prototype of a sytaxparser

Project description
syntax-parser-prototype

spp provides a generic schema implementation for syntax parsers whose structure and behavior can be defined flexibly and complexly using derived objects.
spp also provides some advanced interfaces and parameterizations to meet complex syntax definition requirements.
pip install syntax-parser-prototype --upgrade
pip install syntax-parser-prototype[debug] --upgrade
see Change Log for pre-releases
pip install syntax-parser-prototype==3.1a2
Quick Start
The main entry points for the phrase configuration are the methods Phrase.starts and Phrase.ends.
Their return value tells the parser whether a phrase starts and, if so, where and in what context.
The structural logic of a syntax is realized by assigning phrases objects to other phrases objects as under phrases.
demos/quickstart/main.py (source)
# Represents a simplified method for parsing python syntax.
# The following paragraph is to be parsed:
# foo = 42
# baz = not f'{foo + 42 is foo} \' bar'
import keyword
import re
from src.syntax_parser_prototype import *
from src.syntax_parser_prototype.features.tokenize import *
# simple string definition
class StringPhrase(Phrase):
id = "string"
# token typing
class NodeToken(NodeToken):
id = "string-start-quotes"
class Token(Token):
id = "string-content"
TDefaultToken = Token
class EndToken(EndToken):
id = "string-end-quotes"
# backslash escape handling
class MaskPhrase(Phrase):
id = "mask"
def starts(self, stream: Stream):
if m := re.search("\\\\.", stream.unparsed):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ prevents closure
return MaskToken(m.start(), m.end())
# could also be implemented as a stand-alone token or
# independent phrase if the pattern is to be tokenized separately
else:
return None
PH_MASK = MaskPhrase()
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# creates the logic during initialization
self.add_subs(self.PH_MASK)
def starts(self, stream: Stream):
# searches for quotation marks and possible prefix and saves the quotation mark type
# switches to a different phase configuration if the f-string pattern is found
if m := re.search("(f?)(['\"])", stream.unparsed, re.IGNORECASE):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
if prefix := m.group(1):
switchto = PH_FSTRING
else:
switchto = self
return self.NodeToken(m.start(), m.end(), SwitchTo(switchto), quotes=m.group(2))
else:
return None
def ends(self, stream: Stream):
# searches for the saved quotation mark type
if m := re.search(stream.node.extras.quotes, stream.unparsed):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
return self.EndToken(m.start(), m.end())
else:
return None
# modified string definition for f-string pattern
class FstringPhrase(StringPhrase):
id = "fstring"
# format content handling
class FstringFormatContentPhrase(Phrase):
id = "fstring-format-content"
# token typing
class NodeToken(NodeToken):
id = "fstring-format-content-open"
class EndToken(EndToken):
id = "fstring-format-content-close"
def starts(self, stream: Stream):
if m := re.search("\\{", stream.unparsed):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
return self.NodeToken(m.start(), m.end())
else:
return None
def ends(self, stream: Stream):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
if m := re.search("}", stream.unparsed):
return self.EndToken(m.start(), m.end())
else:
return None
PH_FSTRING_FORMAT_CONTENT = FstringFormatContentPhrase()
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# creates the logic during initialization
self.add_subs(self.PH_FSTRING_FORMAT_CONTENT)
NUMBER42 = list()
# simple word definition
class WordPhrase(Phrase):
id = "word"
# token typing
class KeywordToken(Token):
id = "keyword"
class VariableToken(Token):
id = "variable"
class NumberToken(Token):
id = "number"
class WordNode(NodeToken):
id = "word"
def atConfirmed(self) -> None:
assert not self.inner
def atFeaturized(self) -> None:
# collect 42 during the parsing process
if self.inner[0].content == "42":
NUMBER42.append(self[0])
def starts(self, stream: Stream):
if m := re.search("\\w+", stream.unparsed):
# foo = 42
# ↑ ↑
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ ↑ ↑ ↑ ↑ ↑
return self.WordNode(
m.start(),
m.end(),
# forwards the content to tokenize
RTokenize(len(m.group()))
)
# could also be implemented as a stand-alone token,
# but this way saves conditional queries if the token is not prioritized
else:
return None
def tokenize(self, stream: TokenizeStream):
token = stream.eat_remain()
if token in keyword.kwlist:
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ ↑
return self.KeywordToken
elif re.match("^\\d+$", token):
# foo = 42
# ↑
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
return self.NumberToken
else:
# foo = 42
# ↑
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ ↑ ↑
return self.VariableToken
def ends(self, stream: Stream):
# end the phrase immediately without content after the start process
# foo = 42
# ↑ ↑
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ ↑ ↑ ↑ ↑ ↑
return super().ends(stream) # return InstantEndToken()
MAIN = Root()
PH_STRING = StringPhrase()
PH_FSTRING = FstringPhrase()
PH_WORD = WordPhrase()
# MAIN SETUP
# - configure the logic at the top level
MAIN.add_subs(PH_STRING, PH_WORD)
# - recursive reference to the logic of the top level
PH_FSTRING.PH_FSTRING_FORMAT_CONTENT.add_subs(MAIN.__sub_phrases__)
if __name__ == "__main__":
from demos.quickstart import template
with open(template.__file__) as f:
# foo = 42
# baz = not f'{foo + 42 is foo} \' bar'
#
content = f.read()
# parse the content
result = MAIN.parse_string(content)
if PROCESS_RESULT := True:
# some result processing
assert content == result.tokenReader.branch.content
token = result.tokenIndex.get_token_at_coord(1, 19)
assert token.content == "42"
assert token.column_end == 21
assert token.data_end == 30
assert token.node.phrase.id == "word"
assert token.next.next.next.next.content == "is"
assert token.node.node[0].tokenReader.inner.content == "foo"
assert isinstance(result, NodeToken)
for inner_token in result:
if isinstance(inner_token, NodeToken):
assert isinstance(inner_token.inner, list)
assert isinstance(inner_token.end, EndToken)
else:
assert not hasattr(inner_token, "inner")
assert isinstance(result.end, EndToken) and isinstance(result.end, EOF)
assert len(NUMBER42) == 2
if DEBUG := True:
# visualisation
print(*(f"std. repr: {t} {t!r}" for t in NUMBER42), sep="\n")
from src.syntax_parser_prototype import debug
print(*(f"debug repr: {t} {t!r}" for t in NUMBER42), sep="\n")
debug.html_server.token_css[WordPhrase.KeywordToken] = "font-weight: bold;"
debug.html_server.token_css[WordPhrase.NumberToken] = "color: blue; border-bottom: 1px dotted blue;"
debug.html_server.token_css[StringPhrase.NodeToken] = "color: green;"
debug.html_server.token_css[StringPhrase.Token] = "color: green;"
debug.html_server.token_css[StringPhrase.EndToken] = "color: green;"
debug.html_server.token_css[FstringPhrase.FstringFormatContentPhrase.NodeToken] = "color: orange;"
debug.html_server.token_css[FstringPhrase.FstringFormatContentPhrase.EndToken] = "color: orange;"
debug.html_server(result)
Concept
General
Configuration Overview
The basic parser behavior is defined by
- the structure definition in the form of assignments of phrases to phrases as sub- or suffix phrases
and assignments of root subphrases to
Root; - the return values of
Phrase.starts()andPhrase.ends().
Advanced Features
Phrase.tokenize()(hook)Phrase.atStart()(hook)Phrase.atEnd()(hook)[...]Token(..., features: LStrip | RTokenize | SwitchTo | SwitchPh | ForwardTo)(advanced control)[...]Token.atConfirmed()(hook)[...]Token.atFeaturized()(hook)
Parser Behavior
The entries for starting the parsing process are Root.parse_rows() and Root.parse_string(),
which return a RootNode object as the result.
The parser processes entered data row[^1] by row:
The more detailed definition of a row can be left to the user (
Root.parse_rows()). The line break characters are NOT automatically interpreted at the end of a row and must therefore be included in the transferred data.In
Root.parse_string(), lines are defined by line break characters by default.
Phrases Start and End Values
Within a process iteration, starts() of sub-phrases and the ends() of the currently active phrase
are queried for the unparsed part of the current row[^1]
(defined from the cursor viewpoint to the end of the row[^1]).
The methods must return a token object that matches the context as a positive value (otherwise None).
- Valid node tokens from
Phrase.starts()are: - Valid standalone[^2] tokens from
Phrase.starts()are:Standalone tokens are token types that do not trigger a phrase change and are assigned directly to the parent phrase.
- Valid end tokens from
Phrase.ends()are:
Token Priority
The order in which phrases are assigned as sub-phrases is irrelevant;
the internal order in which the methods of several sub-phrases are queried is random
and in most cases is executed across the board for all potential sub-phrases.
Therefore - and to differentiate from EndToken's - positive return values (tokens) must be
differentiated to find the one that should actually be processed next.
The project talks about token priority[^3]:
InstandToken's have the highest priority. These would- as
InstandEndTokenfromPhrase.ends()prevent the search for starts and close the phrase immediately at the defined point. - as
InstandNodeTokenorInstandTokenas a standalone[^2] Token fromPhrase.starts(), immediately interrupt the search for further starts and process this token directly.
- as
- Tokens with the smallest
atparameter (the start position relative to the viewpoint of the stream) have the second-highest priority. - The third-highest priority is given to so-called null tokens[^4].
Null tokens are tokens for which no content is defined. null tokens that are returned for the position directly at the viewpoint (
at=0) are only permitted asEndTokens, as otherwise the parser might get stuck in an infinite loop. An exception to this is the extended feature configuration withForwardTo, where only one of the tokens has to advance the stream. - Finally, the Token with the longest content has the highest priority.
Value Domains and Tokenization
The domain of values within a phrase defined by starts() and ends() is referred to as a branch and can be nested
by sub- or suffix phrases. The domain at phrase level is then separated by the NodeToken's of these phrases.
By default, the parser parses this domain row[^1] by row[^1] as single tokens. The Phrase.tokenize() hook is
available for selective token typing.
Therefore, before processing a Node, End or standalone[^2] Token or at the end of a row[^1],
the remaining content is automatically assigned to the (still) active node/phrase.
Token Types
Control Tokens
Control tokens are returned as positive values of the configured phrase methods
for controlling the parser and — except the Mask[Node]Token's — are present in the result.
In general, all tokens must be configured with the definition of at <int> and to <int>.
These values tell the parser in which area of the currently unparsed row[^1] part the content for
the token is located.
Except the Mask[Node]Token's, all control tokens can be equipped with extended
features that can significantly influence the parsing process.
In addition, free keyword parameters can be transferred to [...]NodeToken's,
which are assigned to the extras attribute in the node.
class Token
(standard type) Simple text content token and base type for all other tokens.
Tokens of this type must be returned by Phrase.tokenize
or can represent a standalone[^2] token via Phrase.starts.
These are stored as a value in the inner attribute of the parent node.
class NodeToken (Token)
(standard type) Represents the beginning of a phrase as a token and contains subordinate tokens and the end token.
Phrase.starts() must return tokens of this type when a complex phrase starts.
These are stored as a value in the inner attribute of the parent node.
class EndToken (Token)
(standard type) Represents the end of a phrase.
Phrase.ends() must return tokens of this type when a complex phrase ends.
These are stored as a value as the end attribute of the parent node.
class MaskToken (Token)
(special type) Special standalone[^2] token type that can be returned by Phrase.starts().
Instead of the start of this phrase, the content is then assigned to the parent node. This token type will never be present in the result.
Note: If Phrase.start() returns a MaskToken, sub-/suffix-phrases of this Phrase are NOT evaluated.
class MaskNodeToken (MaskToken, NodeToken)
(special type) Special node token type that can be returned by Phrase.starts().
Starts a masking phrase whose content is assigned to the parent node. This token type will never be present in the result.
Note: If Phrase.start() returns a MaskToken, sub-/suffix-phrases of this Phrase are NOT evaluated.
class InstantToken (Token)
(special type) Special standalone[^2] token type that can be returned by Phrase.starts().
Prevents comparison of priority[^3] with other tokens and accepts the token directly.
class InstantEndToken (InstantToken, EndToken)
(special type) Special end token type that can be returned by Phrase.ends().
Prevents comparison of priority[^3] with other tokens and accepts the token directly.
class InstantNodeToken (InstantToken, NodeToken)
(special type) Special node token type that can be returned by Phrase.starts().
Prevents comparison of priority[^3] with other tokens and accepts the token directly.
class DefaultEndToken (EndToken)
(special type) Special end token type that can be returned by Phrase.ends().
This end token closes the associated phrase if no start of a subphrase was found.
class WrapNodeToken (NodeToken)
(special type) Special node token that wraps another node token that can be returned by Phrase.starts().
Functions as an interface to the wrapped node regarding token priority. The parent node of the wrapped one will be this. This node does not contain any content in the result, but is a valid node token.
Internal Token Types
Internal token types are automatically assigned during the process.
class OpenEndToken(Token)
Represents the non-end of a phrase.
This type is set to NodeToken.end by default until an EndToken replaces it
or remains in the result if none was found until the end.
Acts as an interface to the last seen token of the phrase for duck typing.
class RootNode(NodeToken)
Represents the root of the parsed input and contains all other tokens (has no content but is a valid token to represent the result root).
class OToken(Token)
Represents an inner token for the root phrase when no user-defined phrase is active.
class OEOF(OpenEndToken)
Represents the non-end of the parsed input, set to RootNode.end.
This type is set by default until the EOF replaces it at the end of the process
(will never be included in the result).
class EOF(EndToken)
Represents the end of the parsed input, set to RootNode.end
(has no content but is a valid token to be included in the result).
Token Data Interface (Basic Overview)
Structure Hint
RootNode[
OToken
NodeToken[
Token
NodeToken
].EndToken
].EOF
General Token Properties
(all kinds of tokens)
| Selector | Description |
|---|---|
.id: Any |
can be freely defined by the user in derivatives; is only evaluated by the debug module |
.content: str |
text content of this token |
.node: NodeToken |
parent node |
.row_no: int |
row number of the entered data in which the token is located |
.column_start: int |
column number in the row at which the token beginns |
.column_end: int |
column number in the row at which the token ens |
.data_start: int |
data index relative to the entered data at which the token beginns (requires the extensive Token indexing utility (default)) |
.data_end: int |
data index relative to the entered data at which the token ens (requires the extensive Token indexing utility (default)) |
.len_token: int |
== len(.content) |
.inner_index: int |
index of the token in the collection of the parent node |
.previous: AnyToken |
previous tokens in the one-dimensional level |
.next: AnyToken |
next tokens in the one-dimensional level |
str(...) |
== .content |
bool(...) |
== bool(.content) |
.tokenReader |
Token read utility |
Node Token Specifics
(additional to general)
| Selector | Description |
|---|---|
.inner: list[InnerToken, ...] |
collection of inner tokens |
.end: EndToken |
end token of the branch |
.root: RootToken |
the documents root node |
.len_inner: int |
total length of all contained tokens (recursive) |
.len_branch: int |
total length of the branch (recursive, incl. this node and end token) |
bool(...) |
== .content or .inner or .end.content |
iter(...) |
== iter(.inner) |
[i] |
== .inner[i] |
Root Node Token Specifics
(additional to node specifics)
| Selector | Description |
|---|---|
.tokenIndex |
Token indexing utility |
Token.tokenReader
Provides functionality to iterate through tokens in a one-dimensional context and other structure-related methods.
The default iterator behavior is to iterate one-dimensionally from the
token that created the reader (anchor) exclusive to the last token.
The reverse iterator can be obtained via reversed(...) or
the call parameter reverse=True.
General Properties
(all kinds of source tokens)
| Property | Description |
|---|---|
.thereafter: TokenReader |
independent reader with default behavior |
.therebefore: TokenReader |
independent reader that iterates exclusively from the first token to the anchor token |
.content: str |
entire text content of the context of the reader |
Node Properties
(additional to general)
| Property | Description |
|---|---|
.node_path: TokenReader |
independent reader that iterates through the structure path from the root node to the anchor node inclusive |
.inner: TokenReader |
independent reader that iterates through the inner tokens recursively |
.branch: TokenReader |
independent reader that iterates through the inner tokens recursively, inclusive the anchor node and end |
RootNode.tokenIndex
Provides some localization functionality.
(For performance reasons, a different index type can be configured as a class attribute in the root phrase. The "extensive index" used as standard is described here.)
