SIGNed explanations: Unveiling relevant features by reducing bias

Project description
SIGNed explanations: Unveiling relevant features by reducing bias
This repository and python package has been published alongside the following journal article: https://doi.org/10.1016/j.inffus.2023.101883
If you use the code from this repository in your work, please cite:
@article{Gumpfer2023SIGN,
title = {SIGNed explanations: Unveiling relevant features by reducing bias},
author = {Nils Gumpfer and Joshua Prim and Till Keller and Bernhard Seeger and Michael Guckert and Jennifer Hannig},
journal = {Information Fusion},
pages = {101883},
year = {2023},
issn = {1566-2535},
doi = {https://doi.org/10.1016/j.inffus.2023.101883},
url = {https://www.sciencedirect.com/science/article/pii/S1566253523001999}
}
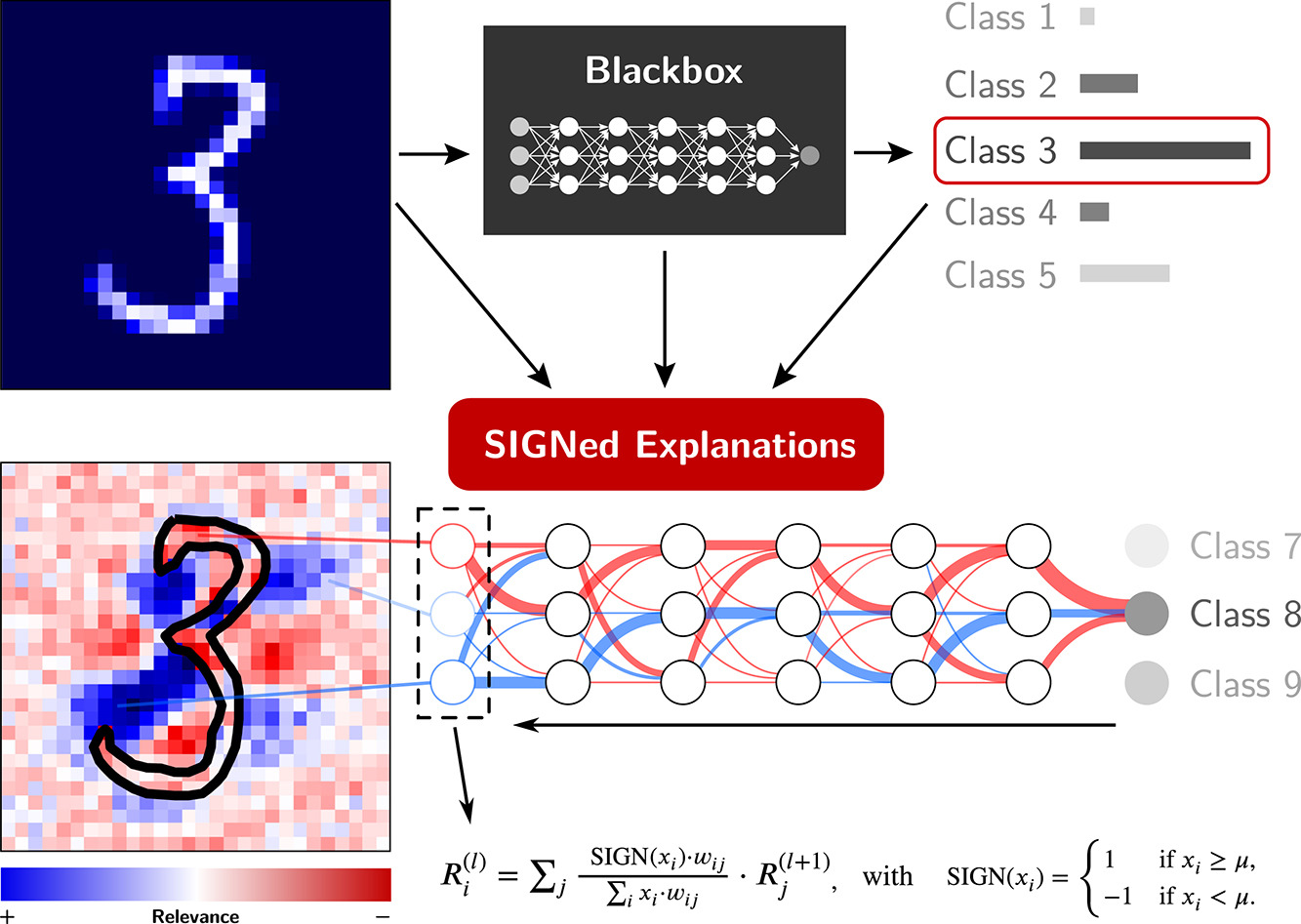
Experiments
To reproduce the experiments from our paper, please find a detailed description on https://github.com/nilsgumpfer/SIGN.
