Backtest 1000s of minute-by-minute trading algorithms. Automated pricing data ingestion from: IEX Cloud (https://iexcloud.io), Tradier (https://tradier.com) and FinViz. Datasets and trading performance automatically compressed and published to S3 for building AI training datasets for teaching DNNs how to trade. Runs on Kubernetes with Helm and docker-compose. >150 million trading history rows generated from +5000 algorithms

Project description
Stock Analysis Engine
Build and tune investment algorithms for use with artificial intelligence (deep neural networks) with a distributed stack for running backtests using live pricing data on publicly traded companies with automated datafeeds from: IEX Cloud, Tradier and FinViz (includes: pricing, options, news, dividends, daily, intraday, screeners, statistics, financials, earnings, and more).
Kubernetes users please refer to the Helm guide to get started and Metalnetes for running multiple Analysis Engines at the same time on a bare-metal server
Fetch the Latest Pricing Data
Supported fetch methods for getting pricing data:
Command line using fetch command
Docker-compose using ./compose/start.sh -c
Kubernetes jobs: Fetch Intraday, Fetch Daily, Fetch Weekly, or Fetch from only Tradier
Fetch using the Command Line
Here is a video showing how to fetch the latest pricing data for a ticker using the command line:
Clone to /opt/sa
git clone https://github.com/AlgoTraders/stock-analysis-engine.git /opt/sa cd /opt/sa
Create Docker Mounts and Start Redis and Minio
This will pull Redis and Minio docker images.
./compose/start.sh -a
Fetch All Pricing Data
Fetch pricing data from IEX Cloud (requires an account and uses on-demand usage pricing) and Tradier (requires an account):
Set the IEX_TOKEN environment variable to fetch from the IEX Cloud datafeeds:
export IEX_TOKEN=YOUR_IEX_TOKEN
Set the TD_TOKEN environment variable to fetch from the Tradier datafeeds:
export TD_TOKEN=YOUR_TRADIER_TOKEN
Fetch with:
fetch -t SPY
Fetch only from IEX with -g iex:
fetch -t SPY -g iex # and fetch from just Tradier with: # fetch -t SPY -g td
Fetch previous 30 calendar days of intraday minute pricing data from IEX Cloud
backfill-minute-data.sh TICKER # backfill-minute-data.sh SPY
View the Compressed Pricing Data in Redis
redis-cli keys "SPY_*" redis-cli get "<key like SPY_2019-01-08_minute>"
Run Backtests with the Algorithm Runner API
Run a backtest with the latest pricing data:
import analysis_engine.algo_runner as algo_runner
import analysis_engine.plot_trading_history as plot
runner = algo_runner.AlgoRunner('SPY')
# run the algorithm with the latest 200 minutes:
df = runner.latest()
print(df[['minute', 'close']].tail(5))
plot.plot_trading_history(
title=(
f'SPY - ${df["close"].iloc[-1]} at: '
f'{df["minute"].iloc[-1]}'),
df=df)
# start a full backtest with:
# runner.start()Check out the backtest_with_runner.py script for a command line example of using the Algorithm Runner API to run and plot from an Algorithm backtest config file.
Extract from Redis API
Once fetched, you can extract datasets from the redis cache with:
import analysis_engine.extract as ae_extract
print(ae_extract.extract('SPY'))Extract Latest Minute Pricing for Stocks and Options
import analysis_engine.extract as ae_extract
print(ae_extract.extract(
'SPY',
datasets=['minute', 'tdcalls', 'tdputs']))Extract Historical Data
Extract historical data with the date argument formatted YYYY-MM-DD:
import analysis_engine.extract as ae_extract
print(ae_extract.extract(
'AAPL',
datasets=['minute', 'daily', 'financials', 'earnings', 'dividends'],
date='2019-02-15'))Additional Extraction APIs
Backups
Pricing data is automatically compressed in redis and there is an example Kubernetes job for backing up all stored pricing data to AWS S3.
Running the Full Stack Locally for Backtesting and Live Trading Analysis
While not required for backtesting, running the full stack is required for running algorithms during a live trading session. Here is a video on how to deploy the full stack locally using docker compose and the commands from the video.
Start Workers, Backtester, Pricing Data Collection, Jupyter, Redis and Minio
Now start the rest of the stack with the command below. This will pull the ~3.0 GB stock-analysis-engine docker image and start the workers, backtester, dataset collection and Jupyter image. It will start Redis and Minio if they are not running already.
./compose/start.sh
Check the Docker Containers
docker ps -a
View for dataset collection logs
logs-dataset-collection.sh
Wait for pricing engine logs to stop with ctrl+c
logs-workers.sh
Verify Pricing Data is in Redis
redis-cli keys "*"
Optional - Automating pricing data collection with the automation-dataset-collection.yml docker compose file:
./compose/start.sh -c
Run a Custom Minute-by-Minute Intraday Algorithm Backtest and Plot the Trading History
With pricing data in redis, you can start running backtests a few ways:
Running an Algorithm with Live Intraday Pricing Data
Here is a video showing how to run it:
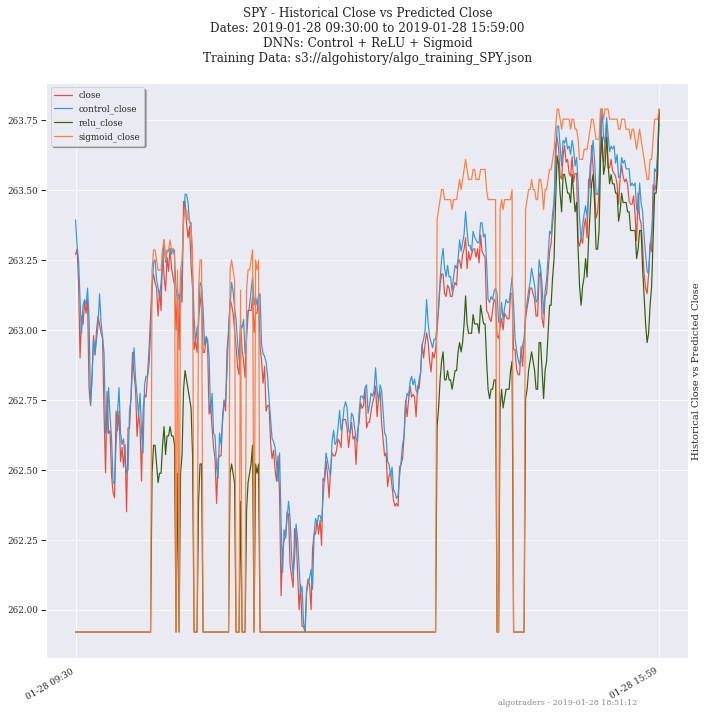
The backtest command line tool uses an algorithm config dictionary to build multiple Williams %R indicators into an algorithm with a 10,000.00 USD starting balance. Once configured, the backtest iterates through each trading dataset and evaluates if it should buy or sell based off the pricing data. After it finishes, the tool will display a chart showing the algorithm’s balance and the stock’s close price per minute using matplotlib and seaborn.
# this can take a few minutes to evaluate # as more data is collected # because each day has 390 rows to process bt -t SPY -f /tmp/history.json
View the Minute Algorithm’s Trading History from a File
Once the trading history is saved to disk, you can open it back up and plot other columns within the dataset with:
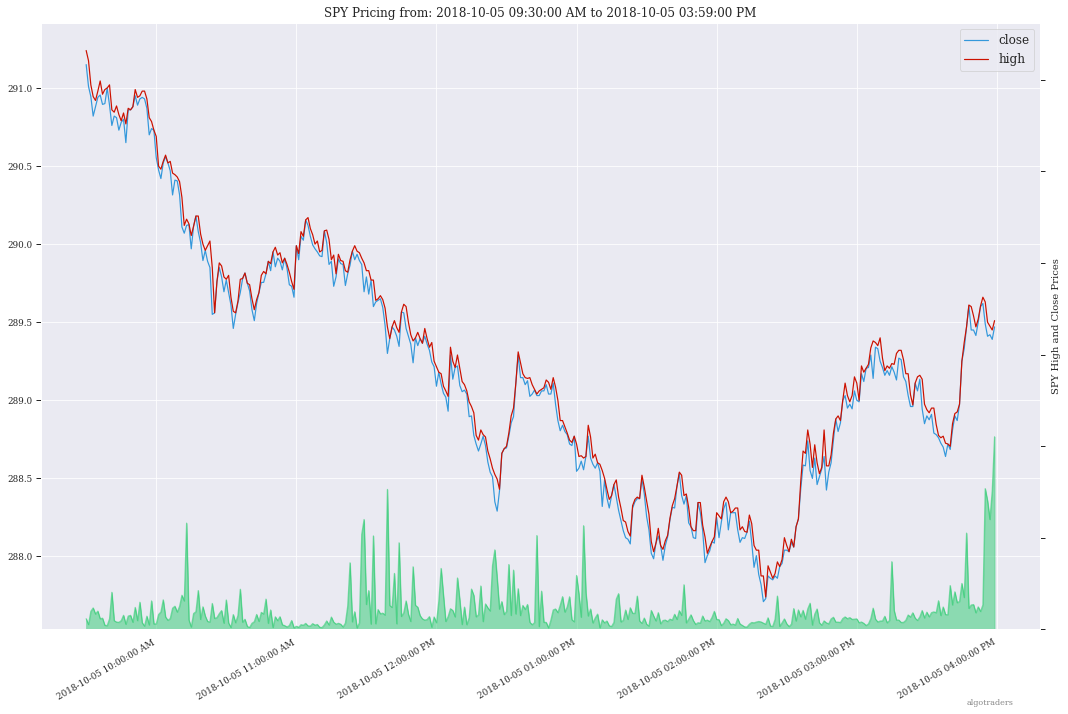
# by default the plot shows # balance vs close per minute plot-history -f /tmp/history.json
Run a Custom Algorithm and Save the Trading History with just Today’s Pricing Data
Here’s how to run an algorithm during a live trading session. This approach assumes another process or cron is fetch-ing the pricing data using the engine so the algorithm(s) have access to the latest pricing data:
bt -t SPY -f /tmp/SPY-history-$(date +"%Y-%m-%d").json -j $(date +"%Y-%m-%d")
Run a Backtest using an External Algorithm Module and Config File
Run an algorithm backtest with a standalone algorithm class contained in a single python module file that can even be outside the repository using a config file on disk:
ticker=SPY
config=<CUSTOM_ALGO_CONFIG_DIR>/minute_algo.json
algo_mod=<CUSTOM_ALGO_MODULE_DIR>/minute_algo.py
bt -t ${ticker} -c ${algo_config} -g ${algo_mod}
Or the config can use "algo_path": "<PATH_TO_FILE>" to set the path to an external algorithm module file.
bt -t ${ticker} -c ${algo_config}
Building Your Own Trading Algorithms
Beyond running backtests, the included engine supports running many algorithms and fetching data for both live trading or backtesting all at the same time. As you start to use this approach, you will be generating lots of algorithm pricing datasets, history datasets and coming soon performance datasets for AI training. Because algorithm’s utilize the same dataset structure, you can share ready-to-go datasets with a team and publish them to S3 for kicking off backtests using lambda functions or just archival for disaster recovery.
The next section looks at how to build an algorithm-ready datasets from cached pricing data in redis.
Run a Local Backtest and Publish Algorithm Trading History to S3
ae -t SPY -p s3://algohistory/algo_training_SPY.json
Run distributed across the engine workers with -w
ae -w -t SPY -p s3://algohistory/algo_training_SPY.json
Run a Local Backtest using an Algorithm Config and Extract an Algorithm-Ready Dataset
Use this command to start a local backtest with the included algorithm config. This backtest will also generate a local algorithm-ready dataset saved to a file once it finishes.
Define common values
ticker=SPY algo_config=tests/algo_configs/test_5_days_ahead.json extract_loc=file:/tmp/algoready-SPY-latest.json history_loc=file:/tmp/history-SPY-latest.json load_loc=${extract_loc}
Run Algo with Extraction and History Publishing
run-algo-history-to-file.sh -t ${ticker} -c ${algo_config} -e ${extract_loc} -p ${history_loc}
Profile Your Algorithm’s Code Performance with vprof
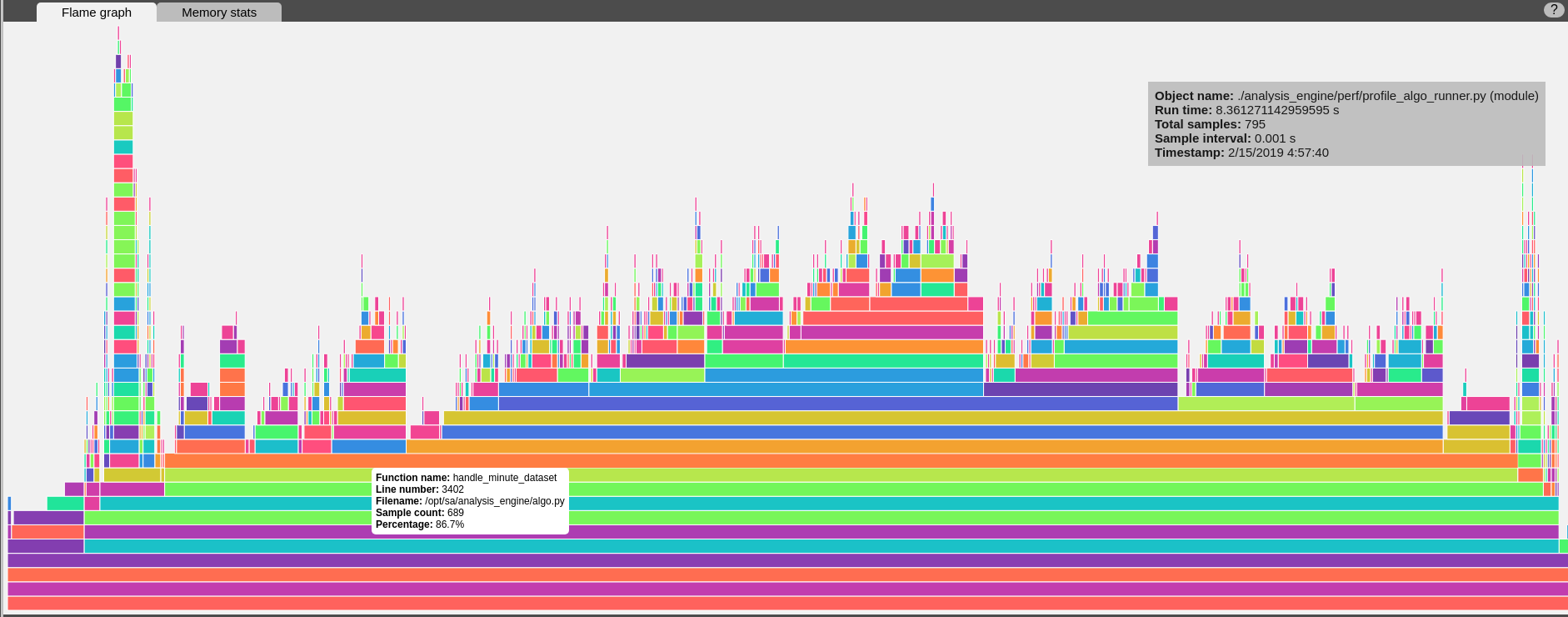
The pip includes vprof for profiling an algorithm’s performance (cpu, memory, profiler and heat map - not money-related) which was used to generate the cpu flame graph seen above.
Profile your algorithm’s code performance with the following steps:
Start vprof in remote mode in a first terminal
vprof -r -p 3434
Start Profiler in a second terminal
vprof -c cm ./analysis_engine/perf/profile_algo_runner.py
Run a Local Backtest using an Algorithm Config and an Algorithm-Ready Dataset
After generating the local algorithm-ready dataset (which can take some time), use this command to run another backtest using the file on disk:
dev_history_loc=file:/tmp/dev-history-${ticker}-latest.json
run-algo-history-to-file.sh -t ${ticker} -c ${algo_config} -l ${load_loc} -p ${dev_history_loc}
View Buy and Sell Transactions
run-algo-history-to-file.sh -t ${ticker} -c ${algo_config} -l ${load_loc} -p ${dev_history_loc} | grep "TRADE"
Plot Trading History Tools
Plot Timeseries Trading History with High + Low + Open + Close
sa -t SPY -H ${dev_history_loc}
Run and Publish Trading Performance Report for a Custom Algorithm
This will run a backtest over the past 60 days in order and run the standalone algorithm as a class example. Once done it will publish the trading performance report to a file or minio (s3).
Write the Trading Performance Report to a Local File
run-algo-report-to-file.sh -t SPY -b 60 -a /opt/sa/analysis_engine/mocks/example_algo_minute.py # run-algo-report-to-file.sh -t <TICKER> -b <NUM_DAYS_BACK> -a <CUSTOM_ALGO_MODULE> # run on specific date ranges with: # -s <start date YYYY-MM-DD> -n <end date YYYY-MM-DD>
Write the Trading Performance Report to Minio (s3)
run-algo-report-to-s3.sh -t SPY -b 60 -a /opt/sa/analysis_engine/mocks/example_algo_minute.py
Run and Publish Trading History for a Custom Algorithm
This will run a full backtest across the past 60 days in order and run the example algorithm. Once done it will publish the trading history to a file or minio (s3).
Write the Trading History to a Local File
run-algo-history-to-file.sh -t SPY -b 60 -a /opt/sa/analysis_engine/mocks/example_algo_minute.py
Write the Trading History to Minio (s3)
run-algo-history-to-s3.sh -t SPY -b 60 -a /opt/sa/analysis_engine/mocks/example_algo_minute.py
Developing on AWS
If you are comfortable with AWS S3 usage charges, then you can run just with a redis server to develop and tune algorithms. This works for teams and for archiving datasets for disaster recovery.
Environment Variables
Export these based off your AWS IAM credentials and S3 endpoint.
export AWS_ACCESS_KEY_ID="ACCESS" export AWS_SECRET_ACCESS_KEY="SECRET" export S3_ADDRESS=s3.us-east-1.amazonaws.com
Extract and Publish to AWS S3
./tools/backup-datasets-on-s3.sh -t TICKER -q YOUR_BUCKET -k ${S3_ADDRESS} -r localhost:6379
Publish to Custom AWS S3 Bucket and Key
extract_loc=s3://YOUR_BUCKET/TICKER-latest.json
./tools/backup-datasets-on-s3.sh -t TICKER -e ${extract_loc} -r localhost:6379
Backtest a Custom Algorithm with a Dataset on AWS S3
backtest_loc=s3://YOUR_BUCKET/TICKER-latest.json
custom_algo_module=/opt/sa/analysis_engine/mocks/example_algo_minute.py
sa -t TICKER -a ${S3_ADDRESS} -r localhost:6379 -b ${backtest_loc} -g ${custom_algo_module}
Fetching New Pricing Tradier Every Minute with Kubernetes
If you want to fetch and append new option pricing data from Tradier, you can use the included kubernetes job with a cron to pull new data every minute:
kubectl -f apply /opt/sa/k8/datasets/pull_tradier_per_minute.yml
Run a Distributed 60-day Backtest on SPY and Publish the Trading Report, Trading History and Algorithm-Ready Dataset to S3
Publish backtests and live trading algorithms to the engine’s workers for running many algorithms at the same time. Once done, the algorithm will publish results to s3, redis or a local file. By default, the included example below publishes all datasets into minio (s3) where they can be downloaded for offline backtests or restored back into redis.
