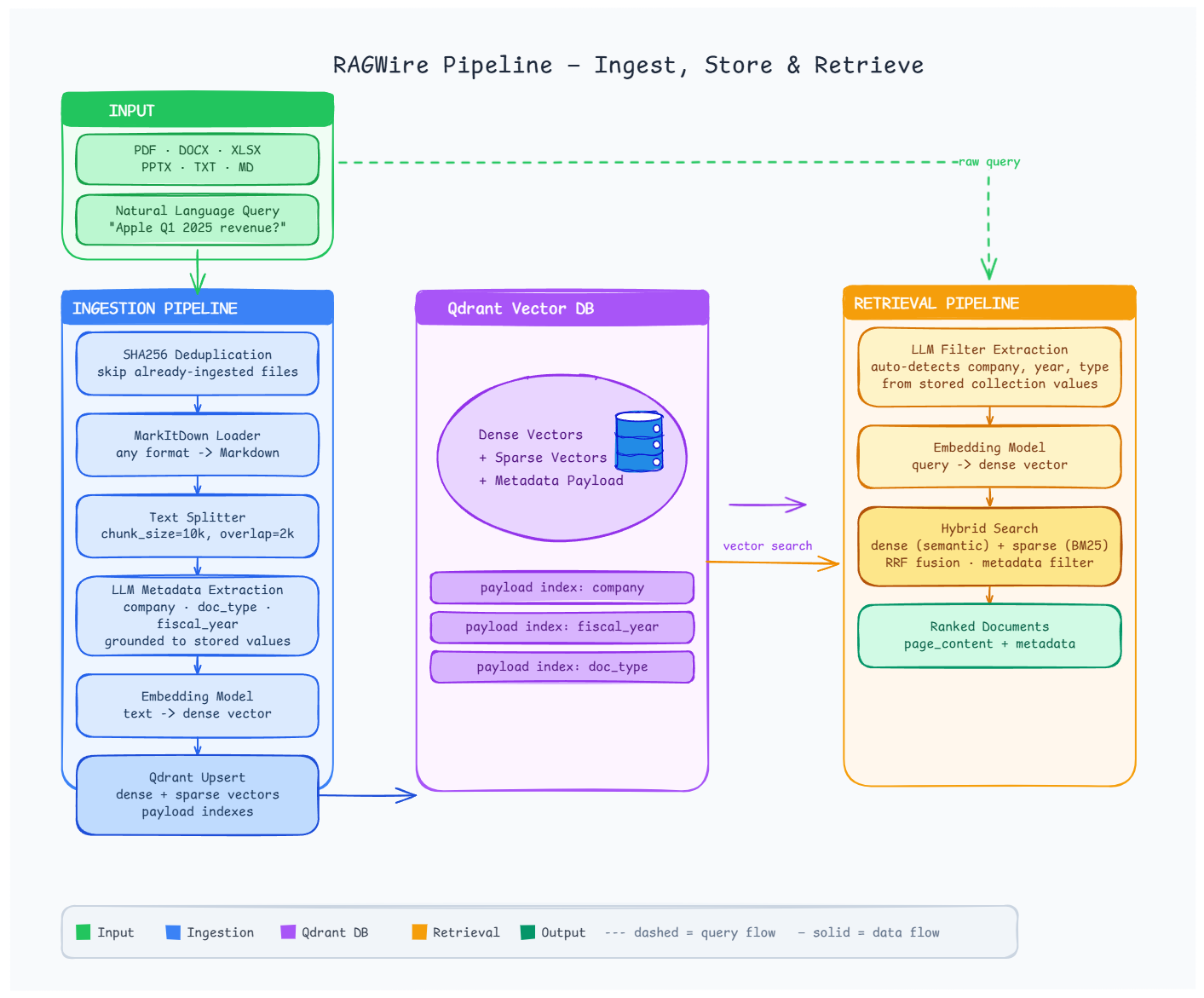
Installation
pip install ragwire
# With Ollama support (local, no API key)
pip install "ragwire[ollama]"
# With all providers
pip install "ragwire[all]"
Quick Start
from ragwire import RAGWire
rag = RAGWire("config.yaml")
# Ingest files — SHA256 deduplication, safe to re-run
stats = rag.ingest_documents(["data/Apple_10k_2025.pdf", "data/Microsoft_10k_2025.pdf"])
print(f"Processed: {stats['processed']}, Skipped: {stats['skipped']}, Chunks: {stats['chunks_created']}")
# Or ingest an entire directory
stats = rag.ingest_directory("data/", recursive=True)
# Basic retrieval — returns list of LangChain Document objects
results = rag.retrieve("What is the total revenue?", top_k=5)
for doc in results:
print(doc.page_content[:300])
print(doc.metadata["company_name"]) # str, lowercased — e.g. "apple"
print(doc.metadata["fiscal_year"]) # list[int] — e.g. [2025] ← NOT a plain int
print(doc.metadata["file_name"]) # str — e.g. "Apple_10k_2025.pdf"
# Retrieval with explicit metadata filters
results = rag.retrieve(
"What is the net income?",
filters={"company_name": "apple", "fiscal_year": 2025} # pass year as int
)
# OR logic within a field — matches any of the listed values
results = rag.retrieve("Compare revenue trends", filters={"fiscal_year": [2023, 2024, 2025]})
# Agent-controlled filtering (recommended for AI agents)
filters = rag.extract_filters("Apple's revenue in 2025")
# → {"company_name": "apple", "fiscal_year": 2025} or None
results = rag.retrieve("Apple's revenue in 2025", filters=filters)
Configuration
Copy config.example.yaml to config.yaml and edit. Secrets can be injected via environment variables:
vectorstore:
url: "https://your-cluster.qdrant.io"
api_key: "${QDRANT_API_KEY}"
llm:
provider: "openai"
model: "gpt-5.4-nano"
api_key: "${OPENAI_API_KEY}"
Full example:
embeddings:
provider: "ollama"
model: "qwen3-embedding:0.6b"
base_url: "http://localhost:11434"
llm:
provider: "ollama"
model: "qwen3.5:9b"
num_ctx: 16384
vectorstore:
url: "http://localhost:6333"
collection_name: "my_docs"
use_sparse: true
retriever:
search_type: "hybrid"
top_k: 5
auto_filter: false # set true to enable LLM-based filter extraction from every query
Embedding Providers
# Ollama (local)
embeddings:
provider: "ollama"
model: "qwen3-embedding:0.6b"
# OpenAI
embeddings:
provider: "openai"
model: "text-embedding-3-small"
# HuggingFace (local)
embeddings:
provider: "huggingface"
model_name: "sentence-transformers/all-MiniLM-L6-v2"
# Google
embeddings:
provider: "google"
model: "models/embedding-001"
Component Usage
from ragwire import (
MarkItDownLoader,
get_splitter,
get_markdown_splitter,
get_embedding,
QdrantStore,
MetadataExtractor,
hybrid_search,
mmr_search,
)
# Load a document
loader = MarkItDownLoader()
result = loader.load("document.pdf")
# Split text
splitter = get_markdown_splitter(chunk_size=10000, chunk_overlap=2000)
chunks = splitter.split_text(result["text_content"])
# Embeddings
embedding = get_embedding({"provider": "ollama", "model": "qwen3-embedding:0.6b"})
# Vector store
store = QdrantStore(config={"url": "http://localhost:6333"}, embedding=embedding)