Setup
To install the package in your environment, run:
pip3 install signxai
Usage
VGG16
The below example illustrates the usage of the signxai package in combination with a VGG16 model trained on imagenet:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.applications.vgg16 import VGG16
from signxai.methods.wrappers import calculate_relevancemap
from signxai.utils.utils import (load_image, aggregate_and_normalize_relevancemap_rgb, download_image,
calculate_explanation_innvestigate)
# Load model
model = VGG16(weights='imagenet')
# Remove last layer's softmax activation (we need the raw values!)
model.layers[-1].activation = None
# Load example image
path = 'example.jpg'
download_image(path)
img, x = load_image(path)
# Calculate relevancemaps
R1 = calculate_relevancemap('lrpz_epsilon_0_1_std_x', np.array(x), model)
R2 = calculate_relevancemap('lrpsign_epsilon_0_1_std_x', np.array(x), model)
# Equivalent relevance maps as for R1 and R2, but with direct access to innvestigate and parameters
R3 = calculate_explanation_innvestigate(model, x, method='lrp.stdxepsilon', stdfactor=0.1, input_layer_rule='Z')
R4 = calculate_explanation_innvestigate(model, x, method='lrp.stdxepsilon', stdfactor=0.1, input_layer_rule='SIGN')
# Visualize heatmaps
fig, axs = plt.subplots(ncols=3, nrows=2, figsize=(18, 12))
axs[0][0].imshow(img)
axs[1][0].imshow(img)
axs[0][1].matshow(aggregate_and_normalize_relevancemap_rgb(R1), cmap='seismic', clim=(-1, 1))
axs[0][2].matshow(aggregate_and_normalize_relevancemap_rgb(R2), cmap='seismic', clim=(-1, 1))
axs[1][1].matshow(aggregate_and_normalize_relevancemap_rgb(R3), cmap='seismic', clim=(-1, 1))
axs[1][2].matshow(aggregate_and_normalize_relevancemap_rgb(R4), cmap='seismic', clim=(-1, 1))
plt.show()
(Image credit for example used in this code: Greg Gjerdingen from Willmar, USA)
MNIST
The below example illustrates the usage of the signxai package in combination with a dense model trained on MNIST:
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.python.keras.datasets import mnist
from tensorflow.python.keras.models import load_model
from signxai.methods.wrappers import calculate_relevancemap
from signxai.utils.utils import normalize_heatmap, download_model
# Load train and test data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Scale images to the [-1, 0] range
x_train = x_train.astype("float32") / -255.0
x_test = x_test.astype("float32") / -255.0
x_train = -(np.ones_like(x_train) + x_train)
x_test = -(np.ones_like(x_test) + x_test)
# Load model
path = 'model.h5'
download_model(path)
model = load_model(path)
# Remove softmax
model.layers[-1].activation = None
# Calculate relevancemaps
x = x_test[231]
R1 = calculate_relevancemap('gradient_x_input', np.array(x), model, neuron_selection=3)
R2 = calculate_relevancemap('gradient_x_sign_mu_neg_0_5', np.array(x), model, neuron_selection=3)
R3 = calculate_relevancemap('gradient_x_input', np.array(x), model, neuron_selection=8)
R4 = calculate_relevancemap('gradient_x_sign_mu_neg_0_5', np.array(x), model, neuron_selection=8)
# Visualize heatmaps
fig, axs = plt.subplots(ncols=3, nrows=2, figsize=(18, 12))
axs[0][0].imshow(x, cmap='seismic', clim=(-1, 1))
axs[1][0].imshow(x, cmap='seismic', clim=(-1, 1))
axs[0][1].matshow(normalize_heatmap(R1), cmap='seismic', clim=(-1, 1))
axs[0][2].matshow(normalize_heatmap(R2), cmap='seismic', clim=(-1, 1))
axs[1][1].matshow(normalize_heatmap(R3), cmap='seismic', clim=(-1, 1))
axs[1][2].matshow(normalize_heatmap(R4), cmap='seismic', clim=(-1, 1))
plt.show()
Methods
| Method | Base | Parameters |
|---|---|---|
| gradient | Gradient | |
| input_t_gradient | Gradient x Input | |
| gradient_x_input | Gradient x Input | |
| gradient_x_sign | Gradient x SIGN | mu = 0 |
| gradient_x_sign_mu | Gradient x SIGN | requires mu parameter |
| gradient_x_sign_mu_0 | Gradient x SIGN | mu = 0 |
| gradient_x_sign_mu_0_5 | Gradient x SIGN | mu = 0.5 |
| gradient_x_sign_mu_neg_0_5 | Gradient x SIGN | mu = -0.5 |
| guided_backprop | Guided Backpropagation | |
| guided_backprop_x_sign | Guided Backpropagation x SIGN | mu = 0 |
| guided_backprop_x_sign_mu | Guided Backpropagation x SIGN | requires mu parameter |
| guided_backprop_x_sign_mu_0 | Guided Backpropagation x SIGN | mu = 0 |
| guided_backprop_x_sign_mu_0_5 | Guided Backpropagation x SIGN | mu = 0.5 |
| guided_backprop_x_sign_mu_neg_0_5 | Guided Backpropagation x SIGN | mu = -0.5 |
| integrated_gradients | Integrated Gradients | |
| smoothgrad | SmoothGrad | |
| smoothgrad_x_sign | SmoothGrad x SIGN | mu = 0 |
| smoothgrad_x_sign_mu | SmoothGrad x SIGN | requires mu parameter |
| smoothgrad_x_sign_mu_0 | SmoothGrad x SIGN | mu = 0 |
| smoothgrad_x_sign_mu_0_5 | SmoothGrad x SIGN | mu = 0.5 |
| smoothgrad_x_sign_mu_neg_0_5 | SmoothGrad x SIGN | mu = -0.5 |
| vargrad | VarGrad | |
| deconvnet | DeconvNet | |
| deconvnet_x_sign | DeconvNet x SIGN | mu = 0 |
| deconvnet_x_sign_mu | DeconvNet x SIGN | requires mu parameter |
| deconvnet_x_sign_mu_0 | DeconvNet x SIGN | mu = 0 |
| deconvnet_x_sign_mu_0_5 | DeconvNet x SIGN | mu = 0.5 |
| deconvnet_x_sign_mu_neg_0_5 | DeconvNet x SIGN | mu = -0.5 |
| grad_cam | Grad-CAM | requires last_conv parameter |
| grad_cam_timeseries | Grad-CAM | (for time series data), requires last_conv parameter |
| grad_cam_VGG16ILSVRC | last_conv based on VGG16 | |
| guided_grad_cam_VGG16ILSVRC | last_conv based on VGG16 | |
| lrp_z | LRP-z | |
| lrpsign_z | LRP-z / LRP-SIGN (Inputlayer-Rule) | |
| zblrp_z_VGG16ILSVRC | LRP-z / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet |
| w2lrp_z | LRP-z / LRP-w² (Inputlayer-Rule) | |
| flatlrp_z | LRP-z / LRP-flat (Inputlayer-Rule) | |
| lrp_epsilon_0_001 | LRP-epsilon | epsilon = 0.001 |
| lrpsign_epsilon_0_001 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.001 |
| zblrp_epsilon_0_001_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.001 |
| lrpz_epsilon_0_001 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.001 |
| lrp_epsilon_0_01 | LRP-epsilon | epsilon = 0.01 |
| lrpsign_epsilon_0_01 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.01 |
| zblrp_epsilon_0_01_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.01 |
| lrpz_epsilon_0_01 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.01 |
| w2lrp_epsilon_0_01 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.01 |
| flatlrp_epsilon_0_01 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.01 |
| lrp_epsilon_0_1 | LRP-epsilon | epsilon = 0.1 |
| lrpsign_epsilon_0_1 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.1 |
| zblrp_epsilon_0_1_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.1 |
| lrpz_epsilon_0_1 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.1 |
| w2lrp_epsilon_0_1 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.1 |
| flatlrp_epsilon_0_1 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.1 |
| lrp_epsilon_0_2 | LRP-epsilon | epsilon = 0.2 |
| lrpsign_epsilon_0_2 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.2 |
| zblrp_epsilon_0_2_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.2 |
| lrpz_epsilon_0_2 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.2 |
| lrp_epsilon_0_5 | LRP-epsilon | epsilon = 0.5 |
| lrpsign_epsilon_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.5 |
| zblrp_epsilon_0_5_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.5 |
| lrpz_epsilon_0_5 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.5 |
| lrp_epsilon_1 | LRP-epsilon | epsilon = 1 |
| lrpsign_epsilon_1 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 1 |
| zblrp_epsilon_1_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 1 |
| lrpz_epsilon_1 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 1 |
| w2lrp_epsilon_1 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 1 |
| flatlrp_epsilon_1 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 1 |
| lrp_epsilon_5 | LRP-epsilon | epsilon = 5 |
| lrpsign_epsilon_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 5 |
| zblrp_epsilon_5_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 5 |
| lrpz_epsilon_5 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 5 |
| lrp_epsilon_10 | LRP-epsilon | epsilon = 10 |
| lrpsign_epsilon_10 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 10 |
| zblrp_epsilon_10_VGG106ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 10 |
| lrpz_epsilon_10 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 10 |
| w2lrp_epsilon_10 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 10 |
| flatlrp_epsilon_10 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 10 |
| lrp_epsilon_20 | LRP-epsilon | epsilon = 20 |
| lrpsign_epsilon_20 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 20 |
| zblrp_epsilon_20_VGG206ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 20 |
| lrpz_epsilon_20 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 20 |
| w2lrp_epsilon_20 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 20 |
| flatlrp_epsilon_20 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 20 |
| lrp_epsilon_50 | LRP-epsilon | epsilon = 50 |
| lrpsign_epsilon_50 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 50 |
| lrpz_epsilon_50 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 50 |
| lrp_epsilon_75 | LRP-epsilon | epsilon = 75 |
| lrpsign_epsilon_75 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 75 |
| lrpz_epsilon_75 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 75 |
| lrp_epsilon_100 | LRP-epsilon | epsilon = 100 |
| lrpsign_epsilon_100 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 100, mu = 0 |
| lrpsign_epsilon_100_mu_0 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 100, mu = 0 |
| lrpsign_epsilon_100_mu_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 100, mu = 0.5 |
| lrpsign_epsilon_100_mu_neg_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 100, mu = -0.5 |
| lrpz_epsilon_100 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 100 |
| zblrp_epsilon_100_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 100 |
| w2lrp_epsilon_100 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 100 |
| flatlrp_epsilon_100 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 100 |
| lrp_epsilon_0_1_std_x | LRP-epsilon | epsilon = 0.1 * std(x) |
| lrpsign_epsilon_0_1_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.1 * std(x) |
| lrpz_epsilon_0_1_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.1 * std(x) |
| zblrp_epsilon_0_1_std_x_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.1 * std(x) |
| w2lrp_epsilon_0_1_std_x | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.1 * std(x) |
| flatlrp_epsilon_0_1_std_x | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.1 * std(x) |
| lrp_epsilon_0_25_std_x | LRP-epsilon | epsilon = 0.25 * std(x) |
| lrpsign_epsilon_0_25_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.25 * std(x), mu = 0 |
| lrpz_epsilon_0_25_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.25 * std(x) |
| zblrp_epsilon_0_25_std_x_VGG256ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.25 * std(x) |
| w2lrp_epsilon_0_25_std_x | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.25 * std(x) |
| flatlrp_epsilon_0_25_std_x | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.25 * std(x) |
| lrpsign_epsilon_0_25_std_x_mu_0 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.25 * std(x), mu = 0 |
| lrpsign_epsilon_0_25_std_x_mu_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.25 * std(x), mu = 0.5 |
| lrpsign_epsilon_0_25_std_x_mu_neg_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.25 * std(x), mu = -0.5 |
| lrp_epsilon_0_5_std_x | LRP-epsilon | epsilon = 0.5 * std(x) |
| lrpsign_epsilon_0_5_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.5 * std(x) |
| lrpz_epsilon_0_5_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.5 * std(x) |
| zblrp_epsilon_0_5_std_x_VGG56ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.5 * std(x) |
| w2lrp_epsilon_0_5_std_x | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.5 * std(x) |
| flatlrp_epsilon_0_5_std_x | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.5 * std(x) |
| lrp_epsilon_1_std_x | LRP-epsilon | epsilon = 1 * std(x) |
| lrpsign_epsilon_1_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 1 * std(x), mu = 0 |
| lrpz_epsilon_1_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 1 * std(x) |
| lrp_epsilon_2_std_x | LRP-epsilon | epsilon = 2 * std(x) |
| lrpsign_epsilon_2_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 2 * std(x), mu = 0 |
| lrpz_epsilon_2_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 2 * std(x) |
| lrp_epsilon_3_std_x | LRP-epsilon | epsilon = 3 * std(x) |
| lrpsign_epsilon_3_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 3 * std(x), mu = 0 |
| lrpz_epsilon_3_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 3 * std(x) |
| lrp_alpha_1_beta_0 | LRP-alpha-beta | alpha = 1, beta = 0 |
| lrpsign_alpha_1_beta_0 | LRP-alpha-beta / LRP-SIGN (Inputlayer-Rule) | alpha = 1, beta = 0, mu = 0 |
| lrpz_alpha_1_beta_0 | LRP-alpha-beta / LRP-z (Inputlayer-Rule) | alpha = 1, beta = 0 |
| zblrp_alpha_1_beta_0_VGG16ILSVRC | bounds based on ImageNet, alpha = 1, beta = 0 | |
| w2lrp_alpha_1_beta_0 | LRP-alpha-beta / LRP-ZB (Inputlayer-Rule) | alpha = 1, beta = 0 |
| flatlrp_alpha_1_beta_0 | LRP-alpha-beta / LRP-flat (Inputlayer-Rule) | alpha = 1, beta = 0 |
| lrp_sequential_composite_a | LRP Comosite Variant A | |
| lrpsign_sequential_composite_a | LRP Comosite Variant A / LRP-SIGN (Inputlayer-Rule) | mu = 0 |
| lrpz_sequential_composite_a | LRP Comosite Variant A / LRP-z (Inputlayer-Rule) | |
| zblrp_sequential_composite_a_VGG16ILSVRC | bounds based on ImageNet | |
| w2lrp_sequential_composite_a | LRP Comosite Variant A / LRP-ZB (Inputlayer-Rule) | |
| flatlrp_sequential_composite_a | LRP Comosite Variant A / LRP-flat (Inputlayer-Rule) | |
| lrp_sequential_composite_b | LRP Comosite Variant B | |
| lrpsign_sequential_composite_b | LRP Comosite Variant B / LRP-SIGN (Inputlayer-Rule) | mu = 0 |
| lrpz_sequential_composite_b | LRP Comosite Variant B / LRP-z (Inputlayer-Rule) | |
| zblrp_sequential_composite_b_VGG16ILSVRC | bounds based on ImageNet | |
| w2lrp_sequential_composite_b | LRP Comosite Variant B / LRP-ZB (Inputlayer-Rule) | |
| flatlrp_sequential_composite_b | LRP Comosite Variant B / LRP-flat (Inputlayer-Rule) |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file signxai-1.1.9.2.tar.gz.
File metadata
- Download URL: signxai-1.1.9.2.tar.gz
- Upload date:
- Size: 89.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.8.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b6b4bb1da00be3f3590e8c4b69553604abecd318cfdfc6a146d618508c36d274
|
|
| MD5 |
f2cc1d92e02b3e3ff8eaa9852f58b4d7
|
|
| BLAKE2b-256 |
2610aaf16ed799dc1f4c25588d4f898c3ffe520bab3c547b12b0469437a71294
|
File details
Details for the file signxai-1.1.9.2-py3-none-any.whl.
File metadata
- Download URL: signxai-1.1.9.2-py3-none-any.whl
- Upload date:
- Size: 111.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.8.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2625875a73ffbb261def39a4640f2bd7c5497ca9181f9177e67156933ef6c181
|
|
| MD5 |
9eae6eebf5a4fb63053e0947e2cc63a8
|
|
| BLAKE2b-256 |
95de861d8859fe3191359cc37a0936d265c85a4a50c913e833d2f70dbd5ee87c
|







