A web interface for managing and interacting with vLLM servers

Reason this release was yanked:
bug
Project description
vLLM Playground
A modern web interface for managing and interacting with vLLM servers (www.github.com/vllm-project/vllm). Supports GPU and CPU modes, with special optimizations for macOS Apple Silicon and enterprise deployment on OpenShift/Kubernetes.
🆕 vLLM-Omni Multimodal Generation
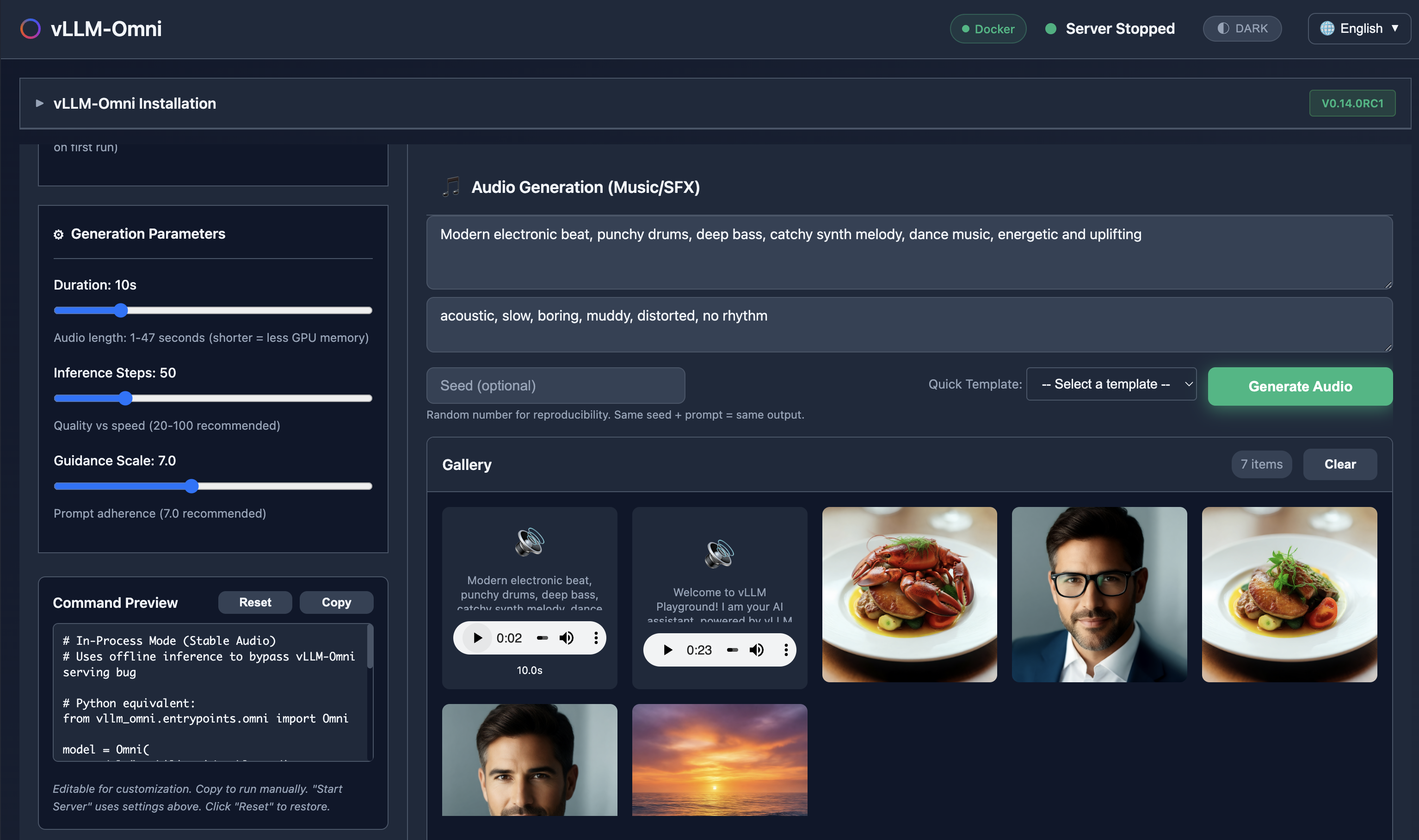
Generate images, edit photos, create speech, and produce music - all with vLLM-Omni integration.
