TileRT: Tile-Based Runtime for Ultra-Low-Latency LLM Inference.

Project description

TileRT: Tile-Based Runtime for
Ultra-Low-Latency LLM Inference
TileRT serves large language models (LLMs) in ultra-low-latency scenarios — pushing the latency limits of hundred-billion-parameter models to millisecond-level time per output token (TPOT) without compromising model size or quality. Its tile-level runtime engine decomposes LLM operators into fine-grained tile tasks and dynamically overlaps computation, I/O, and communication across multiple GPUs.
The current preview supports DeepSeek-V3.2 and GLM-5 on 8× NVIDIA B200. For full usage, examples, and news, see the GitHub repository.
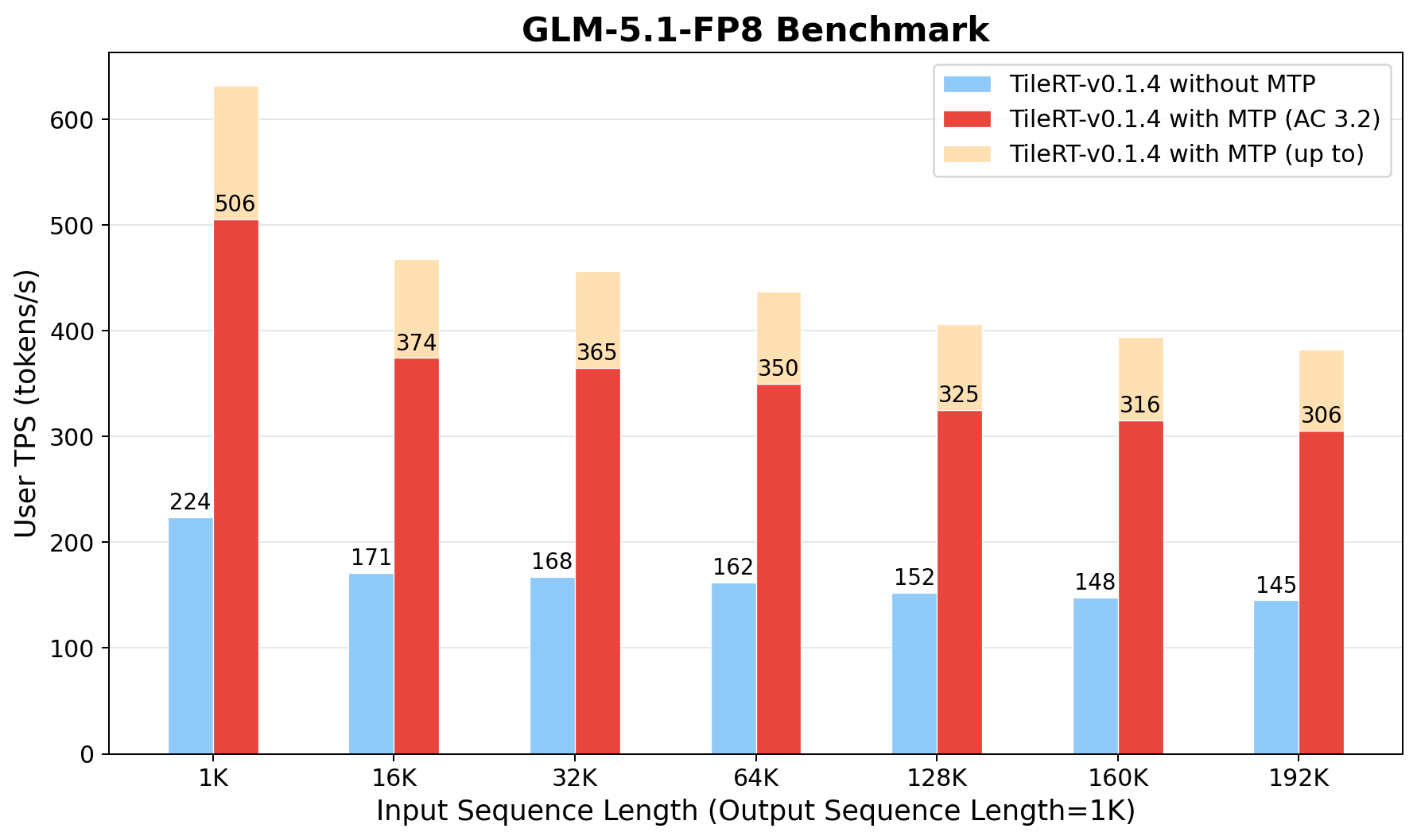
GLM-5.1-FP8 token generation speed with TileRT v0.1.4. Output length 1K, input length 1K–192K. Bars compare TileRT without MTP, with MTP at average acceptance length 3.2, and the peak under best-case MTP acceptance.
Installation
The official tilert==0.1.4 wheel on PyPI was compiled against the following stack. Treat these as hard requirements, not lower bounds.
| Component | Pinned version |
|---|---|
| NVIDIA driver | Supports CUDA 13.2 runtime |
| Operating System | Linux x86_64, glibc ≥ 2.28 (manylinux_2_28) |
| Python | 3.12 |
| PyTorch | torch==2.11.0+cu130 |
transformers |
4.46.3 |
tokenizers |
0.20.3 |
Recommended: pre-built Docker image
The pinned environment is preinstalled in our official image — the recommended way to run TileRT, avoiding version drift on the host. The image is mirrored to two registries; pull from whichever is reachable:
docker pull ghcr.io/tile-ai/tilert:cu132-latest # GitHub Container Registry
docker pull tileai/tilert:cu132-latest # Docker Hub
Launch a container with all 8 GPUs attached, then install the wheel inside:
docker run --rm -it --gpus all --ipc=host \
-v "$PWD":/workspace -w /workspace \
ghcr.io/tile-ai/tilert:cu132-latest
# Install from PyPI:
pip install tilert==0.1.4
# Or pin the exact wheel from the GitHub Release page (same artifact,
# useful when PyPI is unreachable):
pip install https://github.com/tile-ai/TileRT/releases/download/v0.1.4/tilert-0.1.4-cp312-cp312-manylinux_2_28_x86_64.whl
Verify the install:
python -c "import tilert, torch; print('tilert', tilert.__version__, '/ torch', torch.__version__, '/ cuda', torch.version.cuda)"
# Expected: tilert 0.1.4 / torch 2.11.0+cu130 / cuda 13.0
Documentation
For weight conversion, the generation CLI, the programmatic API, Multi-Token Prediction (MTP), and the latest benchmarks, see the TileRT GitHub repository.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tilert-0.1.4-cp312-cp312-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tilert-0.1.4-cp312-cp312-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 6.3 MB
- Tags: CPython 3.12, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ac5919e59d0639e2160cc5b3e2004adb2da26bd6ede29b58d2b29c890736c057
|
|
| MD5 |
c5220de7fe00487d1afa99a3390552ef
|
|
| BLAKE2b-256 |
bbcd2d5c6f33e5a9f9219c59fe89580de4b73a845e6c97e09478fc43135a1dfd
|







