Small, dependable HTML cleaner/minifier with sensible defaults

Project description

smol-html
Small, dependable HTML cleaner/minifier with sensible defaults.
Credits
This package is built on top of excellent open-source projects:
- minify-html (MIT License) – High-performance HTML minifier.
- lxml (BSD-like License) – Fast and feature-rich XML/HTML parsing and cleaning.
- BeautifulSoup4 (MIT License) – Python library for parsing and navigating HTML/XML.
- Brotli (MIT License) – Compression algorithm developed by Google.
We are grateful to the maintainers and contributors of these projects — smol-html wouldn’t be possible without their work.
Motivation
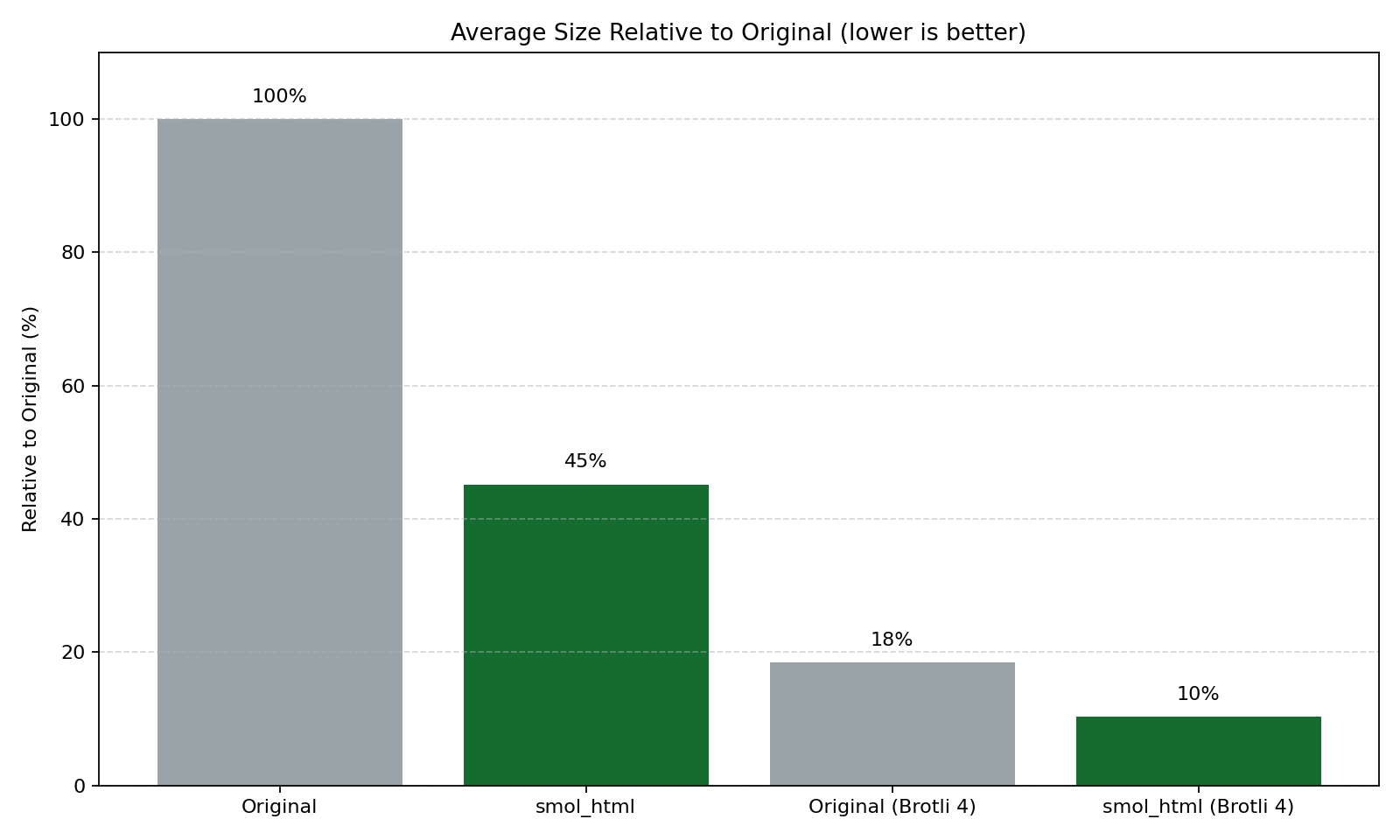
Nosible is a search engine, which means we need to store and process a very large number of webpages. To make this tractable, we strip out visual chrome and other non-essential components that don’t matter for downstream tasks (indexing, ranking, retrieval, and LLM pipelines) while preserving the important content and structure. This package cleans and minifies HTML, greatly reducing size on disk; combined with Brotli compression (by Google), the savings are even larger.
