Comprehensive ServiceNow data loader for AI/LLM pipelines - Incidents, CMDB, KB, Changes, Catalog & more. Works with LangChain & LlamaIndex.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

snowloader
Production ServiceNow data loader for AI, RAG, and agent pipelines.
Created by Roni Das · thetotaltechnology@gmail.com












Documentation · PyPI · Source · Install · API cheatsheet · Roadmap
TL;DR
from snowloader import SnowConnection, IncidentLoader
with SnowConnection(instance_url="https://yourcompany.service-now.com",
username="api_user", password="api_pass") as conn:
docs = IncidentLoader(connection=conn, query="active=true").load()
Three lines from a ServiceNow instance to a list of documents your vector store understands. Same loader objects work with LangChain, LlamaIndex, or anything else that accepts a list of dicts.
Architecture
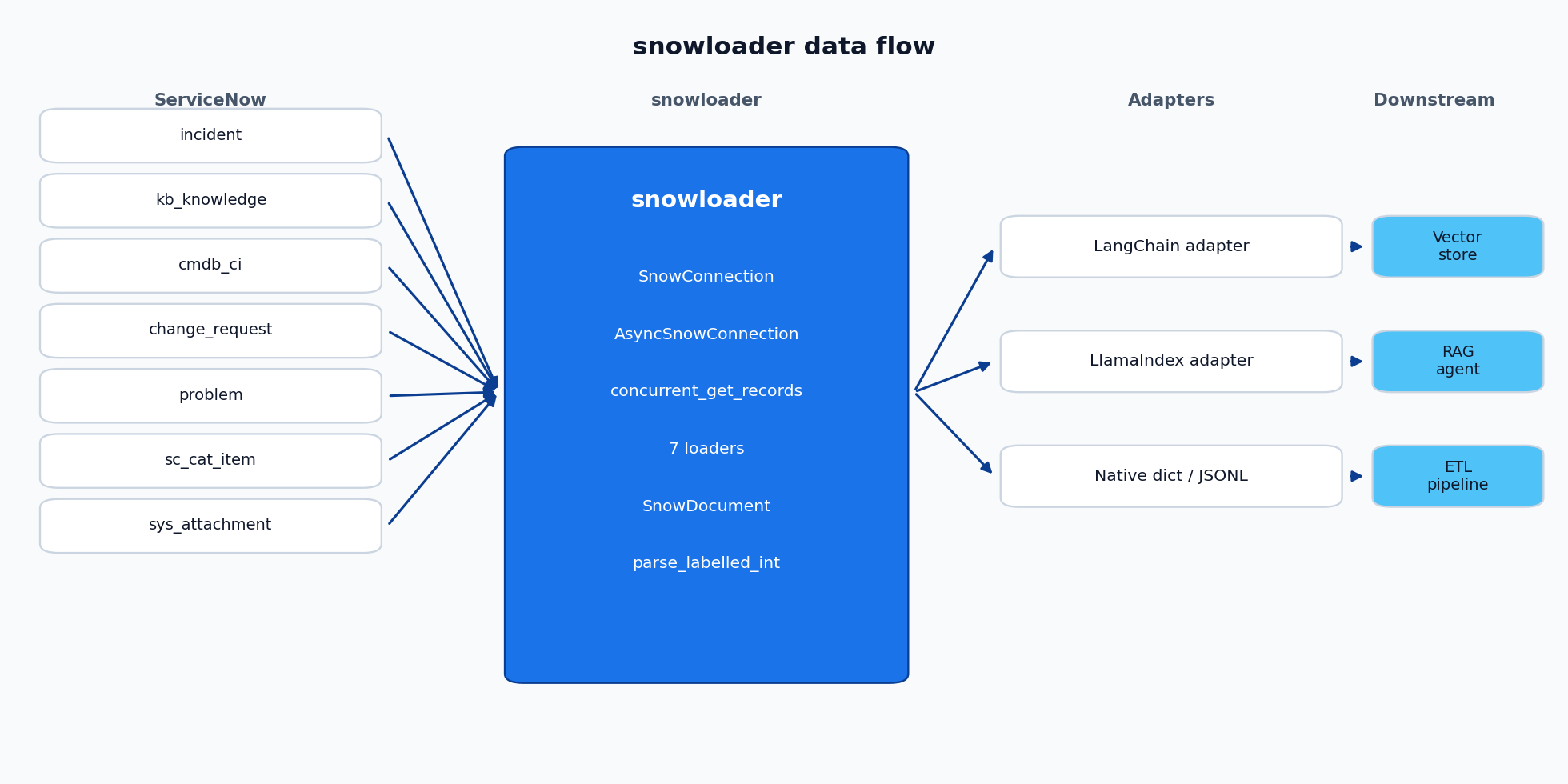
snowloader sits between ServiceNow's Table API and whatever LLM stack you are building. The connection layer handles auth, pagination, retries, and rate limiting. The loaders normalize each table into a SnowDocument. The adapters translate that into LangChain Document or LlamaIndex Document types without copying business logic.
