AI-powered expense analysis and RAG system with CockroachDB vector search and multi-provider AI support (OpenAI, AWS Bedrock, IBM Watsonx, Google Gemini)

Project description




🤖 Banko AI Assistant - RAG Demo
A modern AI-powered expense analysis application with Retrieval-Augmented Generation (RAG) capabilities, built with CockroachDB vector search and multiple AI provider support.
✨ Features
- 🔍 Advanced Vector Search: Enhanced expense search using CockroachDB vector indexes
- 🤖 Multi-AI Provider Support: OpenAI, AWS Bedrock, IBM Watsonx, Google Gemini
- 🔄 Dynamic Model Switching: Switch between models without restarting the app
- 👤 User-Specific Indexing: User-based vector indexes with regional partitioning
- 📊 Data Enrichment: Contextual expense descriptions for better search accuracy
- 💾 Intelligent Caching: Multi-layer caching system for optimal performance
- 🌐 Modern Web Interface: Clean, responsive UI with real-time chat
- 📈 Analytics Dashboard: Comprehensive expense analysis and insights
- 📦 PyPI Package: Easy installation with
pip install banko-ai-assistant - 🎯 Enhanced Context: Merchant and amount information included in search context
- ⚡ Performance Optimized: User-specific vector indexes for faster queries
🚀 Quick Start
Prerequisites
- Python 3.8+
- CockroachDB v25.2.4+ (recommended: v25.3.3)
- Vector Index Feature Enabled (required for vector search)
- AI Provider API Key (OpenAI, AWS, IBM Watsonx, or Google Gemini)
CockroachDB Setup
-
Download and Install CockroachDB:
# Download CockroachDB v25.3.3 (recommended) # Visit: https://www.cockroachlabs.com/docs/releases/v25.3#v25-3-3 # Or install via package manager brew install cockroachdb/tap/cockroach # macOS
-
Start CockroachDB Single Node:
# Start a single-node cluster (for development) cockroach start-single-node \ --insecure \ --store=./cockroach-data \ --listen-addr=localhost:26257 \ --http-addr=localhost:8080 \ --background
-
Enable Vector Index Feature:
-- Connect to the database cockroach sql --url="cockroachdb://root@localhost:26257/defaultdb?sslmode=disable" -- Enable vector index feature (required for vector search) SET CLUSTER SETTING feature.vector_index.enabled = true;
-
Verify Setup:
-- Check if vector index is enabled SHOW CLUSTER SETTING feature.vector_index.enabled; -- Should return: true
Installation
Option 1: PyPI Installation (Recommended)
# Install from PyPI
pip install banko-ai-assistant
# Set up environment variables (example with OpenAI)
export AI_SERVICE="openai"
export OPENAI_API_KEY="your_openai_api_key_here"
export OPENAI_MODEL="gpt-4o-mini"
export DATABASE_URL="cockroachdb://root@localhost:26257/defaultdb?sslmode=disable"
# Run the application
banko-ai run
Option 2: Development Installation
# Clone the repository
git clone https://github.com/cockroachlabs-field/banko-ai-assistant-rag-demo
cd banko-ai-assistant-rag-demo
# Install the package in development mode
pip install -e .
# Run the application
banko-ai run
Option 3: Direct Dependencies
# Install dependencies from pyproject.toml
pip install -e .
