Generate SQL queries from natural language


Project description

| GitHub | PyPI | Documentation |
|---|---|---|
 |
 |
 |
Vanna.AI - Personalized AI SQL Agent
https://github.com/vanna-ai/vanna/assets/7146154/1901f47a-515d-4982-af50-f12761a3b2ce
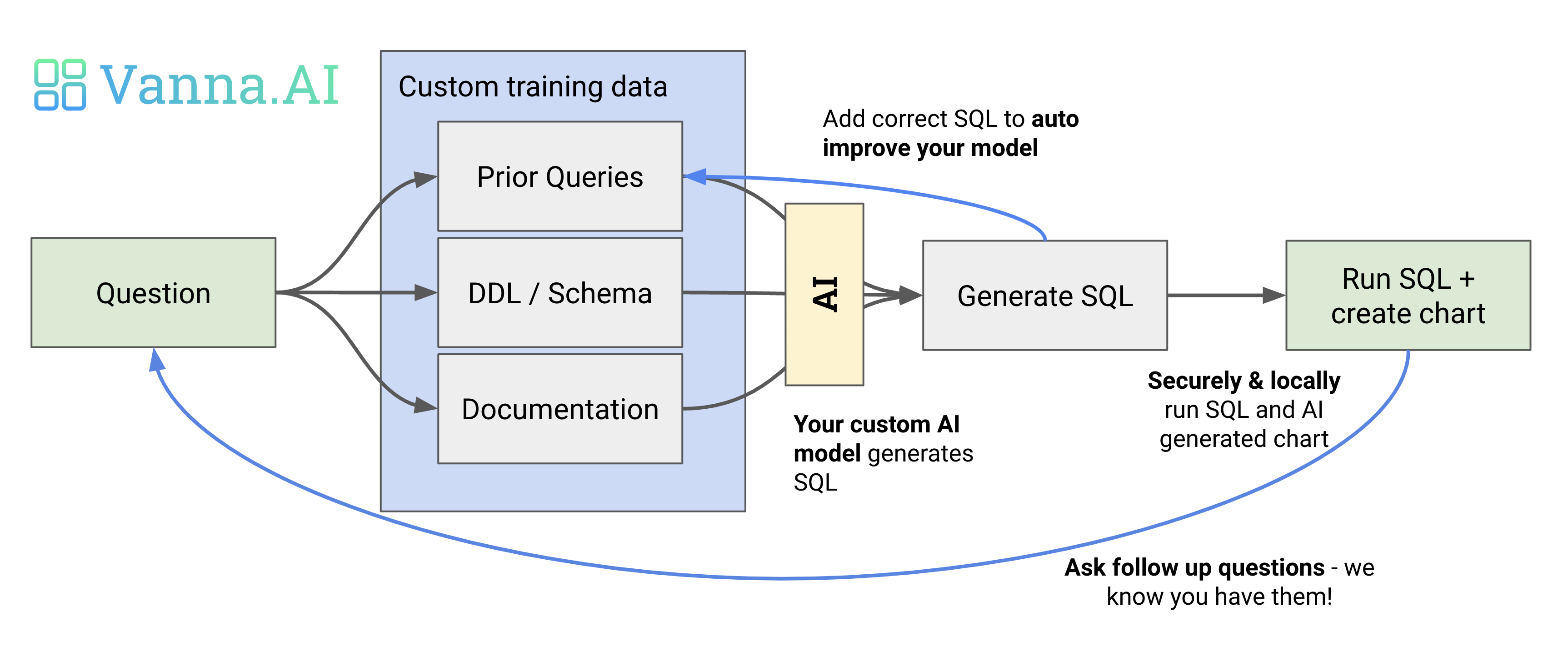
How Vanna works
Vanna works in two easy steps - train a model on your data, and then ask questions.
- Train a model on your data.
- Ask questions.
When you ask a question, we utilize a custom model for your dataset to generate SQL, as seen below. Your model performance and accuracy depends on the quality and quantity of training data you use to train your model.
Getting started
You can start by automatically training Vanna (currently works for Snowflake) or add manual training data.
Install Vanna
pip install vanna
Depending on the database you're using, you can also install the associated database drivers
pip install 'vanna[snowflake]'
Import Vanna
import vanna as vn
Train with DDL Statements
If you prefer to manually train, you do not need to connect to a database. You can use the train function with other parmaeters like ddl
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
Train with Documentation
Sometimes you may want to add documentation about your business terminology or definitions.
vn.train(documentation="Our business defines OTIF score as the percentage of orders that are delivered on time and in full")
Train with SQL
You can also add SQL queries to your training data. This is useful if you have some queries already laying around. You can just copy and paste those from your editor to begin generating new SQL.
vn.train(sql="SELECT * FROM my-table WHERE name = 'John Doe'")
Asking questions
vn.ask("What are the top 10 customers by sales?")
SELECT c.c_name as customer_name,
sum(l.l_extendedprice * (1 - l.l_discount)) as total_sales
FROM snowflake_sample_data.tpch_sf1.lineitem l join snowflake_sample_data.tpch_sf1.orders o
ON l.l_orderkey = o.o_orderkey join snowflake_sample_data.tpch_sf1.customer c
ON o.o_custkey = c.c_custkey
GROUP BY customer_name
ORDER BY total_sales desc limit 10;
| CUSTOMER_NAME | TOTAL_SALES | |
|---|---|---|
| 0 | Customer#000143500 | 6757566.0218 |
| 1 | Customer#000095257 | 6294115.3340 |
| 2 | Customer#000087115 | 6184649.5176 |
| 3 | Customer#000131113 | 6080943.8305 |
| 4 | Customer#000134380 | 6075141.9635 |
| 5 | Customer#000103834 | 6059770.3232 |
| 6 | Customer#000069682 | 6057779.0348 |
| 7 | Customer#000102022 | 6039653.6335 |
| 8 | Customer#000098587 | 6027021.5855 |
| 9 | Customer#000064660 | 5905659.6159 |
Why Vanna?
- High accuracy on complex datasets.
- Vanna’s capabilities are tied to the training data you give it
- More training data means better accuracy for large and complex datasets
- Secure and private.
- Your database contents are never sent to Vanna’s servers
- We only see the bare minimum - schemas & queries.
- Isolated, custom model.
- You train a custom model specific to your database and your schema.
- Nobody else can use your model or view your model’s training data unless you choose to add members to your model or make it public
- We use a combination of third-party foundational models (OpenAI, Google) and our own LLM.
- Self learning.
- As you use Vanna more, your model continuously improves as we augment your training data
- Supports many databases.
- We have out-of-the-box support Snowflake, BigQuery, Postgres
- You can easily make a connector for any database
- Pretrained models.
- If you’re a data provider you can publish your models for anyone to use
- As part of our roadmap, we are in the process of pre-training models for common datasets (Google Ads, Facebook ads, etc)
- Choose your front end.
- Start in a Jupyter Notebook.
- Expose to business users via Slackbot, web app, Streamlit app, or Excel plugin.
- Even integrate in your web app for customers.
More resources
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vanna-0.0.22.tar.gz.
File metadata
- Download URL: vanna-0.0.22.tar.gz
- Upload date:
- Size: 25.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cba03bd0d83bf945c7590d2520ccc39868f63b3c06dfd10a504de8125daef35e
|
|
| MD5 |
b7de1135fd13755a97a9386b43940d54
|
|
| BLAKE2b-256 |
7044d71d2dfc1b5d32a367d19f8a04d3282ded7766e7bccda54ae893c6898e62
|
File details
Details for the file vanna-0.0.22-py3-none-any.whl.
File metadata
- Download URL: vanna-0.0.22-py3-none-any.whl
- Upload date:
- Size: 26.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
708e6524a0d614021b95531a81980210a85b3fe25436b67acffb5de160cd637b
|
|
| MD5 |
d71976f1cf574b9f3d036863af75b97a
|
|
| BLAKE2b-256 |
fb7213a726ef044d1f8ab351c391c168f68dc8556657ac2f4b52d14b554c94fd
|







