skrobot is a Python module for designing, running and tracking Machine Learning experiments / tasks. It is built on top of scikit-learn framework.

Project description





skrobot
What is it about?
skrobot is a Python module for designing, running and tracking Machine Learning experiments / tasks. It is built on top of scikit-learn framework.
How do I install it?
PyPI
$ pip install skrobot
Development Version
The skrobot version on PyPI may always be one step behind; you can install the latest development version from the GitHub repository by executing
$ pip install git+git://github.com/medoidai/skrobot.git
Or, you can clone the GitHub repository and install skrobot from your local drive via
$ python setup.py install
Which are the components?
NOTE : Currently, skrobot can be used only for binary classification problems. Multiclass, regression and multitarget extensions are project priorities. Also, a proper module documentation is on the making after the first public release and testing (please check below).
Functionality for the module users
| Component | What is this? |
|---|---|
| Train Task | This task can be used to fit a scikit-learn estimator on some data. |
| Prediction Task | This task can be used to predict new data using a scikit-learn estimator. |
| Evaluation Cross Validation Task | This task can be used to evaluate a scikit-learn estimator on some data. |
| Feature Selection Cross Validation Task | This task can be used to perform feature selection with Recursive Feature Elimination using a scikit-learn estimator on some data. |
| Hyperparameters Search Cross Validation Task | This task can be used to search the best hyperparameters of a scikit-learn estimator on some data. |
| Experiment | This is used to build and run experiments. It can run tasks in the context of an experiment and glue everything together to complete a modelling pipeline. |
| Task Runner | This is like the Experiment component but without the "experiment" stuff. It can be used to run various tasks and glue everything together to complete a modelling pipeline. |
Functionality for the module developers extending tasks or notifiers
| Component | What is this? |
|---|---|
| Base Task | All tasks inherit from this component. A task is a configurable and reproducible piece of code built on top of scikit-learn that can be used in machine learning pipelines. |
| Base Cross Validation Task | All tasks that use cross validation functionality inherit from this component. |
| Base Notifier | All notifiers inherit from this component. A notifier can be used to send success / failure notifications for tasks execution. |
More details on the components functionality?
Evaluation Cross Validation Task
-
Cross validation runs by default and can be configured to use either stratified k-folds or custom folds
-
The provided estimator is not affected and is used only as a template
-
The provided estimator can be either a scikit-learn machine learning model (e.g., LogisticRegression) or a pipeline ending with an estimator
-
The provided train / test dataset file paths can be either URLs or disk file paths
-
The provided estimator needs to be able to predict probabilities through a
predict_probamethod -
The following evaluation results can be generated on-demand for hold-out test set as well as train / validation CV folds:
- PR / ROC Curves
- Confusion Matrixes
- Classification Reports
- Performance Metrics
- False Positives
- False Negatives
-