Why snowloader?
Building RAG or agentic AI on top of ServiceNow data? Existing tools either cover a single table, ignore relationships, or lock you into one framework. snowloader covers the seven core tables, gives you sync + threaded + async paginators, and stays framework-agnostic at the core so you can plug it into LangChain, LlamaIndex, or your own pipeline.
Seven loadersIncidents, Knowledge Base, CMDB, Changes, Problems, Catalog, and Attachments. One consistent interface across all of them. |
Three pagination pathsSequentialget_records, threaded concurrent_get_records, async aget_records. Pick the one that fits your runtime.
|
Four auth modesBasic, OAuth Password, OAuth Client Credentials, Bearer Token. Switching is a constructor argument. |
Delta syncload_since(datetime) on every loader. Only fetch what changed since your last run.
|
CMDB graph walkingPull configuration items together with their parent / child / depends-on relationships fromcmdb_rel_ci.
|
Streaming everywhereGenerators and async iterators throughout. The full table never lives in memory at once. |
Built-in HTML cleanerKB articles arrive as plain text. No BeautifulSoup, no extra dependencies. |
Production-gradeRetry with backoff, rate limiting, thread-safe sessions, proxy support, custom CA bundles. |
Strict typingPEP 561 marker,mypy --strict clean, full type hints on every public surface.
|
Installation
# pip
pip install snowloader # Core only
pip install snowloader[async] # + AsyncSnowConnection (aiohttp)
pip install snowloader[langchain] # + LangChain adapter
pip install snowloader[llamaindex] # + LlamaIndex adapter
pip install snowloader[all] # Everything
# uv
uv add snowloader
uv add snowloader[all]
Requirements: Python 3.10, 3.11, 3.12, or 3.13. A ServiceNow instance with REST Table API access.
API cheatsheet
| Loader | ServiceNow table | Highlight |
|---|---|---|
IncidentLoader |
incident |
Optional journal entries (work notes + comments) |
KnowledgeBaseLoader |
kb_knowledge |
HTML auto-stripped, plain text out |
CMDBLoader |
cmdb_ci_* |
Concurrent relationship graph traversal |
ChangeLoader |
change_request |
Implementation window details |
ProblemLoader |
problem |
Known error flag normalized to bool |
CatalogLoader |
sc_cat_item |
Active / inactive normalized to bool |
AttachmentLoader |
sys_attachment |
Optional eager download with size cap |
Every loader exposes the same interface:
loader.load() # list[SnowDocument]
loader.lazy_load() # generator
loader.load_since(datetime_cutoff) # list[SnowDocument]
loader.concurrent_load(max_workers) # threaded
loader.concurrent_lazy_load(...) # threaded generator
Async siblings (when installed with [async]) follow the same shape: aload, alazy_load, aload_since.