# Run the application
banko-ai run
📋 Environment Variables Reference
Quick reference for all configurable environment variables:
Core Configuration (Required)
| Variable | Description | Default | Example |
|---|---|---|---|
DATABASE_URL |
CockroachDB connection string | None | cockroachdb://root@localhost:26257/banko_ai |
AI_SERVICE |
AI provider to use | None | watsonx, openai, aws, gemini |
AI Provider Configuration
IBM Watsonx
| Variable | Description | Default |
|---|---|---|
WATSONX_API_KEY |
IBM Cloud API key | None |
WATSONX_PROJECT_ID |
Watsonx project ID | None |
WATSONX_MODEL_ID |
Model to use | openai/gpt-oss-120b |
WATSONX_API_URL |
API endpoint URL | US South region |
WATSONX_TOKEN_URL |
IAM token endpoint | IBM Cloud IAM |
WATSONX_TIMEOUT |
Request timeout (seconds) | 30 |
OpenAI
| Variable | Description | Default |
|---|---|---|
OPENAI_API_KEY |
OpenAI API key | None |
OPENAI_MODEL |
Model to use | gpt-4o-mini |
AWS Bedrock
| Variable | Description | Default |
|---|---|---|
AWS_ACCESS_KEY_ID |
AWS access key | None |
AWS_SECRET_ACCESS_KEY |
AWS secret key | None |
AWS_REGION |
AWS region | us-east-1 |
AWS_MODEL_ID |
Model to use | claude-3-5-sonnet |
Google Gemini
| Variable | Description | Default |
|---|---|---|
GOOGLE_APPLICATION_CREDENTIALS |
Service account JSON path | None |
GOOGLE_PROJECT_ID |
Google Cloud project ID | None |
GOOGLE_MODEL |
Model to use | gemini-2.0-flash-001 |
GOOGLE_LOCATION |
Region | us-central1 |
GOOGLE_API_KEY |
API key (fallback) | None |
Response Caching Configuration
| Variable | Description | Default | Range/Options |
|---|---|---|---|
CACHE_SIMILARITY_THRESHOLD |
Query similarity threshold for cache match | 0.75 |
0.0-1.0 |
CACHE_TTL_HOURS |
Cache time-to-live | 24 |
Any positive integer |
CACHE_STRICT_MODE |
Require exact expense data match | true |
true, false |
Caching Presets:
- Demo:
THRESHOLD=0.75 STRICT_MODE=false(80-90% hit rate) - Balanced:
THRESHOLD=0.75 STRICT_MODE=true(60-70% hit rate) ✅ Recommended - Conservative:
THRESHOLD=0.85 STRICT_MODE=true(50-60% hit rate)
Database Connection Pool
| Variable | Description | Default |
|---|---|---|
DB_POOL_SIZE |
Base connection pool size | 100 |
DB_MAX_OVERFLOW |
Max overflow connections | 100 |
DB_POOL_TIMEOUT |
Connection timeout (seconds) | 30 |
DB_POOL_RECYCLE |
Recycle connections after (seconds) | 3600 |
DB_POOL_PRE_PING |
Test connections before use | true |
DB_CONNECT_TIMEOUT |
Database connection timeout (seconds) | 10 |
Additional Configuration
| Variable | Description | Default |
|---|---|---|
EMBEDDING_MODEL |
Sentence transformer model | all-MiniLM-L6-v2 |
FLASK_ENV |
Flask environment | development |
SECRET_KEY |
Flask secret key | Random UUID |
Quick Start Scripts
# Demo mode (aggressive caching, high hit rate)
./start_demo_mode.sh
# Production mode (balanced, data accuracy)
./start_production_mode.sh
Configuration
Required Environment Variables
# Database Connection (Required)
export DATABASE_URL="cockroachdb://root@localhost:26257/defaultdb?sslmode=disable"
# AI Service Selection (Required - choose one)
export AI_SERVICE="watsonx" # Options: watsonx, openai, aws, gemini
AI Provider Configuration (choose based on AI_SERVICE)
IBM Watsonx:
export WATSONX_API_KEY="your_api_key_here"
export WATSONX_PROJECT_ID="your_project_id_here"
export WATSONX_MODEL_ID="meta-llama/llama-2-70b-chat" # Default: openai/gpt-oss-120b
# Optional - Advanced Configuration
export WATSONX_API_URL="https://us-south.ml.cloud.ibm.com/ml/v1/text/chat?version=2023-05-29" # Change region if needed
export WATSONX_TOKEN_URL="https://iam.cloud.ibm.com/identity/token"
export WATSONX_TIMEOUT="30" # Request timeout in seconds (default: 30)
OpenAI:
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_MODEL="gpt-4o-mini" # Default: gpt-4o-mini
# Options: gpt-4o-mini, gpt-4o, gpt-4-turbo, gpt-4, gpt-3.5-turbo
AWS Bedrock:
export AWS_ACCESS_KEY_ID="your_access_key"
export AWS_SECRET_ACCESS_KEY="your_secret_key"
export AWS_REGION="us-east-1" # Default: us-east-1
export AWS_MODEL_ID="us.anthropic.claude-3-5-sonnet-20241022-v2:0" # Default: Claude 3.5 Sonnet
# Options: claude-3-5-sonnet, claude-3-5-haiku, claude-3-opus, claude-3-sonnet
Google Gemini:
export GOOGLE_APPLICATION_CREDENTIALS="path/to/service-account.json"
export GOOGLE_PROJECT_ID="your-google-cloud-project-id"
export GOOGLE_MODEL="gemini-1.5-pro" # Default: gemini-2.0-flash-001
export GOOGLE_LOCATION="us-central1" # Default: us-central1
# Options: gemini-1.5-pro, gemini-1.5-flash, gemini-1.0-pro, gemini-2.0-flash-001
# Alternative: Generative AI API (if Vertex AI unavailable)
export GOOGLE_API_KEY="your-gemini-api-key"
Optional - Global Configuration
# Embedding Model (applies to all AI providers)
export EMBEDDING_MODEL="all-MiniLM-L6-v2" # Default: all-MiniLM-L6-v2
