This package is written for the restoration of degraded speech

Project description
VoiceFixer
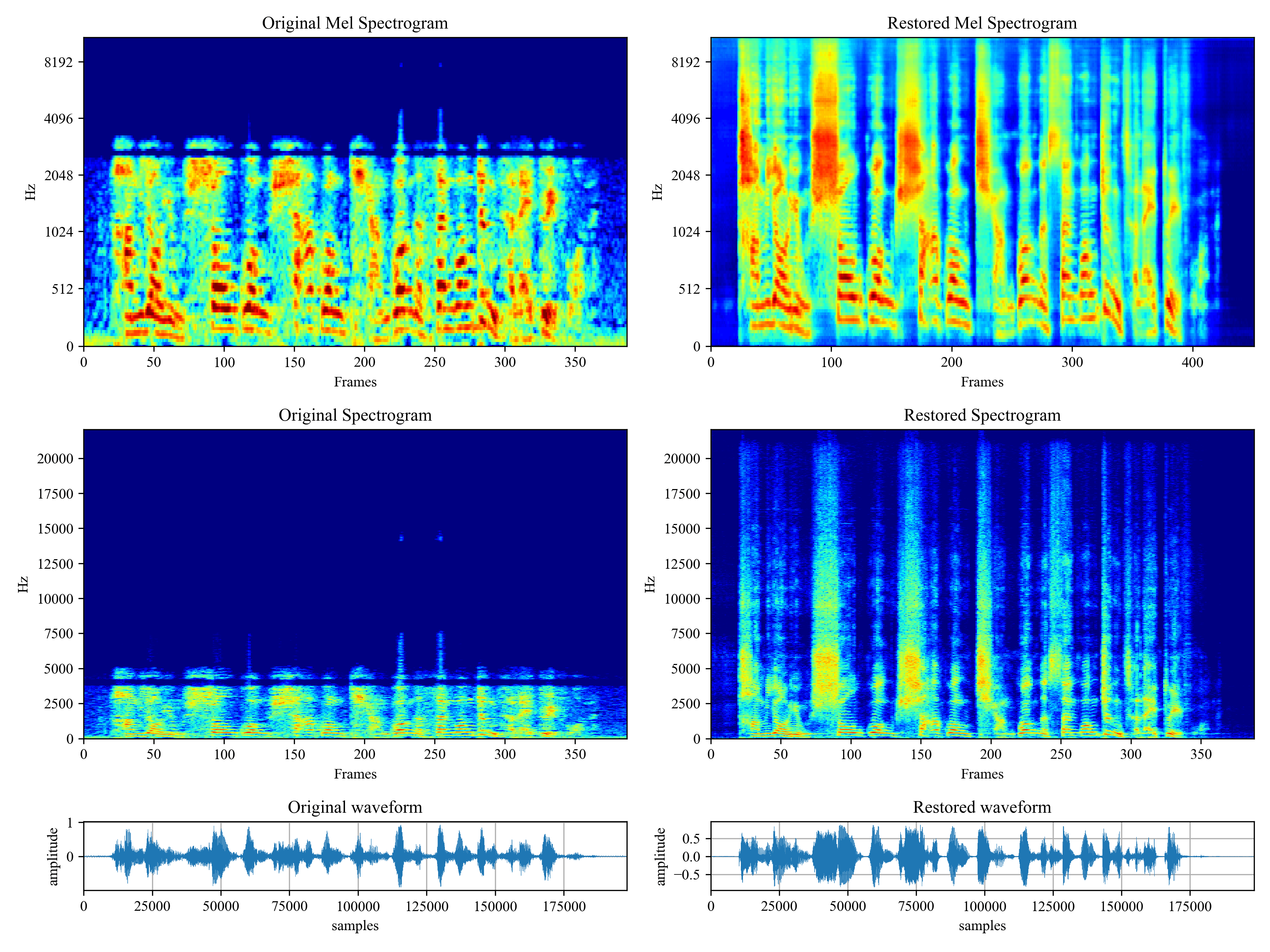
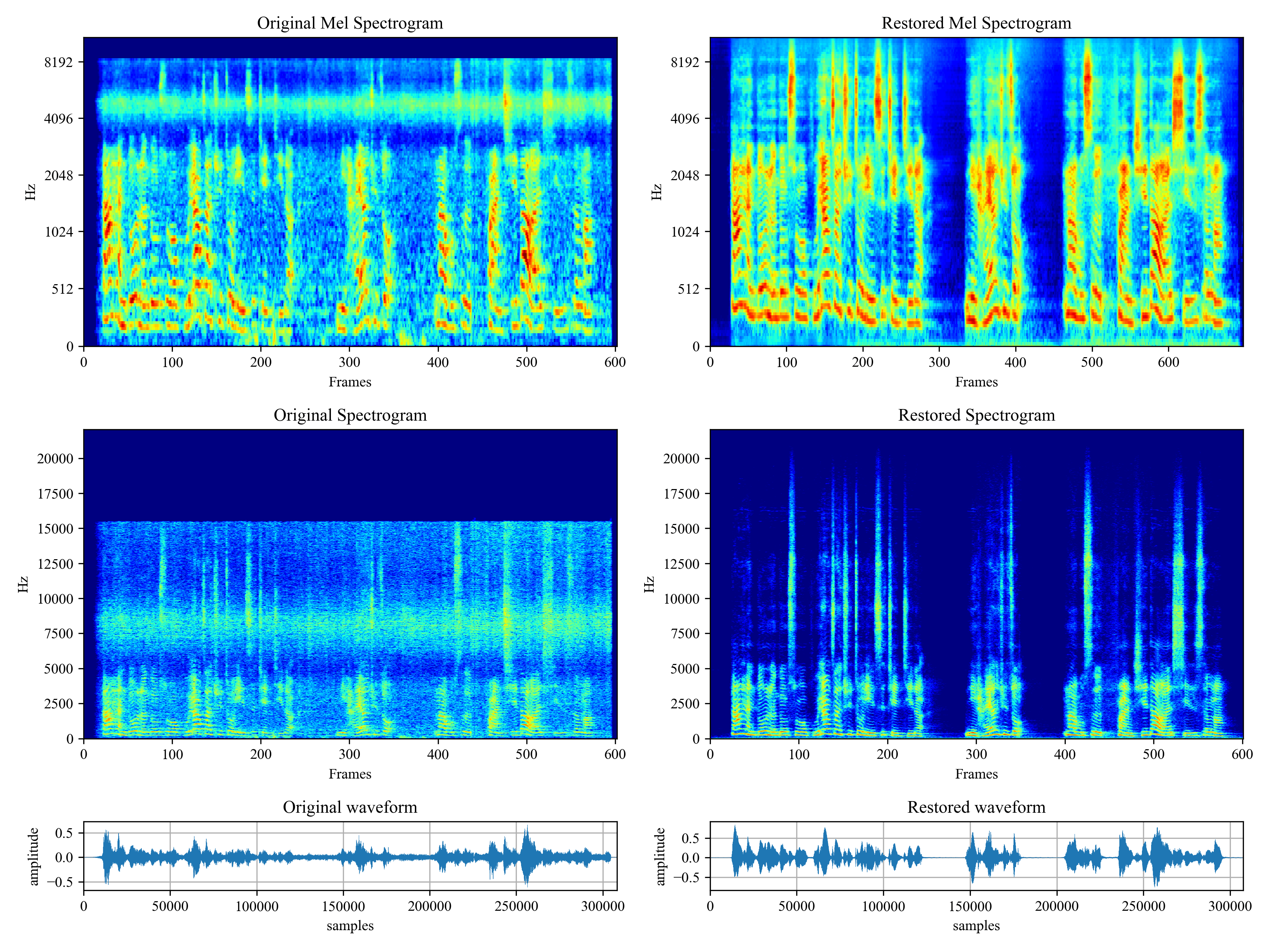
Voicefixer aims at the restoration of human speech regardless how serious its degraded. It can handle noise, reveberation, low resolution (2kHz~44.1kHz) and clipping (0.1-1.0 threshold) effect within one model.