store.set_collection("my_collection")
vectorstore = store.get_store()
Architecture
ragwire/
├── core/ # Config loader + RAGWire orchestrator
├── loaders/ # MarkItDown document converter
├── processing/ # Text splitters + SHA256 hashing
├── metadata/ # Pydantic schema + LLM extractor
├── embeddings/ # Multi-provider embedding factory
├── vectorstores/ # Qdrant wrapper with hybrid search
├── retriever/ # Similarity, MMR, hybrid retrieval
└── utils/ # Logging
Troubleshooting
| Error | Fix |
|---|---|
| Qdrant connection refused | docker run -p 6333:6333 qdrant/qdrant |
markitdown[pdf] missing |
pip install "markitdown[pdf]" |
| Ollama model not found | ollama pull <model-name> |
fastembed missing |
pip install fastembed (needed for hybrid search) |
| Embedding dimension mismatch | Set force_recreate: true in config once, then back to false |
License
MIT © 2026 KGP Talkie Private Limited
Links



- 🌐 Website: kgptalkie.com
- 📖 Docs: laxmimerit.github.io/RAGWire
- 💻 GitHub: github.com/laxmimerit/ragwire
- 📧 Email: udemy@kgptalkie.com
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ragwire-1.2.9.tar.gz.
File metadata
- Download URL: ragwire-1.2.9.tar.gz
- Upload date:
- Size: 3.6 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
31d1bccbcfb616244a5f5740e0fc75e60789b6d7f88a2081b7eb845c698125b8
|
|
| MD5 |
6818a916ef6ffd02634c0c558bcf9fad
|
|
| BLAKE2b-256 |
f14605eff4c911bf1e15bf3ff196349cbd53aca9e6fa3dd5383313da928aa6d8
|
Provenance
The following attestation bundles were made for ragwire-1.2.9.tar.gz:
Publisher:
publish.yml on laxmimerit/RAGWire
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
ragwire-1.2.9.tar.gz -
Subject digest:
31d1bccbcfb616244a5f5740e0fc75e60789b6d7f88a2081b7eb845c698125b8 - Sigstore transparency entry: 1340706489
- Sigstore integration time:
-
Permalink:
laxmimerit/RAGWire@f0c915a4bfe6e2c04c033bea7926a72f156f2789 -
Branch / Tag:
refs/tags/v1.2.9 - Owner: https://github.com/laxmimerit
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@f0c915a4bfe6e2c04c033bea7926a72f156f2789 -
Trigger Event:
release
-
Statement type:
File details
Details for the file ragwire-1.2.9-py3-none-any.whl.
File metadata
- Download URL: ragwire-1.2.9-py3-none-any.whl
- Upload date:
- Size: 3.6 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c26bd857dcb5c084c2c4088855e1eb5b13b34f6d345b3ba0b298e41bec3052df
|
|
| MD5 |
e1380aca4f3777cfce4e56dc4a6e0180
|
|
| BLAKE2b-256 |
530ac0a6d92176f57bce2a85834488fc7cfbde7f3ddc67a042e199956d8f78c4
|
Provenance
The following attestation bundles were made for ragwire-1.2.9-py3-none-any.whl:
Publisher:
publish.yml on laxmimerit/RAGWire
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
ragwire-1.2.9-py3-none-any.whl -
Subject digest:
c26bd857dcb5c084c2c4088855e1eb5b13b34f6d345b3ba0b298e41bec3052df - Sigstore transparency entry: 1340706491
- Sigstore integration time:
-
Permalink:
laxmimerit/RAGWire@f0c915a4bfe6e2c04c033bea7926a72f156f2789 -
Branch / Tag:
refs/tags/v1.2.9 - Owner: https://github.com/laxmimerit
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@f0c915a4bfe6e2c04c033bea7926a72f156f2789 -
Trigger Event:
release
-
Statement type:







