STAC optimizer with a state-free sign trunk and AdamW on the final trainable-module tail.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
stac-optimizer




Korean README | Optimizer docs | Korean docs | Benchmark JSON
STAC means "SignSGD Trunk, AdamW Cap". It keeps the sign trunk state-free, uses AdamW only on the final trainable-module tail, and is tuned to reduce optimizer-state VRAM without giving up tail stability.
| Item | Value |
|---|---|
| Python | >=3.13 |
| PyTorch | >=2.10 |
| Default split | last_n_ratio=0.125 |
| Explicit override | last_n_modules |
| Default sign decay in hybrid mode | 0.5 * weight_decay |
| Default no-decay policy | bias + 1-D parameters |
| Preferred public ratio arg | last_n_ratio (adamw_ratio remains supported) |
Flow
flowchart LR
A["Trainable modules<br/>registration order"]
B["Resolve AdamW cap<br/>`last_n_modules` or<br/>default `last_n_ratio=12.5%`"]
subgraph S["State-free sign trunk"]
C["Earlier modules"]
D["Decoupled weight decay on weight tensors<br/>bias + 1-D params skip decay by default<br/>parameter -= lr * sign(grad)<br/>no momentum, no sign-side state"]
end
subgraph T["AdamW cap"]
E["Final tail modules"]
F["Standard AdamW on the tail<br/>bias + 1-D params skip decay by default<br/>exp_avg + exp_avg_sq"]
end
A --> B
B --> C
B --> E
C --> D
E --> F
classDef neutral fill:#f8fafc,stroke:#475569,color:#0f172a,stroke-width:1px;
classDef sign fill:#d7f0e8,stroke:#0f766e,color:#134e4a,stroke-width:1.5px;
classDef adam fill:#dbeafe,stroke:#2563eb,color:#1d4ed8,stroke-width:1.5px;
class A,B neutral;
class C,D sign;
class E,F adam;
Install
python -m pip install stac-optimizer
For local development and benchmark generation:
python -m pip install -e ".[dev]"
Quickstart
import torch
from torch import nn
from stac_optimizer import STAC
model = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10),
)
optimizer = STAC(
model,
lr=1e-3,
last_n_ratio=0.125,
weight_decay=1e-2,
error_if_nonfinite=True,
)
loss = torch.nn.functional.mse_loss(
model(torch.randn(8, 128)),
torch.randn(8, 10),
)
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
last_n_ratio counts only modules that directly own trainable parameters.
Pure containers such as nn.Sequential are skipped unless they own parameters
themselves. Use last_n_modules when you want an explicit cap size instead.
Bias tensors and 1-D parameters such as LayerNorm scales skip decoupled weight
decay by default in both sections.
CUDA Research Snapshot
The repository benchmark is CUDA-only and uses held-out validation splits,
5 paired seeds, seeded teachers, seeded student initialization, fixed batch
schedules per seed, deep residual models, a transformer-like sequence task
with embeddings and LayerNorm, BF16 autocast when supported, epoch-by-epoch
validation loss curves, and a first-step optimizer-memory probe.
The AdamW baseline uses the same bias/1-D no-decay grouping so the comparison
does not hinge on a different weight-decay policy.
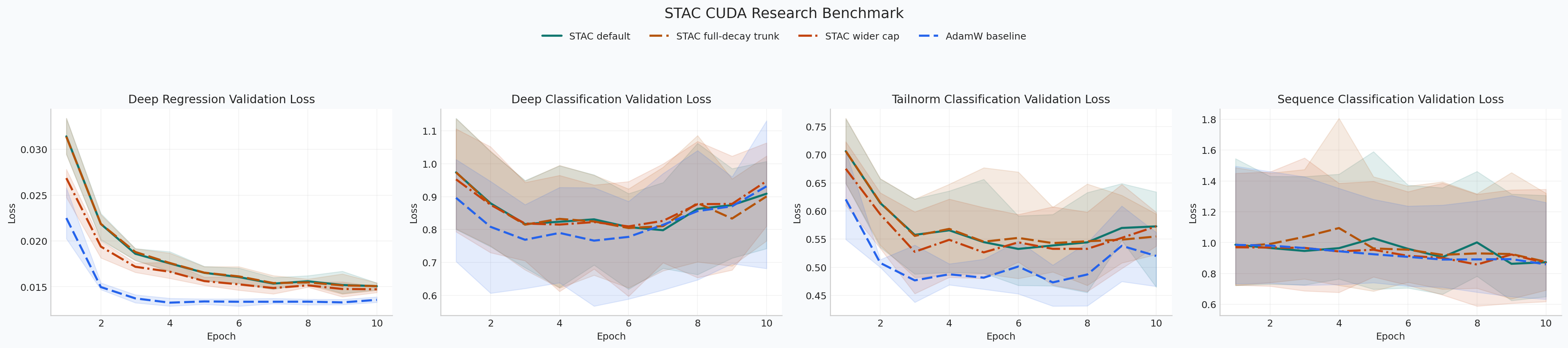
Snapshot from 2026-03-19 on torch 2.10.0+cu126 and
NVIDIA GeForce RTX 3070:
| Config | Setup | Deep regression val loss | Deep classification val acc | TailNorm val acc | Sequence val acc | Optimizer state MB | Peak step delta MB |
|---|---|---|---|---|---|---|---|
STAC default |
last_n_ratio=0.125, hybrid default sign decay, bias/1-D no-decay |
0.015066 |
0.7006 |
0.7984 |
0.6909 |
8.133 |
16.125 |
STAC full-decay trunk |
last_n_ratio=0.125, sign_weight_decay=weight_decay, bias/1-D no-decay |
0.015075 |
0.6994 |
0.8064 |
0.7089 |
8.133 |
16.125 |
STAC wider cap |
last_n_ratio=0.25, bias/1-D no-decay |
0.014726 |
0.6943 |
0.7996 |
0.6909 |
24.149 |
36.125 |
AdamW baseline |
full AdamW with the same no-decay policy in practice | 0.013574 |
0.7129 |
0.8268 |
0.7190 |
98.227 |
147.188 |
Repository takeaway: the default preset cuts optimizer state from
98.227 MB to 8.133 MB, the full-decay variant keeps the same memory profile
while helping the norm-heavy and sequence tasks a bit, and the wider cap spends
more AdamW state to improve regression. Those are repository-local measurements,
not universal guarantees.
Verify
python -m pytest -q
python examples/research_benchmark.py --device cuda
rm -rf build dist
python -m build
python -m twine check dist/*
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file stac_optimizer-0.3.0.tar.gz.
File metadata
- Download URL: stac_optimizer-0.3.0.tar.gz
- Upload date:
- Size: 520.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b2b4c69afe9ea911c2ad2675ef414aafd33f0191e14a2a55e054bf116ae20766
|
|
| MD5 |
3c41de3577311e981234244731ce13d2
|
|
| BLAKE2b-256 |
1c1f122276e3af12dca146f1e6c06e164be61f8ff4deff16069e79201316cdac
|
Provenance
The following attestation bundles were made for stac_optimizer-0.3.0.tar.gz:
Publisher:
workflow.yml on smturtle2/stac-optimizer
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
stac_optimizer-0.3.0.tar.gz -
Subject digest:
b2b4c69afe9ea911c2ad2675ef414aafd33f0191e14a2a55e054bf116ae20766 - Sigstore transparency entry: 1134155568
- Sigstore integration time:
-
Permalink:
smturtle2/stac-optimizer@8873d232a4b37a7c5a2e67c2b4801f4f9c92abc5 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/smturtle2
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
workflow.yml@8873d232a4b37a7c5a2e67c2b4801f4f9c92abc5 -
Trigger Event:
push
-
Statement type:
File details
Details for the file stac_optimizer-0.3.0-py3-none-any.whl.
File metadata
- Download URL: stac_optimizer-0.3.0-py3-none-any.whl
- Upload date:
- Size: 13.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3c0517270c1d7bd56339cd98c324bb103e38dc98c53e550674dd0ae059779593
|
|
| MD5 |
e26f7aafeacca524a41211655b8e2b9f
|
|
| BLAKE2b-256 |
87008287531d2840b50ae614ef3f7624b185b3ef01cfacf9ecfc959d222d3257
|
Provenance
The following attestation bundles were made for stac_optimizer-0.3.0-py3-none-any.whl:
Publisher:
workflow.yml on smturtle2/stac-optimizer
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
stac_optimizer-0.3.0-py3-none-any.whl -
Subject digest:
3c0517270c1d7bd56339cd98c324bb103e38dc98c53e550674dd0ae059779593 - Sigstore transparency entry: 1134155631
- Sigstore integration time:
-
Permalink:
smturtle2/stac-optimizer@8873d232a4b37a7c5a2e67c2b4801f4f9c92abc5 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/smturtle2
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
workflow.yml@8873d232a4b37a7c5a2e67c2b4801f4f9c92abc5 -
Trigger Event:
push
-
Statement type:








{kind=link}