Simple wrapper for tabula-java, read tables from PDF into DataFrame
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
tabula-py





tabula-py is a simple Python wrapper of tabula-java, which can read tables in a PDF.
You can read tables from a PDF and convert them into a pandas DataFrame. tabula-py also enables you to convert a PDF file into a CSV, a TSV or a JSON file.
You can see the example notebook and try it on Google Colab, or we highly recommend reading our documentation, especially the FAQ section.
Requirements
- Java 8+
- Python 3.8+
OS
I confirmed working on macOS and Ubuntu. But some people confirm it works on Windows 10. See also the documentation for the detailed installation for Windows 10.
Usage
- Documentation
- FAQ would be helpful if you have an issue
- Example notebook on Google Colaboratory
Install
Ensure you have a Java runtime and set the PATH for it.
pip install tabula-py
If you want to leverage faster execution with jpype, install with jpype extra.
pip install tabula-py[jpype]
Example
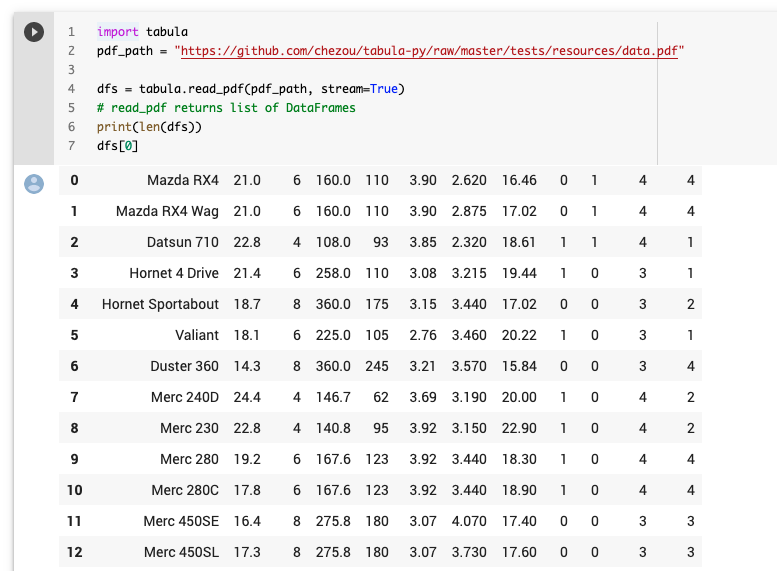
tabula-py enables you to extract tables from a PDF into a DataFrame, or a JSON. It can also extract tables from a PDF and save the file as a CSV, a TSV, or a JSON.
import tabula
# Read pdf into list of DataFrame
dfs = tabula.read_pdf("test.pdf", pages='all')
# Read remote pdf into list of DataFrame
dfs2 = tabula.read_pdf("https://github.com/tabulapdf/tabula-java/raw/master/src/test/resources/technology/tabula/arabic.pdf")
# convert PDF into CSV file
tabula.convert_into("test.pdf", "output.csv", output_format="csv", pages='all')
# convert all PDFs in a directory
tabula.convert_into_by_batch("input_directory", output_format='csv', pages='all')
See an example notebook for more details. I also recommend reading the tutorial article written by @aegis4048, and another tutorial written by @tdpetrou.
Contributing
Interested in helping out? I'd love to have your help!
You can help by:
- Reporting a bug.
- Adding or editing documentation.
- Contributing code via a Pull Request. See also for the contribution
- Write a blog post or spread the word about
tabula-pyto people who might be able to benefit from using it.
Contributors
- @lahoffm
- @jakekara
- @lcd1232
- @kirkholloway
- @CurtLH
- @nikhilgk
- @krassowski
- @alexandreio
- @rmnevesLH
- @red-bin
- @Gallaecio
- @red-bin
- @alexandreio
- @bpben
- @Bueddl
- @cjotade
- @codeboy5
- @manohar-voggu
- @deveshSingh06
- @grfeller
- @djbrown
- @swar
- @mvoggu
- @tdpetrou
Another support
You can also support our continued work on tabula-py with a donation on GitHub Sponsors or Patreon.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tabula_py-2.10.0.tar.gz.
File metadata
- Download URL: tabula_py-2.10.0.tar.gz
- Upload date:
- Size: 12.5 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.1.1 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
75968a83fe978e5d56ccf23f0f0255a459c256b7b52db7cabe5ac795bb3b12df
|
|
| MD5 |
cdd7dc001840f516e01a1b3d5fa76606
|
|
| BLAKE2b-256 |
e2312a14a5048f681c404ae0b32a00d141128dd3065965190fdcae3b33e2bcae
|
File details
Details for the file tabula_py-2.10.0-py3-none-any.whl.
File metadata
- Download URL: tabula_py-2.10.0-py3-none-any.whl
- Upload date:
- Size: 12.0 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.1.1 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c7596c559fc813e313eb4fbc7aabe7e4290dbd04717c4cbe4aa4a2cafd00ab63
|
|
| MD5 |
84d0928c3457c28640517de5759bb59a
|
|
| BLAKE2b-256 |
2f8010bc6f303054d1a06eb8628f90e5997f4b1272956a477230f3fa95637c28
|