Pick the right pagination path
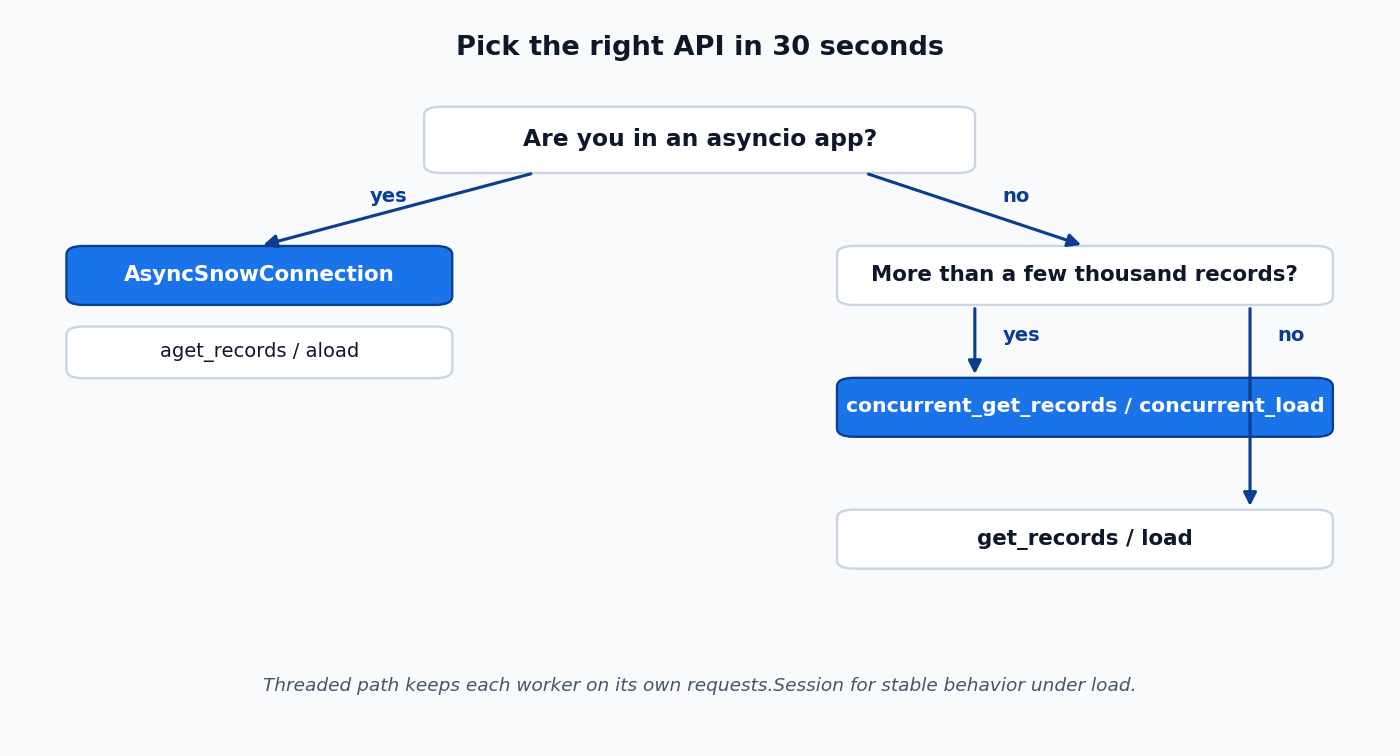
Three concurrency models, three jobs:
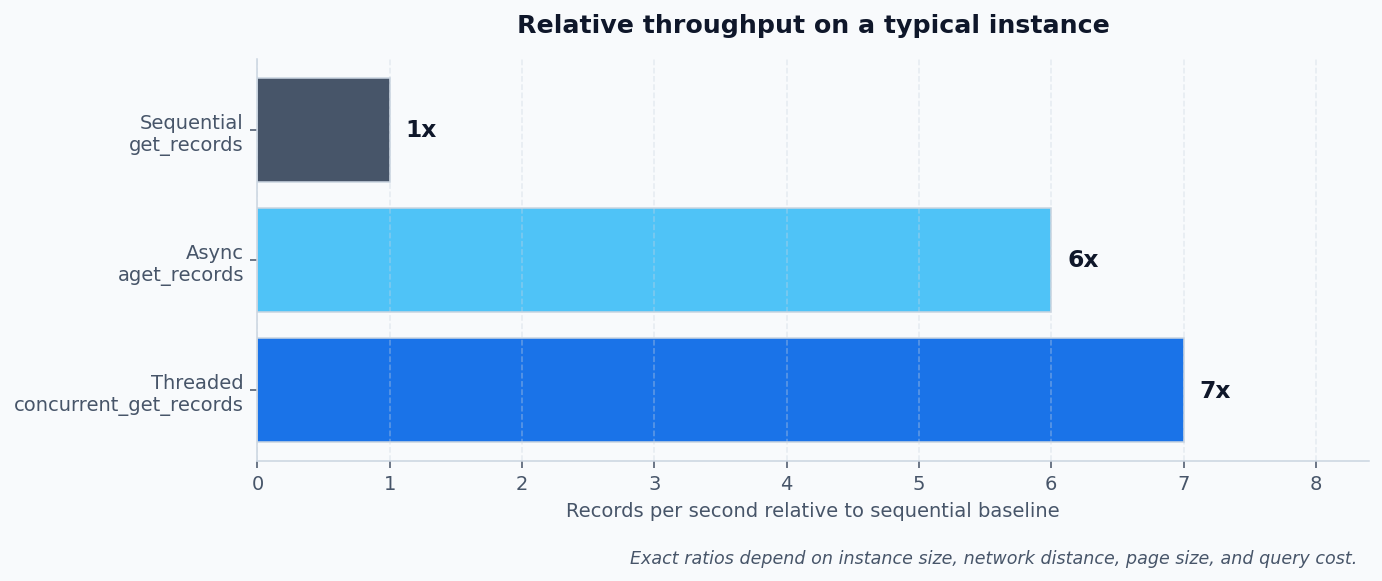
The threaded path uses a per-thread requests.Session, which keeps connection pools and TLS state isolated per worker and avoids the connection-reuse failures some ServiceNow front ends exhibit when many concurrent requests share one session.
Code recipes
Sequential extraction (the simplest path)
from snowloader import SnowConnection, IncidentLoader
with SnowConnection(
instance_url="https://yourcompany.service-now.com",
username="api_user",
password="api_pass",
) as conn:
loader = IncidentLoader(connection=conn, query="active=true^priority<=2")
for doc in loader.lazy_load():
process(doc)
Threaded extraction (sync, fast)
from snowloader import SnowConnection, IncidentLoader
with SnowConnection(
instance_url="https://yourcompany.service-now.com",
username="api_user",
password="api_pass",
page_size=500,
) as conn:
total = conn.get_count("incident", query="state=6^close_notesISNOTEMPTY")
for record in conn.concurrent_get_records(
table="incident",
query="state=6^close_notesISNOTEMPTY",
max_workers=16,
):
process(record)
loader = IncidentLoader(connection=conn, query="state=6^close_notesISNOTEMPTY")
docs = loader.concurrent_load(max_workers=16)
Async extraction (asyncio apps)
import asyncio
from snowloader import AsyncSnowConnection, AsyncIncidentLoader
async def main() -> None:
async with AsyncSnowConnection(
instance_url="https://yourcompany.service-now.com",
username="api_user",
password="api_pass",
page_size=500,
concurrency=16,
) as conn:
loader = AsyncIncidentLoader(connection=conn, query="active=true")
async for doc in loader.alazy_load():
print(doc.page_content[:200])
asyncio.run(main())