num_days_back=60
./tools/run-algo-with-publishing.sh -t SPY -b ${num_days_back} -w
Run a Local 60-day Backtest on SPY and Publish Trading Report, Trading History and Algorithm-Ready Dataset to S3
num_days_back=60
./tools/run-algo-with-publishing.sh -t SPY -b ${num_days_back}
Or manually with:
ticker=SPY
num_days_back=60
use_date=$(date +"%Y-%m-%d")
ds_id=$(uuidgen | sed -e 's/-//g')
ticker_dataset="${ticker}-${use_date}_${ds_id}.json"
echo "creating ${ticker} dataset: ${ticker_dataset}"
extract_loc="s3://algoready/${ticker_dataset}"
history_loc="s3://algohistory/${ticker_dataset}"
report_loc="s3://algoreport/${ticker_dataset}"
backtest_loc="s3://algoready/${ticker_dataset}" # same as the extract_loc
processed_loc="s3://algoprocessed/${ticker_dataset}" # archive it when done
start_date=$(date --date="${num_days_back} day ago" +"%Y-%m-%d")
echo ""
echo "extracting algorithm-ready dataset: ${extract_loc}"
echo "sa -t SPY -e ${extract_loc} -s ${start_date} -n ${use_date}"
sa -t SPY -e ${extract_loc} -s ${start_date} -n ${use_date}
echo ""
echo "running algo with: ${backtest_loc}"
echo "sa -t SPY -p ${history_loc} -o ${report_loc} -b ${backtest_loc} -e ${processed_loc} -s ${start_date} -n ${use_date}"
sa -t SPY -p ${history_loc} -o ${report_loc} -b ${backtest_loc} -e ${processed_loc} -s ${start_date} -n ${use_date}
Jupyter on Kubernetes
This command runs Jupyter on an AntiNex Kubernetes cluster
./k8/jupyter/run.sh ceph dev
Kubernetes - Analyze and Tune Algorithms from a Trading History
With the Analysis Engine’s Jupyter instance deployed you can tune algorithms from a trading history using this notebook.
Kubernetes Job - Export SPY Datasets and Publish to Minio
Manually run with an ssh-eng alias:
function ssheng() {
pod_name=$(kubectl get po | grep ae-engine | grep Running |tail -1 | awk '{print $1}')
echo "logging into ${pod_name}"
kubectl exec -it ${pod_name} bash
}
ssheng
# once inside the container on kubernetes
source /opt/venv/bin/activate
sa -a minio-service:9000 -r redis-master:6379 -e s3://backups/SPY-$(date +"%Y-%m-%d") -t SPY
View Algorithm-Ready Datasets
With the AWS cli configured you can view available algorithm-ready datasets in your minio (s3) bucket with the command:
aws --endpoint-url http://localhost:9000 s3 ls s3://algoready
View Trading History Datasets
With the AWS cli configured you can view available trading history datasets in your minio (s3) bucket with the command:
aws --endpoint-url http://localhost:9000 s3 ls s3://algohistory
View Trading History Datasets
With the AWS cli configured you can view available trading performance report datasets in your minio (s3) bucket with the command:
aws --endpoint-url http://localhost:9000 s3 ls s3://algoreport
Advanced - Running Algorithm Backtests Offline
With extracted Algorithm-Ready datasets in minio (s3), redis or a file you can develop and tune your own algorithms offline without having redis, minio, the analysis engine, or jupyter running locally.
Run a Offline Custom Algorithm Backtest with an Algorithm-Ready File
# extract with: sa -t SPY -e file:/tmp/SPY-latest.json sa -t SPY -b file:/tmp/SPY-latest.json -g /opt/sa/analysis_engine/mocks/example_algo_minute.py
Run the Intraday Minute-by-Minute Algorithm and Publish the Algorithm-Ready Dataset to S3
Run the included standalone algorithm with the latest pricing datasets use:
sa -t SPY -g /opt/sa/analysis_engine/mocks/example_algo_minute.py -e s3://algoready/SPY-$(date +"%Y-%m-%d").json
And to debug an algorithm’s historical trading performance add the -d debug flag:
sa -d -t SPY -g /opt/sa/analysis_engine/mocks/example_algo_minute.py -e s3://algoready/SPY-$(date +"%Y-%m-%d").json
Extract Algorithm-Ready Datasets
With pricing data cached in redis, you can extract algorithm-ready datasets and save them to a local file for offline historical backtesting analysis. This also serves as a local backup where all cached data for a single ticker is in a single local file.
Extract an Algorithm-Ready Dataset from Redis and Save it to a File
sa -t SPY -e ~/SPY-latest.json
Create a Daily Backup
sa -t SPY -e ~/SPY-$(date +"%Y-%m-%d").json
Validate the Daily Backup by Examining the Dataset File
sa -t SPY -l ~/SPY-$(date +"%Y-%m-%d").json
Validate the Daily Backup by Examining the Dataset File
sa -t SPY -l ~/SPY-$(date +"%Y-%m-%d").json
Restore Backup to Redis
Use this command to cache missing pricing datasets so algorithms have the correct data ready-to-go before making buy and sell predictions.
sa -t SPY -L ~/SPY-$(date +"%Y-%m-%d").json
Fetch
With redis and minio running (./compose/start.sh), you can fetch, cache, archive and return all of the newest datasets for tickers:
from analysis_engine.fetch import fetch
d = fetch(ticker='SPY')
for k in d['SPY']:
print(f'dataset key: {k}\nvalue {d["SPY"][k]}\n')Backfill Historical Minute Data from IEX Cloud
fetch -t TICKER -F PAST_DATE -g iex_min # example: # fetch -t SPY -F 2019-02-07 -g iex_min
Please refer to the Stock Analysis Intro Extracting Datasets Jupyter Notebook for the latest usage examples.

|
Getting Started
This section outlines how to get the Stock Analysis stack running locally with:
Redis
Minio (S3)
Stock Analysis engine
Jupyter
For background, the stack provides a data pipeline that automatically archives pricing data in minio (s3) and caches pricing data in redis. Once cached or archived, custom algorithms can use the pricing information to determine buy or sell conditions and track internal trading performance across historical backtests.
From a technical perspective, the engine uses Celery workers to process heavyweight, asynchronous tasks and scales horizontally with support for many transports and backends depending on where you need to run it. The stack deploys with Kubernetes or docker compose and supports publishing trading alerts to Slack.
With the stack already running, please refer to the Intro Stock Analysis using Jupyter Notebook for more getting started examples.
Setting up Your Tradier Account with Docker Compose
Please set your Tradier account token in the docker environment files before starting the stack:
grep -r SETYOURTRADIERTOKENHERE compose/* compose/envs/backtester.env:TD_TOKEN=SETYOURTRADIERTOKENHERE compose/envs/workers.env:TD_TOKEN=SETYOURTRADIERTOKENHER
Please export the variable for developing locally:
export TD_TOKEN=<TRADIER_ACCOUNT_TOKEN>
Start Redis and Minio
./compose/start.sh
Verify Redis and Minio are Running
docker ps | grep -E "redis|minio"
Running on Ubuntu and CentOS
Install Packages
Ubuntu
sudo apt-get install make cmake gcc python3-distutils python3-tk python3 python3-apport python3-certifi python3-dev python3-pip python3-venv python3.6 redis-tools virtualenv libcurl4-openssl-dev libssl-dev
CentOS 7
sudo yum install cmake gcc gcc-c++ make tkinter curl-devel make cmake python-devel python-setuptools python-pip python-virtualenv redis python36u-libs python36u-devel python36u-pip python36u-tkinter python36u-setuptools python36u openssl-devel
Install TA-Lib
Follow the TA-Lib install guide or use the included install tool as root:
sudo su /opt/sa/tools/linux-install-talib.sh exit
Create and Load Python 3 Virtual Environment
virtualenv -p python3 /opt/venv source /opt/venv/bin/activate pip install --upgrade pip setuptools
Install Analysis Pip
pip install -e .
Verify Pip installed
pip list | grep stock-analysis-engine
Running on Mac OS X
Download Python 3.6
Install Packages
brew install openssl pyenv-virtualenv redis freetype pkg-config gcc ta-lib
Create and Load Python 3 Virtual Environment
python3 -m venv /opt/venv source /opt/venv/bin/activate pip install --upgrade pip setuptools
Install Certs
After hitting ssl verify errors, I found this stack overflow which shows there’s an additional step for setting up python 3.6:
/Applications/Python\ 3.6/Install\ Certificates.command
Install PyCurl with OpenSSL
PYCURL_SSL_LIBRARY=openssl LDFLAGS="-L/usr/local/opt/openssl/lib" CPPFLAGS="-I/usr/local/opt/openssl/include" pip install --no-cache-dir pycurl
Install Analysis Pip
pip install --upgrade pip setuptools pip install -e .
Verify Pip installed
pip list | grep stock-analysis-engine
Start Workers
./start-workers.sh
Get and Publish Pricing data
Please refer to the lastest API docs in the repo:
https://github.com/AlgoTraders/stock-analysis-engine/blob/master/analysis_engine/api_requests.py
Fetch New Stock Datasets
Run the ticker analysis using the ./analysis_engine/scripts/fetch_new_stock_datasets.py:
Collect all datasets for a Ticker or Symbol
Collect all datasets for the ticker SPY:
fetch -t SPY
View the Engine Worker Logs
docker logs ae-workers
Running Inside Docker Containers
If you are using an engine that is running inside a docker container, then localhost is probably not the correct network hostname for finding redis and minio.
Please set these values as needed to publish and archive the dataset artifacts if you are using the integration or notebook integration docker compose files for deploying the analysis engine stack:
fetch -t SPY -a 0.0.0.0:9000 -r 0.0.0.0:6379
Detailed Usage Example
The fetch_new_stock_datasets.py script supports many parameters. Here is how to set it up if you have custom redis and minio deployments like on kubernetes as minio-service:9000 and redis-master:6379:
S3 authentication (-k and -s)
S3 endpoint (-a)
Redis endoint (-r)
Custom S3 Key and Redis Key Name (-n)
fetch -t SPY -g all -u pricing -k trexaccesskey -s trex123321 -a localhost:9000 -r localhost:6379 -m 0 -n SPY_demo -P 1 -N 1 -O 1 -U 1 -R 1
Usage
Please refer to the fetch_new_stock_datasets.py script for the latest supported usage if some of these are out of date:
fetch -h
2019-02-11 01:55:33,791 - fetch - INFO - start - fetch_new_stock_datasets
usage: fetch_new_stock_datasets.py [-h] [-t TICKER] [-g FETCH_MODE]
[-i TICKER_ID] [-e EXP_DATE_STR]
[-l LOG_CONFIG_PATH] [-b BROKER_URL]
[-B BACKEND_URL] [-k S3_ACCESS_KEY]
[-s S3_SECRET_KEY] [-a S3_ADDRESS]
[-S S3_SECURE] [-u S3_BUCKET_NAME]
[-G S3_REGION_NAME] [-p REDIS_PASSWORD]
[-r REDIS_ADDRESS] [-n KEYNAME]
[-m REDIS_DB] [-x REDIS_EXPIRE] [-z STRIKE]
[-c CONTRACT_TYPE] [-P GET_PRICING]
[-N GET_NEWS] [-O GET_OPTIONS]
[-U S3_ENABLED] [-R REDIS_ENABLED]
[-A ANALYSIS_TYPE] [-L URLS] [-Z] [-d]
Download and store the latest stock pricing, news, and options chain data and
store it in Minio (S3) and Redis. Also includes support for getting FinViz
screener tickers
optional arguments:
-h, --help show this help message and exit
-t TICKER ticker
-g FETCH_MODE optional - fetch mode: initial = default fetch from
initial data feeds (IEX and Tradier), intra = fetch
intraday from IEX and Tradier, daily = fetch daily from
IEX, weekly = fetch weekly from IEX, all = fetch from
all data feeds, td = fetch from Tradier feeds only, iex
= fetch from IEX Cloud feeds only, iex_min = fetch IEX
Cloud intraday per-minute feed
https://iexcloud.io/docs/api/#historical-prices iex_day
= fetch IEX Cloud daily feed
https://iexcloud.io/docs/api/#historical-prices
iex_quote = fetch IEX Cloud quotes feed
https://iexcloud.io/docs/api/#quote iex_stats = fetch
IEX Cloud key stats feed
https://iexcloud.io/docs/api/#key-stats iex_peers =
fetch from just IEX Cloud peers feed
https://iexcloud.io/docs/api/#peers iex_news = fetch IEX
Cloud news feed https://iexcloud.io/docs/api/#news
iex_fin = fetch IEX Cloud financials
feedhttps://iexcloud.io/docs/api/#financials iex_earn =
fetch from just IEX Cloud earnings feeed
https://iexcloud.io/docs/api/#earnings iex_div = fetch
from just IEX Cloud dividends
feedhttps://iexcloud.io/docs/api/#dividends iex_comp =
fetch from just IEX Cloud company feed
https://iexcloud.io/docs/api/#company
-i TICKER_ID optional - ticker id not used without a database
-e EXP_DATE_STR optional - options expiration date
-l LOG_CONFIG_PATH optional - path to the log config file
-b BROKER_URL optional - broker url for Celery
-B BACKEND_URL optional - backend url for Celery
-k S3_ACCESS_KEY optional - s3 access key
-s S3_SECRET_KEY optional - s3 secret key
-a S3_ADDRESS optional - s3 address format: <host:port>
-S S3_SECURE optional - s3 ssl or not
-u S3_BUCKET_NAME optional - s3 bucket name
-G S3_REGION_NAME optional - s3 region name
-p REDIS_PASSWORD optional - redis_password
-r REDIS_ADDRESS optional - redis_address format: <host:port>
-n KEYNAME optional - redis and s3 key name
-m REDIS_DB optional - redis database number (0 by default)
-x REDIS_EXPIRE optional - redis expiration in seconds
-z STRIKE optional - strike price
-c CONTRACT_TYPE optional - contract type "C" for calls "P" for puts
-P GET_PRICING optional - get pricing data if "1" or "0" disabled
-N GET_NEWS optional - get news data if "1" or "0" disabled
-O GET_OPTIONS optional - get options data if "1" or "0" disabled
-U S3_ENABLED optional - s3 enabled for publishing if "1" or "0" is
disabled
-R REDIS_ENABLED optional - redis enabled for publishing if "1" or "0" is
disabled
-A ANALYSIS_TYPE optional - run an analysis supported modes: scn
-L URLS optional - screener urls to pull tickers for analysis
-Z disable run without an engine for local testing and
demos
-d debug
Run FinViz Screener-driven Analysis
This is a work in progress, but the screener-driven workflow is:
Convert FinViz screeners into a list of tickers and a pandas.DataFrames from each ticker’s html row
Build unique list of tickers
Pull datasets for each ticker
Run sale-side processing - coming soon
Run buy-side processing - coming soon
Issue alerts to slack - coming soon
Here is how to run an analysis on all unique tickers found in two FinViz screener urls:
https://finviz.com/screener.ashx?v=111&f=cap_midunder,exch_nyse,fa_div_o6,idx_sp500&ft=4 and https://finviz.com/screener.ashx?v=111&f=cap_midunder,exch_nyse,fa_div_o8,idx_sp500&ft=4
fetch -A scn -L 'https://finviz.com/screener.ashx?v=111&f=cap_midunder,exch_nyse,fa_div_o6,idx_sp500&ft=4|https://finviz.com/screener.ashx?v=111&f=cap_midunder,exch_nyse,fa_div_o8,idx_sp500&ft=4'
Run Publish from an Existing S3 Key to Redis
Upload Integration Test Key to S3
export INT_TESTS=1 python -m unittest tests.test_publish_pricing_update.TestPublishPricingData.test_integration_s3_upload
Confirm the Integration Test Key is in S3
Run an analysis with an existing S3 key using ./analysis_engine/scripts/publish_from_s3_to_redis.py
publish_from_s3_to_redis.py -t SPY -u integration-tests -k trexaccesskey -s trex123321 -a localhost:9000 -r localhost:6379 -m 0 -n integration-test-v1
Confirm the Key is now in Redis
./tools/redis-cli.sh 127.0.0.1:6379> keys * keys * 1) "SPY_demo_daily" 2) "SPY_demo_minute" 3) "SPY_demo_company" 4) "integration-test-v1" 5) "SPY_demo_stats" 6) "SPY_demo" 7) "SPY_demo_quote" 8) "SPY_demo_peers" 9) "SPY_demo_dividends" 10) "SPY_demo_news1" 11) "SPY_demo_news" 12) "SPY_demo_options" 13) "SPY_demo_pricing" 127.0.0.1:6379>
Run Aggregate and then Publish data for a Ticker from S3 to Redis
Run an analysis with an existing S3 key using ./analysis_engine/scripts/publish_ticker_aggregate_from_s3.py
publish_ticker_aggregate_from_s3.py -t SPY -k trexaccesskey -s trex123321 -a localhost:9000 -r localhost:6379 -m 0 -u pricing -c compileddatasets
Confirm the aggregated Ticker is now in Redis
./tools/redis-cli.sh 127.0.0.1:6379> keys *latest* 1) "SPY_latest" 127.0.0.1:6379>
View Archives in S3 - Minio
Here’s a screenshot showing the stock market dataset archives created while running on the 3-node Kubernetes cluster for distributed AI predictions
http://localhost:9000/minio/pricing/
Login
username: trexaccesskey
password: trex123321
Using the AWS CLI to List the Pricing Bucket
Please refer to the official steps for using the awscli pip with minio:
https://docs.minio.io/docs/aws-cli-with-minio.html
Export Credentials
export AWS_SECRET_ACCESS_KEY=trex123321 export AWS_ACCESS_KEY_ID=trexaccesskey
List Buckets
aws --endpoint-url http://localhost:9000 s3 ls 2018-10-02 22:24:06 company 2018-10-02 22:24:02 daily 2018-10-02 22:24:06 dividends 2018-10-02 22:33:15 integration-tests 2018-10-02 22:24:03 minute 2018-10-02 22:24:05 news 2018-10-02 22:24:04 peers 2018-10-02 22:24:06 pricing 2018-10-02 22:24:04 stats 2018-10-02 22:24:04 quote
List Pricing Bucket Contents
aws --endpoint-url http://localhost:9000 s3 ls s3://pricing
Get the Latest SPY Pricing Key
aws --endpoint-url http://localhost:9000 s3 ls s3://pricing | grep -i spy_demo SPY_demo
View Caches in Redis
./tools/redis-cli.sh 127.0.0.1:6379> keys * 1) "SPY_demo"
Jupyter
You can run the Jupyter notebooks by starting the notebook-integration.yml stack with the command:
For Linux users, the Jupyter container hosts the Stock Analysis Intro notebook at the url (default login password is admin):
Jupyter Presentations with RISE
The docker container comes with RISE installed for running notebook presentations from a browser. Here’s the button on the notebook for starting the web presentation:
Distributed Automation with Docker
Dataset Collection
Start automated dataset collection with docker compose:
./compose/start.sh -c
Datasets in Redis
After running the dataset collection container, the datasets should be auto-cached in Minio (http://localhost:9000/minio/pricing/) and Redis:
./tools/redis-cli.sh 127.0.0.1:6379> keys *
Publishing to Slack
Please refer to the Publish Stock Alerts to Slack Jupyter Notebook for the latest usage examples.
Publish FinViz Screener Tickers to Slack
Here is sample code for trying out the Slack integration.