📦 Installation
pip install smol-html
⚡ Installing with uv
uv pip install smol-html
Optional extras
Some features are optional and only used if you enable them:
- Readability-style article isolation (content_isolator="readability")
- Fast DOM pre-pass using selectolax (prepass_selectolax=True)
Install extras via:
# Readability-style article extraction.
pip install "smol-html[readability]"
# Fast selectolax pre-pass.
pip install "smol-html[selectolax]"
# Everything.
pip install "smol-html[all]"
Requirements
- Python: 3.9
- Dependencies:
- beautifulsoup4>=4.0.1
- brotli>=0.5.2
- lxml[html-clean]>=1.3.2
- minify-html>=0.2.6
- Optional dependencies:
- readability-lxml (for content_isolator="readability")
- selectolax (for prepass_selectolax=True)
Quick Start
Clean an HTML string (or page contents):
from smol_html import SmolHtmlCleaner
html = """
<html>
<head><title> Example </title></head>
<body>
<div> Hello <span> world </span> </div>
</body>
</html>
"""
# All constructor arguments are keyword-only and optional.
cleaner = SmolHtmlCleaner()
cleaned = cleaner.make_smol(raw_html=html)
print(cleaned)
Customization
SmolHtmlCleaner exposes keyword-only parameters with practical defaults. You can:
- Pass overrides to the constructor, or
- Adjust attributes on the instance after creation.
from smol_html import SmolHtmlCleaner
cleaner = SmolHtmlCleaner()
cleaner.attr_stop_words.add("advert") # e.g., add a custom stop word
Usage Examples
Minimal:
from smol_html import SmolHtmlCleaner
cleaner = SmolHtmlCleaner()
out = cleaner.make_smol(raw_html="<p>Hi <!-- note --> <a href='x'>link</a></p>")
Customize a few options:
from smol_html import SmolHtmlCleaner
cleaner = SmolHtmlCleaner(
attr_stop_words={"nav", "advert"},
remove_header_lists=False,
minify=True,
)
out = cleaner.make_smol(raw_html="<p>Hi</p>")
Use advanced options:
from smol_html import SmolHtmlCleaner
cleaner = SmolHtmlCleaner(
# More aggressive chrome stripping:
aggressive_strip=True,
# Strip tracking parameters from links:
strip_tracking_query=True,
# Remove 1x1 / CSS-hidden tracking pixels:
strip_tracking_pixels=True,
# Normalize tables for better text extraction:
table_normalize=True,
# Collect micro-benchmark stats for this run:
report_stats=True,
)
out = cleaner.make_smol(raw_html=html)
print(out)
print(cleaner.last_stats)
# {
# "bytes_before": ...,
# "bytes_after": ...,
# "pct_delta": ...,
# "node_count": ...,
# "wall_time_ms": ...
# }
Optional content isolator (requires readability-lxml):
from smol_html import SmolHtmlCleaner
cleaner = SmolHtmlCleaner(content_isolator="readability")
article_html = cleaner.make_smol(raw_html=raw_news_page_html)
Optional fast pre-pass (requires selectolax):
from smol_html import SmolHtmlCleaner
cleaner = SmolHtmlCleaner(
prepass_selectolax=True,
prepass_kill_classes={"cookie-banner", "newsletter-signup"},
prepass_kill_ids={"sidebar", "promo"},
)
out = cleaner.make_smol(raw_html=html)
Compressed Bytes Output
Produce compressed bytes using Brotli with make_smol_bytes.
- By default, the compressed bytes are URL-safe Base64 encoded (
base64_encode=True). - If you enable Base64, you must decode before Brotli-decompressing.
- You can disable Base64 by passing
base64_encode=Falseand decompress directly.
