Tomoto, The Topic Modeling Tool for Python

Project description
What is tomotopy?
tomotopy is a Python extension of tomoto (Topic Modeling Tool) which is a Gibbs-sampling based topic model library written in C++. It utilizes a vectorization of modern CPUs for maximizing speed. The current version of tomoto supports several major topic models including
Latent Dirichlet Allocation (tomotopy.LDAModel),
Dirichlet Multinomial Regression (tomotopy.DMRModel),
Hierarchical Dirichlet Process (tomotopy.HDPModel),
Multi Grain LDA (tomotopy.MGLDAModel),
Pachinko Allocation (tomotopy.PAModel),
Hierarchical PA (tomotopy.HPAModel).
Getting Started
You can install tomotopy easily using pip.
$ pip install tomotopy
For Linux, it is neccesary to have gcc 5 or more for compiling C++14 codes. After installing, you can start tomotopy by just importing.
import tomotopy as tp print(tp.isa) # prints 'avx2', 'avx', 'sse2' or 'none'
Currently, tomotopy can exploits AVX2, AVX or SSE2 SIMD instruction set for maximizing performance. When the package is imported, it will check available instruction sets and select the best option. If tp.isa tells none, iterations of training may take a long time. But, since most of modern Intel or AMD CPUs provide SIMD instruction set, the SIMD acceleration could show a big improvement.
Here is a sample code for simple LDA training of texts from ‘sample.txt’ file.
import tomotopy as tp
mdl = tp.LDAModel(k=20)
for line in open('sample.txt'):
mdl.add_doc(line.strip().split())
for i in range(0, 100, 10):
mdl.train(10)
print('Iteration: {}\tLog-likelihood: {}'.format(i, mdl.ll_per_word))
for k in range(mdl.k):
print('Top 10 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=10))
Performance of tomotopy
tomotopy uses Collapsed Gibbs-Sampling(CGS) to infer the distribution of topics and the distribution of words. Generally CGS converges more slowly than Variational Bayes(VB) that [gensim’s LdaModel] uses, but its iteration can be computed much faster. In addition, tomotopy can take advantage of multicore CPUs with a SIMD instruction set, which can result in faster iterations.
[gensim’s LdaModel]: https://radimrehurek.com/gensim/models/ldamodel.html
Following chart shows the comparison of LDA model’s running time between tomotopy and gensim. The input data consists of 1000 random documents from English Wikipedia with 1,506,966 words (about 10.1 MB). tomotopy trains 200 iterations and gensim trains 10 iterations.
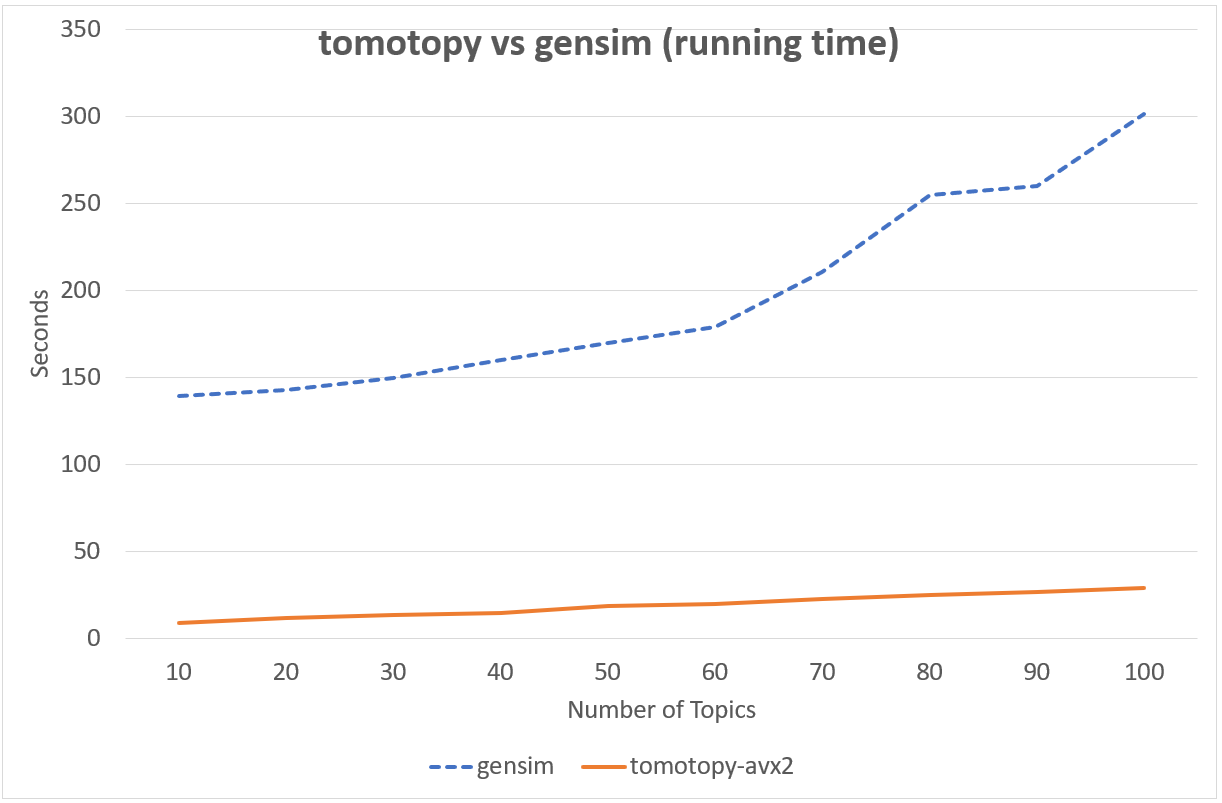
Performance in Intel i5-6600, x86-64 (4 cores)
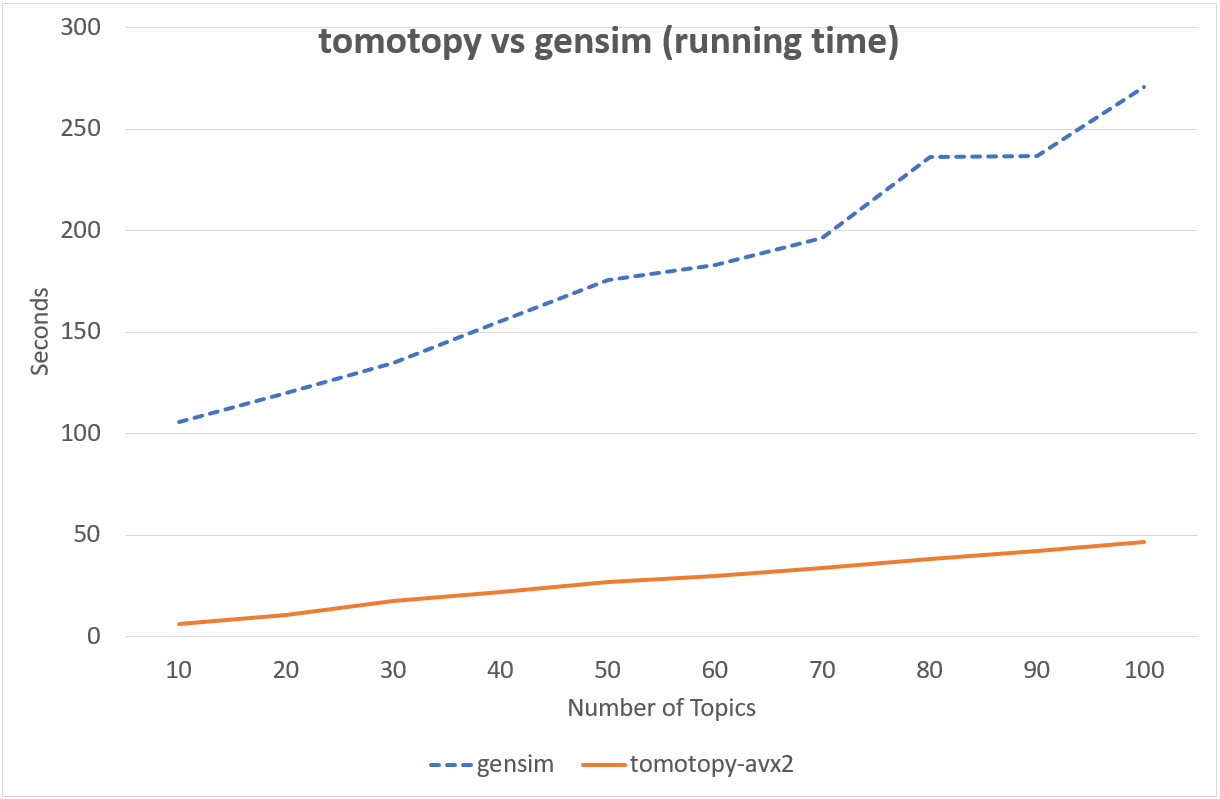
Performance in Intel Xeon E5-2620 v4, x86-64 (8 cores, 16 threads)
Although tomotopy iterated 20 times more, the overall running time was 5~10 times faster than gensim. And it yields a stable result.
It is difficult to compare CGS and VB directly because they are totaly different techniques. But from a practical point of view, we can compare the speed and the result between them. The following chart shows the log-likelihood per word of two models’ result.
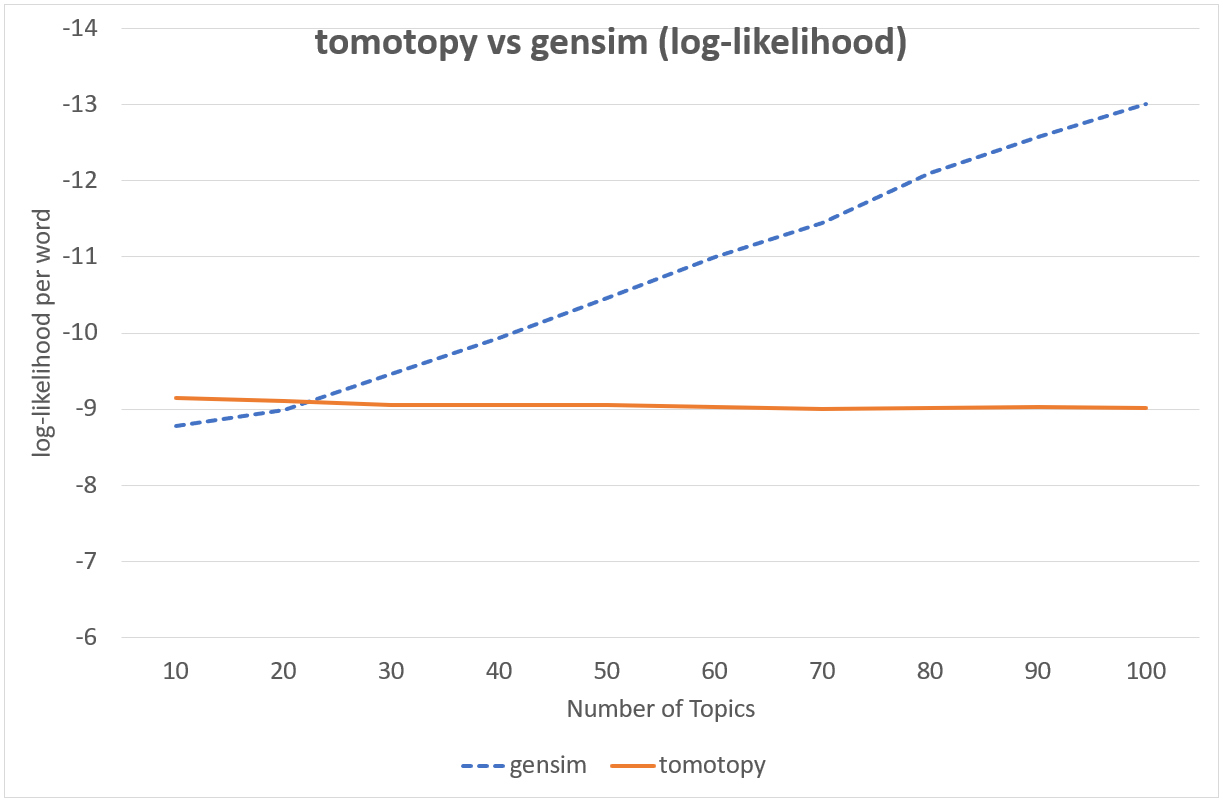
The SIMD instruction set has a great effect on performance. Following is a comparison between SIMD instruction sets.
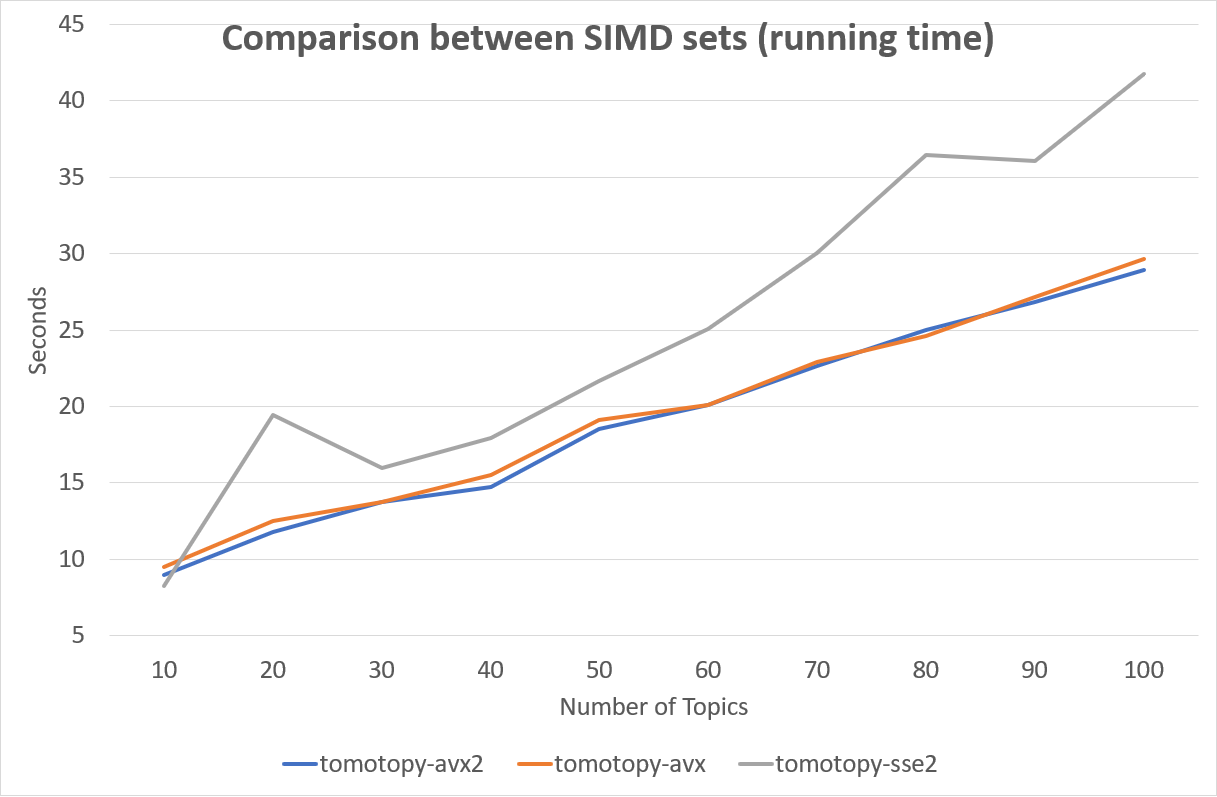
Fortunately, most of recent x86-64 CPUs provide AVX2 instruction set, so we can enjoy the performance of AVX2.
Model Save and Load
tomotopy provides save and load method for each topic model class, so you can save the model into the file whenever you want, and re-load it from the file.
import tomotopy as tp
mdl = tp.HDPModel()
for line in open('sample.txt'):
mdl.add_doc(line.strip().split())
for i in range(0, 100, 10):
mdl.train(10)
print('Iteration: {}\tLog-likelihood: {}'.format(i, mdl.ll_per_word))
# save into file
mdl.save('sample_hdp_model.bin')
# load from file
mdl = tp.HDPModel.load('sample_hdp_model.bin')
for k in range(mdl.k):
if not mdl.is_live_topic(k): continue
print('Top 10 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=10))
# the saved model is HDP model,
# so when you load it by LDA model, it will raise an exception
mdl = tp.LDAModel.load('sample_hdp_model.bin')
When you load the model from a file, a model type in the file should match the class of methods.
See more at tomotopy.LDAModel.save and tomotopy.LDAModel.load methods.
Documents in the Model and out of the Model
We can use Topic Model for two major purposes. The basic one is to discover topics from a set of documents as a result of trained model, and the more advanced one is to infer topic distributions for unseen documents by using trained model.
We named the document in the former purpose (used for model training) as document in the model, and the document in the later purpose (unseen document during training) as document out of the model.
In tomotopy, these two different kinds of document are generated differently. A document in the model can be created by tomotopy.LDAModel.add_doc method. add_doc can be called before tomotopy.LDAModel.train starts. In other words, after train called, add_doc cannot add a document into the model because the set of document used for training has become fixed.
To acquire the instance of the created document, you should use tomotopy.LDAModel.docs like:
mdl = tp.LDAModel(k=20)
idx = mdl.add_doc(words)
if idx < 0: raise RuntimeError("Failed to add doc")
doc_inst = mdl.docs[idx]
# doc_inst is an instance of the added document
A document out of the model is generated by tomotopy.LDAModel.make_doc method. make_doc can be called only after train starts. If you use make_doc before the set of document used for training has become fixed, you may get wrong results. Since make_doc returns the instance directly, you can use its return value for other manipulations.
mdl = tp.LDAModel(k=20) # add_doc ... mdl.train(100) doc_inst = mdl.make_doc(unseen_words) # doc_inst is an instance of the unseen document
Inference for Unseen Documents
If a new document is created by tomotopy.LDAModel.make_doc, its topic distribution can be inferred by the model. Inference for unseen document should be performed using tomotopy.LDAModel.infer method.
mdl = tp.LDAModel(k=20)
# add_doc ...
mdl.train(100)
doc_inst = mdl.make_doc(unseen_words)
topic_dist, ll = mdl.infer(doc_inst)
print("Topic Distribution for Unseen Docs: ", topic_dist)
print("Log-likelihood of inference: ", ll)
The infer method can infer only one instance of tomotopy.Document or a list of instances of tomotopy.Document. See more at tomotopy.LDAModel.infer.
License
tomotopy is licensed under the terms of MIT License, meaning you can use it for any reasonable purpose and remain in complete ownership of all the documentation you produce.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tomotopy-0.1.6.tar.gz.
File metadata
- Download URL: tomotopy-0.1.6.tar.gz
- Upload date:
- Size: 864.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: Python-urllib/3.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fbf366e12e593664273f1f05172bd763f22fcaa8bf20befbf732bc4bff372a9f
|
|
| MD5 |
0a96083e3b64fffaf06ed0b0409890fa
|
|
| BLAKE2b-256 |
1e064755923991774db8604828e3818330066a25ef3e4f44a497953581b341d9
|
File details
Details for the file tomotopy-0.1.6-cp37-cp37m-win_amd64.whl.
File metadata
- Download URL: tomotopy-0.1.6-cp37-cp37m-win_amd64.whl
- Upload date:
- Size: 1.7 MB
- Tags: CPython 3.7m, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: Python-urllib/3.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
92aff5d2fca66e394fa028768aa473b2ad12c8043f1b342a2662182c2cbd2615
|
|
| MD5 |
ab60829ab1bc7869968dbaebb0383dc2
|
|
| BLAKE2b-256 |
67b46e24b32dbf395de557637347881bf4c2f55e9b665f1c72094ec7cc9e7dda
|
File details
Details for the file tomotopy-0.1.6-cp37-cp37m-win32.whl.
File metadata
- Download URL: tomotopy-0.1.6-cp37-cp37m-win32.whl
- Upload date:
- Size: 972.7 kB
- Tags: CPython 3.7m, Windows x86
- Uploaded using Trusted Publishing? No
- Uploaded via: Python-urllib/3.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cff307f04a293825e92275b4e606b186460f57660e2c1539b07aa4075fd2e885
|
|
| MD5 |
b69317664054cfdeb4481d1f4d1dd910
|
|
| BLAKE2b-256 |
df009709f28a263b532cc903d08ffd442cebec278ffb44b849279cb867be5b86
|
File details
Details for the file tomotopy-0.1.6-cp36-cp36m-win_amd64.whl.
File metadata
- Download URL: tomotopy-0.1.6-cp36-cp36m-win_amd64.whl
- Upload date:
- Size: 1.7 MB
- Tags: CPython 3.6m, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: Python-urllib/3.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
33ae991c1ddb4e3ed1700df8453784ea5ecfc9a2d4671996cbd05f822a740230
|
|
| MD5 |
875d13f4d54d60f70d2f06f3a024ce9c
|
|
| BLAKE2b-256 |
687c68d2222f247b49259c86cf26fdd3c900242e808122352072063618656d6a
|
File details
Details for the file tomotopy-0.1.6-cp36-cp36m-win32.whl.
File metadata
- Download URL: tomotopy-0.1.6-cp36-cp36m-win32.whl
- Upload date:
- Size: 972.7 kB
- Tags: CPython 3.6m, Windows x86
- Uploaded using Trusted Publishing? No
- Uploaded via: Python-urllib/3.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
df2c99b7f9fa4e8f3940e0b832e4feadc0a8dd5f05d3b004901e2a06010158d0
|
|
| MD5 |
e84c5af3579700678c9cab54a8f91a68
|
|
| BLAKE2b-256 |
3509279d49974f8f41ee059b87f84c4bb3777f79bfc9d455c5829d6ba6a5bf65
|
File details
Details for the file tomotopy-0.1.6-cp35-cp35m-win_amd64.whl.
File metadata
- Download URL: tomotopy-0.1.6-cp35-cp35m-win_amd64.whl
- Upload date:
- Size: 1.7 MB
- Tags: CPython 3.5m, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: Python-urllib/3.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
75367846a12634974489e57a5e1278076fa12b5747c0d172c46ff562b0a95d67
|
|
| MD5 |
e16b06519c8104a8b0b5cc1ce112bbc4
|
|
| BLAKE2b-256 |
92021bb8ab43c9e55faff09410940e10275d96d6fb1ba55bf316bae72f47c2a4
|
File details
Details for the file tomotopy-0.1.6-cp35-cp35m-win32.whl.
File metadata
- Download URL: tomotopy-0.1.6-cp35-cp35m-win32.whl
- Upload date:
- Size: 972.7 kB
- Tags: CPython 3.5m, Windows x86
- Uploaded using Trusted Publishing? No
- Uploaded via: Python-urllib/3.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
72dfc66d13fc1e516fcc9d0f845bbbb5669bc0cff716e952ac070a8120441f3f
|
|
| MD5 |
51fcf7c16e2bd0a77565c0b1090601e7
|
|
| BLAKE2b-256 |
034bd4f964e2d65d4c10b6e1d5f444477c06884c6fdf4352dda7fd0535092b09
|