The evaluation results can be generated either for a specifc provided threshold or for the best one found from threshold tuning
-
The threshold used along with its related performance metrics and summary metrics from all CV splits as well as hold-out test set are returned as a result
Feature Selection Cross Validation Task
-
Cross validation runs by default and can be configured to use either stratified k-folds or custom folds
-
The provided estimator can be either a scikit-learn machine learning model (e.g., LogisticRegression) or a pipeline ending with an estimator
-
The provided train dataset file path can be either a URL or a disk file path
-
The provided estimator needs to provide feature importances through either a
coef_or afeature_importances_attribute -
Along with the provided estimator a preprocessor can also be provided to preprocess the data before feature selection runs
-
The provided estimator and preprocessor are not affected and are used only as templates
-
The selected features can be either column names (from the original data) or column indexes (from the preprocessed data) depending on whether a preprocessor was used or not
-
The selected features are stored in a text file and also returned as a result
Train Task
-
The provided estimator is not affected and is used only as a template
-
The provided estimator can be either a scikit-learn machine learning model (e.g., LogisticRegression) or a pipeline ending with an estimator
-
The provided train dataset file path can be either a URL or a disk file path
-
The fitted estimator is stored as a pickle file and also returned as a result
Prediction Task
-
The provided estimator can be either a scikit-learn machine learning model (e.g., LogisticRegression) or a pipeline ending with an estimator
-
The provided dataset file path can be either a URL or a disk file path
-
The predictions are stored in a CSV file and also returned as a result
Hyperparameters Search Cross Validation Task
-
Cross validation runs by default and can be configured to use either stratified k-folds or custom folds
-
The provided estimator is not affected and is used only as a template
-
The provided estimator can be either a scikit-learn machine learning model (e.g., LogisticRegression) or a pipeline ending with an estimator
-
The provided train dataset file path can be either a URL or a disk file path
-
The search can be either randomized or grid-based
-
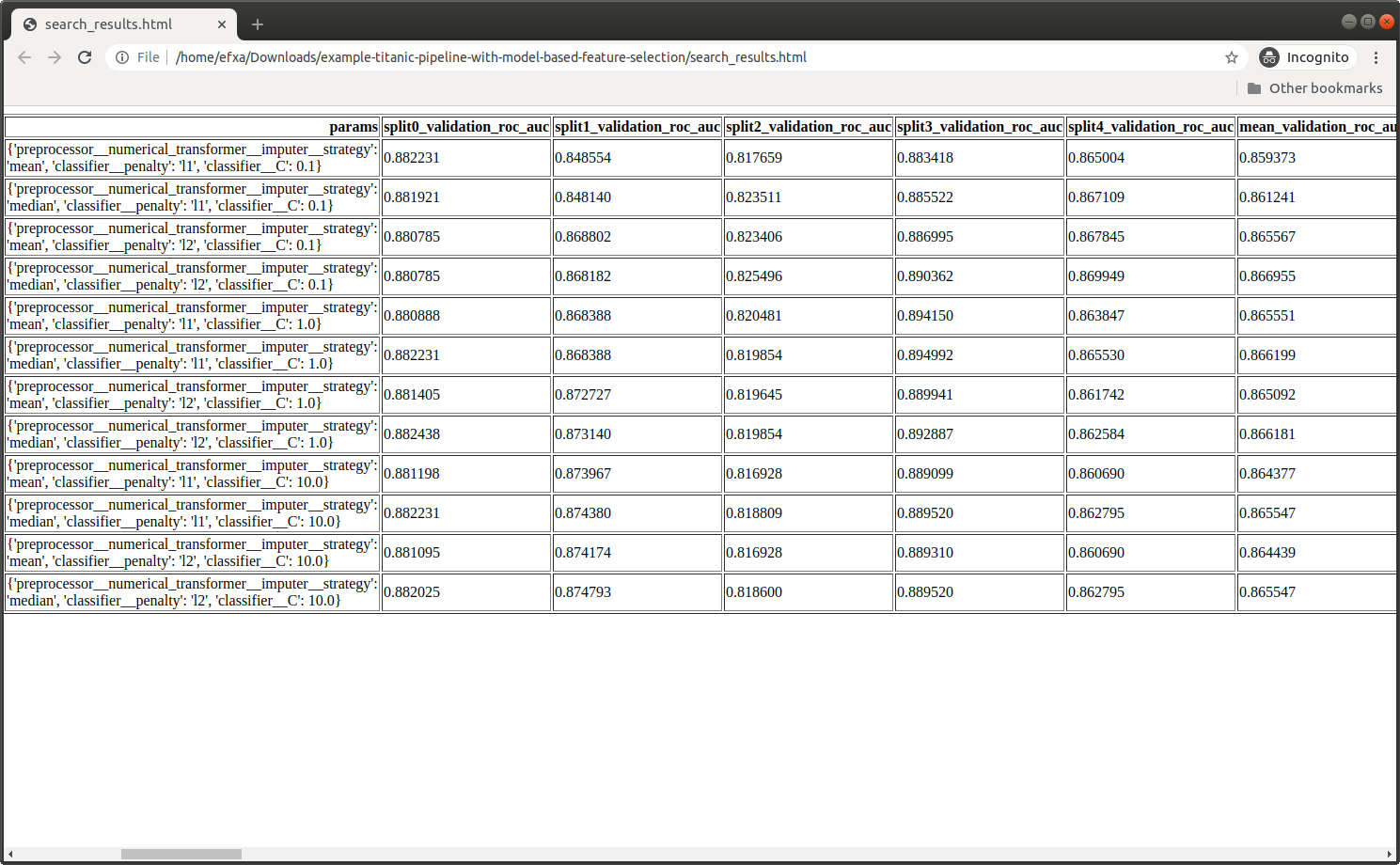
The search results as well as the best estimator found with its related hyperparameters and score are returned as a result
-
The search results are stored in a file as a static HTML table
Experiment
-
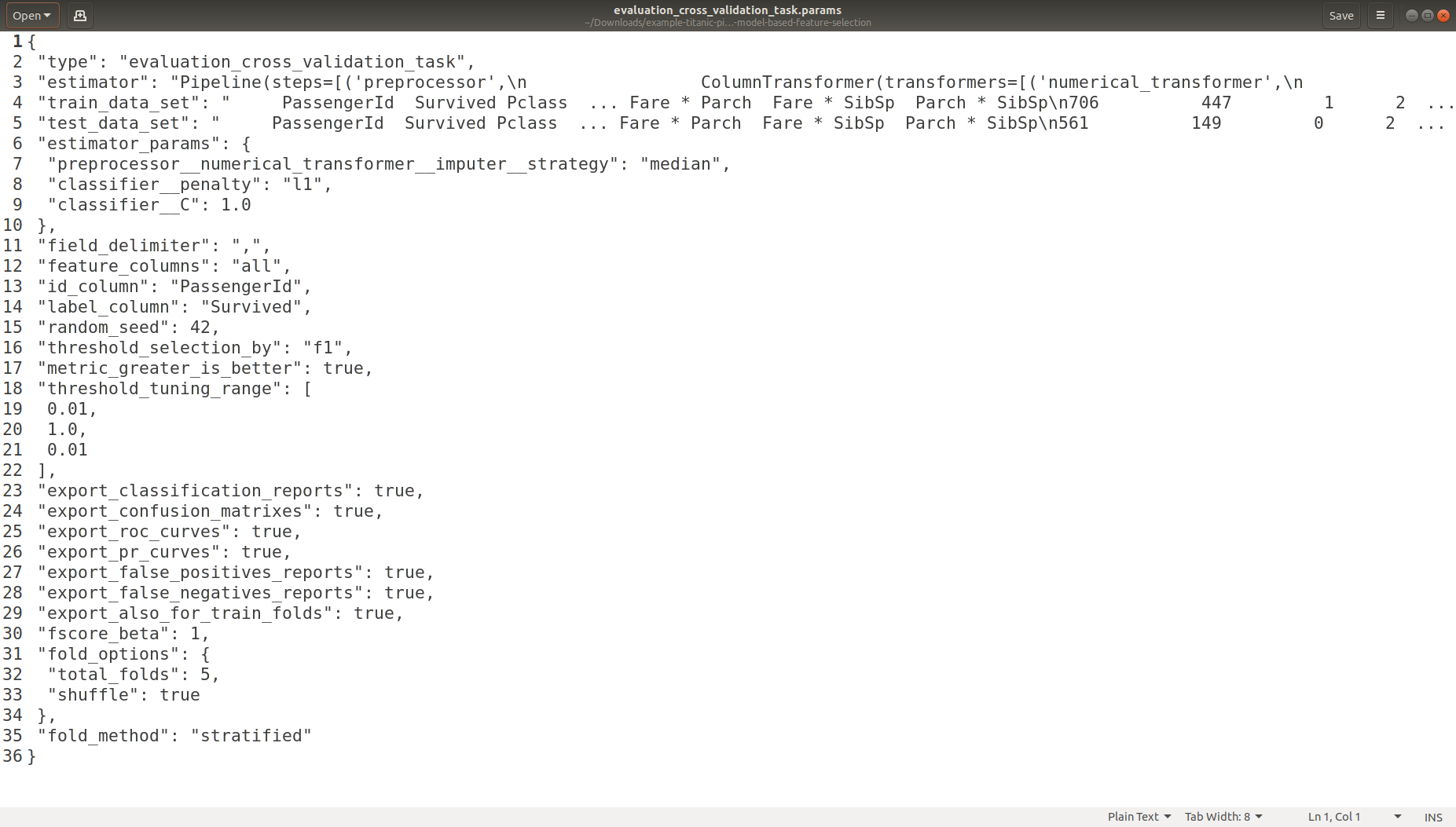
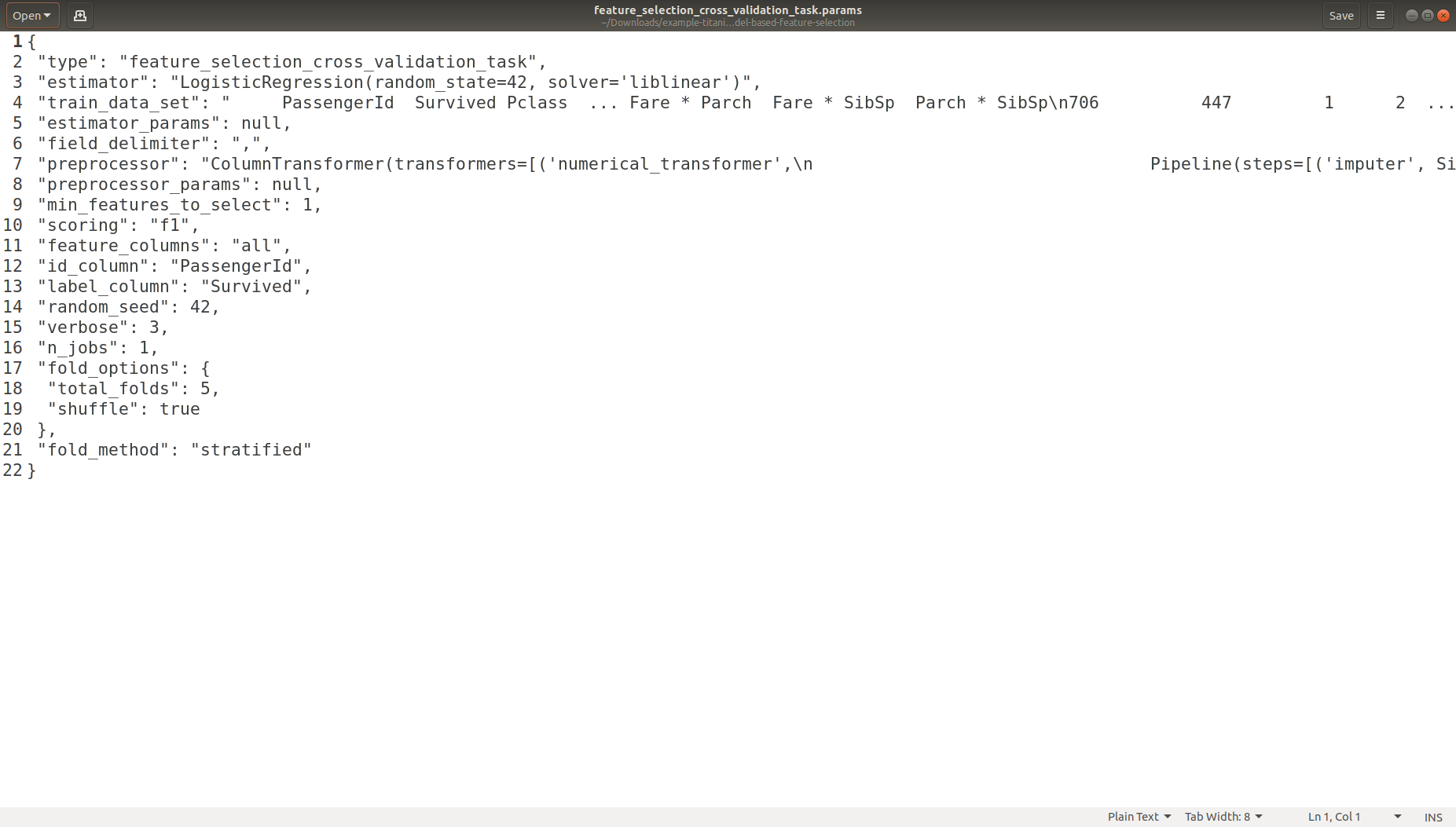
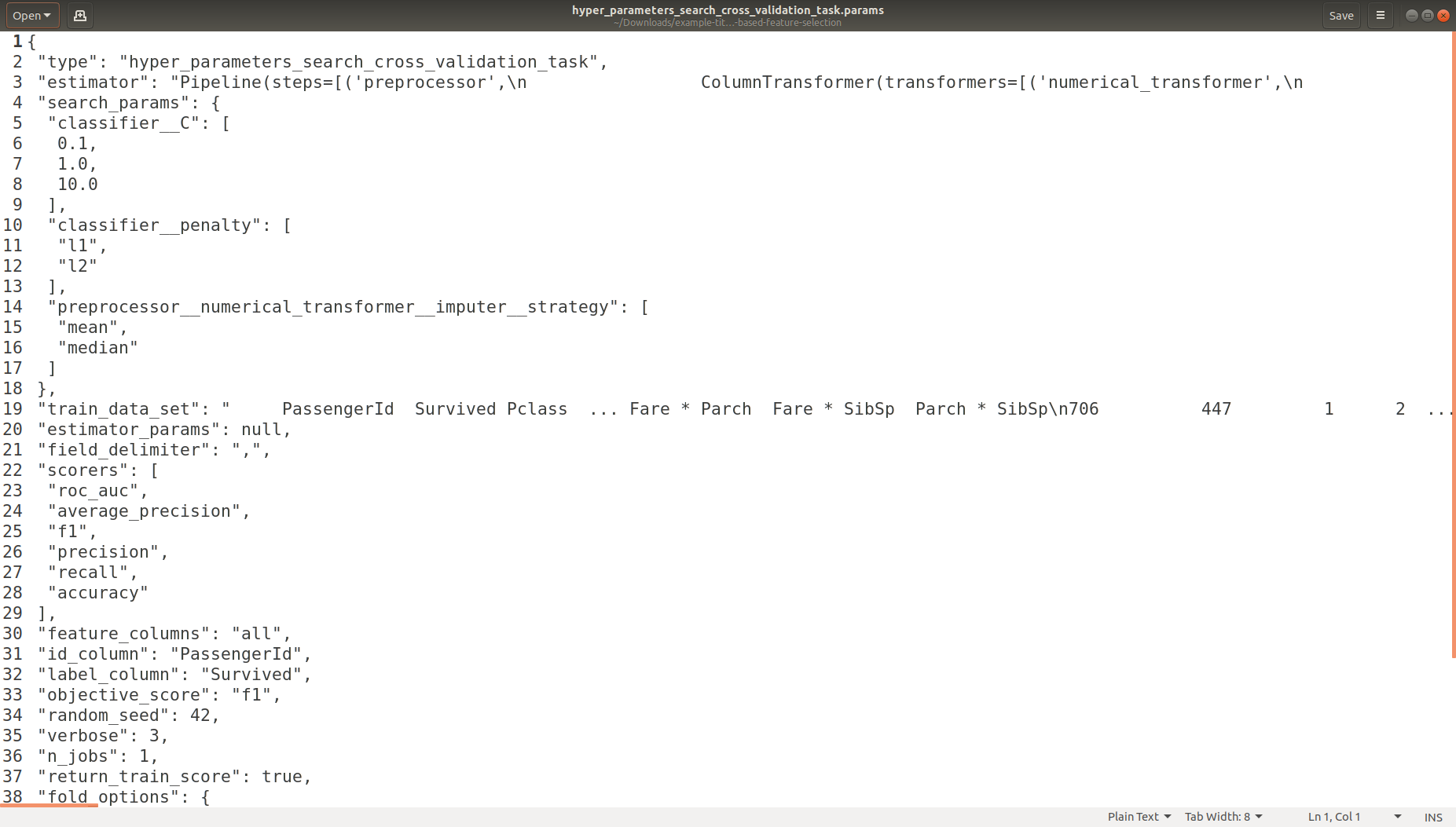
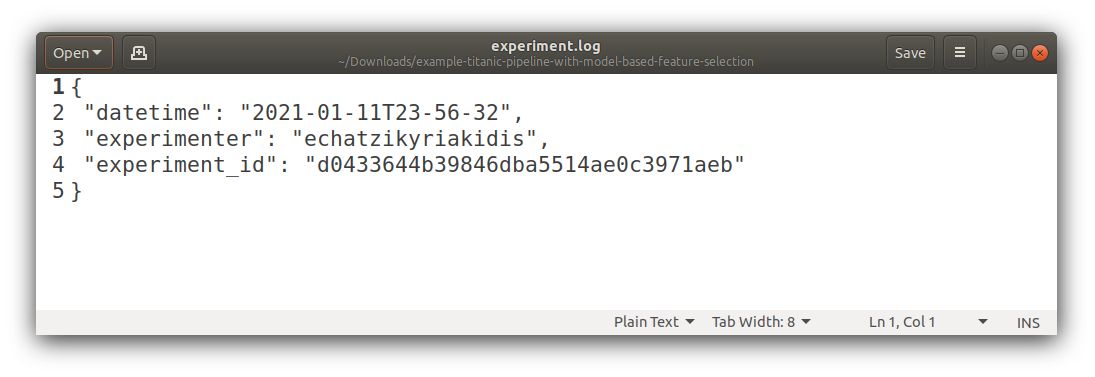
Each experiment when it runs it leaves in a unique directory a footprint of metadata files (experiment source code, experiment ID, experiment date/time, experimenter name, experiment default / overwritten parameters in JSON format)
-
Notifications can be send after running a task, through an easy to implement API (it can be useful for teams who need to get notified for the progress of the experiment)
-
In case of error when running a task, a text file will be generated with the related error
Task Runner
-
It runs the provided tasks and saves in a file the default / overwritten parameters in JSON format
-
In case of error when running a task, a text file will be generated with the related error
Why does it exists?