✨ Claude Code Integration
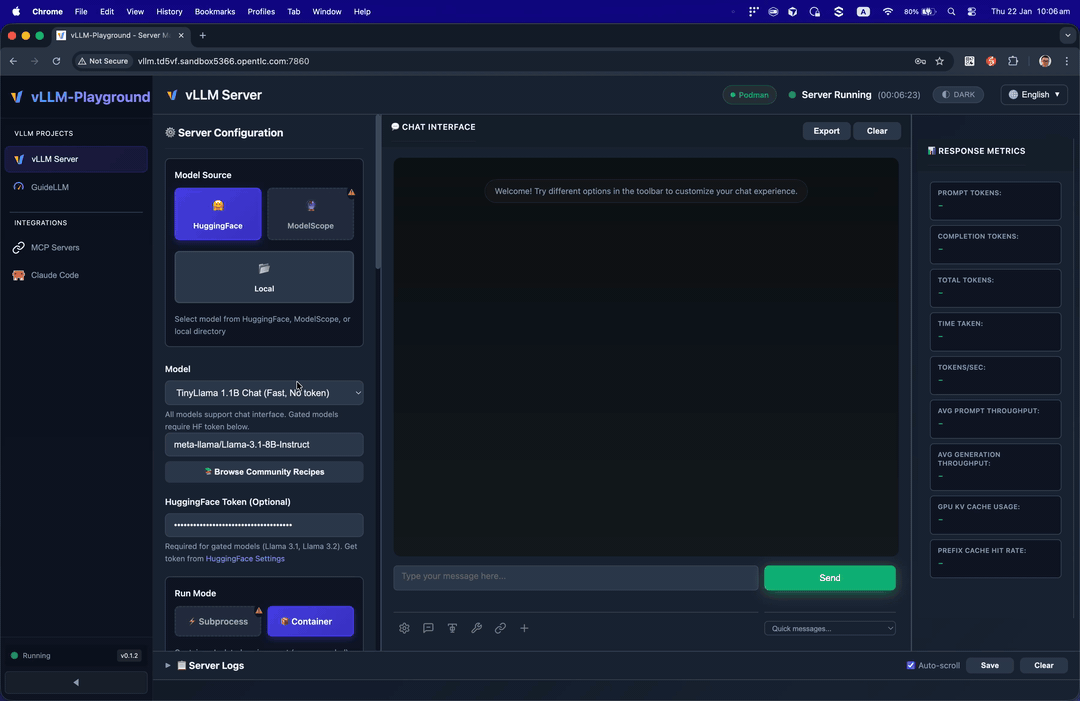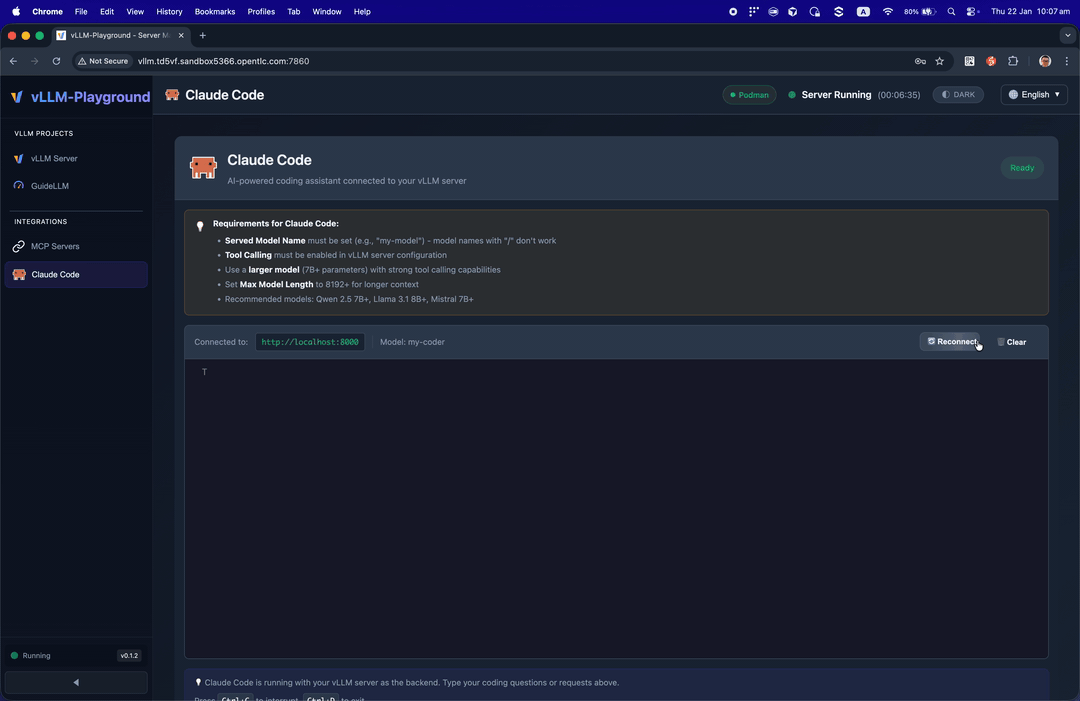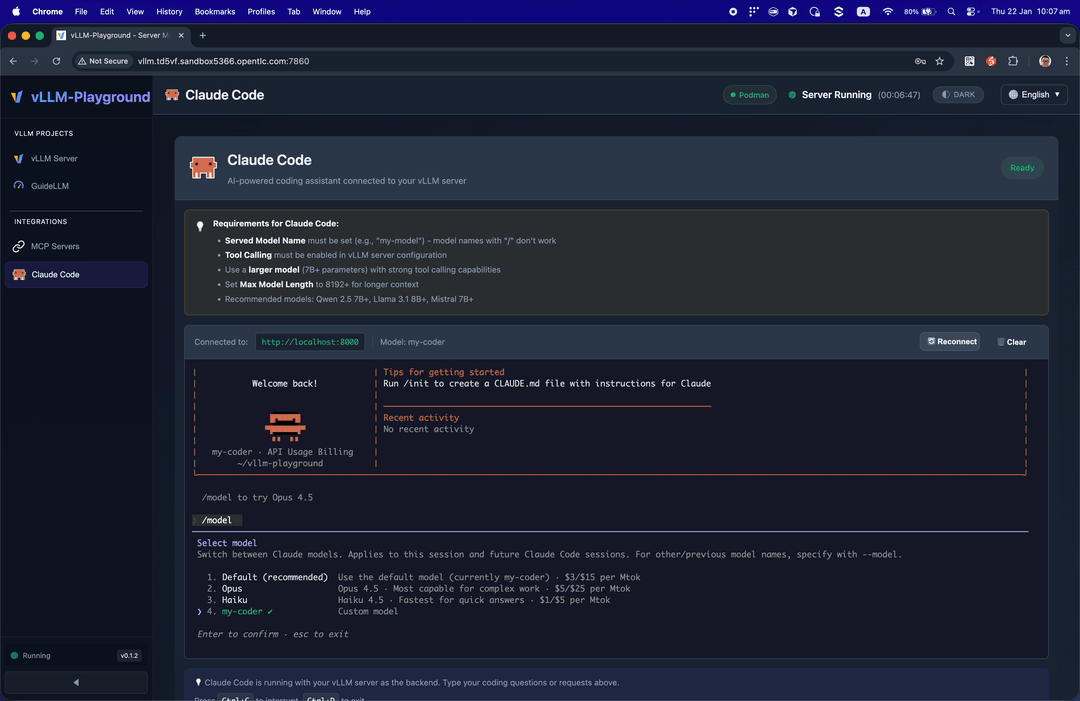