Reduce multiple TensorBoard runs to new event (or CSV) files

Project description







This project was inspired by
tensorboard-aggregator(similar project built with TensorFlow rather than PyTorch) and this SO answer.
Compute reduced statistics (mean, std, min, max, median or any other numpy operation) of multiple TensorBoard runs matching a directory glob pattern. This can for instance be used when training multiple identical models to reduce the noise in their loss/accuracy/error curves to establish statistical significance in performance improvements. The aggregation results can be saved to disk either as new TensorBoard event files or in CSV format.
Requires PyTorch and TensorBoard. No TensorFlow installation required.
Installation
pip install tensorboard-reducer
Usage
Example:
tb-reducer -i 'glob_pattern/of_dirs_to_reduce*' -o basename_of_output_dir -r mean,std,min,max
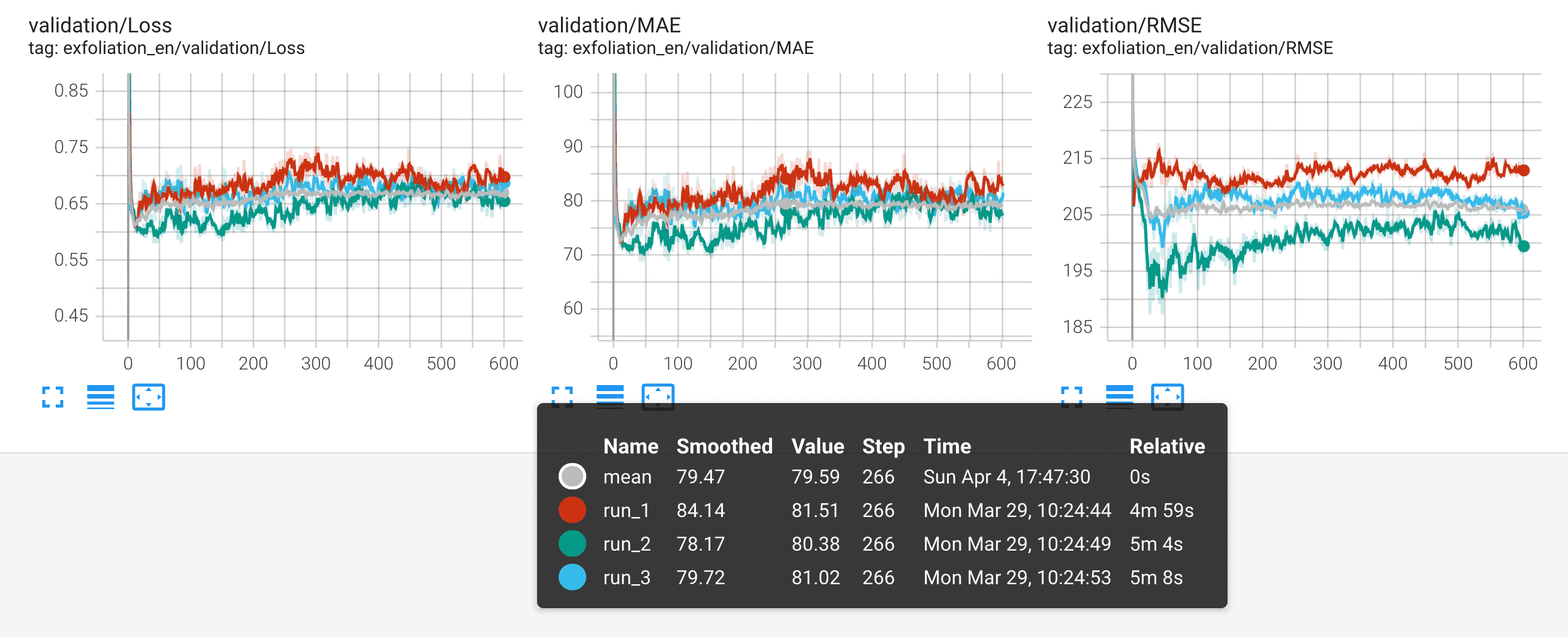
tb-reducer has the following flags:
-i/--indirs-glob(required): Glob pattern of the run directories to reduce.-o/--outdir(required): Name of the directory to save the new reduced run data. If--formatistb-events, a separate directory will be created for each reduce op (mean,std, ...) suffixed by the op's name (outdir-mean,outdir-std, ...). If--formatiscsv, a single file will created andoutdirmust end with a.csvextension.-r/--reduce-ops(optional): Comma-separated names of numpy reduction ops (mean,std,min,max, ...). Default ismean. Each reduction is written to a separateoutdirsuffixed by its op name, e.g. ifoutdir='my-new-run, the mean reduction will be written tomy-new-run-mean.-f/--format: Output format of reduced TensorBoard runs. One oftb-eventsfor regular TensorBoard event files orcsv. Ifcsv,-o/--outdirmust have.csvextension and all reduction ops will be written to a single CSV file rather than separate directories for each reduce op. Usepandas.read_csv("path/to/file.csv", header=[0, 1], index_col=0)to read data back into memory as a multi-index dataframe.-w/--overwrite(optional): Whether to overwrite existingoutdirs/CSV files.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tensorboard-reducer-0.1.6.tar.gz.
File metadata
- Download URL: tensorboard-reducer-0.1.6.tar.gz
- Upload date:
- Size: 10.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/3.10.0 pkginfo/1.7.0 requests/2.24.0 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fb2ed4201dc29f4ac4913a7992355dddc9788d8873938ef1a84cd9310d38e751
|
|
| MD5 |
644c9a8692864b8a2d2b3b133eda99eb
|
|
| BLAKE2b-256 |
7907bf2435bfcf0aec6945aedfa2c43f4a0a79b54fc2e36e2178c11c2797aef9
|
File details
Details for the file tensorboard_reducer-0.1.6-py2.py3-none-any.whl.
File metadata
- Download URL: tensorboard_reducer-0.1.6-py2.py3-none-any.whl
- Upload date:
- Size: 10.7 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/3.10.0 pkginfo/1.7.0 requests/2.24.0 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8594e7d43e5087883e622b26e4a17a6cc8d606652f3f3e3cb8a1699a5d2fb55a
|
|
| MD5 |
dcd22b36b807171c1ed400565a056426
|
|
| BLAKE2b-256 |
4a4c362688df459d81f8203de0d38da4922965576a6a44f510fbc7fefcb22980
|