# Options: all-MiniLM-L6-v2, all-mpnet-base-v2, sentence-transformers models
# Flask Configuration
export FLASK_ENV="development" # Options: development, production
export SECRET_KEY="your-random-secret-key" # Generate with: python -c "import secrets; print(secrets.token_hex(32))"
Response Caching Configuration
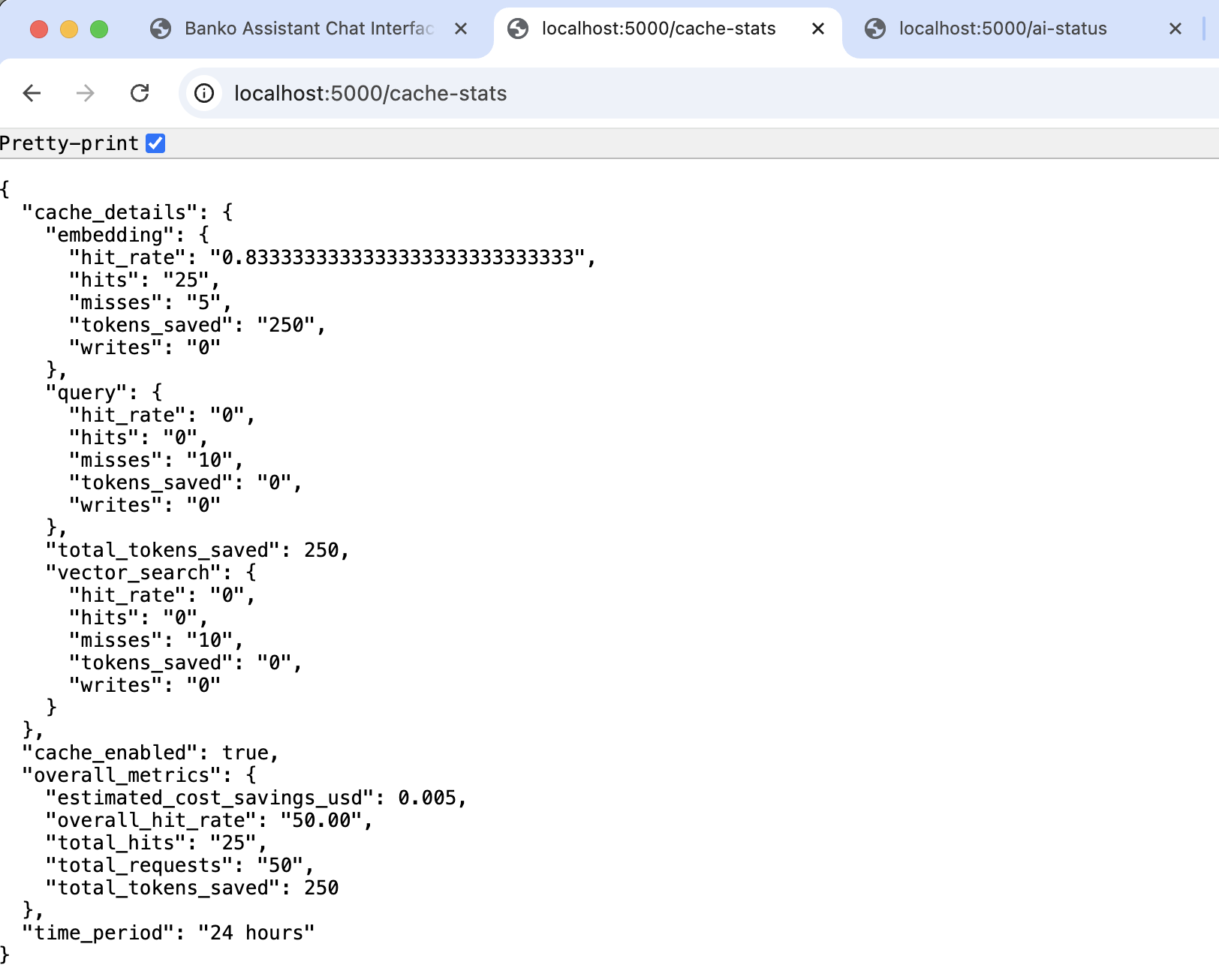
Intelligent caching reduces token usage and improves response times. Configure based on your accuracy vs. efficiency tradeoff:
# Cache Similarity Threshold (how similar queries need to be for cache match)
export CACHE_SIMILARITY_THRESHOLD="0.75" # Default: 0.75 (Range: 0.0-1.0)
# Cache TTL (how long to keep cached responses)
export CACHE_TTL_HOURS="24" # Default: 24 hours
# Cache Strict Mode (require exact expense data match)
export CACHE_STRICT_MODE="true" # Default: true
Caching Strategy:
- High confidence (≥0.90): Exact semantic match - always use cache
- Medium confidence (0.70-0.89): Similar match - use cache if data matches (strict mode)
- Low confidence (<0.70): Different query - generate fresh response
Recommended Settings by Use Case:
# Financial advisory (high accuracy required)
export CACHE_SIMILARITY_THRESHOLD="0.85"
export CACHE_STRICT_MODE="true"
# Customer support chatbot (balanced)
export CACHE_SIMILARITY_THRESHOLD="0.75" # ← Recommended for most cases
export CACHE_STRICT_MODE="true"
# Demo/testing (aggressive caching)
export CACHE_SIMILARITY_THRESHOLD="0.70"
export CACHE_STRICT_MODE="false" # Matches on similarity alone
# High-traffic production (optimize for speed)
export CACHE_SIMILARITY_THRESHOLD="0.80"
export CACHE_STRICT_MODE="true"
export CACHE_TTL_HOURS="48" # Cache longer
Example Scenarios:
| Threshold | Query 1 | Query 2 | Similarity | Cache Hit? |
|---|---|---|---|---|
| 0.75 | "coffee" | "what did i spend on coffee" | 0.69 | ❌ No (below threshold) |
| 0.75 | "coffee expenses" | "my coffee spending" | 0.88 | ✅ Yes (above threshold) |
| 0.85 | "coffee expenses" | "my coffee spending" | 0.88 | ✅ Yes (above threshold) |
| 0.90 | "coffee expenses" | "my coffee spending" | 0.88 | ❌ No (below threshold) |
Tips:
- Lower threshold = more cache hits but less accurate
- Higher threshold = fewer cache hits but more accurate
- Strict mode ensures data consistency at cost of cache efficiency
- Monitor cache hit rate in logs to tune threshold
Database Connection Pool Configuration
Important: Configure pool size based on your workload. CockroachDB can handle many concurrent connections efficiently.
# Connection Pool Settings (all optional with sensible defaults)
export DB_POOL_SIZE="100" # Base pool size (default: 100)
export DB_MAX_OVERFLOW="100" # Max overflow connections (default: 100)
export DB_POOL_TIMEOUT="30" # Timeout waiting for connection in seconds (default: 30)
export DB_POOL_RECYCLE="3600" # Recycle connections after N seconds (default: 3600 = 1 hour)
export DB_POOL_PRE_PING="true" # Test connections before use (default: true)
export DB_CONNECT_TIMEOUT="10" # Database connection timeout in seconds (default: 10)
Pool Size Recommendations:
- Low traffic (< 10 QPS): 10-50 connections
- Medium traffic (10-100 QPS): 100-500 connections
- High traffic (100+ QPS): 500-1000+ connections
- Rule of thumb: Each connection handles ~50-100 requests/second
- Your case (14 QPS): 100+ connections recommended (default is good)
- For 1000+ connections: Increase pool size and overflow accordingly
CockroachDB Best Practices:
- Use
pool_pre_ping=trueto detect stale connections (especially with HAProxy) - Set
pool_recycleto 1 hour (3600s) to handle long-running connections - Monitor pool usage:
engine.pool.checkedout()andengine.pool.overflow() - Increase pool size if you see timeout errors waiting for connections
- CockroachDB handles 1000+ connections per node efficiently
Example Configurations:
For high throughput (1000 connections total):
export DB_POOL_SIZE="500"
export DB_MAX_OVERFLOW="500"
For development (minimal connections):
export DB_POOL_SIZE="10"
export DB_MAX_OVERFLOW="10"
Regional Configuration Examples
Watsonx - EU Region:
export WATSONX_API_URL="https://eu-de.ml.cloud.ibm.com/ml/v1/text/chat?version=2023-05-29"
Watsonx - Tokyo Region:
export WATSONX_API_URL="https://jp-tok.ml.cloud.ibm.com/ml/v1/text/chat?version=2023-05-29"
AWS - Europe:
export AWS_REGION="eu-west-1"
Google - Europe:
export GOOGLE_LOCATION="europe-west1"
Multi-Region CockroachDB with Load Balancer
Standard Production Pattern: In multi-region deployments, use a load balancer (HAProxy, AWS NLB, etc.) in front of CockroachDB nodes. The application connects to the load balancer, which handles:
- Health checking of backend database nodes
- Automatic routing to healthy nodes/regions
- Connection distribution and failover
# Development (local single node)
export DATABASE_URL="cockroachdb://root@localhost:26257/banko_ai?sslmode=disable"
# Production with load balancer (standard pattern)
export DATABASE_URL="cockroachdb://root@haproxy-lb:26257/banko_ai?sslmode=verify-full"
# or
export DATABASE_URL="cockroachdb://root@lb.example.com:26257/banko_ai?sslmode=verify-full"
How Failover Works with Load Balancer:
- Application connects to load balancer (single endpoint)
- Load balancer routes connections to healthy database nodes across regions
- When a region fails, load balancer detects unhealthy nodes via health checks
- Load balancer automatically routes to healthy regions
- Application gets
StatementCompletionUnknownduring failover (transaction state is ambiguous) - Application retry logic (up to 10 retries) handles the ambiguous state
- Retry succeeds via load balancer routing to healthy region
Why This Pattern:
- ✅ Single connection endpoint (simplified application config)
- ✅ Load balancer handles health checking and routing
- ✅ Application doesn't need to know about individual nodes
- ✅ Application retry logic handles transient failures during failover
- ✅ Standard production pattern for multi-region databases
Running the Application
The application automatically creates database tables and loads sample data (5000 records by default):
# Start with default settings (5000 sample records)
banko-ai run
# Start with custom data amount
banko-ai run --generate-data 10000
# Start without generating data
banko-ai run --no-data
# Start with debug mode
banko-ai run --debug
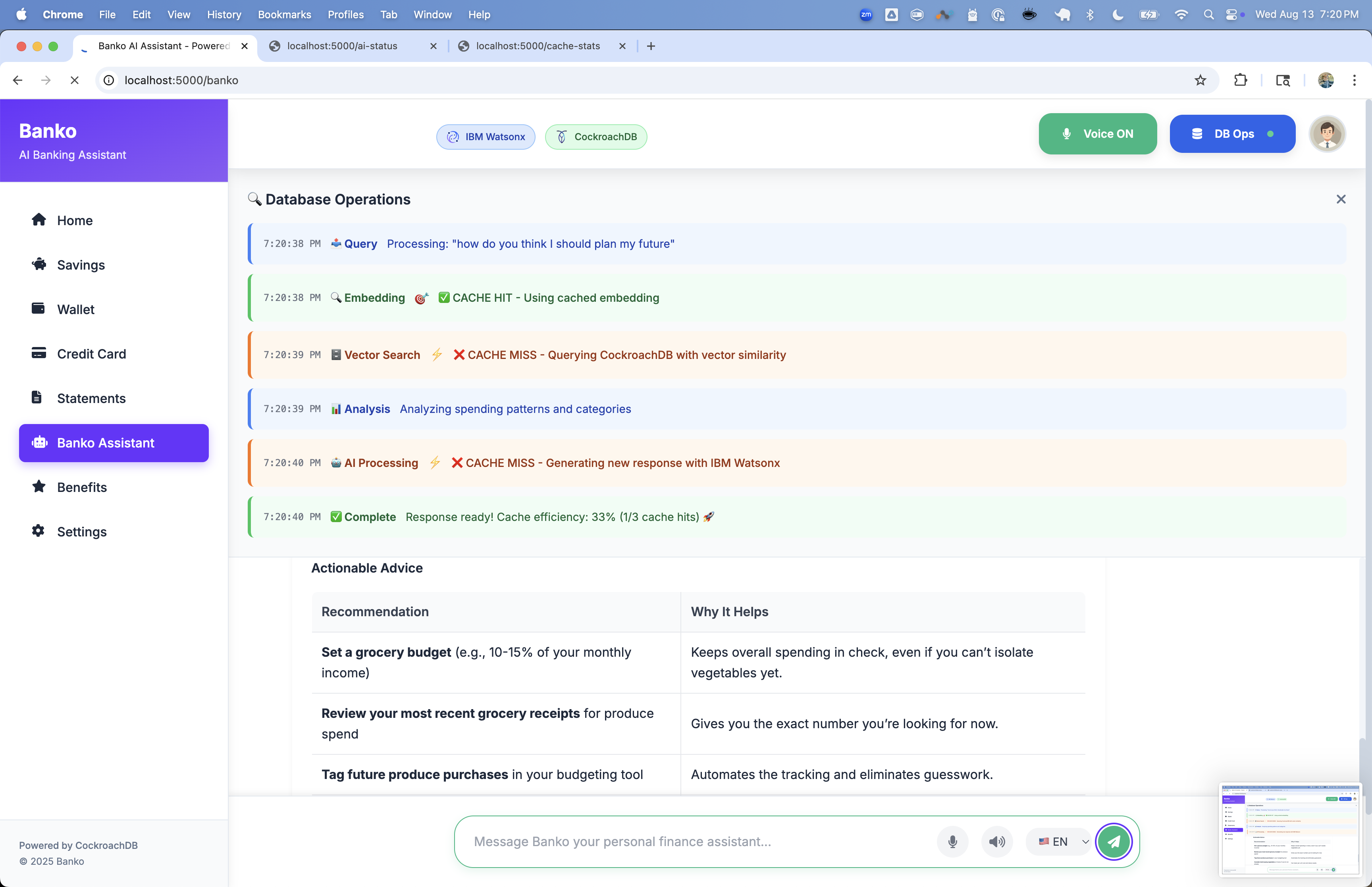
🎯 What Happens on Startup
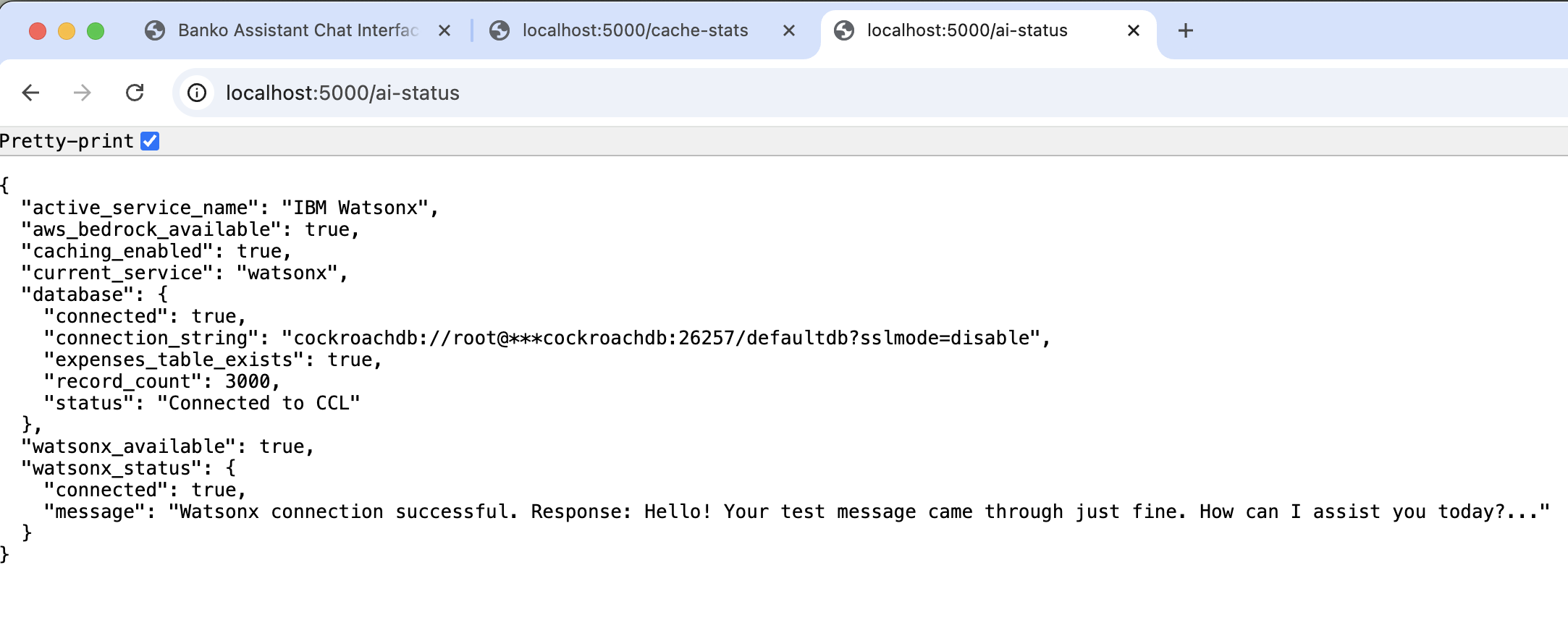
- Database Connection: Connects to CockroachDB and creates necessary tables
- Table Creation: Creates
expensestable with vector indexes and cache tables - Data Generation: Automatically generates 5000 sample expense records with enriched descriptions
- AI Provider Setup: Initializes the selected AI provider and loads available models
- Web Server: Starts the Flask application on http://localhost:5000
📊 Sample Data Features
The generated sample data includes:
- Rich Descriptions: "Bought food delivery at McDonald's for $56.68 fast significant purchase restaurant and service paid with debit card this month"
- Merchant Information: Realistic merchant names and categories
- Amount Context: Expense amounts with contextual descriptions
- Temporal Context: Recent, this week, this month, etc.