Every sync loader has a matching Async* variant. The framework adapters expose async forms too (AsyncServiceNow*Loader for LangChain, AsyncServiceNow*Reader for LlamaIndex).
LangChain adapter
from snowloader import SnowConnection
from snowloader.adapters.langchain import ServiceNowIncidentLoader
conn = SnowConnection(
instance_url="https://yourcompany.service-now.com",
username="api_user",
password="api_pass",
)
loader = ServiceNowIncidentLoader(connection=conn, query="active=true")
docs = loader.load() # list[langchain_core.documents.Document]
# Plug straight into any vector store
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
vectorstore = FAISS.from_documents(docs, OpenAIEmbeddings())
LlamaIndex adapter
from snowloader.adapters.llamaindex import ServiceNowIncidentReader
reader = ServiceNowIncidentReader(connection=conn, query="active=true")
docs = reader.load_data() # list[llama_index.core.schema.Document]
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(docs)
Delta sync
from datetime import datetime, timezone
loader = IncidentLoader(connection=conn)
docs = loader.load() # First run: everything
last_sync = datetime.now(timezone.utc)
updated = loader.load_since(last_sync) # Subsequent runs: only changes
CMDB relationship graph
from snowloader import CMDBLoader
loader = CMDBLoader(
connection=conn,
ci_class="cmdb_ci_server",
include_relationships=True,
)
for doc in loader.lazy_load():
# -> db-prod-01 (Depends on::Used by)
# <- load-balancer-01 (Depends on::Used by)
print(doc.page_content)
Journal entries (work notes + comments)
loader = IncidentLoader(connection=conn, query="active=true", include_journals=True)
for doc in loader.lazy_load():
print(doc.page_content)
# Incident: INC0000007
# Summary: Need access to sales DB
# ...
# [work_notes] 2024-06-01 09:15:00 by alice
# Restarted Exchange service, monitoring.
Also works with ChangeLoader and ProblemLoader.
