A comprehensive explainable AI library supporting both TensorFlow and PyTorch with unified API and advanced XAI methods including SIGN, LRP, and Grad-CAM. Authored by Nils Gumpfer, Jana Fischer and Alexander Paul.

Project description
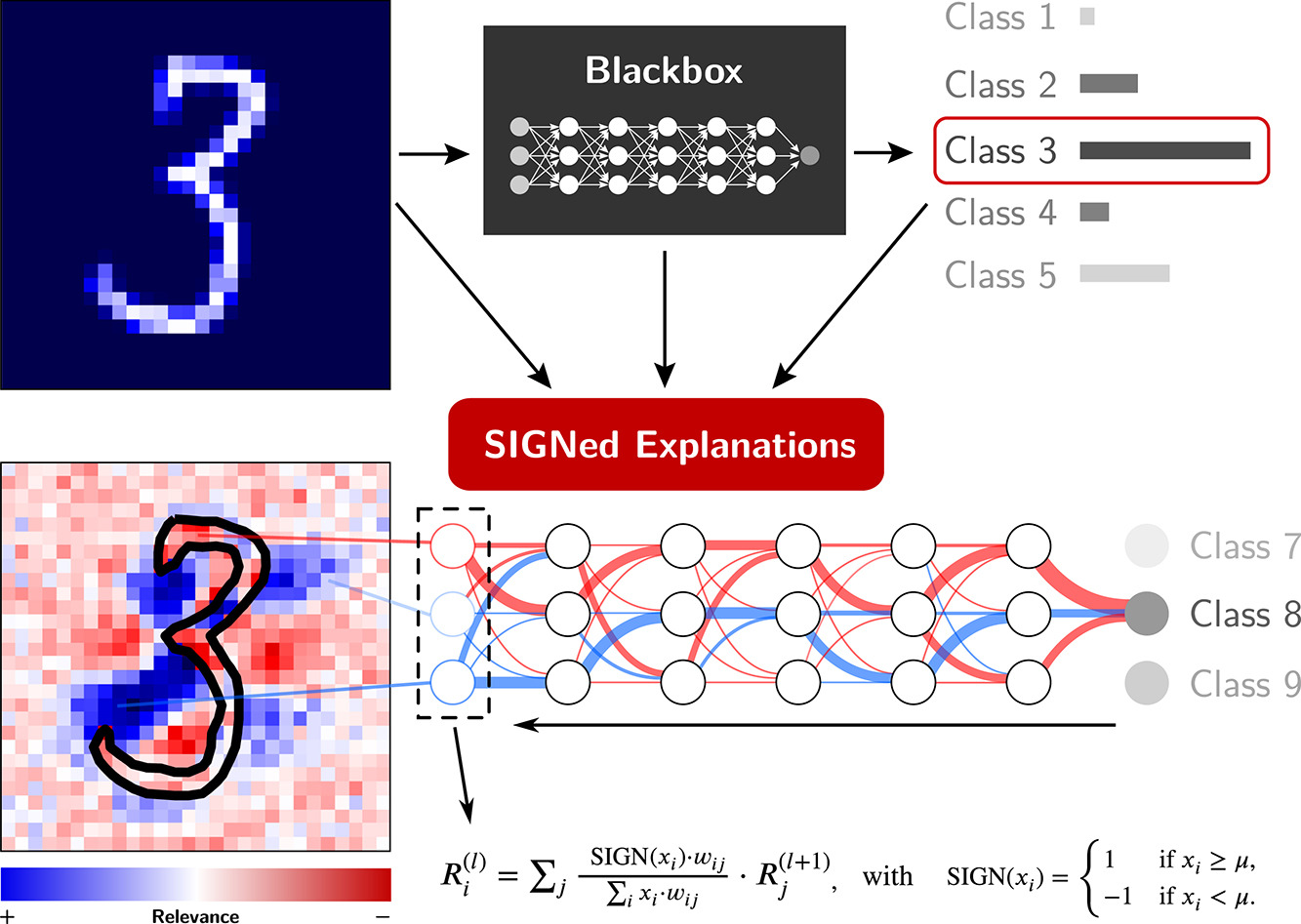
SIGNed explanations: Unveiling relevant features by reducing bias
This repository and python package is an extended version of the published python package of the following journal article: https://doi.org/10.1016/j.inffus.2023.101883
If you use the code from this repository in your work, please cite:
@article{Gumpfer2023SIGN,
title = {SIGNed explanations: Unveiling relevant features by reducing bias},
author = {Nils Gumpfer and Joshua Prim and Till Keller and Bernhard Seeger and Michael Guckert and Jennifer Hannig},
journal = {Information Fusion},
pages = {101883},
year = {2023},
issn = {1566-2535},
doi = {https://doi.org/10.1016/j.inffus.2023.101883},
url = {https://www.sciencedirect.com/science/article/pii/S1566253523001999}
}
🚀 Installation as Python Package via Pypi [Dual Framework Support]
pip install signxai2
Installation after cloning the repository [Dual Framework Support]
Git clone the repository:
git clone https://github.com/IRISlaboratory/signxai2.git
Navigate to the repository directory and run:
pip install -e .
Setup of Git LFS
Before you get started please set up Git LFS to download the large files in this repository. This is required to access the pre-trained models and example data.
git lfs install
📦 Load Data and Documentation
After installation, run the setup script to download documentation, examples, and sample data:
bash ./prepare.sh
This will download:
- 📚 Full documentation (viewable at
docs/index.html) - 📝 Example scripts and notebooks (
examples/) - 📊 Sample ECG data and images (
examples/data/)
Examples
To get started with SignXAI2 Methods, please follow the example tutorials ('examples/tutorials/').
Features
- Support for TensorFlow and PyTorch models
- Consistent API across frameworks
- Wide range of explanation methods:
- Gradient-based: Vanilla gradient, Integrated gradients, SmoothGrad
- Class activation maps: Grad-CAM
- Guided backpropagation
- Layer-wise Relevance Propagation (LRP)
- Sign-based thresholding for binary relevance maps
PyTorch only
The library now includes a PyTorch implementation based on zennit. To use the PyTorch implementation only, you'll need to install:
pip install signxai2[pytorch]
TensorFlow only
To use the TensorFlow implementation only, you'll need to install:
pip install signxai2[tensorflow]
Development version can be installed with:
To reproduce all results from the paper, you can install the development version of SignXAI2 with:
pip install signxai2[dev]
After running the Dual Setup first.
Usage
Please follow the example tutorials in the examples/tutorials/ directory to get started with SignXAI2 methods. The examples cover various use cases, including images and time series analysis.
Methods
| Method | Base | Parameters |
|---|---|---|
| gradient | Gradient | |
| input_t_gradient | Gradient x Input | |
| gradient_x_input | Gradient x Input | |
| gradient_x_sign | Gradient x SIGN | mu = 0 |
| gradient_x_sign_mu | Gradient x SIGN | requires mu parameter |
| gradient_x_sign_mu_0 | Gradient x SIGN | mu = 0 |
| gradient_x_sign_mu_0_5 | Gradient x SIGN | mu = 0.5 |
| gradient_x_sign_mu_neg_0_5 | Gradient x SIGN | mu = -0.5 |
| guided_backprop | Guided Backpropagation | |
| guided_backprop_x_sign | Guided Backpropagation x SIGN | mu = 0 |
| guided_backprop_x_sign_mu | Guided Backpropagation x SIGN | requires mu parameter |
| guided_backprop_x_sign_mu_0 | Guided Backpropagation x SIGN | mu = 0 |
| guided_backprop_x_sign_mu_0_5 | Guided Backpropagation x SIGN | mu = 0.5 |
| guided_backprop_x_sign_mu_neg_0_5 | Guided Backpropagation x SIGN | mu = -0.5 |
| integrated_gradients | Integrated Gradients | |
| smoothgrad | SmoothGrad | |
| smoothgrad_x_sign | SmoothGrad x SIGN | mu = 0 |
| smoothgrad_x_sign_mu | SmoothGrad x SIGN | requires mu parameter |
| smoothgrad_x_sign_mu_0 | SmoothGrad x SIGN | mu = 0 |
| smoothgrad_x_sign_mu_0_5 | SmoothGrad x SIGN | mu = 0.5 |
| smoothgrad_x_sign_mu_neg_0_5 | SmoothGrad x SIGN | mu = -0.5 |
| vargrad | VarGrad | |
| deconvnet | DeconvNet | |
| deconvnet_x_sign | DeconvNet x SIGN | mu = 0 |
| deconvnet_x_sign_mu | DeconvNet x SIGN | requires mu parameter |
| deconvnet_x_sign_mu_0 | DeconvNet x SIGN | mu = 0 |
| deconvnet_x_sign_mu_0_5 | DeconvNet x SIGN | mu = 0.5 |
| deconvnet_x_sign_mu_neg_0_5 | DeconvNet x SIGN | mu = -0.5 |
| grad_cam | Grad-CAM | requires last_conv parameter |
| grad_cam_timeseries | Grad-CAM | (for time series data), requires last_conv parameter |
| grad_cam_VGG16ILSVRC | last_conv based on VGG16 | |
| guided_grad_cam_VGG16ILSVRC | last_conv based on VGG16 | |
| lrp_z | LRP-z | |
| lrpsign_z | LRP-z / LRP-SIGN (Inputlayer-Rule) | |
| zblrp_z_VGG16ILSVRC | LRP-z / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet |
| w2lrp_z | LRP-z / LRP-w² (Inputlayer-Rule) | |
| flatlrp_z | LRP-z / LRP-flat (Inputlayer-Rule) | |
| lrp_epsilon_0_001 | LRP-epsilon | epsilon = 0.001 |
| lrpsign_epsilon_0_001 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.001 |
| zblrp_epsilon_0_001_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.001 |
| lrpz_epsilon_0_001 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.001 |
| lrp_epsilon_0_01 | LRP-epsilon | epsilon = 0.01 |
| lrpsign_epsilon_0_01 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.01 |
| zblrp_epsilon_0_01_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.01 |
| lrpz_epsilon_0_01 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.01 |
| w2lrp_epsilon_0_01 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.01 |
| flatlrp_epsilon_0_01 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.01 |
| lrp_epsilon_0_1 | LRP-epsilon | epsilon = 0.1 |
| lrpsign_epsilon_0_1 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.1 |
| zblrp_epsilon_0_1_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.1 |
| lrpz_epsilon_0_1 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.1 |
| w2lrp_epsilon_0_1 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.1 |
| flatlrp_epsilon_0_1 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.1 |
| lrp_epsilon_0_2 | LRP-epsilon | epsilon = 0.2 |
| lrpsign_epsilon_0_2 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.2 |
| zblrp_epsilon_0_2_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.2 |
| lrpz_epsilon_0_2 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.2 |
| lrp_epsilon_0_5 | LRP-epsilon | epsilon = 0.5 |
| lrpsign_epsilon_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.5 |
| zblrp_epsilon_0_5_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.5 |
| lrpz_epsilon_0_5 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.5 |
| lrp_epsilon_1 | LRP-epsilon | epsilon = 1 |
| lrpsign_epsilon_1 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 1 |
| zblrp_epsilon_1_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 1 |
| lrpz_epsilon_1 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 1 |
| w2lrp_epsilon_1 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 1 |
| flatlrp_epsilon_1 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 1 |
| lrp_epsilon_5 | LRP-epsilon | epsilon = 5 |
| lrpsign_epsilon_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 5 |
| zblrp_epsilon_5_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 5 |
| lrpz_epsilon_5 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 5 |
| lrp_epsilon_10 | LRP-epsilon | epsilon = 10 |
| lrpsign_epsilon_10 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 10 |
| zblrp_epsilon_10_VGG106ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 10 |
| lrpz_epsilon_10 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 10 |
| w2lrp_epsilon_10 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 10 |
| flatlrp_epsilon_10 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 10 |
| lrp_epsilon_20 | LRP-epsilon | epsilon = 20 |
| lrpsign_epsilon_20 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 20 |
| zblrp_epsilon_20_VGG206ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 20 |
| lrpz_epsilon_20 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 20 |
| w2lrp_epsilon_20 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 20 |
| flatlrp_epsilon_20 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 20 |
| lrp_epsilon_50 | LRP-epsilon | epsilon = 50 |
| lrpsign_epsilon_50 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 50 |
| lrpz_epsilon_50 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 50 |
| lrp_epsilon_75 | LRP-epsilon | epsilon = 75 |
| lrpsign_epsilon_75 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 75 |
