Efficient LLM inference on Slurm clusters using vLLM.


Project description
Vector Inference: Easy inference on Slurm clusters







This repository provides an easy-to-use solution to run inference servers on Slurm-managed computing clusters using vLLM. This package runs natively on the Vector Institute cluster environments. To adapt to other environments, follow the instructions in Installation.
NOTE: Supported models on Killarney are tracked here
Installation
If you are using the Vector cluster environment, and you don't need any customization to the inference server environment, run the following to install package:
pip install vec-inf
Otherwise, we recommend using the provided Dockerfile to set up your own environment with the package. The latest image has vLLM version 0.10.1.1.
If you'd like to use vec-inf on your own Slurm cluster, you would need to update the configuration files, there are 3 ways to do it:
- Clone the repository and update the
environment.yamland themodels.yamlfile invec_inf/config, then install from source by runningpip install .. - The package would try to look for cached configuration files in your environment before using the default configuration. The default cached configuration directory path points to
/model-weights/vec-inf-shared, you would need to create anenvironment.yamland amodels.yamlfollowing the format of these files invec_inf/config. - The package would also look for an enviroment variable
VEC_INF_CONFIG_DIR. You can put yourenvironment.yamlandmodels.yamlin a directory of your choice and set the enviroment variableVEC_INF_CONFIG_DIRto point to that location.
Usage
Vector Inference provides 2 user interfaces, a CLI and an API
CLI
The launch command allows users to deploy a model as a slurm job. If the job successfully launches, a URL endpoint is exposed for the user to send requests for inference.
We will use the Llama 3.1 model as example, to launch an OpenAI compatible inference server for Meta-Llama-3.1-8B-Instruct, run:
vec-inf launch Meta-Llama-3.1-8B-Instruct
You should see an output like the following:
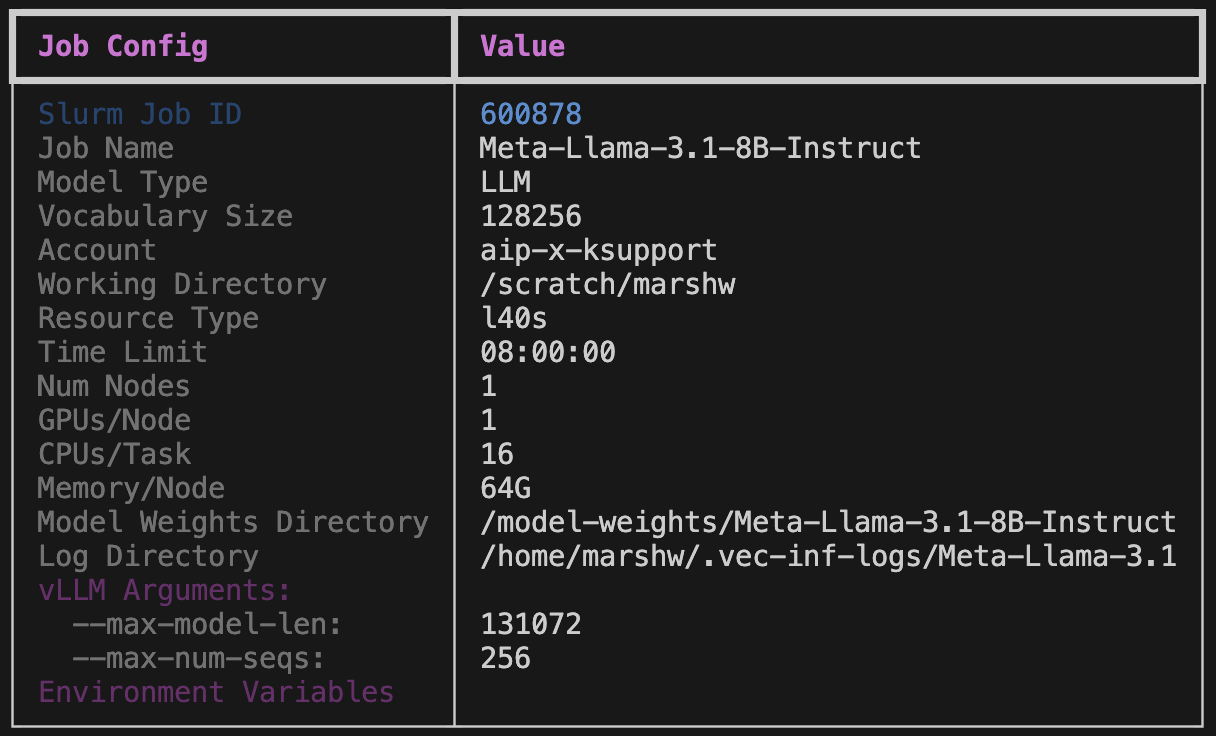
NOTE: You can set the required fields in the environment configuration (environment.yaml), it's a mapping between required arguments and their corresponding environment variables. On the Vector Killarney Cluster environment, the required fields are:
--account,-A: The Slurm account, this argument can be set to default by setting environment variableVEC_INF_ACCOUNT.--work-dir,-D: A working directory other than your home directory, this argument can be set to default by seeting environment variableVEC_INF_WORK_DIR.
Models that are already supported by vec-inf would be launched using the cached configuration (set in slurm_vars.py) or default configuration. You can override these values by providing additional parameters. Use vec-inf launch --help to see the full list of parameters that can be overriden. You can also launch your own custom model as long as the model architecture is supported by vLLM. For detailed instructions on how to customize your model launch, check out the launch command section in User Guide
Other commands
batch-launch: Launch multiple model inference servers at once, currently ONLY single node models supported,status: Check the model status by providing its Slurm job ID.metrics: Streams performance metrics to the console.shutdown: Shutdown a model by providing its Slurm job ID.list: List all available model names, or view the default/cached configuration of a specific model.cleanup: Remove old log directories, use--helpto see the supported filters. Use--dry-runto preview what would be deleted.
For more details on the usage of these commands, refer to the User Guide
API
Example:
>>> from vec_inf.api import VecInfClient
>>> client = VecInfClient()
>>> # Assume VEC_INF_ACCOUNT and VEC_INF_WORK_DIR is set
>>> response = client.launch_model("Meta-Llama-3.1-8B-Instruct")
>>> job_id = response.slurm_job_id
>>> status = client.get_status(job_id)
>>> if status.status == ModelStatus.READY:
... print(f"Model is ready at {status.base_url}")
>>> # Alternatively, use wait_until_ready which will either return a StatusResponse or throw a ServerError
>>> try:
>>> status = wait_until_ready(job_id)
>>> except ServerError as e:
>>> print(f"Model launch failed: {e}")
>>> client.shutdown_model(job_id)
For details on the usage of the API, refer to the API Reference
Check Job Configuration
With every model launch, a Slurm script will be generated dynamically based on the job and model configuration. Once the Slurm job is queued, the generated Slurm script will be moved to the log directory for reproducibility, located at $log_dir/$model_family/$model_name.$slurm_job_id/$model_name.$slurm_job_id.slurm. In the same directory you can also find a JSON file with the same name that captures the launch configuration, and will have an entry of server URL once the server is ready.
Send inference requests
Once the inference server is ready, you can start sending in inference requests. We provide example scripts for sending inference requests in examples folder. Make sure to update the model server URL and the model weights location in the scripts. For example, you can run python examples/inference/llm/chat_completions.py, and you should expect to see an output like the following:
{
"id":"chatcmpl-387c2579231948ffaf66cdda5439d3dc",
"choices": [
{
"finish_reason":"stop",
"index":0,
"logprobs":null,
"message": {
"content":"Arrr, I be Captain Chatbeard, the scurviest chatbot on the seven seas! Ye be wantin' to know me identity, eh? Well, matey, I be a swashbucklin' AI, here to provide ye with answers and swappin' tales, savvy?",
"role":"assistant",
"function_call":null,
"tool_calls":[],
"reasoning_content":null
},
"stop_reason":null
}
],
"created":1742496683,
"model":"Meta-Llama-3.1-8B-Instruct",
"object":"chat.completion",
"system_fingerprint":null,
"usage": {
"completion_tokens":66,
"prompt_tokens":32,
"total_tokens":98,
"prompt_tokens_details":null
},
"prompt_logprobs":null
}
NOTE: Certain models don't adhere to OpenAI's chat template, e.g. Mistral family. For these models, you can either change your prompt to follow the model's default chat template or provide your own chat template via --chat-template: TEMPLATE_PATH.
SSH tunnel from your local device
If you want to run inference from your local device, you can open a SSH tunnel to your cluster environment like the following:
ssh -L 8081:10.1.1.29:8081 username@v.vectorinstitute.ai -N
The example provided above is for the Vector Killarney cluster, change the variables accordingly for your environment. The IP address for the compute nodes on Killarney follow 10.1.1.XX pattern, where XX is the GPU number (kn029 -> 29 in this example).
Reference
If you found Vector Inference useful in your research or applications, please cite using the following BibTeX template:
@software{vector_inference,
title = {Vector Inference: Efficient LLM inference on Slurm clusters using vLLM},
author = {Wang, Marshall},
organization = {Vector Institute},
year = {<YEAR_OF_RELEASE>},
version = {<VERSION_TAG>},
url = {https://github.com/VectorInstitute/vector-inference}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vec_inf-0.7.1.tar.gz.
File metadata
- Download URL: vec_inf-0.7.1.tar.gz
- Upload date:
- Size: 411.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.6.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7de1a1fb3c3814cf3105ec9446c854391fbfc67a44846895204f6b57e9851b07
|
|
| MD5 |
1866ab4649f770e21fd12920cd57a874
|
|
| BLAKE2b-256 |
edc1d3a5568a851bc60da7aec72c0655ab416c49d2ac039b0b4da2e740ccce6f
|
File details
Details for the file vec_inf-0.7.1-py3-none-any.whl.
File metadata
- Download URL: vec_inf-0.7.1-py3-none-any.whl
- Upload date:
- Size: 46.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.6.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1f4d7209f8ad94d4a3defe7f2a901acbee433bbb75ec485a55f02668f2075acb
|
|
| MD5 |
0fb68609a8de038f08f11cdf3455168d
|
|
| BLAKE2b-256 |
ac88228dda74eee0fe21ffc6559c5b1c8e9144c009657187440b4b2f233c09bd
|