Overview:
.data_start_of().get_token_at_coord().get_token_at_cursor()[row_no] -> IndexRecord.row_no.row_tokens.first_token.last_token.data_start.data_end.len_row.token_at()
Visualization Tools
The debug module (source) provides some support for visualization. All necessary packages can be installed separately:
pip install syntax-parser-prototype[debug] --upgrade
Overview
XML __repr__
>>> parserResult, parserResult[1]
(<syntax_parser_prototype.main.tokens.RootNode object at 0x0000>, <... object at ...>)
>>> from syntax_parser_prototype import debug # that's all
>>> parserResult, parserResult[1]
(<R phrase="<id>" coord="0 0:0"></R>, <o coord="0 3:4"> </o>)
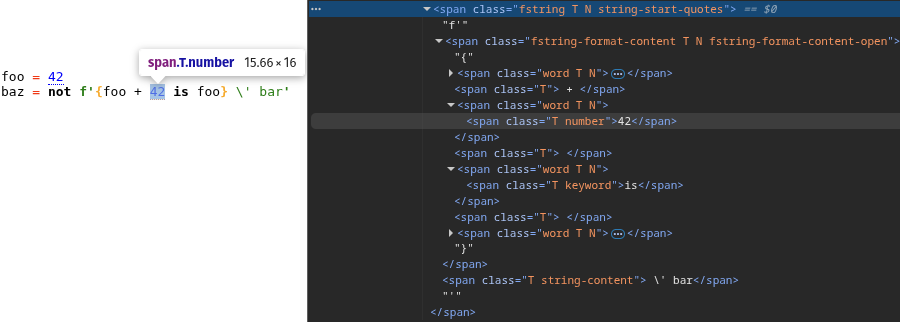
HTML Server
from src.syntax_parser_prototype import debug
debug.html_server(result)
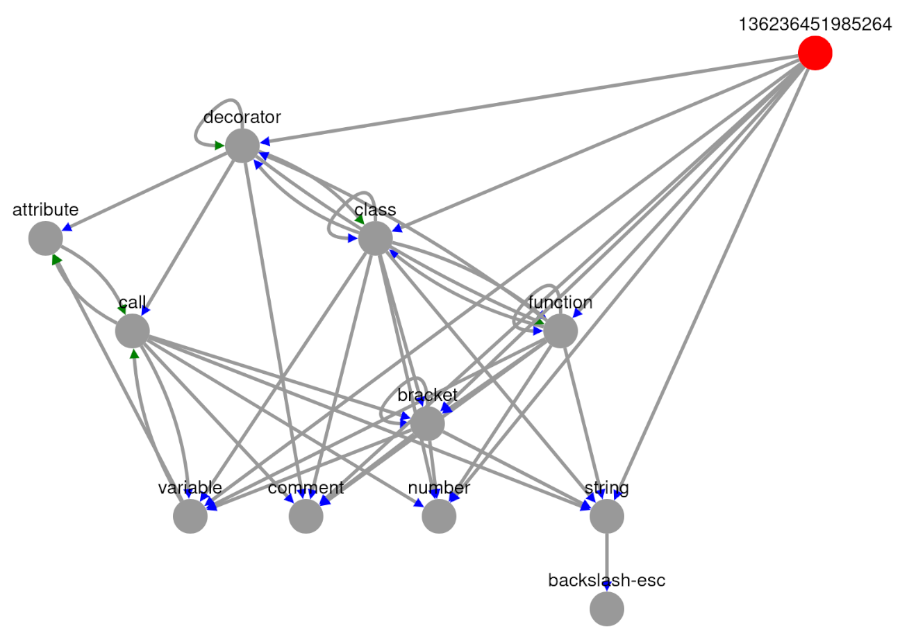
Structure Graph App
from src.syntax_parser_prototype import debug
debug.structure_graph_app(MAIN)
Pretty XML
from src.syntax_parser_prototype import debug
print(debug.pretty_xml(result))
<?xml version="1.0" ?>
<R phrase="130192620364736" coord="0 0:0">
<word phrase="word" coord="0 0:0">
<variable coord="0 0:3">foo</variable>
<iE coord="0 3:3"/>
</word>
<o coord="0 3:6"> = </o>
<word phrase="word" coord="0 6:6">
<number coord="0 6:8">42</number>
<iE coord="0 8:8"/>
</word>
<o coord="0 8:9">
</o>
<word phrase="word" coord="1 0:0">
<variable coord="1 0:3">baz</variable>
<iE coord="1 3:3"/>
</word>
<o coord="1 3:6"> = </o>
<word phrase="word" coord="1 6:6">
<keyword coord="1 6:9">not</keyword>
<iE coord="1 9:9"/>
</word>
<o coord="1 9:10"> </o>
<string-start-quotes phrase="fstring" coord="1 10:12">
f'
<fstring-format-content-open phrase="fstring-format-content" coord="1 12:13">
{
<word phrase="word" coord="1 13:13">
<variable coord="1 13:16">foo</variable>
<iE coord="1 16:16"/>
</word>
<T coord="1 16:19"> + </T>
<word phrase="word" coord="1 19:19">
<number coord="1 19:21">42</number>
<iE coord="1 21:21"/>
</word>
<T coord="1 21:22"> </T>
<word phrase="word" coord="1 22:22">
<keyword coord="1 22:24">is</keyword>
<iE coord="1 24:24"/>
</word>
<T coord="1 24:25"> </T>
<word phrase="word" coord="1 25:25">
<variable coord="1 25:28">foo</variable>
<iE coord="1 28:28"/>
</word>
<fstring-format-content-close coord="1 28:29">}</fstring-format-content-close>
</fstring-format-content-open>
<string-content coord="1 32:39"> \' bar</string-content>
<string-end-quotes coord="1 36:37">'</string-end-quotes>
</string-start-quotes>
<o coord="1 37:38">
</o>
<EOF coord="1 38:38"/>
</R>
Change Log
3.1a2 — improvements and cleanup
- added optional
indentandnewlineparameters todebug.pretty_xml() - removed generic type hints and type variables (unusable)
- added hooks
atStartandatEndtoPhrase - improve documentation
3.1a1 — feature update
- added
class DefaultEndToken(EndToken) - added
class WrapNodeToken(NodeToken) - changed parameterization of
toforTDefaultTokeninDefaultTokenizeStreamfrom0to-1 - removed
Parser.__carby__ - changed module
typing
3.0 — major release
-
added
nodeshortcut inTokenizeStream -
added less restrictive type hints in
PhraseandRootgenerics -
added support for
PhraseandNodetype hints forStream's andToken's viaGeneric[TV_PHRASE, TV_NODE_TOKEN]to ensure stronger type binding between phrase implementations and token/node types(Application example in a
Phrase.startsmethod definition:def starts(self, stream: streams.Stream[MyPhrase, MyNode1 | MyNode2]): stream.node.my_attribute stream.node.phrase.my_attribute ...
-
fixed
OpenEndTokeninterface -
added/fixed unpacking in
Phrase.add_suffixes()
3.0a3 — fix type hint
- 3.0a3 fixes a type hint error in
Phrase.tokenize()
3.0a2 — security update
- 3.0a2 closes a gap in the protection against infinite loops
With the configuration of the extended feature
ForwardToto anEndToken, the parser would not have recognized if it did not advance.
3.0a1 — initial pre-release
- Version 3 differs fundamentally from its predecessors
[^1]: A row is not necessarily a line as it is generally understood.
[^2]: Standalone tokens are token types that do not trigger a phrase change and are assigned directly to the parent phrase.
[^3]: InstandEndToken < InstandNodeToken < InstandToken < smallest at < Null tokens < longest content
[^4]: Null tokens are tokens for which no content is defined.
Null tokens that are returned for the position directly at the viewpoint (at=0) are only permitted as EndTokens.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file syntax_parser_prototype-3.1a2.tar.gz.
File metadata
- Download URL: syntax_parser_prototype-3.1a2.tar.gz
- Upload date:
- Size: 40.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a1d97a0c043f76773d98b59e5d069cbe5ad115047db8f7d2a1561d594f062b86
|
|
| MD5 |
32d399c889905263523e5ddc42e806a0
|
|
| BLAKE2b-256 |
547f5ad4ecebf16078a5355b6cda1eadb41287ffbf8a3fdacc221d06b8ab5672
|
File details
Details for the file syntax_parser_prototype-3.1a2-py3-none-any.whl.
File metadata
- Download URL: syntax_parser_prototype-3.1a2-py3-none-any.whl
- Upload date:
- Size: 36.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dfb89c616a92424b4a1bef232dd3c7daa7bc23e6a0dd31a7d5d740e309358b9f
|
|
| MD5 |
6ab9371ba66e83baca39f9119f278a93
|
|
| BLAKE2b-256 |
864ec913f90fb6ead70252e2b42f0b42533f19517575fe43822e71c613514853
|