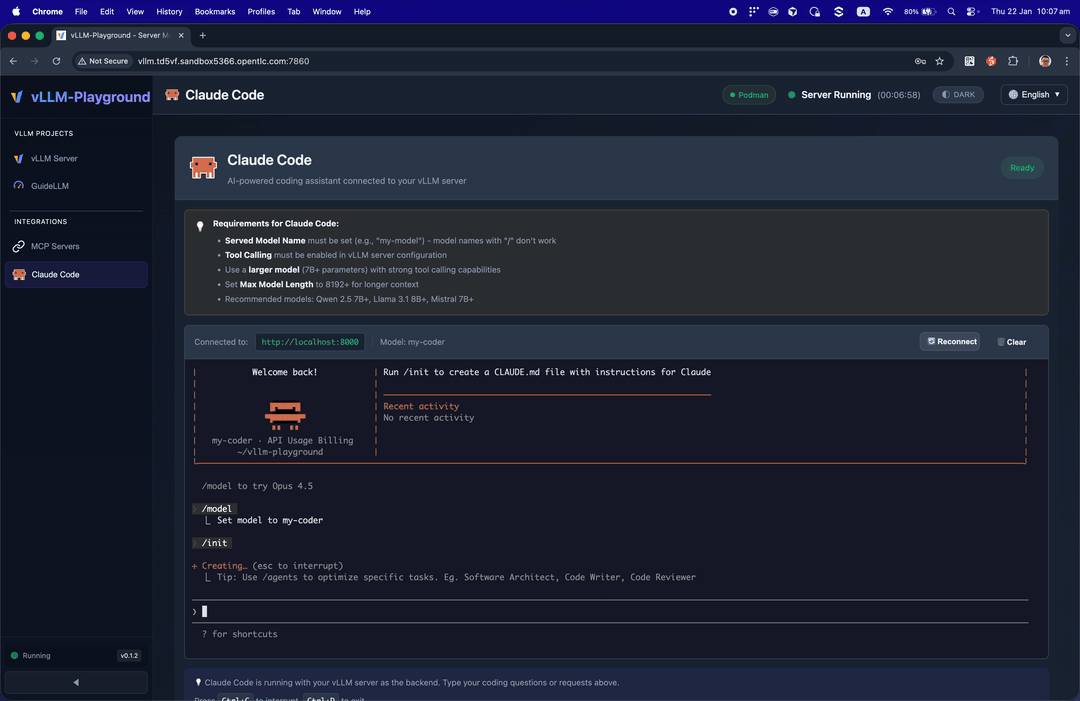
Run Claude Code with open-source models served by vLLM - your private, local coding assistant.
✨ Agentic-Ready with MCP Support