import analysis_engine.finviz.fetch_api as fv
from analysis_engine.send_to_slack import post_df
# simple NYSE Dow Jones Index Financials with a P/E above 5 screener url
url = 'https://finviz.com/screener.ashx?v=111&f=exch_nyse,fa_pe_o5,idx_dji,sec_financial&ft=4'
res = fv.fetch_tickers_from_screener(url=url)
df = res['rec']['data']
# please make sure the SLACK_WEBHOOK environment variable is set correctly:
post_df(
df=df[SLACK_FINVIZ_COLUMNS],
columns=SLACK_FINVIZ_COLUMNS)Running on Kubernetes
Kubernetes Deployments - Engine
Deploy the engine with:
kubectl apply -f ./k8/engine/deployment.yml
Kubernetes Job - Dataset Collection
Start the dataset collection job with:
kubectl apply -f ./k8/datasets/job.yml
Kubernetes Deployments - Jupyter
Deploy Jupyter to a Kubernetes cluster with:
./k8/jupyter/run.sh
Kubernetes with a Private Docker Registry
You can deploy a private docker registry that can be used to pull images from outside a kubernetes cluster with the following steps:
Deploy Docker Registry
./compose/start.sh -r
Configure Kubernetes hosts and other docker daemons for insecure registries
cat /etc/docker/daemon.json { "insecure-registries": [ "<public ip address/fqdn for host running the registry container>:5000" ] }Restart all Docker daemons
sudo systemctl restart docker
Login to Docker Registry from all Kubernetes hosts and other daemons that need access to the registry
docker login <public ip address/fqdn for host running the registry container>:5000
Setup Kubernetes Secrets for All Credentials
Set each of the fields according to your own buckets, docker registry and Tradier account token:
cat /opt/sa/k8/secrets/secrets.yml | grep SETYOUR aws_access_key_id: SETYOURENCODEDAWSACCESSKEYID aws_secret_access_key: SETYOURENCODEDAWSSECRETACCESSKEY .dockerconfigjson: SETYOURDOCKERCREDS td_token: SETYOURTDTOKEN
Deploy Kubernetes Secrets
kubectl apply -f /opt/sa/k8/secrets/secrets.yml
Confirm Kubernetes Secrets are Deployed
kubectl get secrets ae.docker.creds NAME TYPE DATA AGE ae.docker.creds kubernetes.io/dockerconfigjson 1 4d1h
kubectl get secrets | grep "ae\." ae.docker.creds kubernetes.io/dockerconfigjson 1 4d1h ae.k8.aws.s3 Opaque 3 4d1h ae.k8.minio.s3 Opaque 3 4d1h ae.k8.tradier Opaque 4 4d1h
Configure Kubernetes Deployments for using an External Private Docker Registry
Add these lines to a Kubernetes deployment yaml file based off your set up:
imagePullSecrets: - name: ae.docker.creds containers: - image: <public ip address/fqdn for host running the registry container>:5000/my-own-stock-ae:latest imagePullPolicy: Always
Testing
To show debug, trace logging please export SHARED_LOG_CFG to a debug logger json file. To turn on debugging for this library, you can export this variable to the repo’s included file with the command:
export SHARED_LOG_CFG=/opt/sa/analysis_engine/log/debug-logging.json
Run all
py.test --maxfail=1
Run a test case
python -m unittest tests.test_publish_pricing_update.TestPublishPricingData.test_success_publish_pricing_data
Test Publishing
S3 Upload
python -m unittest tests.test_publish_pricing_update.TestPublishPricingData.test_success_s3_upload
Publish from S3 to Redis
python -m unittest tests.test_publish_from_s3_to_redis.TestPublishFromS3ToRedis.test_success_publish_from_s3_to_redis
Redis Cache Set
python -m unittest tests.test_publish_pricing_update.TestPublishPricingData.test_success_redis_set
Prepare Dataset
python -m unittest tests.test_prepare_pricing_dataset.TestPreparePricingDataset.test_prepare_pricing_data_success
Test Algo Saving All Input Datasets to File
python -m unittest tests.test_base_algo.TestBaseAlgo.test_algo_can_save_all_input_datasets_to_file
End-to-End Integration Testing
Start all the containers for full end-to-end integration testing with real docker containers with the script:
./compose/start.sh -a
Verify Containers are running:
docker ps | grep -E "stock-analysis|redis|minio"
Stop End-to-End Stack:
./compose/stop.sh ./compose/stop.sh -s
Integration UnitTests
Please enable integration tests
export INT_TESTS=1
Redis
python -m unittest tests.test_publish_pricing_update.TestPublishPricingData.test_integration_redis_set
S3 Upload
python -m unittest tests.test_publish_pricing_update.TestPublishPricingData.test_integration_s3_upload
Publish from S3 to Redis
python -m unittest tests.test_publish_from_s3_to_redis.TestPublishFromS3ToRedis.test_integration_publish_from_s3_to_redis
IEX Test - Fetching All Datasets
python -m unittest tests.test_iex_fetch_data
IEX Test - Fetch Daily
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_fetch_daily
IEX Test - Fetch Minute
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_fetch_minute
IEX Test - Fetch Stats
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_fetch_stats
IEX Test - Fetch Peers
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_fetch_peers
IEX Test - Fetch News
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_fetch_news
IEX Test - Fetch Financials
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_fetch_financials
IEX Test - Fetch Earnings
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_fetch_earnings
IEX Test - Fetch Dividends
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_fetch_dividends
IEX Test - Fetch Company
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_fetch_company
IEX Test - Fetch Financials Helper
python -m unittest tests.test_iex_fetch_data.TestIEXFetchData.test_integration_get_financials_helper
IEX Test - Extract Daily Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_daily_dataset
IEX Test - Extract Minute Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_minute_dataset
IEX Test - Extract Quote Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_quote_dataset
IEX Test - Extract Stats Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_stats_dataset
IEX Test - Extract Peers Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_peers_dataset
IEX Test - Extract News Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_news_dataset
IEX Test - Extract Financials Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_financials_dataset
IEX Test - Extract Earnings Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_earnings_dataset
IEX Test - Extract Dividends Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_dividends_dataset
IEX Test - Extract Company Dataset
python -m unittest tests.test_iex_dataset_extraction.TestIEXDatasetExtraction.test_integration_extract_company_dataset
FinViz Test - Fetch Tickers from Screener URL
python -m unittest tests.test_finviz_fetch_api.TestFinVizFetchAPI.test_integration_test_fetch_tickers_from_screener
or with code:
import analysis_engine.finviz.fetch_api as fv
url = 'https://finviz.com/screener.ashx?v=111&f=exch_nyse&ft=4&r=41'
res = fv.fetch_tickers_from_screener(url=url)
print(res)Algorithm Testing
Algorithm Test - Input Dataset Publishing to Redis
python -m unittest tests.test_base_algo.TestBaseAlgo.test_integration_algo_publish_input_dataset_to_redis
Algorithm Test - Input Dataset Publishing to File
python -m unittest tests.test_base_algo.TestBaseAlgo.test_integration_algo_publish_input_dataset_to_file
Algorithm Test - Load Dataset From a File
python -m unittest tests.test_base_algo.TestBaseAlgo.test_integration_algo_load_from_file
Algorithm Test - Publish Algorithm-Ready Dataset to S3 and Load from S3
python -m unittest tests.test_base_algo.TestBaseAlgo.test_integration_algo_publish_input_s3_and_load
Algorithm Test - Publish Algorithm-Ready Dataset to S3 and Load from S3
python -m unittest tests.test_base_algo.TestBaseAlgo.test_integration_algo_publish_input_redis_and_load
Algorithm Test - Extract Algorithm-Ready Dataset from Redis DB 0 and Load into Redis DB 1
Copying datasets between redis databases is part of the integration tests. Run it with:
python -m unittest tests.test_base_algo.TestBaseAlgo.test_integration_algo_restore_ready_back_to_redis
Algorithm Test - Test the Docs Example
python -m unittest tests.test_base_algo.TestBaseAlgo.test_sample_algo_code_in_docstring
Prepare a Dataset
ticker=SPY
sa -t ${ticker} -f -o ${ticker}_latest_v1 -j prepared -u pricing -k trexaccesskey -s trex123321 -a localhost:9000 -r localhost:6379 -m 0 -n ${ticker}_demo
Debugging
Test Algos
The fastest way to run algos is to specify a 1-day range:
sa -t SPY -s $(date +"%Y-%m-%d) -n $(date +"%Y-%m-%d")
Test Tasks
Most of the scripts support running without Celery workers. To run without workers in a synchronous mode use the command:
export CELERY_DISABLED=1
ticker=SPY
publish_from_s3_to_redis.py -t ${ticker} -u integration-tests -k trexaccesskey -s trex123321 -a localhost:9000 -r localhost:6379 -m 0 -n integration-test-v1
sa -t ${ticker} -f -o ${ticker}_latest_v1 -j prepared -u pricing -k trexaccesskey -s trex123321 -a localhost:9000 -r localhost:6379 -m 0 -n ${ticker}_demo
fetch -t ${ticker} -g all -e 2018-10-19 -u pricing -k trexaccesskey -s trex123321 -a localhost:9000 -r localhost:6379 -m 0 -n ${ticker}_demo -P 1 -N 1 -O 1 -U 1 -R 1
fetch -A scn -L 'https://finviz.com/screener.ashx?v=111&f=cap_midunder,exch_nyse,fa_div_o6,idx_sp500&ft=4|https://finviz.com/screener.ashx?v=111&f=cap_midunder,exch_nyse,fa_div_o8,idx_sp500&ft=4'
Linting and Other Tools
Linting
flake8 . pycodestyle .