Default (Base64-encoded) output:
from smol_html import SmolHtmlCleaner
import base64
import brotli # only needed if you want to decompress here in the example
html = """
<html>
<body>
<div> Hello <span> world </span> </div>
</body>
</html>
"""
cleaner = SmolHtmlCleaner()
# Get compressed bytes (quality 11 is strong compression)
compressed = cleaner.make_smol_bytes(raw_html=html, compression_level=11)
# Because Base64 is enabled by default, decode before decompressing
decoded = base64.urlsafe_b64decode(compressed)
decompressed = brotli.decompress(decoded).decode("utf-8")
print(decompressed)
# Or write Base64-encoded compressed output directly to a file
with open("page.html.br.b64", "wb") as f:
f.write(compressed)
Disable Base64 and decompress directly:
from smol_html import SmolHtmlCleaner
import brotli
cleaner = SmolHtmlCleaner()
compressed_raw = cleaner.make_smol_bytes(
raw_html="<p>Hi</p>",
compression_level=11,
base64_encode=False,
)
print(brotli.decompress(compressed_raw).decode("utf-8"))
Parameter Reference
To improve readability, the reference is split into two tables:
- What it does and when to change
- Types and default values
What It Does
| Parameter | What it does | When to change |
|---|---|---|
non_text_to_keep |
Whitelist of empty/non-text tags to preserve (e.g., images, figures, tables, line breaks). | If important non-text elements are being removed or you want to keep/drop more empty tags. |
attr_stop_words |
Tokens matched against id/class/role/item_type on small elements; matches are removed as likely non-content. |
Add tokens like advert, hero, menu to aggressively drop UI chrome, or remove tokens if content is lost. |
remove_header_lists |
Removes links/lists/images within <header> to reduce nav clutter. |
Set False if your header contains meaningful content you want to keep. |
remove_footer_lists |
Removes links/lists/images within <footer> to reduce boilerplate. |
Set False for content-heavy footers you need. |
minify |
Minifies output HTML using minify_html. |
Set False for readability or debugging; use --pretty in the CLI. |
minify_kwargs |
Extra options passed to minify_html.minify. |
Tune minification behavior (e.g., whitespace, comments) without changing cleaning. |
minify_inline_css/minify_inline_js |
Convenience flags to control minify_html’s handling of inline CSS and JS (wired into minify_kwargs). |
Use when you want to force-enable or disable inline CSS/JS minification without manually building minify_kwargs. |
image_inline_threshold |
Configures a byte-size threshold for tiny images that could be inlined as data URIs (currently stored on the cleaner; reserved for higher-level integration). | Use as part of a larger pipeline if you want to decide when to inline small assets based on size. |
meta |
lxml Cleaner option: remove <meta> content when True. |
Usually leave False; enable only for strict sanitation. |
page_structure |
lxml Cleaner option: remove page-structure tags (e.g., <head>, <body>) when True. |
Rarely needed; keep False to preserve structure. |
links |
lxml Cleaner option: sanitize/clean links. | Leave True unless you need raw anchors untouched. |
scripts |
lxml Cleaner option: remove <script> tags when True. |
Keep False to preserve scripts; usually safe to remove via javascript=True anyway. |
javascript |
lxml Cleaner option: remove JS and event handlers. | Set False only if you truly need inline JS (not recommended). |
comments |
lxml Cleaner option: remove HTML comments. | Set False to retain comments for debugging. |
style |
lxml Cleaner option: remove CSS and style attributes. | Set False to keep inline styles/CSS. |
processing_instructions |
lxml Cleaner option: remove processing instructions. | Rarely change; keep for safety. |
embedded |
lxml Cleaner option: remove embedded content (e.g., <embed>, <object>). |
Set False to keep embedded media. |
frames |
lxml Cleaner option: remove frames/iframes. | Set False if iframes contain needed content. |
forms |
lxml Cleaner option: remove form elements. | Set False if you need to keep forms/inputs. |
annoying_tags |
lxml Cleaner option: remove tags considered "annoying" by lxml (e.g., <blink>, <marquee>). |