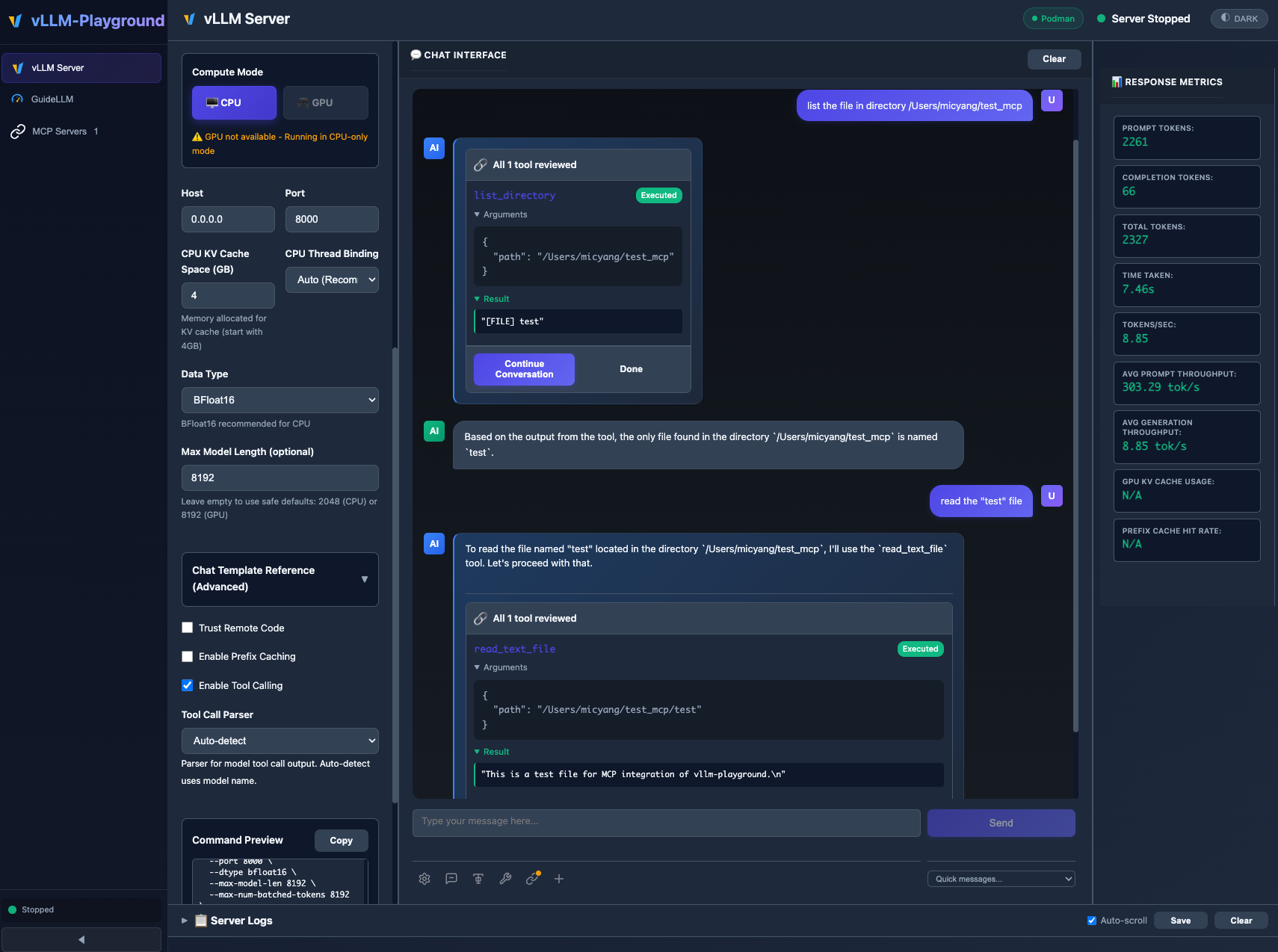
MCP (Model Context Protocol) integration enables models to use external tools with human-in-the-loop approval.
🖼️ VLM (Vision Language Model)
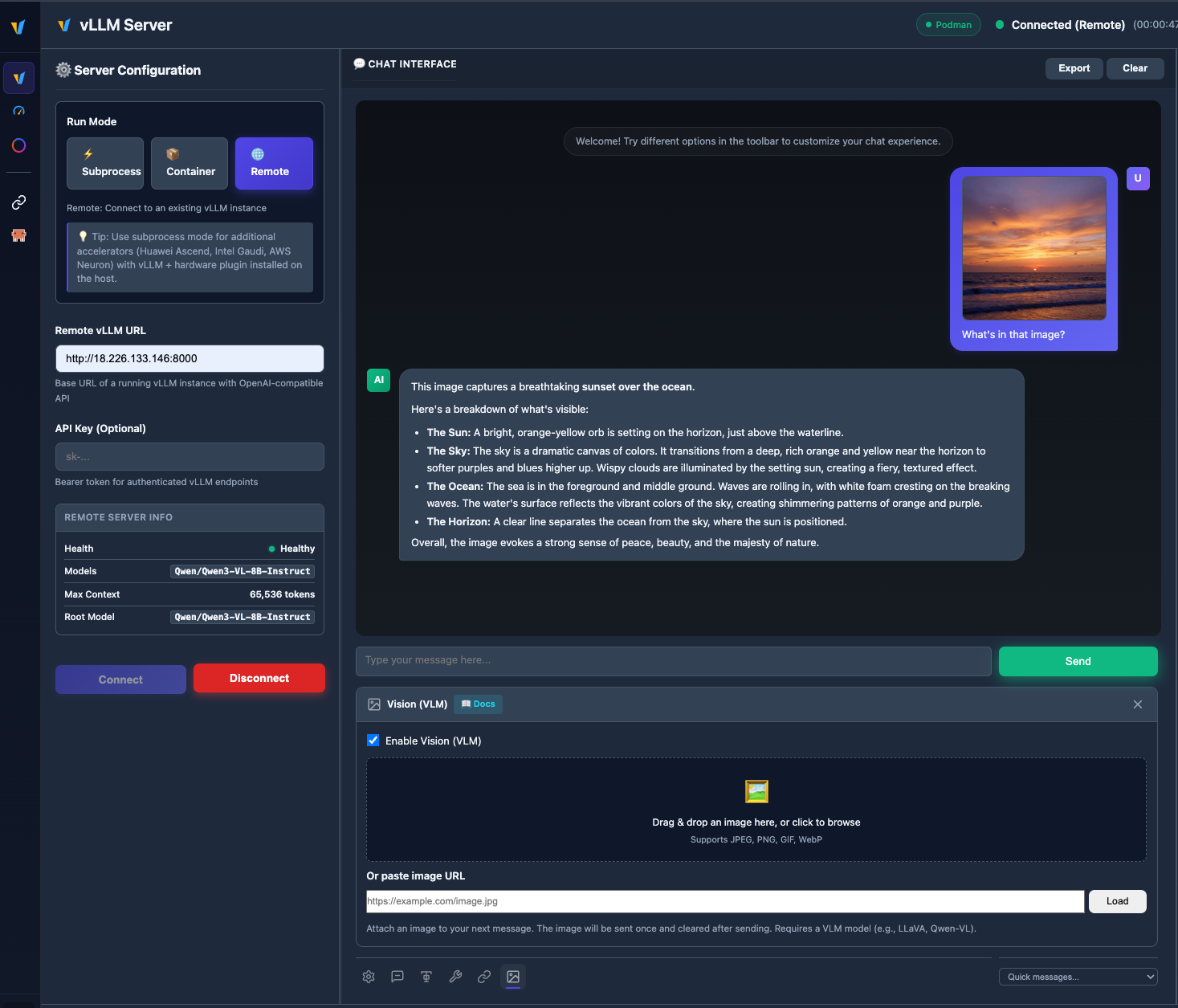
Upload images and chat with vision models like Qwen2.5-VL, LLaVA, and more.
