STAC optimizer with sign-based early-layer updates and AdamW on the last N trainable layers.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
stac-optimizer




It is a PyTorch optimizer that keeps the earlier trainable layers on a
momentum-stabilized sign updates and the last N trainable layers on AdamW.
The goal is simple: keep optimizer-state VRAM lower than full AdamW while
preserving strong optimization behavior where adaptive updates matter most.
| Item | Value |
|---|---|
| Python | >=3.13 |
| PyTorch | >=2.10 |
| Default split | last 1 trainable layer uses AdamW |
| Sign-updated section | decoupled weight decay + sign(EMA(grad)) |
| AdamW section | AdamW with decoupled weight decay |
| Extra VRAM knob | sign_state_dtype=torch.bfloat16 |
| Validation | local CUDA test suite + research benchmark |
Optimizer Layout
flowchart LR
A[Trainable layers in registration order] --> B[Earlier trainable layers]
A --> C[Last N trainable layers]
B --> D[Sign-updated section<br/>decoupled weight decay<br/>EMA(grad) -> sign update<br/>optional bf16 state]
C --> E[AdamW section<br/>decoupled weight decay]
Installation
python -m pip install stac-optimizer
For local development:
python -m pip install -e ".[dev]"
Quickstart
import torch
from torch import nn
from stac_optimizer import STAC
model = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10),
)
optimizer = STAC(
model,
lr=1e-3,
last_n_layers=1,
sign_momentum=0.9,
weight_decay=1e-2,
sign_state_dtype=torch.bfloat16,
error_if_nonfinite=True,
)
inputs = torch.randn(8, 128)
targets = torch.randn(8, 10)
loss = torch.nn.functional.mse_loss(model(inputs), targets)
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
print("sign layers:", optimizer.partition.sign_layer_names)
print("adamw layers:", optimizer.partition.adamw_layer_names)
Why This Design
- signSGD: Compressed Optimisation for Non-Convex Problems motivates sign-based updates as a low-state alternative to adaptive methods.
- Momentum Ensures Convergence of SIGNSGD under Weaker Assumptions
supports using momentum before taking the sign instead of raw
sign(grad). - Decoupled Weight Decay Regularization supports the AdamW-style decoupled decay used in the final section.
- Deconstructing What Makes a Good Optimizer for Autoregressive Language Models argues that much of the benefit of adaptivity can come from a small subset of parameters, which is the main motivation for concentrating AdamW in the final section.
STAC intentionally exposes a single public learning-rate knob. In mixed mode it keeps the earlier sign-updated section slightly more conservative internally, which performed more reliably than a fully matched rate on this repository's held-out CUDA study.
CUDA Research Benchmark
Primary benchmark script: examples/research_benchmark.py
Machine-readable report: docs/benchmark/research_benchmark.json
Methodology:
- CUDA only
- separate train/validation splits
5seeds12epochs and20updates per epoch- reports epoch-by-epoch validation loss curves
- measures optimizer state plus peak CUDA allocated/reserved memory on first step
Snapshot from 2026-03-19 on torch 2.10.0+cu126 and NVIDIA GeForce RTX 3070:
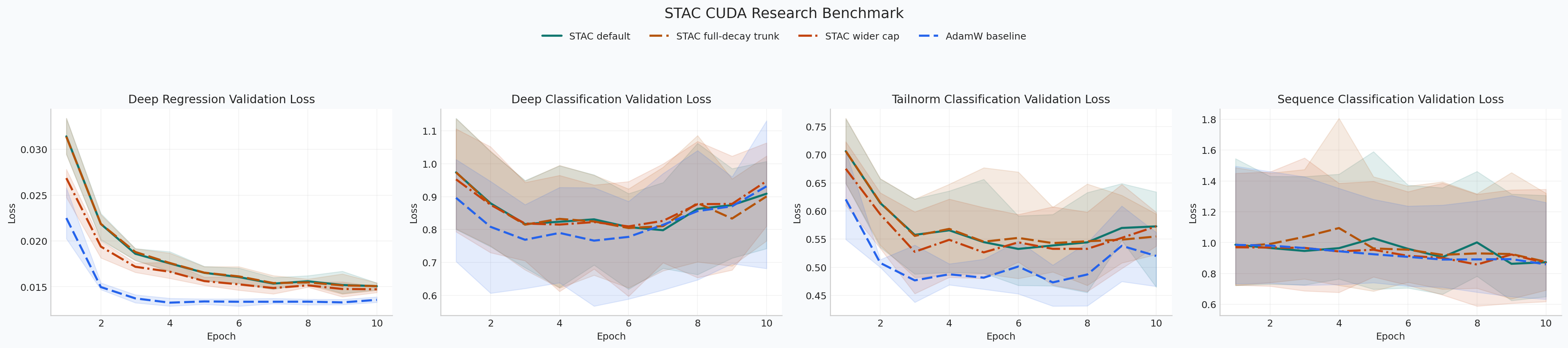
Regression validation loss:
| Optimizer | Final val loss mean | Final val loss range |
|---|---|---|
STAC default (last_n_layers=1) |
0.046044 |
0.044386 - 0.047686 |
STAC wider AdamW section (last_n_layers=2) |
0.044885 |
0.044014 - 0.046273 |
STAC plain sign update |
0.043162 |
0.041903 - 0.044614 |
AdamW baseline |
0.043753 |
0.042771 - 0.045108 |
Classification validation:
| Optimizer | Final val loss mean | Final val loss range | Final val acc mean |
|---|---|---|---|
STAC default (last_n_layers=1) |
0.303325 |
0.252935 - 0.333419 |
0.8926 |