| lrpz_epsilon_75 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 75 |
| lrp_epsilon_100 | LRP-epsilon | epsilon = 100 |
| lrpsign_epsilon_100 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 100, mu = 0 |
| lrpsign_epsilon_100_mu_0 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 100, mu = 0 |
| lrpsign_epsilon_100_mu_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 100, mu = 0.5 |
| lrpsign_epsilon_100_mu_neg_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 100, mu = -0.5 |
| lrpz_epsilon_100 | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 100 |
| zblrp_epsilon_100_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 100 |
| w2lrp_epsilon_100 | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 100 |
| flatlrp_epsilon_100 | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 100 |
| lrp_epsilon_0_1_std_x | LRP-epsilon | epsilon = 0.1 * std(x) |
| lrpsign_epsilon_0_1_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.1 * std(x) |
| lrpz_epsilon_0_1_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.1 * std(x) |
| zblrp_epsilon_0_1_std_x_VGG16ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.1 * std(x) |
| w2lrp_epsilon_0_1_std_x | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.1 * std(x) |
| flatlrp_epsilon_0_1_std_x | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.1 * std(x) |
| lrp_epsilon_0_25_std_x | LRP-epsilon | epsilon = 0.25 * std(x) |
| lrpsign_epsilon_0_25_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.25 * std(x), mu = 0 |
| lrpz_epsilon_0_25_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.25 * std(x) |
| zblrp_epsilon_0_25_std_x_VGG256ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.25 * std(x) |
| w2lrp_epsilon_0_25_std_x | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.25 * std(x) |
| flatlrp_epsilon_0_25_std_x | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.25 * std(x) |
| lrpsign_epsilon_0_25_std_x_mu_0 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.25 * std(x), mu = 0 |
| lrpsign_epsilon_0_25_std_x_mu_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.25 * std(x), mu = 0.5 |
| lrpsign_epsilon_0_25_std_x_mu_neg_0_5 | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.25 * std(x), mu = -0.5 |
| lrp_epsilon_0_5_std_x | LRP-epsilon | epsilon = 0.5 * std(x) |
| lrpsign_epsilon_0_5_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 0.5 * std(x) |
| lrpz_epsilon_0_5_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 0.5 * std(x) |
| zblrp_epsilon_0_5_std_x_VGG56ILSVRC | LRP-epsilon / LRP-ZB (Inputlayer-Rule) | bounds based on ImageNet, epsilon = 0.5 * std(x) |
| w2lrp_epsilon_0_5_std_x | LRP-epsilon / LRP-w² (Inputlayer-Rule) | epsilon = 0.5 * std(x) |
| flatlrp_epsilon_0_5_std_x | LRP-epsilon / LRP-flat (Inputlayer-Rule) | epsilon = 0.5 * std(x) |
| lrp_epsilon_1_std_x | LRP-epsilon | epsilon = 1 * std(x) |
| lrpsign_epsilon_1_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 1 * std(x), mu = 0 |