🆕 What's New in v0.1.6
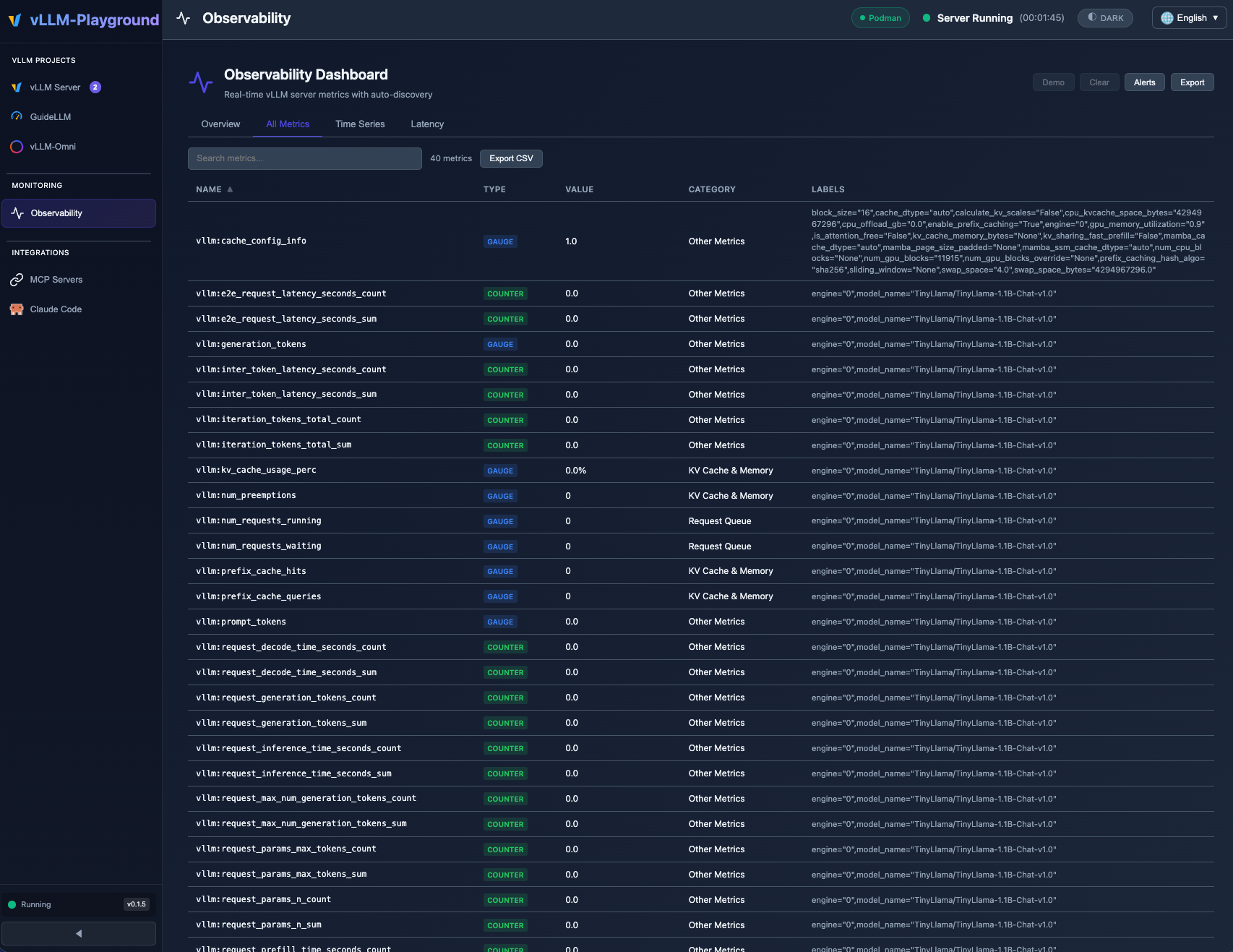
Real-time Observability Dashboard with auto-discovered vLLM metrics, category filtering, and threshold alerts.