STAC wider AdamW section (last_n_layers=2) |
0.311801 |
0.285143 - 0.320327 |
0.8918 |
STAC plain sign update |
0.314426 |
0.279694 - 0.330161 |
0.9039 |
AdamW baseline |
0.304733 |
0.275815 - 0.317797 |
0.9074 |
Memory probe:
| Optimizer | Optimizer state MB | Peak allocated MB | Peak reserved MB |
|---|---|---|---|
STAC default (last_n_layers=1) |
3.637 |
31.925 |
38.000 |
STAC wider AdamW section (last_n_layers=2) |
3.762 |
31.674 |
38.000 |
STAC plain sign update |
0.004 |
28.292 |
34.000 |
AdamW baseline |
7.270 |
35.565 |
40.000 |
This benchmark is evidence, not a universal leaderboard. It is meant to answer two practical questions for this repository:
- Does STAC remain competitive with AdamW on held-out CUDA tasks?
- Does STAC reduce optimizer-state and peak-memory pressure in practice?
Public API
The package exports:
STACpartition_trainable_layers(model, last_n_layers=1)LayerGroupSTACPartition
Useful runtime guarantees:
- deterministic sign/AdamW partitioning based on
model.named_modules() - explicit rejection of sparse gradients
- whole-step skip on non-finite dense gradients unless
error_if_nonfinite=True - checkpoint validation against saved layer names, parameter names, and state tensor shapes
Verification
python -m pytest -q
python -m build
python -m twine check dist/*
python examples/research_benchmark.py --device cuda
The repository also keeps the older quick smoke benchmark at examples/toy_benchmark.py for fast sanity checks, but the research benchmark above is the primary CUDA evidence for README claims.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file stac_optimizer-0.1.5.tar.gz.
File metadata
- Download URL: stac_optimizer-0.1.5.tar.gz
- Upload date:
- Size: 293.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e28f49947ac4b05eda317d17f837edba7526f5c5f77c8916066f6c99984a9f50
|
|
| MD5 |
566d754aab99ff85bed09035f7a630af
|
|
| BLAKE2b-256 |
8b0841d5692da9566f09cf8631cd9705bed2be90d6266391d1b2eab95e4dbbd1
|
Provenance
The following attestation bundles were made for stac_optimizer-0.1.5.tar.gz:
Publisher:
workflow.yml on smturtle2/stac-optimizer
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
stac_optimizer-0.1.5.tar.gz -
Subject digest:
e28f49947ac4b05eda317d17f837edba7526f5c5f77c8916066f6c99984a9f50 - Sigstore transparency entry: 1132622457
- Sigstore integration time:
-
Permalink:
smturtle2/stac-optimizer@3898d7d464f654874d5dc3c5985af158ad912a63 -
Branch / Tag:
refs/tags/v0.1.5 - Owner: https://github.com/smturtle2
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
workflow.yml@3898d7d464f654874d5dc3c5985af158ad912a63 -
Trigger Event:
push
-
Statement type:
File details
Details for the file stac_optimizer-0.1.5-py3-none-any.whl.
File metadata
- Download URL: stac_optimizer-0.1.5-py3-none-any.whl
- Upload date:
- Size: 10.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
79604230b20313147a43c548482086f1979720b35ba433e4ea2fc7e862ca4f4a
|
|
| MD5 |
4fe38123e2a14fd320d5fda3239080e7
|
|
| BLAKE2b-256 |
b03e4ddab4b821fef8bc670b73123bde72184bab84d5d25033ba07d967ea1723
|
Provenance
The following attestation bundles were made for stac_optimizer-0.1.5-py3-none-any.whl:
Publisher:
workflow.yml on smturtle2/stac-optimizer
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
stac_optimizer-0.1.5-py3-none-any.whl -
Subject digest:
79604230b20313147a43c548482086f1979720b35ba433e4ea2fc7e862ca4f4a - Sigstore transparency entry: 1132622537
- Sigstore integration time:
-
Permalink:
smturtle2/stac-optimizer@3898d7d464f654874d5dc3c5985af158ad912a63 -
Branch / Tag:
refs/tags/v0.1.5 - Owner: https://github.com/smturtle2
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
workflow.yml@3898d7d464f654874d5dc3c5985af158ad912a63 -
Trigger Event:
push
-
Statement type:







