A type-safe wrapper around BeautifulSoup and related HTML parsing utilities

Project description
typed-soup
A type-safe wrapper around BeautifulSoup and utilities for parsing HTML. Extracted from Open-Gov Crawlers.
Motivation
This is an example from production code.
Before
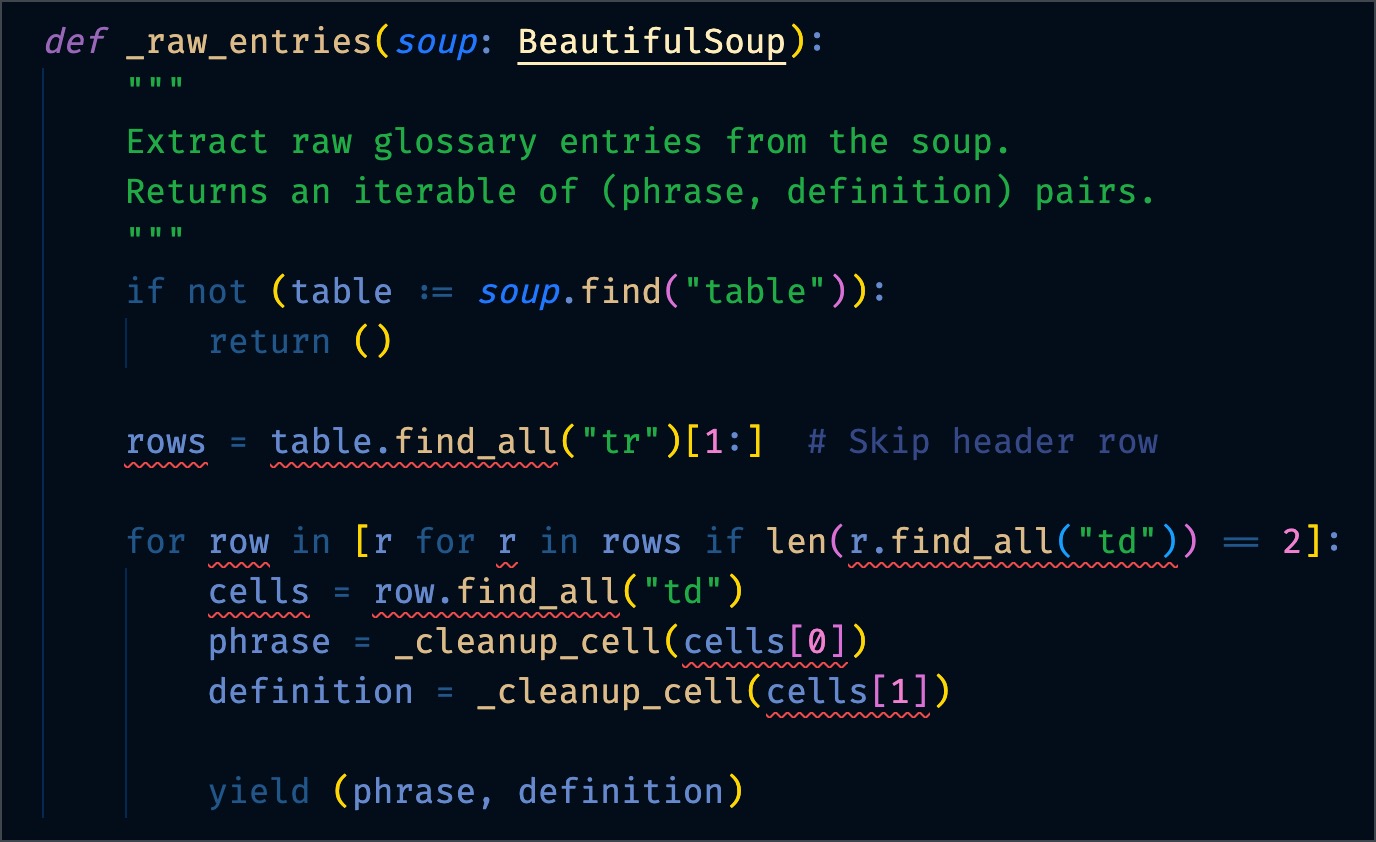
Here are the first five errors. There are 16 in total.
error: Type of "rows" is partially unknown
Type of "rows" is "list[PageElement | Tag | NavigableString] | Unknown" (reportUnknownVariableType)
error: Type of "find_all" is partially unknown
Type of "find_all" is "Unknown | ((name: str | bytes | Pattern[str] | bool | ((Tag) -> bool) | Iterable[str | bytes | Pattern[str] | bool | ((Tag) -> bool)] | ElementFilter | None = None, attrs: Dict[str, str | bytes | Pattern[str] | bool | ((str) -> bool) | Iterable[str | bytes | Pattern[str] | bool | ((str) -> bool)]] = {}, recursive: bool = True, string: str | bytes | Pattern[str] | bool | ((str) -> bool) | Iterable[str | bytes | Pattern[str] | bool | ((str) -> bool)] | None = None, limit: int | None = None, _stacklevel: int = 2, **kwargs: str | bytes | Pattern[str] | bool | ((str) -> bool) | Iterable[str | bytes | Pattern[str] | bool | ((str) -> bool)]) -> ResultSet[PageElement | Tag | NavigableString])" (reportUnknownMemberType)
error: Cannot access attribute "find_all" for class "PageElement"
Attribute "find_all" is unknown (reportAttributeAccessIssue)
error: Cannot access attribute "find_all" for class "NavigableString"
Attribute "find_all" is unknown (reportAttributeAccessIssue)
error: Type of "row" is partially unknown
Type of "row" is "PageElement | Tag | NavigableString | Unknown" (reportUnknownVariableType)
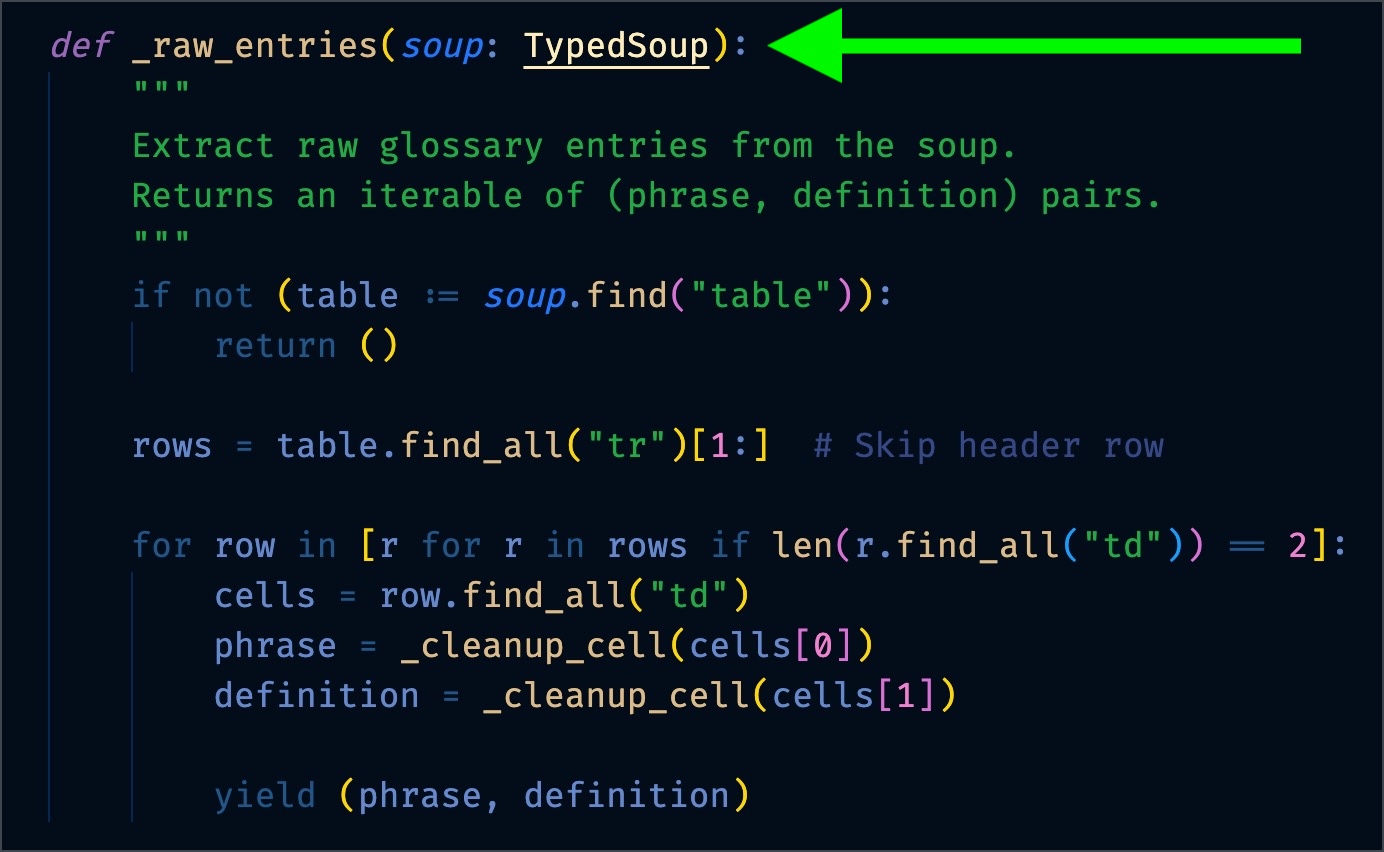
After
Switching out BeautifulSoup for TypedSoup provides type knowledge to the checker and IDE:
Installation
pip install typed-soup
Quick Start
from typed_soup import TypedSoup
from bs4 import BeautifulSoup
# Create a type-safe soup object
soup = TypedSoup(BeautifulSoup("<div>Hello <span>World</span></div>", "html.parser"))
# Find elements with type safety
element = soup.find("span")
if element:
print(element.get_text()) # Type-safe: IDE knows this returns str
Usage
If you're using Scrapy, you can use the from_response function to create a TypedSoup object from a Scrapy response:
from typed_soup import from_response
from scrapy.http.response.html import HtmlResponse
# Assume 'response' is an HtmlResponse object
soup = from_response(response)
# Find an element
element = soup.find("div", class_="example")
if element:
print(element.get_text())
# Find all elements
elements = soup("p")
for elem in elements:
print(elem.get_text())
Or, without Scrapy, you can explicity wrap a BeautifulSoup object in TypedSoup:
from typed_soup import TypedSoup
from bs4 import BeautifulSoup
soup = TypedSoup(BeautifulSoup(html_content, "html.parser"))
Supported Functions
I'm adding functions as I need them. If you have a request, please open an issue. These are the ones that I needed for a dozen spiders:
findfind_all__call__(implicit find_all, e.g.soup("p")- standard BeautifulSoup API)get_textchildrentag_nameparentnext_siblingget_content_after_elementstring
And then these help create a TypedSoup object:
from_responseTypedSoup
Type Safety Benefits
- All methods return properly typed results
- No more
Nonesurprises - optional values are properly typed and described in the function signatures - IDE autocomplete support for all methods
- Static type checking support with mypy/pyright
- Runtime type validation for BeautifulSoup results
License
This project is licensed under the MIT License.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file typed_soup-0.1.6.tar.gz.
File metadata
- Download URL: typed_soup-0.1.6.tar.gz
- Upload date:
- Size: 3.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.1.3 CPython/3.13.3 Darwin/24.4.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e111a51561fe21768d180d28cb03dbd8ece384b377f427ab32f31ff97f5e7d63
|
|
| MD5 |
217b20b8d0d59a45b3e02cc5baafbfba
|
|
| BLAKE2b-256 |
0936bd80b2bf2a4a863f583d90f4e07fc019b1a47692400edbee556adaeb21e3
|
File details
Details for the file typed_soup-0.1.6-py3-none-any.whl.
File metadata
- Download URL: typed_soup-0.1.6-py3-none-any.whl
- Upload date:
- Size: 4.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.1.3 CPython/3.13.3 Darwin/24.4.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d067962873b5b5d4357ca599d5b4899bb406d89a7233ee3fcf2bdc09750cfc63
|
|
| MD5 |
49bf94e6f5195b8e4f01984aaa401953
|
|
| BLAKE2b-256 |
7e723aa9d69a04ddd05c778cee364d047c42fef20baa234bbcd02e66535b4aa1
|







