Aggregator tool for multiple Amplicon Architect outputs




Project description
Amplicon Suite Aggregator
Description
Aggregates the results from AmpliconSuite
- Takes in zip files (completed results of individual or grouped Amplicon Suite runs)
- Aggregates results
- Packages results into a new file
- Outputs an aggregated .html and .csv file of results.
- Result file (in .tar.gz) is the aggregated results of all individual AmpliconSutie runs. It can be directly loaded onto AmpliconRepository.
- Can also take additional files along with the upload, provided the directory they are in contains a file named
AUX_DIR.
Parameters available on GenePattern Server
- Available at: https://genepattern.ucsd.edu/gp/pages/index.jsf?lsid=urn:lsid:genepattern.org:module.analysis:00429:4.1
- Amplicon Architect Results (required)
- Compressed (.tar.gz, .zip) files of the results from individual or grouped Amplicon Architect runs.
- project_name (required)
- Prefix for output .tar.gz. Result will be named: output_prefix.tar.gz
- Amplicon Repository Email
- If wanting to directly transfer results to AmpliconRepository.org, please enter your email.
- run amplicon classifier
- Option for users to re-run Amplicon Classifier.
- reference genome
- Reference genome used for Amplicon Architect results in the input.
- upload only
- If 'Yes', then skip aggregation / classification and upload file to AmpliconRepository as is.
- name map
- A two column file providing the current identifier for each sample (col 1) and a replacement name (col 2). Enables batch renaming of samples.
Installation
- Option 1: Git Clone
- Step 1:
git clone https://github.com/genepattern/AmpliconSuiteAggregator.git - Step 2: Install python package dependencies from list below.
- If running into dependency issues, please use the docker methods.
- Step 1:
- Option 2: Docker
- Step 1:
docker pull genepattern/amplicon-suite-aggregator
- Step 1:
Dependencies
- List of python package dependencies used: intervaltree, matplotlib, numpy, pandas, Pillow, requests, scipy, urllib3
Options when running locally
Amplicon Suite Aggregator related options
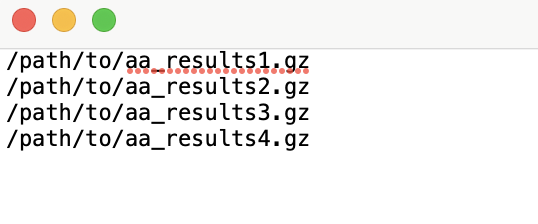
-flist/--filelist: Text file with files to use (one per line)-
Create an
input_list.txtfile in this format where each line is a filepath to compressed aa_results: -
Use this file as the input to the
-flistflag.
-
--files: List of files or directories to use. Can specify multiple paths of (.tar.gz, .zip) of Amplicon Architect results.-o/--output_name: Output Prefix. Will be used as project name for Amplicon Repository upload.--name_map: A two column file providing the current identifier for each sample (col 1) and a replacement name (col 2). Enables batch renaming of samples.-c/--run_classifier(Yes, No): If 'Yes', then run Amplicon Classifier on AA samples. If Amplicon Classifier results are already included in inputs, then they will be removed and samples will be re-classified.--ref(hg19, GRCh37, GRCh38, GRCh38_viral, mm10): Reference genome name used for alignment, one of hg19, GRCh37, GRCh38, GRCh38_viral, or mm10.
AmpliconRepository related options
-u/--username: Email address for Amplicon Repository. If specified, will trigger an attempt to upload the aggregated file to AmpliconRepository.org.--upload_only(Yes, No): If 'Yes', then skip aggregation / classification and upload file to AmpliconRepository as is.-s/--server(dev, prod, local-debug): Which server to send results to. Accepts 'dev' or 'prod' or 'local-debug'. 'prod' is what most users want. 'dev' and 'local-debug' are for development and debugging.
How to run
-
If using local CLI:
- Running aggregator:
python3 /path/to/AmpliconSuiteAggregator/path/src/AmpliconSuiteAggregator.py **options** - Using API to upload directly to AmpliconRepository without aggregation:
python3 /path/to/AmpliconSuiteAggregator/path/src/AmpliconSuiteAggregator.py --files /path/to/aggregated/file.tar.gz -o projname -u your.amplicon.repository.username@gmail.com --upload_only Yes -s prod- Log into Amplicon Repository, you should see a new project with the output prefix you specified.
- Running aggregator:
-
If using Docker:
- To Running aggregator:
docker run --rm -it -v PATH/TO/INPUTS/FOLDER:/inputs/ genepattern/amplicon-suite-aggregator python3 /opt/genepatt/AmpliconSuiteAggregator.py **options**
- Using API to upload directly to AmpliconRepository without aggregation:
docker run --rm -it -v PATH/TO/INPUTS/FOLDER:/inputs/ genepattern/amplicon-suite-aggregator python3 /opt/genepatt/AmpliconSuiteAggregator.py -flist /path/to/input_list.txt -u YOUR_AMPLICON_REPOSITORY_EMAIL -o projname -u your.amplicon.repository.username@gmail.com --upload_only Yes -s prod- Log into Amplicon Repository, you should see a new project with the output prefix you specified.
- To Running aggregator:
Programming Language
- Python
Contact
For any issues
- Edwin Huang, edh021@cloud.ucsd.edu
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
ampliconsuiteaggregator-2.tar.gz
(24.2 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ampliconsuiteaggregator-2.tar.gz.
File metadata
- Download URL: ampliconsuiteaggregator-2.tar.gz
- Upload date:
- Size: 24.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.10.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6e2a1d362d3233e6ee79692c64d593d8498e45268ba9c9a063773b4ea45edd03
|
|
| MD5 |
d541971013ab6daf8edcd27e62775770
|
|
| BLAKE2b-256 |
c717c2858dea4bc726b4a677ccd019bd4aa25f646c93ca4e1e2bf84d36d6c4d6
|
File details
Details for the file AmpliconSuiteAggregator-2-py3-none-any.whl.
File metadata
- Download URL: AmpliconSuiteAggregator-2-py3-none-any.whl
- Upload date:
- Size: 26.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.10.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
53a03d56bb752ab52ba050b6dd9ca91b6b6825ac31b9360f4243b047b1091ebf
|
|
| MD5 |
b48f58019bb37043bc6fd1446728f0e1
|
|
| BLAKE2b-256 |
7ea6cd4fae4a2ed376462b5a8950c45f868efd1f1bcafd2396c5757321020849
|