Sphinx Docs
cd docs make html
Docker Admin - Pull Latest
docker pull jayjohnson/stock-analysis-jupyter && docker pull jayjohnson/stock-analysis-engine
Back up Docker Redis Database
/opt/sa/tools/backup-redis.sh
View local redis backups with:
ls -hlrt /opt/sa/tests/datasets/redis/redis-0-backup-*.rdb
Export the Kubernetes Redis Cluster’s Database to the Local Redis Container
stop the redis docker container:
./compose/stop.sh
Archive the previous redis database
cp /data/redis/data/dump.rdb /data/redis/data/archive.rdb
Save the Redis database in the Cluster
kubectl exec -it redis-master-0 redis-cli save
Export the saved redis database file inside the pod to the default docker redis container’s local file
kubectl cp redis-master-0:/bitnami/redis/data/dump.rdb /data/redis/data/dump.rdb
Restart the stack
./compose/start.sh
Deploy Fork Feature Branch to Running Containers
When developing features that impact multiple containers, you can deploy your own feature branch without redownloading or manually building docker images. With the containers running., you can deploy your own fork’s branch as a new image (which are automatically saved as new docker container images).
Deploy a public or private fork into running containers
./tools/update-stack.sh <git fork https uri> <optional - branch name (master by default)> <optional - fork repo name>
Example:
./tools/update-stack.sh https://github.com/jay-johnson/stock-analysis-engine.git timeseries-charts jay
Restore the containers back to the Master
Restore the container builds back to the master branch from https://github.com/AlgoTraders/stock-analysis-engine with:
./tools/update-stack.sh https://github.com/AlgoTraders/stock-analysis-engine.git master upstream
Deploy Fork Alias
Here’s a bashrc alias for quickly building containers from a fork’s feature branch:
alias bd='pushd /opt/sa >> /dev/null && source /opt/venv/bin/activate && /opt/sa/tools/update-stack.sh https://github.com/jay-johnson/stock-analysis-engine.git timeseries-charts jay && popd >> /dev/null'
Debug Fetching IEX Data
ticker="SPY"
use_date=$(date +"%Y-%m-%d")
source /opt/venv/bin/activate
exp_date=$(/opt/sa/analysis_engine/scripts/print_next_expiration_date.py)
fetch -t ${ticker} -g iex -n ${ticker}_${use_date} -e ${exp_date} -Z
Failed Fetching Tradier Data
Please export a valid TD_TOKEN in your compose/envs/*.env docker compose files if you see the following errors trying to pull pricing data from Tradier:
2019-01-09 00:16:47,148 - analysis_engine.td.fetch_api - INFO - failed to get put with response=<Response [401]> code=401 text=Invalid Access Token 2019-01-09 00:16:47,151 - analysis_engine.td.get_data - CRITICAL - ticker=TSLA-tdputs - ticker=TSLA field=10001 failed fetch_data with ex='date' 2019-01-09 00:16:47,151 - analysis_engine.work_tasks.get_new_pricing_data - CRITICAL - ticker=TSLA failed TD ticker=TSLA field=tdputs status=ERR err=ticker=TSLA-tdputs - ticker=TSLA field=10001 failed fetch_data with ex='date'
License
Apache 2.0 - Please refer to the LICENSE for more details
FAQ
Can I live trade with my algorithms?
Not yet. Please reach out for help on how to do this or if you have a platform you like.
Can I publish algorithm trade notifications?
Right now algorithms only support publishing to a private Slack channel for sharing with a group when an algorithm finds a buy/sell trade to execute. Reach out if you have a custom chat client app or service you think should be supported.
Terms of Service
Data Attribution
This repository currently uses Tradier and IEX for pricing data. Usage of these feeds require the following agreements in the terms of service.
IEX Cloud
Link to IEX’s Terms of Use
IEX Real-Time Price is used with this repository
IEX Cloud is a data source with the additional data attribution instructions available on https://iextrading.com/developer/docs/#attribution
Adding Celery Tasks
If you want to add a new Celery task add the file path to WORKER_TASKS at these locations:
compose/envs/local.env
compose/envs/.env
analysis_engine/work_tasks/consts.py
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file stock-analysis-engine-1.9.15.tar.gz.
File metadata
- Download URL: stock-analysis-engine-1.9.15.tar.gz
- Upload date:
- Size: 290.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/50.2.0 requests-toolbelt/0.9.1 tqdm/4.48.0 CPython/3.8.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
23d76cfb8816a209446311bd223d86858db76945d4e444855889767d83d003b6
|
|
| MD5 |
8442f590f6df4ea5cb440333b6ffffa7
|
|
| BLAKE2b-256 |
af0a840074fc4cf3817a22b590d07794d3367d896e78d26f9b416a7ed7a917b7
|
File details
Details for the file stock_analysis_engine-1.9.15-py2.py3-none-any.whl.
File metadata
- Download URL: stock_analysis_engine-1.9.15-py2.py3-none-any.whl
- Upload date:
- Size: 443.6 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/50.2.0 requests-toolbelt/0.9.1 tqdm/4.48.0 CPython/3.8.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4cc30a4bb3f514e7cad8fcd4f53732c95198af0a86d8d7444861078e355c7509
|
|
| MD5 |
d2cc46179bd3f54fc0fcfe73ac2c85e1
|
|
| BLAKE2b-256 |
43c9cce5e11d8fa28b85eff041ff651594be11ec003c6d97859b6fcb97d7afc0
|