| lrpz_epsilon_1_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 1 * std(x) |
| lrp_epsilon_2_std_x | LRP-epsilon | epsilon = 2 * std(x) |
| lrpsign_epsilon_2_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 2 * std(x), mu = 0 |
| lrpz_epsilon_2_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 2 * std(x) |
| lrp_epsilon_3_std_x | LRP-epsilon | epsilon = 3 * std(x) |
| lrpsign_epsilon_3_std_x | LRP-epsilon / LRP-SIGN (Inputlayer-Rule) | epsilon = 3 * std(x), mu = 0 |
| lrpz_epsilon_3_std_x | LRP-epsilon / LRP-z (Inputlayer-Rule) | epsilon = 3 * std(x) |
| lrp_alpha_1_beta_0 | LRP-alpha-beta | alpha = 1, beta = 0 |
| lrpsign_alpha_1_beta_0 | LRP-alpha-beta / LRP-SIGN (Inputlayer-Rule) | alpha = 1, beta = 0, mu = 0 |
| lrpz_alpha_1_beta_0 | LRP-alpha-beta / LRP-z (Inputlayer-Rule) | alpha = 1, beta = 0 |
| zblrp_alpha_1_beta_0_VGG16ILSVRC | bounds based on ImageNet, alpha = 1, beta = 0 | |
| w2lrp_alpha_1_beta_0 | LRP-alpha-beta / LRP-ZB (Inputlayer-Rule) | alpha = 1, beta = 0 |
| flatlrp_alpha_1_beta_0 | LRP-alpha-beta / LRP-flat (Inputlayer-Rule) | alpha = 1, beta = 0 |
| lrp_sequential_composite_a | LRP Comosite Variant A | |
| lrpsign_sequential_composite_a | LRP Comosite Variant A / LRP-SIGN (Inputlayer-Rule) | mu = 0 |
| lrpz_sequential_composite_a | LRP Comosite Variant A / LRP-z (Inputlayer-Rule) | |
| zblrp_sequential_composite_a_VGG16ILSVRC | bounds based on ImageNet | |
| w2lrp_sequential_composite_a | LRP Comosite Variant A / LRP-ZB (Inputlayer-Rule) | |
| flatlrp_sequential_composite_a | LRP Comosite Variant A / LRP-flat (Inputlayer-Rule) | |
| lrp_sequential_composite_b | LRP Comosite Variant B | |
| lrpsign_sequential_composite_b | LRP Comosite Variant B / LRP-SIGN (Inputlayer-Rule) | mu = 0 |
| lrpz_sequential_composite_b | LRP Comosite Variant B / LRP-z (Inputlayer-Rule) | |
| zblrp_sequential_composite_b_VGG16ILSVRC | bounds based on ImageNet | |
| w2lrp_sequential_composite_b | LRP Comosite Variant B / LRP-ZB (Inputlayer-Rule) | |
| flatlrp_sequential_composite_b | LRP Comosite Variant B / LRP-flat (Inputlayer-Rule) |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file signxai2-0.7.0.tar.gz.
File metadata
- Download URL: signxai2-0.7.0.tar.gz
- Upload date:
- Size: 267.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
97aa269a1685aebef4cfcdef4b8d2e84de2c2e94c57354f23216350e99b7e0e4
|
|
| MD5 |
2587785dbb8fa1180e55a3d285d32e9c
|
|
| BLAKE2b-256 |
9eba4401c55dcca6dedb1bd211b32762fa04e14a49f553a1db61b030ba0abd2c
|
File details
Details for the file signxai2-0.7.0-py3-none-any.whl.
File metadata
- Download URL: signxai2-0.7.0-py3-none-any.whl
- Upload date:
- Size: 245.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0616aaaa75083e47cb76b3b1d79f22b64d366d59747ed34be6fa9b39eb71f3e1
|
|
| MD5 |
3ecf7e123aa2ce50c887316fcf00023a
|
|
| BLAKE2b-256 |
49055e35d5b23a870e579d4e10f47c11b783e0532ab4640f2cd2d34ce4030b14
|