It can help Data Scientists and Machine Learning Engineers:
-
to keep track of modelling experiments / tasks
-
to automate the repetitive (and boring) stuff when designing modelling pipelines
-
to spend more time on the things that truly matter when solving a problem
The people behind it
Development:
Support, testing and features recommendation:
Next Priorities?
-
Write documentation (e.g., Read the Docs) for the module!
-
Add support in the module for multiclass, regression and multitarget problems
-
Build some notifiers (e.g., Slack, Trello and Discord)
-
Add Bayesian hyperparameter tuning support
Can I contribute?
Of course, the project is Free Software and you can contribute to it!
What license do you use?
See our license (LICENSE.txt) for more details.
How do I use it?
Many examples can be found in the examples directory.
Below, are some examples that use many of skrobot's components to built a machine learning modelling pipeline. Please try them and we would love to have your feedback!
Example on Titanic Dataset (auto-generated results)
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from skrobot.core import Experiment
from skrobot.tasks import TrainTask
from skrobot.tasks import PredictionTask
from skrobot.tasks import FeatureSelectionCrossValidationTask
from skrobot.tasks import EvaluationCrossValidationTask
from skrobot.tasks import HyperParametersSearchCrossValidationTask
from skrobot.feature_selection import ColumnSelector
from skrobot.notification import BaseNotifier
######### Initialization Code
train_data_set_file_path = 'https://bit.ly/titanic-data-train'
test_data_set_file_path = 'https://bit.ly/titanic-data-test'
new_data_set_file_path = 'https://bit.ly/titanic-data-new'
random_seed = 42
id_column = 'PassengerId'
label_column = 'Survived'
numerical_features = ['Age', 'Fare', 'SibSp', 'Parch']
categorical_features = ['Embarked', 'Sex', 'Pclass']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer()),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(transformers=[
('numerical_transformer', numeric_transformer, numerical_features),
('categorical_transformer', categorical_transformer, categorical_features)])
classifier = LogisticRegression(solver='liblinear', random_state=random_seed)
search_params = {
"classifier__C" : [ 1.e-01, 1.e+00, 1.e+01 ],
"classifier__penalty" : [ "l1", "l2" ],
"preprocessor__numerical_transformer__imputer__strategy" : [ "mean", "median" ]
}
######### skrobot Code
# Define a Notifier (This is optional and you can implement any notifier you want, e.g. for Slack / Trello / Discord)
class ConsoleNotifier(BaseNotifier):
def notify (self, message):
print(message)
# Build an Experiment
experiment = Experiment('experiments-output').set_source_code_file_path(__file__).set_experimenter('echatzikyriakidis').set_notifier(ConsoleNotifier()).build()
# Run Feature Selection Task
features_columns = experiment.run(FeatureSelectionCrossValidationTask (estimator=classifier,
train_data_set_file_path=train_data_set_file_path,
preprocessor=preprocessor,
min_features_to_select=4,
id_column=id_column,
label_column=label_column,
random_seed=random_seed).stratified_folds(total_folds=5, shuffle=True))
pipe = Pipeline(steps=[('preprocessor', preprocessor),
('selector', ColumnSelector(cols=features_columns)),
('classifier', classifier)])
# Run Hyperparameters Search Task
hyperparameters_search_results = experiment.run(HyperParametersSearchCrossValidationTask (estimator=pipe,
search_params=search_params,
train_data_set_file_path=train_data_set_file_path,
id_column=id_column,
label_column=label_column,
random_seed=random_seed).random_search(n_iters=100).stratified_folds(total_folds=5, shuffle=True))