Attachments
from snowloader import AttachmentLoader
# Metadata only
loader = AttachmentLoader(connection=conn, query="table_name=kb_knowledge")
for doc in loader.lazy_load():
print(doc.metadata["file_name"], doc.metadata["size_bytes"])
# Download a specific file by sys_id
loader.download_to("att_sys_id", "./out/diagram.png")
# Eager download with size cap (10 MB)
loader = AttachmentLoader(connection=conn, download=True, max_size_bytes=10 * 1024 * 1024)
for doc in loader.lazy_load():
blob = doc.metadata.get("content_bytes")
Authentication (4 modes)
# Basic Auth (development)
conn = SnowConnection(instance_url="...", username="admin", password="pass")
# OAuth Client Credentials (recommended for production)
conn = SnowConnection(instance_url="...", client_id="...", client_secret="...")
# OAuth Password Grant
conn = SnowConnection(instance_url="...", client_id="...", client_secret="...",
username="...", password="...")
# Bearer Token (pre-obtained)
conn = SnowConnection(instance_url="...", token="eyJhbG...")
Recipe: large-scale extraction with resume support
A common pattern for AI knowledge bases is two parallel corpus pulls. Closed and resolved tickets become a recommendation corpus; active tickets become a duplicate-prevention corpus. Both need raw API output (with sysparm_display_value=all), JSONL streaming, resume on crash, and end-of-run validation against the API count.
import json
from pathlib import Path
from snowloader import SnowConnection
QUERY = (
"stateIN6,7"
"^close_notesISNOTEMPTY"
"^sys_updated_on>=javascript:gs.daysAgoStart(730)"
"^ORDERBYsys_created_on"
)
FIELDS = ["sys_id", "number", "short_description", "close_notes",
"state", "priority", "urgency", "impact", "category",
"assignment_group", "caller_id", "assigned_to",
"opened_at", "resolved_at", "sys_updated_on"]
output_path = Path("incidents_closed.jsonl")
state_path = Path("incidents_closed.state.json")
state = json.loads(state_path.read_text()) if state_path.exists() else {"completed": []}
completed_offsets = set(state["completed"])
with SnowConnection(
instance_url="https://yourcompany.service-now.com",
username="api_user",
password="api_pass",
page_size=1000,
display_value="all",
max_retries=5,
) as conn:
mode = "a" if completed_offsets else "w"
with output_path.open(mode, encoding="utf-8") as fh:
for record in conn.concurrent_get_records(
table="incident", query=QUERY, fields=FIELDS, max_workers=16
):
sid = record["sys_id"].get("value") if isinstance(record["sys_id"], dict) else record["sys_id"]
num = record["number"].get("value") if isinstance(record["number"], dict) else record["number"]
if not sid or not num:
continue
fh.write(json.dumps(record, ensure_ascii=False) + "\n")
line_count = sum(1 for _ in output_path.open("r"))
api_total = conn.get_count("incident", query=QUERY)
print(f"file: {line_count}, api: {api_total}, drift: {line_count - api_total}")
For the full pattern with offset-level checkpointing (so a crash mid-run loses at most a few seconds of work), see the concurrent documentation page.
Configuration
| Parameter | Default | Description |
|---|---|---|
page_size |
100 |
Records per API call (1 - 10,000) |
timeout |
60 |
HTTP timeout in seconds |
max_retries |
3 |
Retry attempts for 429 / 500 / 502 / 503 / 504 |
retry_backoff |
1.0 |
Base delay between retries (doubles each attempt) |
request_delay |
0.0 |
Minimum seconds between requests (rate limiting) |
display_value |
"true" |
sysparm_display_value setting (true / false / all) |
proxy |
None |
HTTP / HTTPS proxy URL |
verify |
True |
SSL verification (or path to a custom CA bundle) |
See the full documentation for every parameter.