- 📊 Observability Dashboard - Full-page metrics dashboard with time-series charts, threshold alerts, and auto-discovery
- 🔍 PagedAttention Visualizer - Real-time KV cache utilization heatmap with eviction alerts
- 🔢 Token Counter & Logprobs - Live token estimation and per-token probability heatmap
- ⚡ Speculative Decoding Dashboard - Acceptance rate, speedup factor, and method configuration
See Changelog for full details.
🚀 Quick Start
# Install from PyPI
pip install vllm-playground
# Pre-download container image (~10GB for GPU)
vllm-playground pull
# Start the playground
vllm-playground
Open http://localhost:7860 and click "Start Server" - that's it! 🎉
CLI Options
vllm-playground pull # Pre-download GPU image (NVIDIA)
vllm-playground pull --nvidia # Pre-download NVIDIA GPU image
vllm-playground pull --amd # Pre-download AMD ROCm image
vllm-playground pull --tpu # Pre-download Google TPU image
vllm-playground pull --cpu # Pre-download CPU image
vllm-playground pull --all # Pre-download all images
vllm-playground --port 8080 # Custom port
vllm-playground stop # Stop running instance
vllm-playground status # Check status
✨ Key Features
| Feature | Description |
|---|---|
| 🌐 Remote Server | Connect to any remote vLLM instance via URL + API key |
| 🖼️ VLM Support | Upload images and chat with vision models (Qwen2.5-VL, LLaVA) |
| 🤖 Claude Code | Use open-source models as Claude Code backend via vLLM |
| 💬 Modern Chat UI | Markdown-rendered chat with streaming responses |
| 🔧 Tool Calling | Function calling with Llama, Mistral, Qwen, and more |
| 🔗 MCP Integration | Connect to MCP servers for agentic capabilities |
| 🏗️ Structured Outputs | Constrain responses to JSON Schema, Regex, or Grammar |
| 🐳 Container Mode | Zero-setup vLLM via automatic container management |
| ☸️ OpenShift/K8s | Enterprise deployment with dynamic pod creation |
| 📊 Benchmarking | GuideLLM integration for load testing |
| 📚 Recipes | One-click configs from vLLM community recipes |
📦 Installation Options
| Method | Command | Best For |
|---|---|---|
| PyPI | pip install vllm-playground |
Most users |
| With Benchmarking | pip install vllm-playground[benchmark] |
Load testing |
| From Source | git clone + python run.py |
Development |
| OpenShift/K8s | ./openshift/deploy.sh |
Enterprise |
📖 See Installation Guide for detailed instructions.
🔧 Configuration
Tool Calling
Enable in Server Configuration before starting:
- Check "Enable Tool Calling"
- Select parser (or "Auto-detect")
- Start server
- Define tools in the 🔧 toolbar panel
Supported Models:
- Llama 3.x (
llama3_json) - Mistral (
mistral) - Qwen (
hermes) - Hermes (
hermes)
Claude Code Integration
Use vLLM to serve open-source models as a backend for Claude Code:
- Go to Claude Code in the sidebar
- Start vLLM with a recommended model (see tips on the page)
- The embedded terminal connects automatically
Requirements:
- vLLM v0.12.0+ (for Anthropic Messages API)
- Model with native 65K+ context and tool calling support
- ttyd installed for web terminal
Recommended Model for most GPUs:
meta-llama/Llama-3.1-8B-Instruct
--max-model-len 65536 --enable-auto-tool-choice --tool-call-parser llama3_json
Note: This integration demonstrates using vLLM as a backend for Claude Code. Claude Code is a separate product by Anthropic - users must install it independently and comply with Anthropic's Commercial Terms of Service. vLLM Playground provides the terminal interface only.
MCP Servers
Connect to external tools via Model Context Protocol:
- Go to MCP Servers in the sidebar
- Add a server (presets available: Filesystem, Git, Fetch, Time)
- Connect and enable in chat panel
⚠️ MCP requires Python 3.10+
CPU Mode (macOS)
Edit config/vllm_cpu.env:
export VLLM_CPU_KVCACHE_SPACE=40
export VLLM_CPU_OMP_THREADS_BIND=auto
Metal GPU Support (macOS Apple Silicon)
vLLM Playground supports Apple Silicon GPU acceleration:
- Install vllm-metal following official instructions
- Configure playground to use Metal:
- Run Mode: Subprocess
- Compute Mode: Metal
- Venv Path:
~/.venv-vllm-metal(or your installation path)
See macOS Metal Guide for details.
Custom vLLM Installations
Use specific vLLM versions or custom builds:
- Install vLLM in a virtual environment
- Configure playground:
- Run Mode: Subprocess
- Venv Path:
/path/to/your/venv
See Custom venv Guide for details.
📖 Documentation
Getting Started
- Installation Guide - All installation methods
- Quick Start - Get running in minutes
- macOS CPU Guide - Apple Silicon CPU setup
- macOS Metal Guide - Apple Silicon GPU acceleration
- Custom venv Guide - Using custom vLLM installations
Features
- Features Overview - Complete feature list
- Gated Models Guide - Access Llama, Gemma, etc.
Deployment
- OpenShift/K8s Deployment - Enterprise deployment
- Architecture Overview - System design
- Container Variants - Container options
Reference
- Troubleshooting - Common issues
- Performance Metrics - Benchmarking
- Command Reference - CLI cheat sheet
Releases
- Changelog - Version history and changes
- v0.1.6 - Observability dashboard, PagedAttention visualizer, token counter, logprobs
- v0.1.5 - Remote server, VLM vision support, markdown rendering
- v0.1.4 - vLLM-Omni multimodal, Studio UI
- v0.1.3 - Multi-accelerators, Claude Code, vLLM-Metal
- v0.1.2 - ModelScope integration, i18n improvements
- v0.1.1 - MCP integration, runtime detection
- v0.1.0 - First release, modern UI, tool calling
🏗️ Architecture
┌──────────────────┐
│ User Browser │
└────────┬─────────┘
│ http://localhost:7860
↓
┌──────────────────┐
│ Web UI (Host) │ ← FastAPI + JavaScript
└────────┬─────────┘
│
┌────┴────┐
↓ ↓
┌───────-─┐ ┌────────┐
│ vLLM │ │ MCP │ ← Containers / External Servers
│Container│ │Servers │
└────────-┘ └────────┘
📖 See Architecture Overview for details.
🆘 Quick Troubleshooting
| Issue | Solution |
|---|---|
| Port in use | vllm-playground stop |
| Container won't start | podman logs vllm-service |
| Tool calling fails | Restart with "Enable Tool Calling" checked |
| Image pull errors | vllm-playground pull --all |
📖 See Troubleshooting Guide for more.
🔗 Related Projects
- vLLM - High-throughput LLM serving
- Claude Code - Anthropic's agentic coding tool
- LLMCompressor Playground - Model compression & quantization
- GuideLLM - Performance benchmarking
- MCP Servers - Official MCP servers
📝 License
Apache 2.0 License - See LICENSE file for details.
🤝 Contributing
Contributions welcome! Please see CONTRIBUTING.md for setup instructions and guidelines.
Made with ❤️ for the vLLM community
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vllm_playground-0.1.6.tar.gz.
File metadata
- Download URL: vllm_playground-0.1.6.tar.gz
- Upload date:
- Size: 9.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8c58908175cb7f720a5a6429a1de51dc36ac69c8262265d827d91ea8209305cc
|
|
| MD5 |
f1806deef45402894a7417558fead551
|
|
| BLAKE2b-256 |
8fe8ed95ddb6394299067033ee4c9d5be34c0a0deafd5a0686337208894ffd1e
|
File details
Details for the file vllm_playground-0.1.6-py3-none-any.whl.
File metadata
- Download URL: vllm_playground-0.1.6-py3-none-any.whl
- Upload date:
- Size: 9.2 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f8ae7a715ce4e82f7de8a6df3763e69d5bcdad09584ff75555fdb3b603c4cbb5
|
|
| MD5 |
b3a69c717d0cb6d863703c4a6108ac13
|
|
| BLAKE2b-256 |
1bc18b814c296cc0d1329fc0570cf198073c9510852b8d2b7272f0af002753a7
|