# Run Evaluation Task
evaluation_results = experiment.run(EvaluationCrossValidationTask(estimator=pipe,
estimator_params=hyperparameters_search_results['best_params'],
train_data_set_file_path=train_data_set_file_path,
test_data_set_file_path=test_data_set_file_path,
id_column=id_column,
label_column=label_column,
random_seed=random_seed,
export_classification_reports=True,
export_confusion_matrixes=True,
export_pr_curves=True,
export_roc_curves=True,
export_false_positives_reports=True,
export_false_negatives_reports=True,
export_also_for_train_folds=True).stratified_folds(total_folds=5, shuffle=True))
# Run Train Task
train_results = experiment.run(TrainTask(estimator=pipe,
estimator_params=hyperparameters_search_results['best_params'],
train_data_set_file_path=train_data_set_file_path,
id_column=id_column,
label_column=label_column,
random_seed=random_seed))
# Run Prediction Task
predictions = experiment.run(PredictionTask(estimator=train_results['estimator'],
data_set_file_path=new_data_set_file_path,
id_column=id_column,
prediction_column=label_column))
# Print in-memory results
print(features_columns)
print(hyperparameters_search_results['best_params'])
print(hyperparameters_search_results['best_index'])
print(hyperparameters_search_results['best_estimator'])
print(hyperparameters_search_results['best_score'])
print(hyperparameters_search_results['search_results'])
print(evaluation_results['threshold'])
print(evaluation_results['cv_threshold_metrics'])
print(evaluation_results['cv_splits_threshold_metrics'])
print(evaluation_results['cv_splits_threshold_metrics_summary'])
print(evaluation_results['test_threshold_metrics'])
print(train_results['estimator'])
print(predictions)
Example on SMS Spam Collection Dataset (auto-generated results)
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.feature_selection import SelectPercentile, chi2
from sklearn.linear_model import SGDClassifier
from skrobot.core import Experiment
from skrobot.tasks import TrainTask
from skrobot.tasks import PredictionTask
from skrobot.tasks import EvaluationCrossValidationTask
from skrobot.tasks import HyperParametersSearchCrossValidationTask
from skrobot.feature_selection import ColumnSelector
######### Initialization Code
train_data_set_file_path = 'https://bit.ly/sms-spam-ham-data-train'
test_data_set_file_path = 'https://bit.ly/sms-spam-ham-data-test'
new_data_set_file_path = 'https://bit.ly/sms-spam-ham-data-new'
field_delimiter = '\t'
random_seed = 42
pipe = Pipeline(steps=[
('column_selection', ColumnSelector(cols=['message'], drop_axis=True)),
('vectorizer', CountVectorizer()),
('tfidf', TfidfTransformer()),
('feature_selection', SelectPercentile(chi2)),
('classifier', SGDClassifier(loss='log'))])
search_params = {
'classifier__max_iter': [ 20, 50, 80 ],
'classifier__alpha': [ 0.00001, 0.000001 ],
'classifier__penalty': [ 'l2', 'elasticnet' ],
"vectorizer__stop_words" : [ "english", None ],
"vectorizer__ngram_range" : [ (1, 1), (1, 2) ],
"vectorizer__max_df": [ 0.5, 0.75, 1.0 ],
"tfidf__use_idf" : [ True, False ],
"tfidf__norm" : [ 'l1', 'l2' ],
"feature_selection__percentile" : [ 70, 60, 50 ]
}
######### skrobot Code
# Build an Experiment
experiment = Experiment('experiments-output').set_source_code_file_path(__file__).set_experimenter('echatzikyriakidis').build()
# Run Hyperparameters Search Task
hyperparameters_search_results = experiment.run(HyperParametersSearchCrossValidationTask (estimator=pipe,
search_params=search_params,
train_data_set_file_path=train_data_set_file_path,
field_delimiter=field_delimiter,
random_seed=random_seed).random_search().stratified_folds(total_folds=5, shuffle=True))