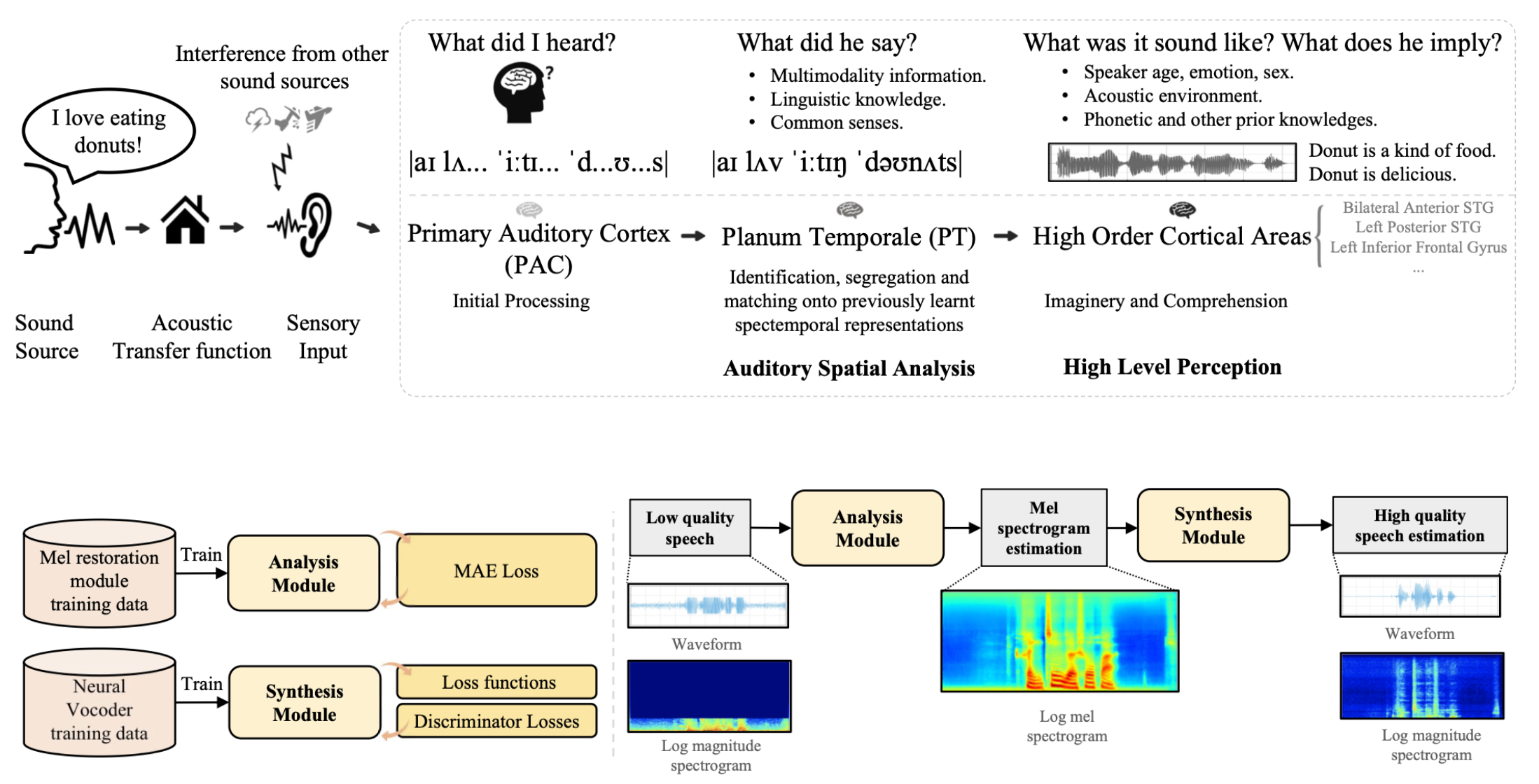
Usage
from voicefixer import VoiceFixer
voicefixer = VoiceFixer()
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0) # You can try out mode 0, 1 to find out the best result
from voicefixer import Vocoder
# Universal Speaker Independent Vocoder
vocoder = Vocoder(sample_rate=44100) # only support 44100 sample rate
vocoder.oracle(fpath="", # input wav file path
out_path="") # output wav file path
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
voicefixer-0.0.6.tar.gz
(34.7 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file voicefixer-0.0.6.tar.gz.
File metadata
- Download URL: voicefixer-0.0.6.tar.gz
- Upload date:
- Size: 34.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.8.1 pkginfo/1.7.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.2 CPython/3.7.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a7225e94a2f042e04803d67f377c7423aca82f01bcec7e98c1f30fafe57a5dfc
|
|
| MD5 |
bcced519ee8d58884a94670d9cde32a3
|
|
| BLAKE2b-256 |
8051776fb64c2698de30c0343bb9460a4f1f04536fa15291d69f3cd5e408c1cd
|
File details
Details for the file voicefixer-0.0.6-py3-none-any.whl.
File metadata
- Download URL: voicefixer-0.0.6-py3-none-any.whl
- Upload date:
- Size: 41.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.8.1 pkginfo/1.7.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.2 CPython/3.7.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0f44f8a5b38d9f2a5ececa0d431c29ca9ed878d63491dfff9267744ee2f61259
|
|
| MD5 |
fd6ed978e79ef31f45be0f4aa067c8ae
|
|
| BLAKE2b-256 |
71d714b292d22f786de872a32ec94919f9865e5c94c25847b137286c08b02bbd
|







