Generated from aind-library-template

Project description
aind-analysis-arch-result-access






APIs to access analysis results in the AIND behavior pipeline.
Installation
pip install aind-analysis-arch-result-access
Usage
Try the demo:

See the demo notebook for comprehensive examples.
Fetch dynamic foraging MLE model fitting results
New: Now supports both the AIND Analysis Framework and Han's original pipeline with full backward compatibility.
from aind_analysis_arch_result_access import get_mle_model_fitting
# Get MLE fitting results for a specific session
df = get_mle_model_fitting(
subject_id="730945",
session_date="2024-10-24"
)
print(df.columns)
# Index(['_id', 'nwb_name', 'session_date', 'status', 'subject_id',
# 'analysis_time', 'agent_alias', 'n_trials', 'log_likelihood',
# 'prediction_accuracy', 'k_model', 'AIC', 'BIC', 'LPT', 'LPT_AIC',
# 'LPT_BIC', 'params', 'prediction_accuracy_test',
# 'prediction_accuracy_fit', 'prediction_accuracy_test_bias_only',
# 'pipeline_source', 'S3_location', 'latent_variables', 'qvalue_spread'],
# dtype='object')
print(df[["agent_alias", "n_trials", "AIC", "pipeline_source"]])
# agent_alias n_trials AIC pipeline_source
# 0 QLearning_L1F0_CKfull_softmax 394 241.922187 han's analysis pipeline
# 1 QLearning_L1F1_CKfull_softmax 394 238.848589 han's analysis pipeline
# 2 ForagingCompareThreshold 394 242.957376 han's analysis pipeline
# ...
Control which pipeline version to fetch
By default, only the most recent analysis version is returned (prefers AIND Framework if available):
# Default: only fetch the most recent version
df = get_mle_model_fitting(
subject_id="778869",
session_date="2025-07-26",
only_recent_version=True # default
)
# Found 8 records in AIND Analysis Framework
# Found 12 records in Han's prototype analysis pipeline
# Total: 20 MLE fitting records!
# --- After filtering for successful fittings: 14 records (6 skipped) ---
# --- After filtering for most recent versions: 8 records ---
# AIND Analysis Framework: 8
# Han's prototype analysis pipeline: 0
To get results from both pipelines:
# Get all versions from both pipelines
df = get_mle_model_fitting(
subject_id="778869",
session_date="2025-07-26",
only_recent_version=False
)
# Found 8 records in AIND Analysis Framework
# Found 12 records in Han's prototype analysis pipeline
# Total: 20 MLE fitting records!
# --- After filtering for successful fittings: 14 records (6 skipped) ---
# WARNING: Duplicated records for the same session and agent_alias!
# You should check the nwb_name, n_trials, or pipeline_source
# to select the ones you want.
Filter by agent/model
# Get all sessions for a specific model
df = get_mle_model_fitting(
subject_id="730945",
agent_alias="QLearning_L2F1_CK1_softmax"
)
Download figures
df = get_mle_model_fitting(
subject_id="730945",
session_date="2024-10-24",
if_download_figures=True,
download_path="./mle_figures"
)
Example figure:
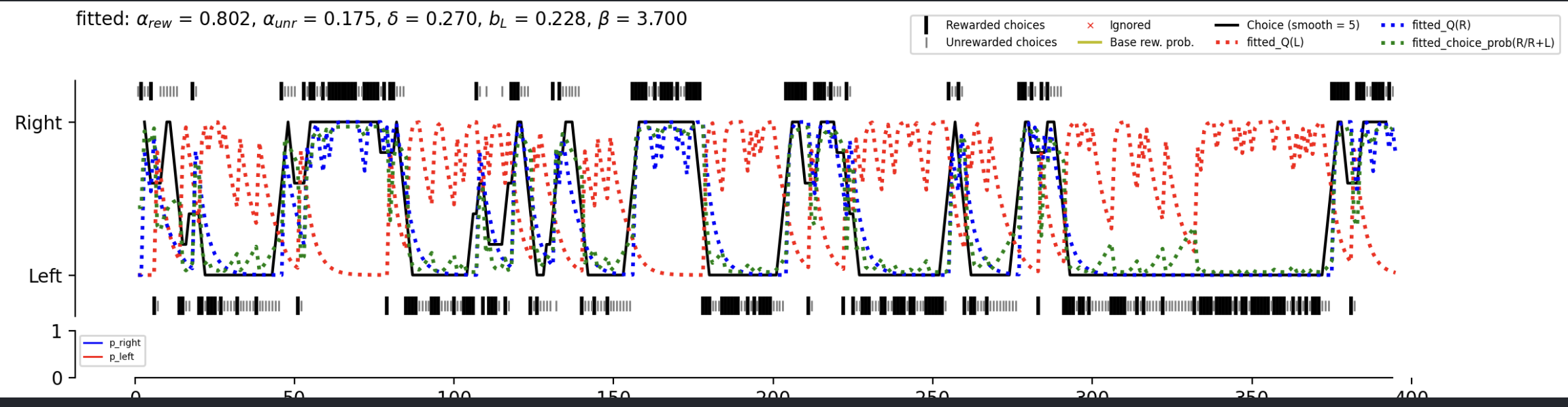
Advanced: Custom queries
df = get_mle_model_fitting(
from_custom_query={
"analysis_results.fit_settings.agent_alias": "QLearning_L2F1_CK1_softmax",
"analysis_results.n_trials": {"$gt": 600},
},
if_include_latent_variables=False
)
print(df.shape)
# (807, 22)
Access Han's pipeline utilities
Access Han's pipeline utilities
Fetch the session master table in Streamlit
from aind_analysis_arch_result_access.han_pipeline import get_session_table
df_master = get_session_table(if_load_bpod=False) # `if_load_bpod=True` will load additional 4000+ old sessions from bpod
# Get only recent sessions
df_recent = get_session_table(if_load_bpod=False, only_recent_n_month=6) # Last 6 months
Fetch logistic regression results
Get logistic regression results from one session:
from aind_analysis_arch_result_access.han_pipeline import get_logistic_regression
import pandas as pd
df_logistic = get_logistic_regression(
df_sessions=pd.DataFrame({
"subject_id": ["769253"],
"session_date": ["2025-03-12"],
}),
model="Su2022",
)
Get logistic regression results in batch:
df_logistic = get_logistic_regression(
df_master.query("subject_id == '769253'"), # All sessions from a single subject
model="Su2022",
if_download_figures=True, # Also download fitting plots
download_path="./tmp",
)
Fetch trial table (🚧 under development)
Fetch analysis figures (🚧 under development)
Contributing
Installation
To use the software, in the root directory, run
pip install -e .
To develop the code, run
pip install -e .[dev]
Linters and testing
There are several libraries used to run linters, check documentation, and run tests.
- Please test your changes using the coverage library, which will run the tests and log a coverage report:
coverage run -m unittest discover && coverage report
- Use interrogate to check that modules, methods, etc. have been documented thoroughly:
interrogate .
- Use flake8 to check that code is up to standards (no unused imports, etc.):
flake8 .
- Use black to automatically format the code into PEP standards:
black .
- Use isort to automatically sort import statements:
isort .
Pull requests
For internal members, please create a branch. For external members, please fork the repository and open a pull request from the fork. We'll primarily use Angular style for commit messages. Roughly, they should follow the pattern:
<type>(<scope>): <short summary>
where scope (optional) describes the packages affected by the code changes and type (mandatory) is one of:
- build: Changes that affect build tools or external dependencies (example scopes: pyproject.toml, setup.py)
- ci: Changes to our CI configuration files and scripts (examples: .github/workflows/ci.yml)
- docs: Documentation only changes
- feat: A new feature
- fix: A bugfix
- perf: A code change that improves performance
- refactor: A code change that neither fixes a bug nor adds a feature
- test: Adding missing tests or correcting existing tests
Semantic Release
The table below, from semantic release, shows which commit message gets you which release type when semantic-release runs (using the default configuration):
| Commit message | Release type |
|---|---|
fix(pencil): stop graphite breaking when too much pressure applied |
|
feat(pencil): add 'graphiteWidth' option |
|
perf(pencil): remove graphiteWidth optionBREAKING CHANGE: The graphiteWidth option has been removed.The default graphite width of 10mm is always used for performance reasons. |
(Note that the BREAKING CHANGE: token must be in the footer of the commit) |
Documentation
To generate the rst files source files for documentation, run
sphinx-apidoc -o docs/source/ src
Then to create the documentation HTML files, run
sphinx-build -b html docs/source/ docs/build/html
More info on sphinx installation can be found here.
Read the Docs Deployment
Note: Private repositories require Read the Docs for Business account. The following instructions are for a public repo.
The following are required to import and build documentations on Read the Docs:
- A Read the Docs user account connected to Github. See here for more details.
- Read the Docs needs elevated permissions to perform certain operations that ensure that the workflow is as smooth as possible, like installing webhooks. If you are not the owner of the repo, you may have to request elevated permissions from the owner/admin.
- A .readthedocs.yaml file in the root directory of the repo. Here is a basic template:
# Read the Docs configuration file
# See https://docs.readthedocs.io/en/stable/config-file/v2.html for details
# Required
version: 2
# Set the OS, Python version, and other tools you might need
build:
os: ubuntu-24.04
tools:
python: "3.13"
# Path to a Sphinx configuration file.
sphinx:
configuration: docs/source/conf.py
# Declare the Python requirements required to build your documentation
python:
install:
- method: pip
path: .
extra_requirements:
- dev
Here are the steps for building docs in Read the Docs. See here for detailed instructions:
- From Read the Docs dashboard, click on Add project.
- For automatic configuration, select Configure automatically and type the name of the repo. A repo with public visibility should appear as you type.
- Follow the subsequent steps.
- For manual configuration, select Configure manually and follow the subsequent steps
Once a project is created successfully, you will be able to configure/modify the project's settings; such as Default version, Default branch etc.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file aind_analysis_arch_result_access-1.1.2.tar.gz.
File metadata
- Download URL: aind_analysis_arch_result_access-1.1.2.tar.gz
- Upload date:
- Size: 291.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c672da289ffa0217a2e7abd5b6bee123351b2650f4ef438e9f435b97f67506c4
|
|
| MD5 |
c132748337b7c5a938c22fdfdfd41987
|
|
| BLAKE2b-256 |
fbb839b8ce1492328b533d6c5b6995c03eecef2fc9606d7c0941f22affc6a6dd
|
File details
Details for the file aind_analysis_arch_result_access-1.1.2-py3-none-any.whl.
File metadata
- Download URL: aind_analysis_arch_result_access-1.1.2-py3-none-any.whl
- Upload date:
- Size: 25.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
847c8179dd990d3a13bed8ec4c49c91ff5659252a97f47d9e80424eb56f07488
|
|
| MD5 |
706a841f9e991c78620f03641fa4bfbd
|
|
| BLAKE2b-256 |
2e6d12099a1c1ed4f493cadc01b57ee28c10c888c73c3aa64c9313e342430106
|