# Run Evaluation Task
evaluation_results = experiment.run(EvaluationCrossValidationTask(estimator=pipe,
estimator_params=hyperparameters_search_results['best_params'],
train_data_set_file_path=train_data_set_file_path,
test_data_set_file_path=test_data_set_file_path,
field_delimiter=field_delimiter,
random_seed=random_seed,
export_classification_reports=True,
export_confusion_matrixes=True,
export_pr_curves=True,
export_roc_curves=True,
export_false_positives_reports=True,
export_false_negatives_reports=True,
export_also_for_train_folds=True).stratified_folds(total_folds=5, shuffle=True))
# Run Train Task
train_results = experiment.run(TrainTask(estimator=pipe,
estimator_params=hyperparameters_search_results['best_params'],
train_data_set_file_path=train_data_set_file_path,
field_delimiter=field_delimiter,
random_seed=random_seed))
# Run Prediction Task
predictions = experiment.run(PredictionTask(estimator=train_results['estimator'],
data_set_file_path=new_data_set_file_path,
field_delimiter=field_delimiter))
# Print in-memory results
print(hyperparameters_search_results['best_params'])
print(hyperparameters_search_results['best_index'])
print(hyperparameters_search_results['best_estimator'])
print(hyperparameters_search_results['best_score'])
print(hyperparameters_search_results['search_results'])
print(evaluation_results['threshold'])
print(evaluation_results['cv_threshold_metrics'])
print(evaluation_results['cv_splits_threshold_metrics'])
print(evaluation_results['cv_splits_threshold_metrics_summary'])
print(evaluation_results['test_threshold_metrics'])
print(train_results['estimator'])
print(predictions)
Sample of auto-generated results
Classification Reports
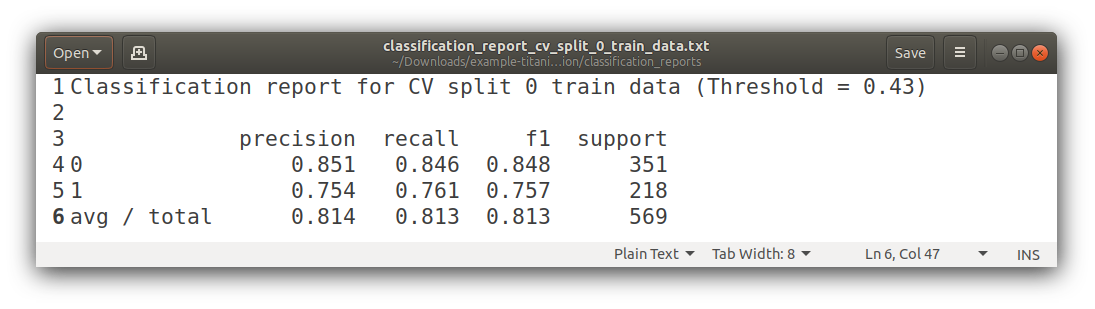
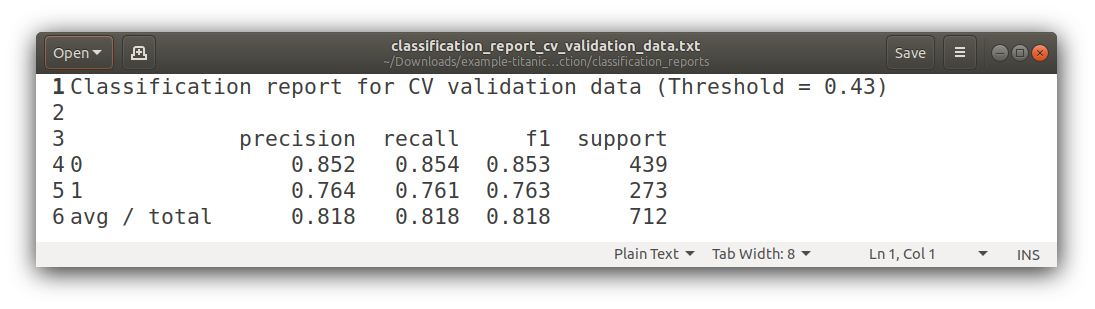
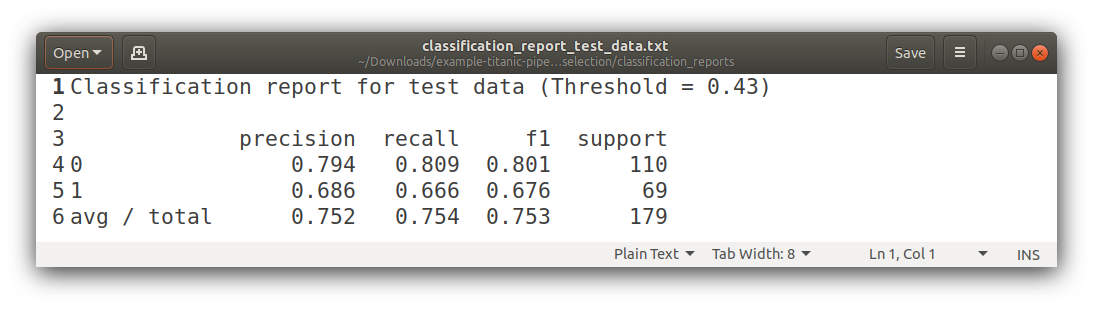
Confusion Matrixes
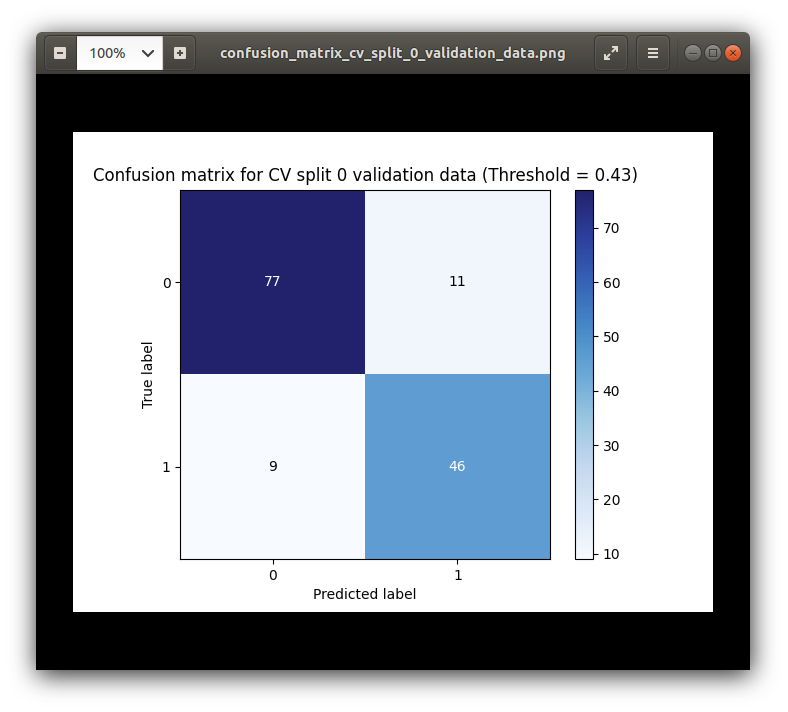
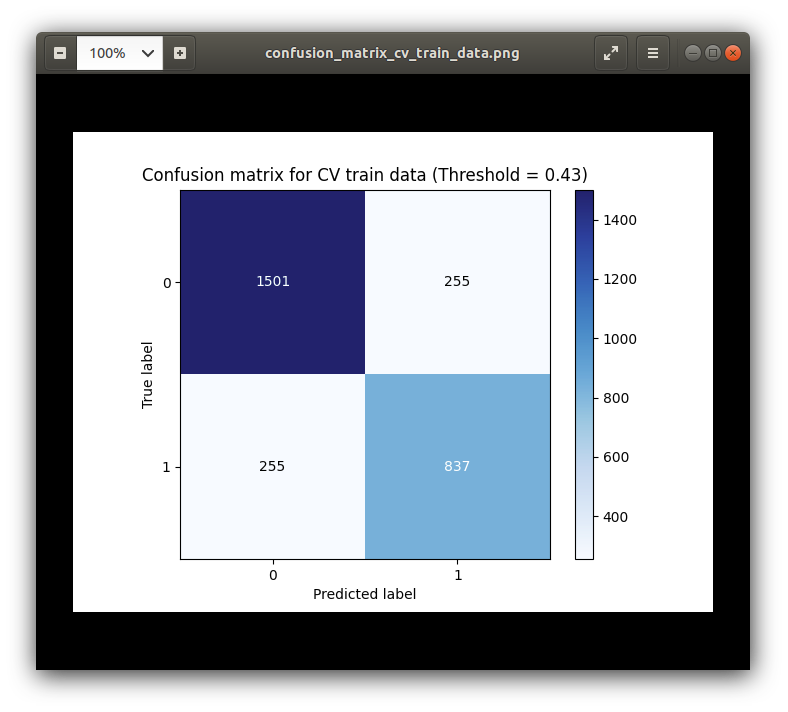
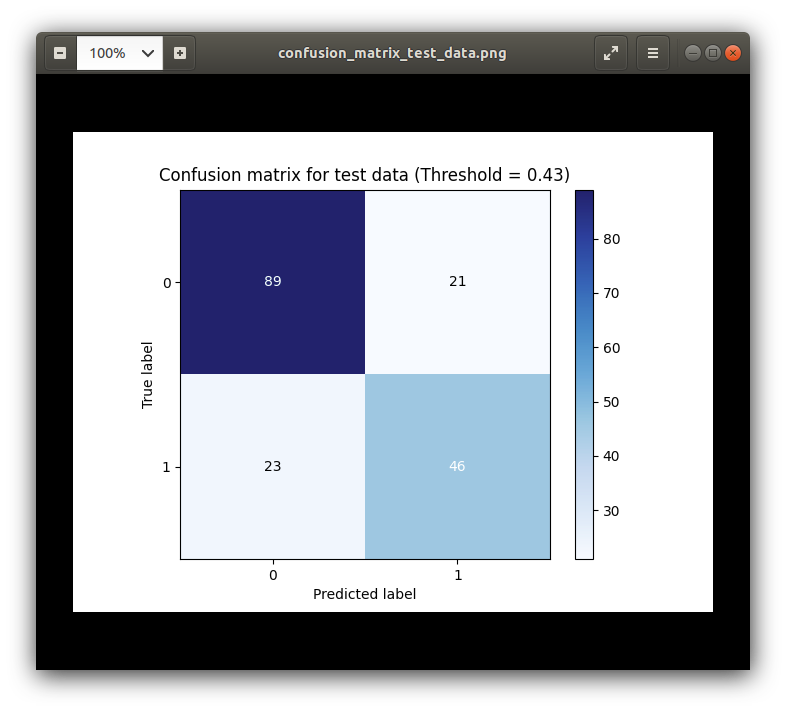
False Negatives
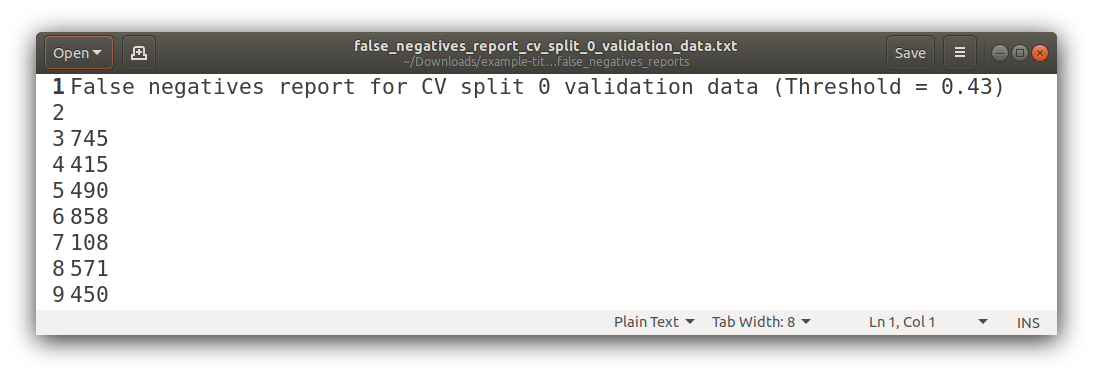
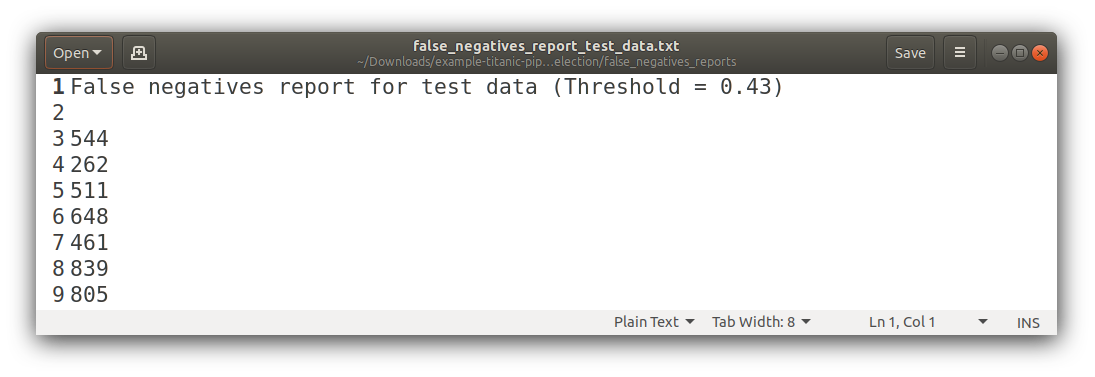
False Positives
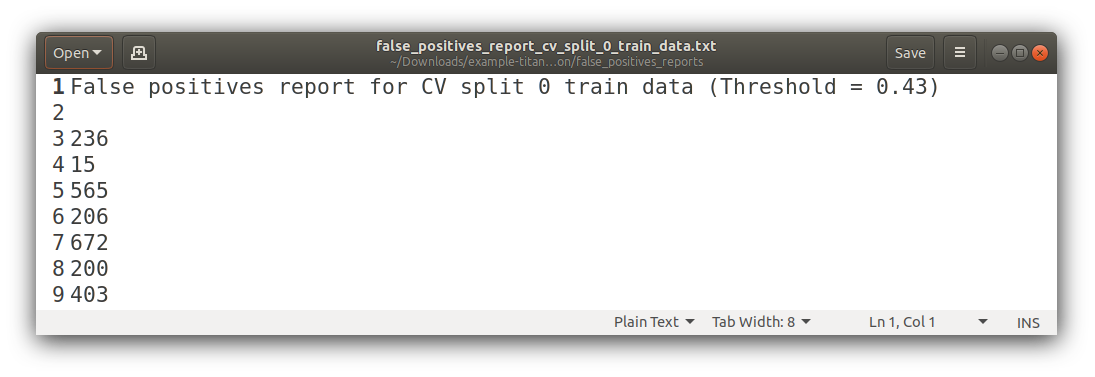
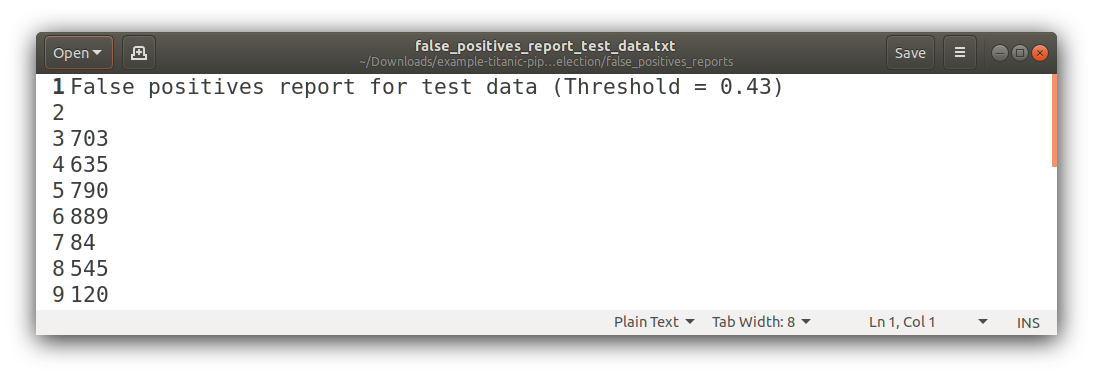
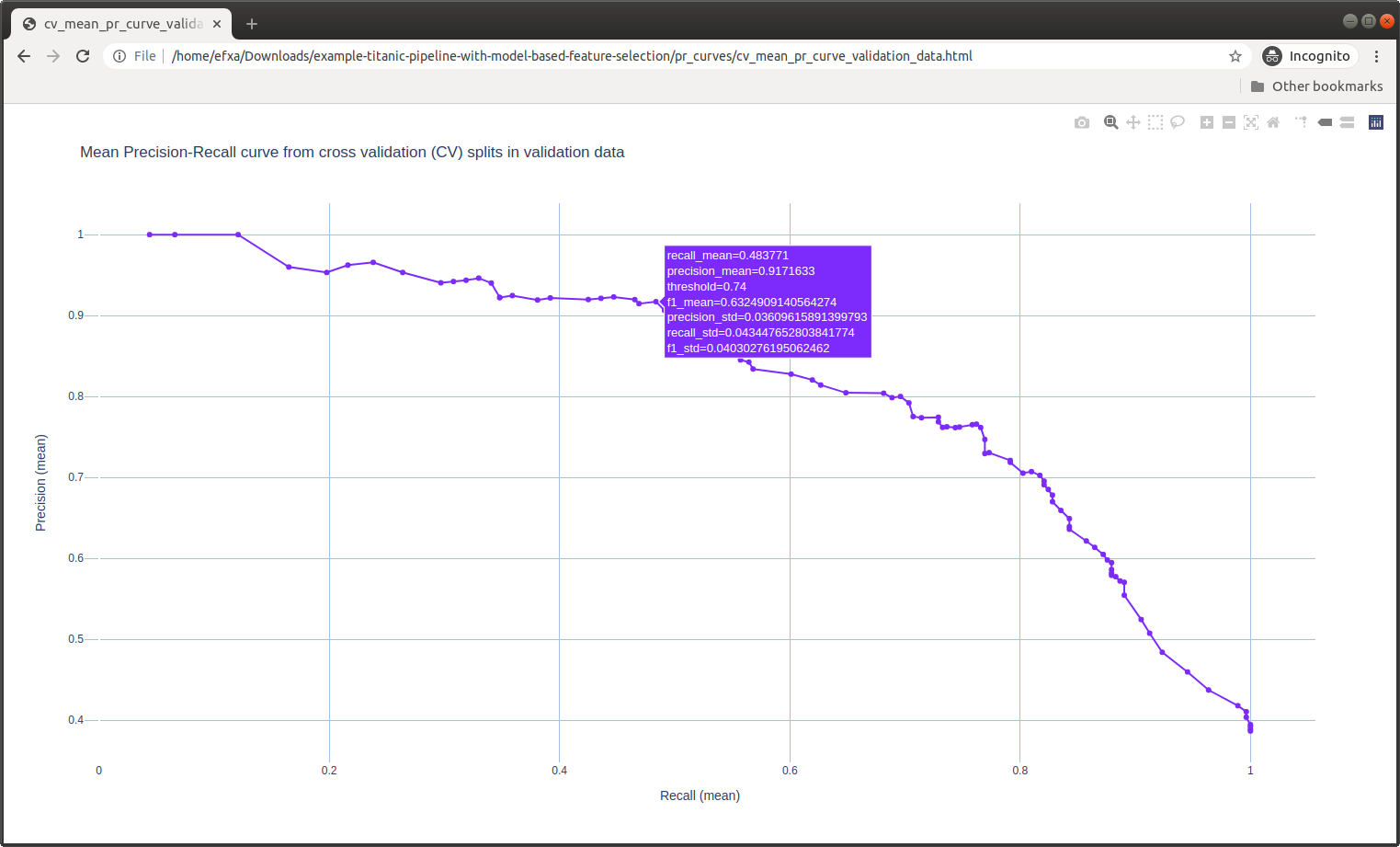
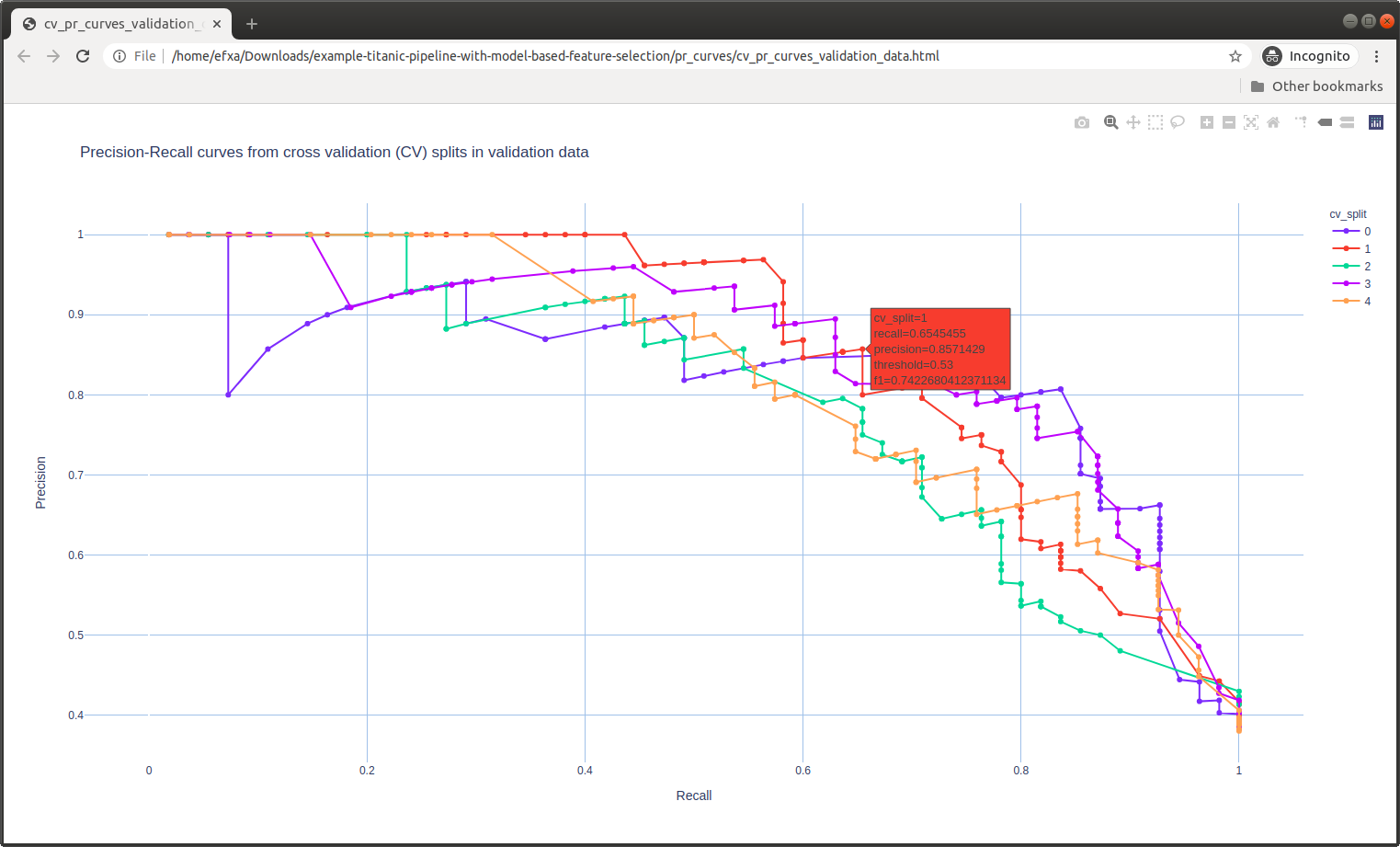
PR Curves
ROC Curves
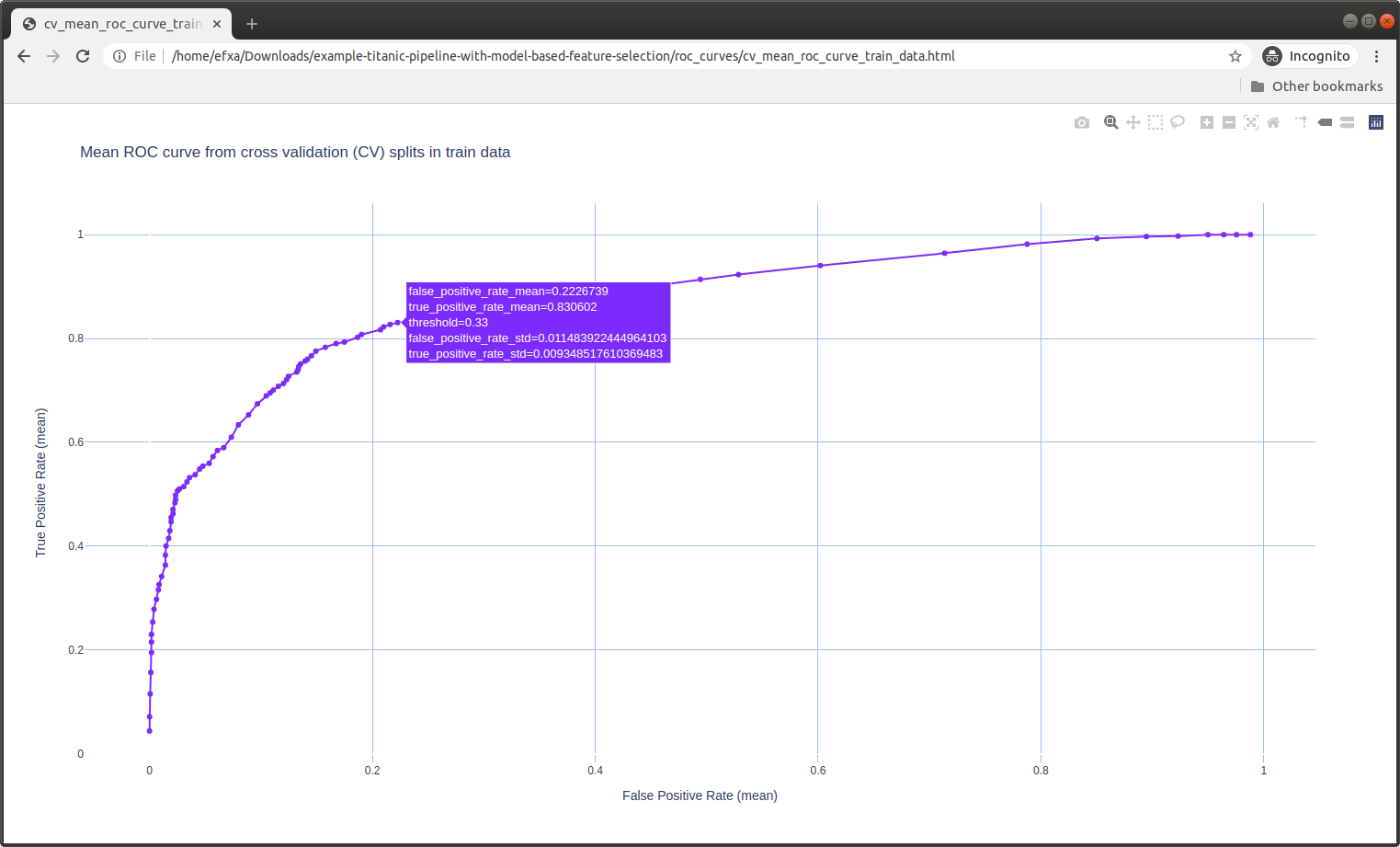
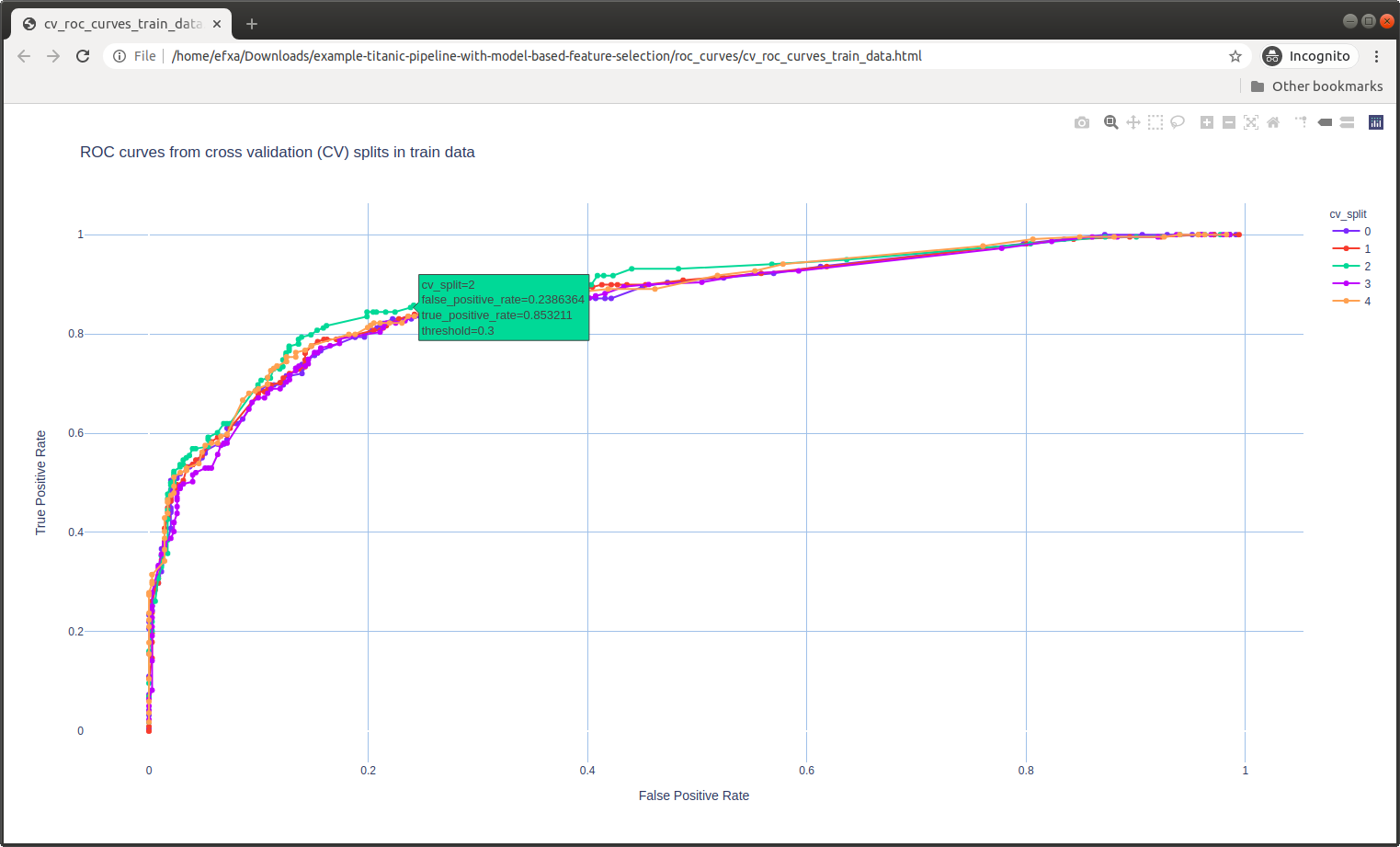
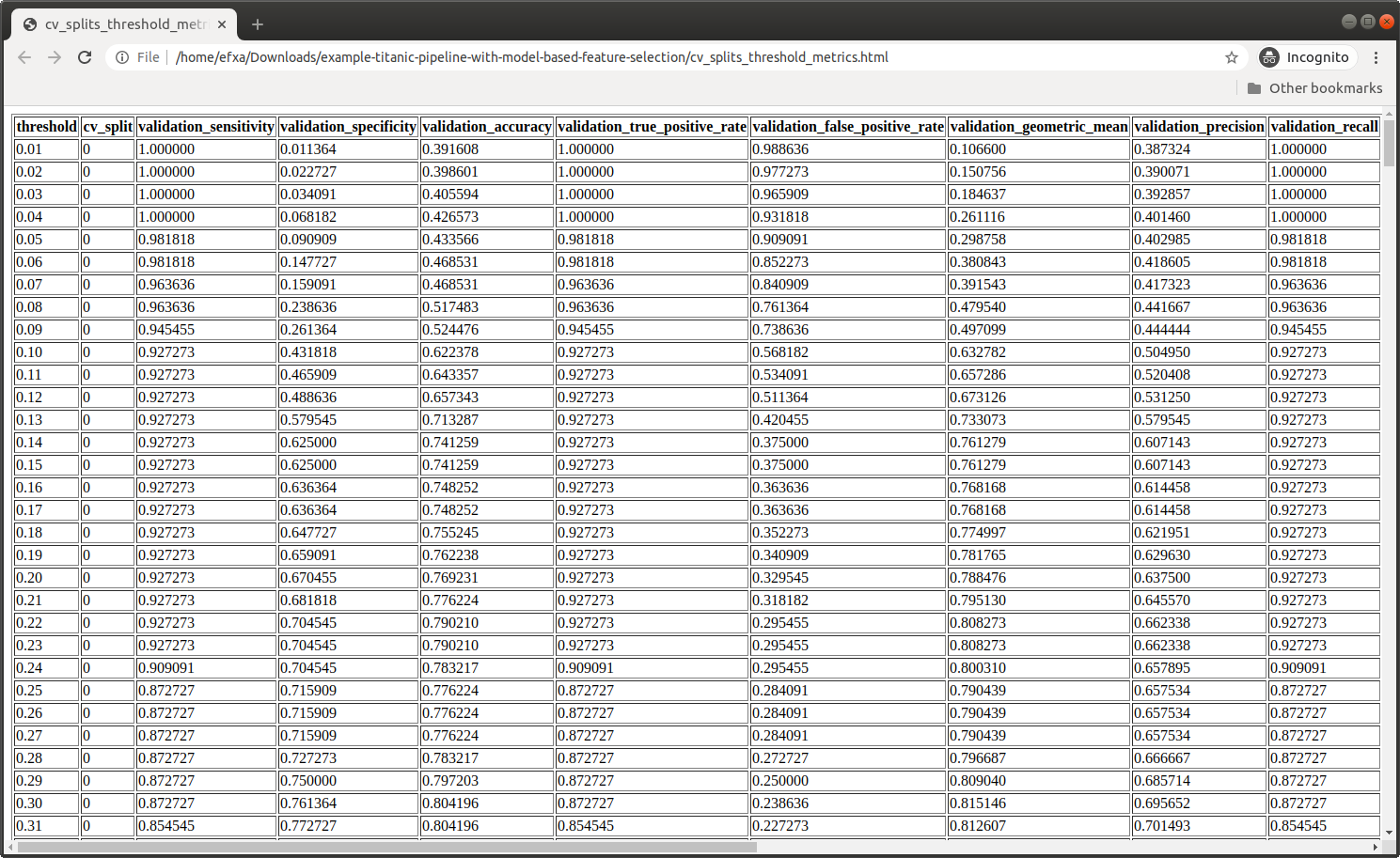
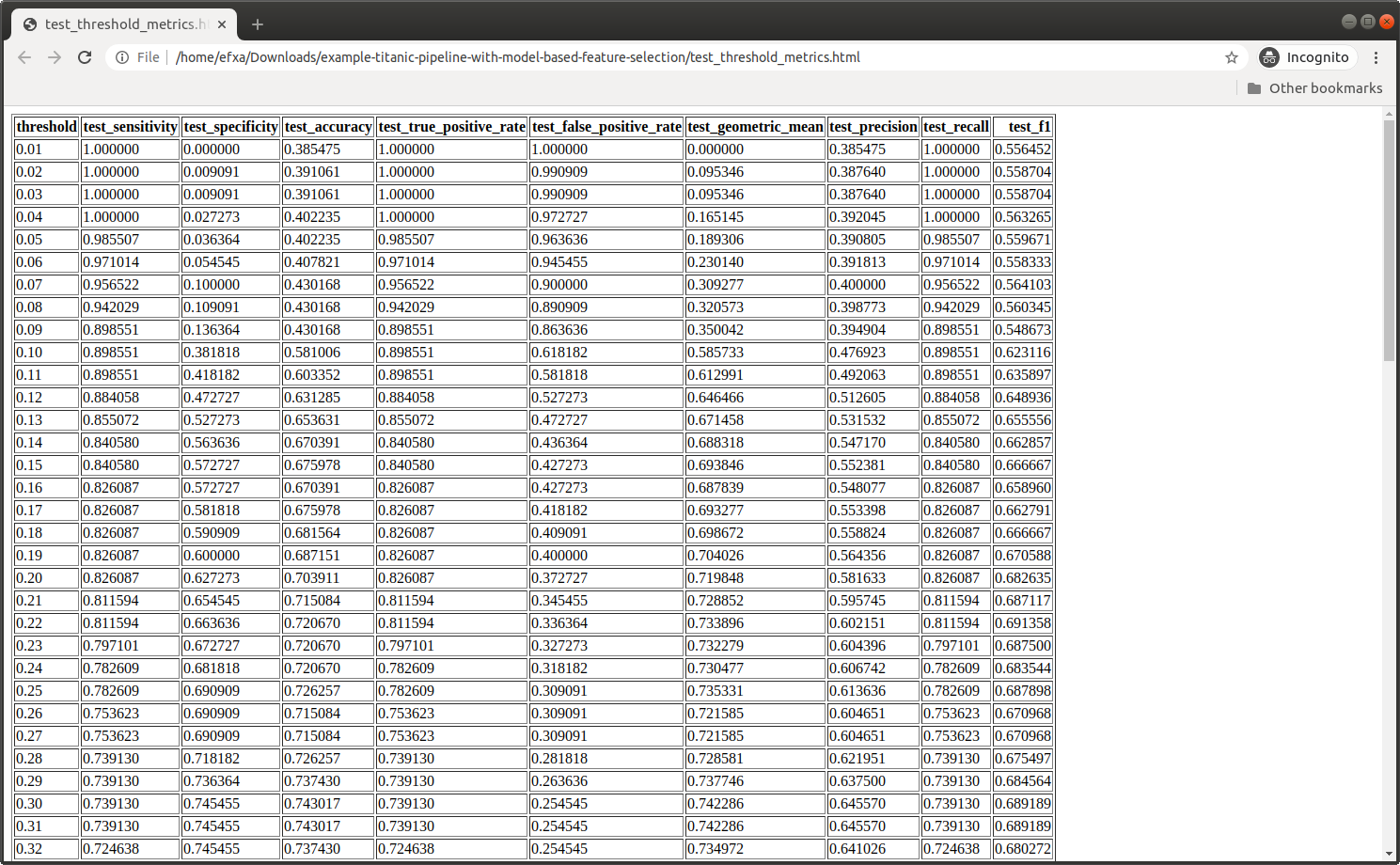
Performance Metrics
On train / validation CV folds:
On hold-out test set:
Hyperparameters Search Results
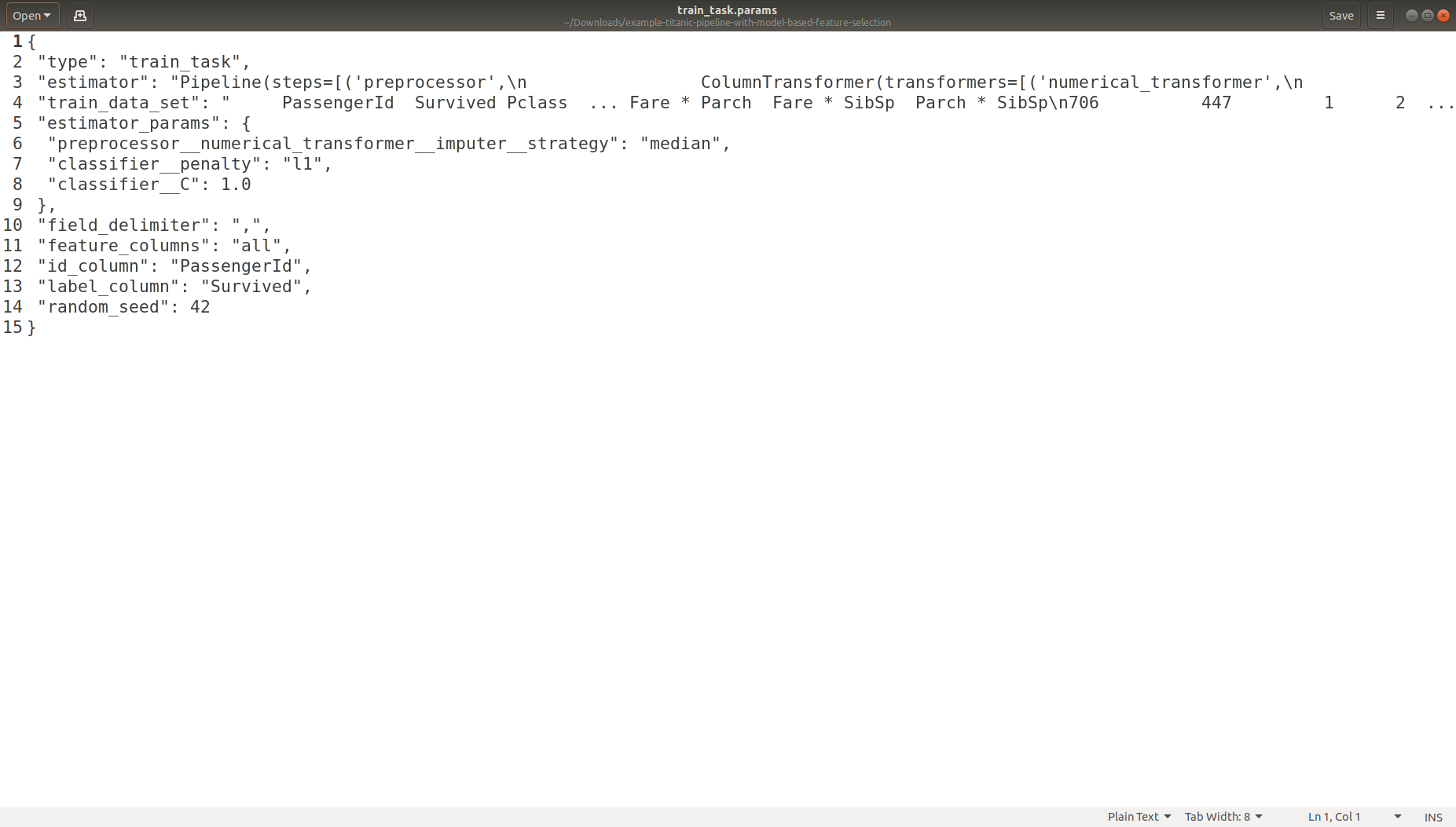
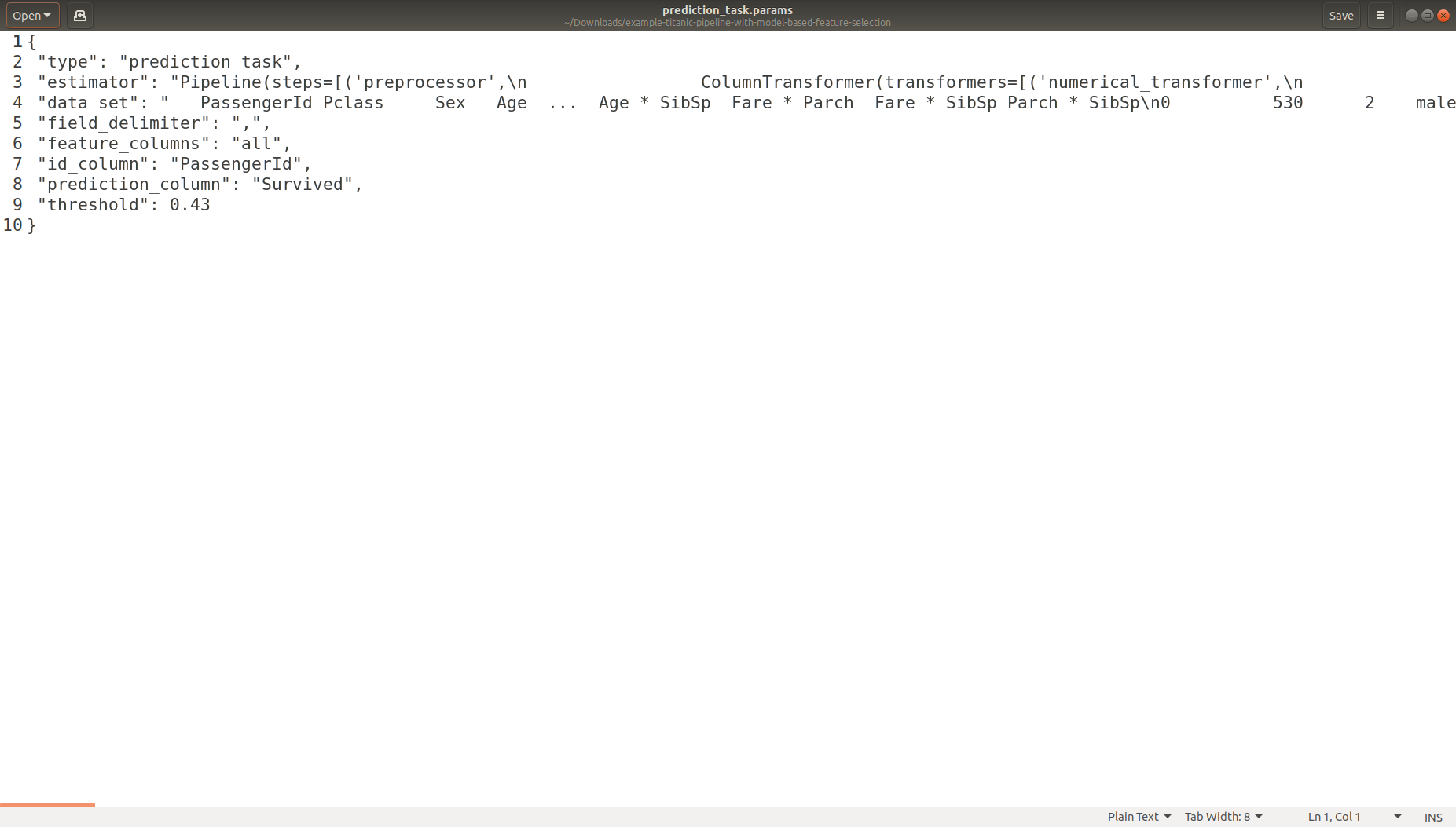
Task Parameters Logging
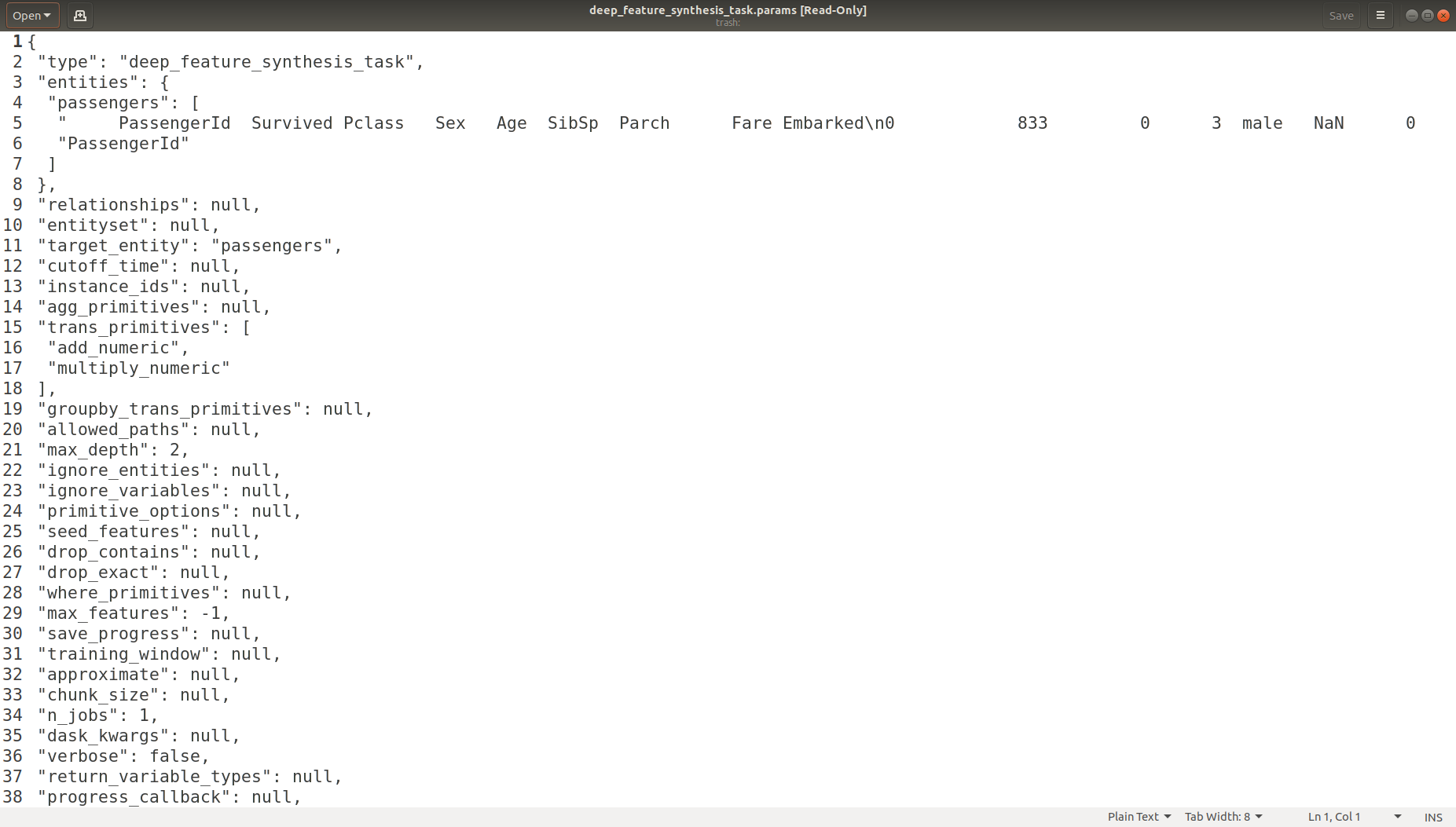
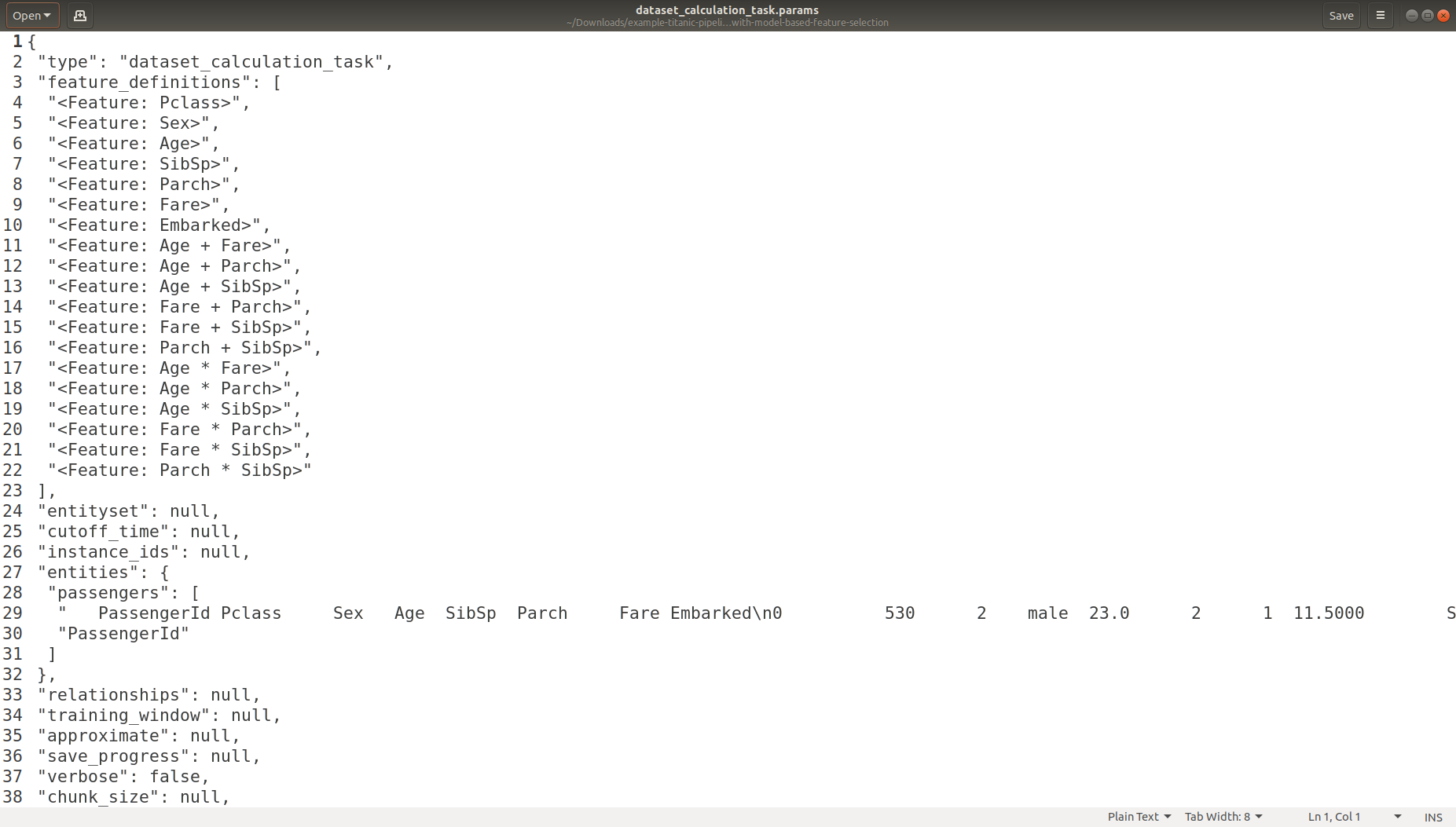
Experiment Logging
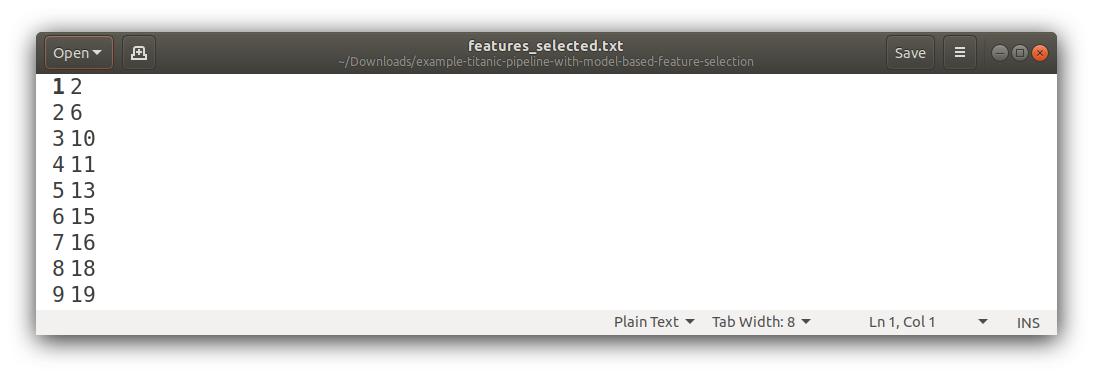
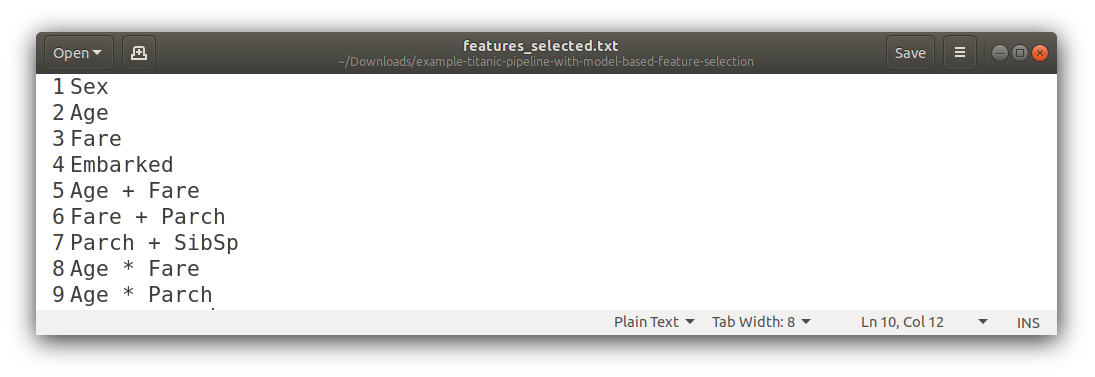
Features Selected
The selected column indexes from the transformed features (this is generated when a preprocessor is used):
The selected column names from the original features (this is generated when no preprocessor is used):
Expreriment Source Code
Predictions
Thank you!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file skrobot-1.0.5.tar.gz.
File metadata
- Download URL: skrobot-1.0.5.tar.gz
- Upload date:
- Size: 21.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/45.2.0.post20200210 requests-toolbelt/0.8.0 tqdm/4.42.1 CPython/3.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
25e2779a813beeac981c7d3223e56771aeec6427fcf6b0dfe5a3c0c8cab173b8
|
|
| MD5 |
577d2f9e490b4ef563d6e9c807ee6a97
|
|
| BLAKE2b-256 |
cac7956f136b392f958af825cb5bc6998f107b3a064520e220f306df245554f5
|