Rarely change. |
kill_tags |
Additional explicit tags to remove entirely. | Add site-specific or custom tags to drop. |
remove_unknown_tags |
lxml Cleaner option: drop unknown/invalid tags. | Set False if you rely on custom elements. |
safe_attrs_only |
Only allow attributes listed in safe_attrs. |
Set False if you need to keep arbitrary attributes. |
safe_attrs |
Allowed HTML attributes when safe_attrs_only=True. |
Extend to keep additional attributes you trust. |
strip_tracking_query |
Strips common tracking query parameters (utm_*, gclid, fbclid) from <a href> URLs. |
Enable when you want canonical, non-tracking URLs for downstream indexing/RAG. |
strip_tracking_pixels |
Removes likely tracking pixels (1×1 images or CSS-hidden images), before lxml cleaning. | Enable when you want to avoid storing/processing common tracking beacons. |
table_normalize |
Normalizes table cells, currently converting <br> inside td/th to spaces to improve text extraction. |
Enable for cleaner linear text from tables, especially for RAG and summarization. |
prepass_selectolax |
Runs a fast selectolax-based pre-pass to delete nodes matching prepass_kill_tags, prepass_kill_classes, prepass_kill_ids before full parsing. |
Enable when you know specific tags/classes/ids to drop early (e.g., cookie banners, sidebars) and you have selectolax installed. |
prepass_kill_tags / prepass_kill_classes / prepass_kill_ids |
Killlists applied by the optional selectolax pre-pass. | Configure when using prepass_selectolax=True to tailor early DOM pruning to your sites. |
content_isolator |
Optional content isolation strategy; currently supports readability via readability-lxml. |
Set to readability when you want to extract the primary article/content before cleaning. |
report_stats |
When True, make_smol records a small micro-benchmark for each call in last_stats. |
Enable when you want per-page metrics like size delta and wall-clock time to monitor effectiveness. |
Types and Defaults
| Parameter | Type | Default |
|---|---|---|
non_text_to_keep |
set[str] |
media/meta/table/br tags |
attr_stop_words |
set[str] |
common UI/navigation tokens |
aggressive_strip |
bool |
False |
remove_header_lists |
bool |
True |
remove_footer_lists |
bool |
True |
minify |
bool |
True |
minify_kwargs |
dict |
{} |
minify_inline_css |
bool or None |
None |
minify_inline_js |
bool or None |
None |
image_inline_threshold |
int or None |
None |
meta |
bool |
False |
page_structure |
bool |
False |
links |
bool |
True |
scripts |
bool |
False |
javascript |
bool |
True |
comments |
bool |
True |
style |
bool |
True |
processing_instructions |
bool |
True |
embedded |
bool |
True |
frames |
bool |
True |
forms |
bool |
True |
annoying_tags |
bool |
True |
kill_tags |
set[str] | None |
None |
remove_unknown_tags |
bool |
True |
safe_attrs_only |
bool |
True |
safe_attrs |
set[str] |
curated set |
strip_tracking_query |
bool |
False |
strip_tracking_pixels |
bool |
False |
table_normalize |
bool |
False |
prepass_selectolax |
bool |
False |
prepass_kill_tags |
set[str] |
set() |
prepass_kill_classes |
set[str] |
set() |
prepass_kill_ids |
set[str] |
set() |
content_isolator |
str |
None |
report_stats |
bool |
False |
make_smol_bytes Options
| Parameter | Type | Default |
|---|---|---|
compression_level |
int |
4 |
base64_encode |
bool |
True |


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file smol_html-0.2.0.tar.gz.
File metadata
- Download URL: smol_html-0.2.0.tar.gz
- Upload date:
- Size: 2.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
97335dad2d52a909d0f0f4434db97e5a3bcdcd3be3cc98ebc728dbb5831cb268
|
|
| MD5 |
40b0122d3312587db9ca477343f36430
|
|
| BLAKE2b-256 |
ba456adbfe2b3b290cb05f3376d04d14cac6b6fb5d6cac1b6ad0603288599fe1
|
File details
Details for the file smol_html-0.2.0-py3-none-any.whl.
File metadata
- Download URL: smol_html-0.2.0-py3-none-any.whl
- Upload date:
- Size: 6.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
18508e477d6d23b2caea3c7560ddd0a0b3bbda91e50e86c9bb48959186451f33
|
|
| MD5 |
e1196ce5c567594587f890b14b89cc05
|
|
| BLAKE2b-256 |
c2cff83bb66c63580eeea74df8517999bc8a28712e38938da052d194980cfec7
|