Roadmap
| Version | Feature | Status |
|---|---|---|
| v0.1 | Six sync loaders, LangChain + LlamaIndex adapters, 4 auth modes, delta sync, journal entries, HTML cleaning, CMDB graph traversal |  |
| v0.2 | Async support (aiohttp) and async variants of every loader and adapter |
|
| v0.2 | Attachment loader for sys_attachment with optional eager download and size cap |
|
| v0.2 | Threaded sync paginator (concurrent_get_records, concurrent_load) with per-thread sessions |
|
| v0.2 | parse_labelled_int helper for fields like priority, urgency, impact |
|
| v0.3 | Direct vector store streaming (Pinecone, Weaviate, Chroma, Qdrant) |  |
| v0.3 | Checkpoint and resume for very large loads | |
| v1.0 | Custom field mapping for heavily customized instances | |
Contributing
Contributions are welcome.
- Fork the repository
- Create a feature branch
- Write tests first (the project uses
pytest+responsesfor HTTP mocking) - Ensure the quality gate passes:
ruff check src/ tests/ && ruff format --check src/ tests/ && mypy src/snowloader/ && pytest tests/ -x
- Open a pull request
Author
|
Roni Das thetotaltechnology@gmail.com github.com/ronidas39 |
Built snowloader because every ServiceNow + AI project I picked up started with the same boilerplate. The library is the version of that boilerplate I want every team to be able to start from. |
License
MIT. See LICENSE for the full text.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file snowloader-0.2.8.tar.gz.
File metadata
- Download URL: snowloader-0.2.8.tar.gz
- Upload date:
- Size: 708.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
145df411c3c95479bad6adbf4e6cc49d1bf5141c79d6e301d0b4703f41a29321
|
|
| MD5 |
e7f102e8b4f4daf37e5653d88f2b3887
|
|
| BLAKE2b-256 |
cbc243973d68c8105cc8e78ae1848ec59b09ca021882fbadbaf8a623948674dc
|
Provenance
The following attestation bundles were made for snowloader-0.2.8.tar.gz:
Publisher:
publish.yml on ronidas39/snowloader
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
snowloader-0.2.8.tar.gz -
Subject digest:
145df411c3c95479bad6adbf4e6cc49d1bf5141c79d6e301d0b4703f41a29321 - Sigstore transparency entry: 1396693250
- Sigstore integration time:
-
Permalink:
ronidas39/snowloader@c8aef08c5c81e84380cd60f7368dd97dd82c7634 -
Branch / Tag:
refs/tags/v0.2.8 - Owner: https://github.com/ronidas39
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@c8aef08c5c81e84380cd60f7368dd97dd82c7634 -
Trigger Event:
push
-
Statement type:
File details
Details for the file snowloader-0.2.8-py3-none-any.whl.
File metadata
- Download URL: snowloader-0.2.8-py3-none-any.whl
- Upload date:
- Size: 55.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4e802e05c0e9156d47276d68b68718b9a7c0e73ea991f2caef3dfc3b5233c235
|
|
| MD5 |
56cbb601a2c269cecc682e76fb05ae67
|
|
| BLAKE2b-256 |
481244dfd99a65ed692b5f46627dbf8c41b7551adc31cee7f891fa626c22ebf4
|
Provenance
The following attestation bundles were made for snowloader-0.2.8-py3-none-any.whl:
Publisher:
publish.yml on ronidas39/snowloader
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
snowloader-0.2.8-py3-none-any.whl -
Subject digest:
4e802e05c0e9156d47276d68b68718b9a7c0e73ea991f2caef3dfc3b5233c235 - Sigstore transparency entry: 1396693254
- Sigstore integration time:
-
Permalink:
ronidas39/snowloader@c8aef08c5c81e84380cd60f7368dd97dd82c7634 -
Branch / Tag:
refs/tags/v0.2.8 - Owner: https://github.com/ronidas39
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@c8aef08c5c81e84380cd60f7368dd97dd82c7634 -
Trigger Event:
push
-
Statement type:







