Powering community nowcasts at www.microprediction.org

Project description
Rediz
Server code for open community microprediction at www.microprediction.org.
Microprediction.Org
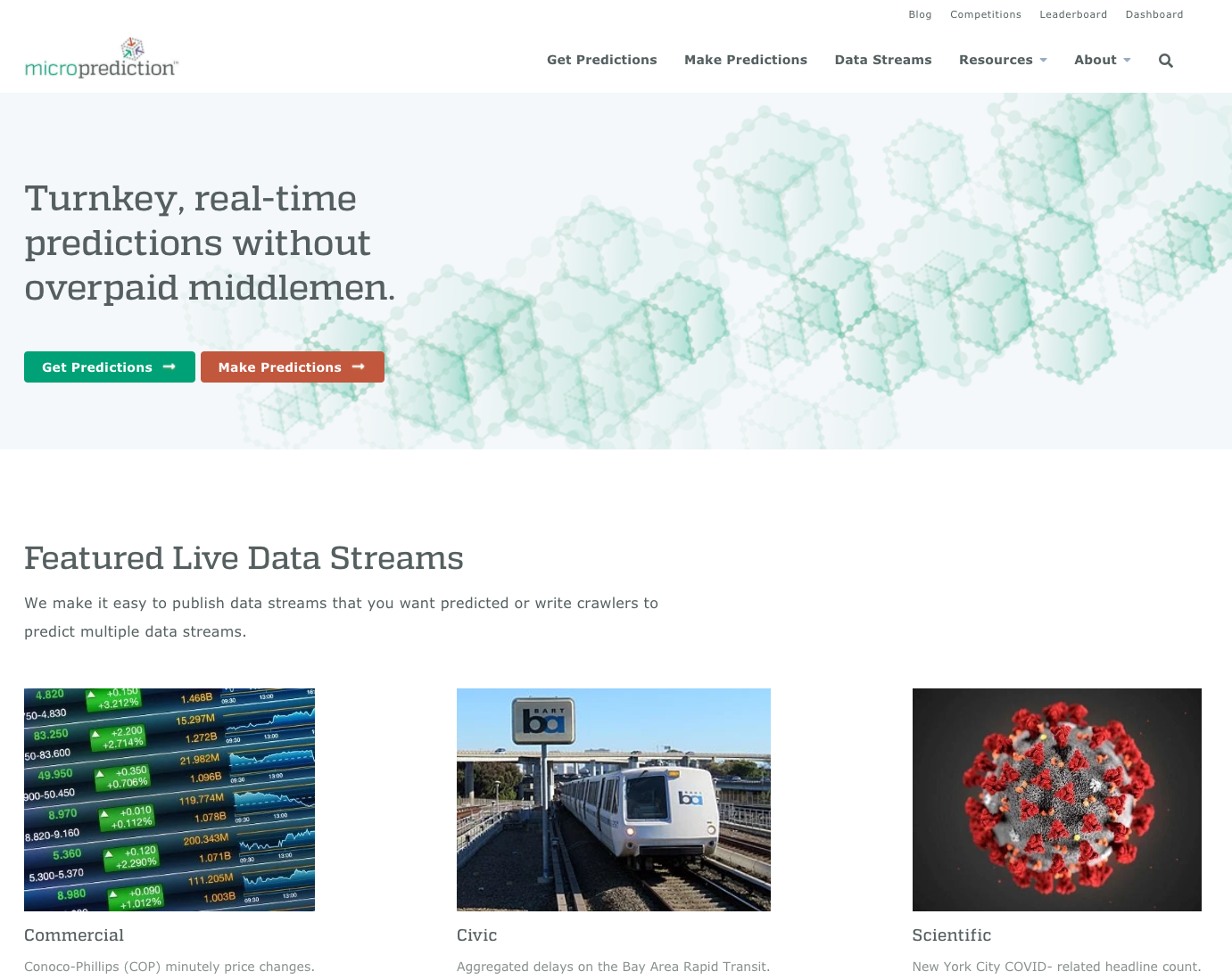
Overview
The python packages called "microprediction" (user client library) and "rediz" (system implementation using redis as transport) are demonstrated at www.microprediction.org, where they make it easy for anyone who needs a live source of data predicted to receive help from clever humans and self-navigating time series algorithms. They do this by:
- Obtaining a write_key with microconventions.create_key(difficulty=12), which takes several hours
- Using the write_key to update a live quantity, such as https://www.microprediction.org/live/cop.json
- Repeating often.
They can then access history (e.g. https://www.microprediction.org/live/lagged::cop.json) and predictions (e.g. https://www.microprediction.org/cdf/cop.json). This is an easy way to normalize data and perform anomaly detection. Over time it may garner other insights such as assessment of the predictive value of the data stream the identities of streams that might be causally related.
This setup is especially well suited to collective prediction of civic data streams such as transport, water, electricity, public supply chain indicators or the spread of infectious diseases. The client library https://github.com/microprediction/rediz/blob/master/README.md and site www.microprediction.org provide more information.
Related packages and dependencies
muid getjson
| |
microconventions
| |
rediz microprediction
- Conventions https://github.com/microprediction/microconventions/blob/master/README.md
- Microprediction https://github.com/microprediction/rediz/blob/master/README.md
Rediz details
This may be a little stale.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rediz-1.0.12.tar.gz.
File metadata
- Download URL: rediz-1.0.12.tar.gz
- Upload date:
- Size: 36.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
59664800f8aef15495d5755f3b102d28fe88205152e7a977c4f06d11894194f3
|
|
| MD5 |
f10a59505ff3a5afacd38fda24084569
|
|
| BLAKE2b-256 |
9f410cbf558ccc0842b6884857697ffe7b6751df3b5f57b6de2e578f04e0b86e
|
File details
Details for the file rediz-1.0.12-py3-none-any.whl.
File metadata
- Download URL: rediz-1.0.12-py3-none-any.whl
- Upload date:
- Size: 38.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ad3a1bf13ddc05b5fb8decc7d4b50333cb1e71e786e66fea33459bc52d766c4d
|
|
| MD5 |
f559e71ba5f958e4e4da687165c9b502
|
|
| BLAKE2b-256 |
322407f9db0baa7eaf96498375fcba57a3354e9ee6bbad34ccfc7605d1b4e732
|