- Payment Methods: Bank Transfer, Debit Card, Credit Card, Cash, Check
- User-Specific Data: Multiple user IDs for testing user-specific search
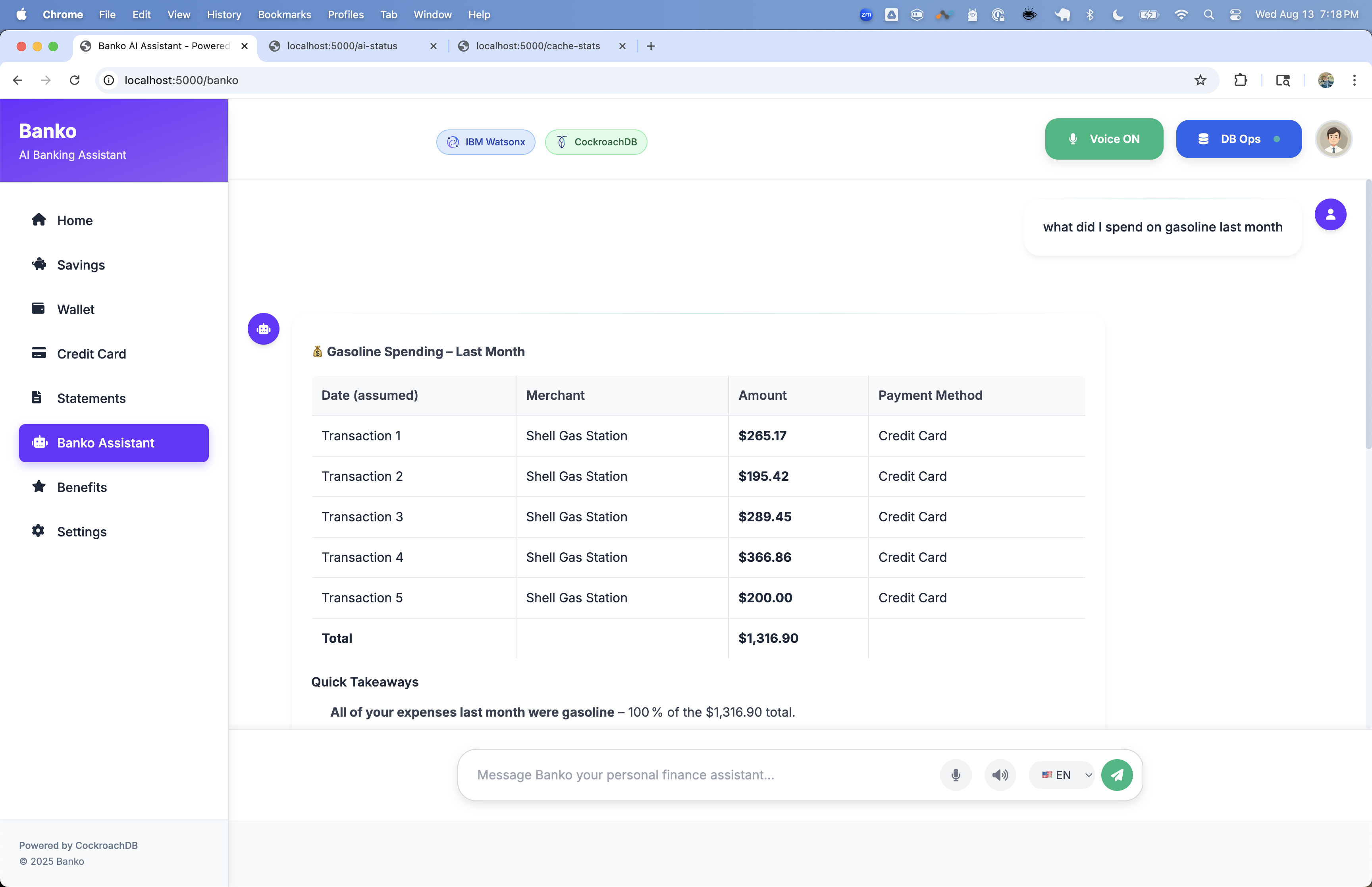
🌐 Web Interface
Access the application at http://localhost:5000
Main Features
- 🏠 Home: Overview dashboard with expense statistics
- 💬 Chat: AI-powered expense analysis and Q&A
- 🔍 Search: Vector-based expense search
- ⚙️ Settings: AI provider and model configuration
- 📊 Analytics: Detailed expense analysis and insights
🔧 CLI Commands
# Run the application
banko-ai run [OPTIONS]
# Generate sample data
banko-ai generate-data --count 2000
# Clear all data
banko-ai clear-data
# Check application status
banko-ai status
# Search expenses
banko-ai search "food delivery" --limit 10
# Show help
banko-ai help
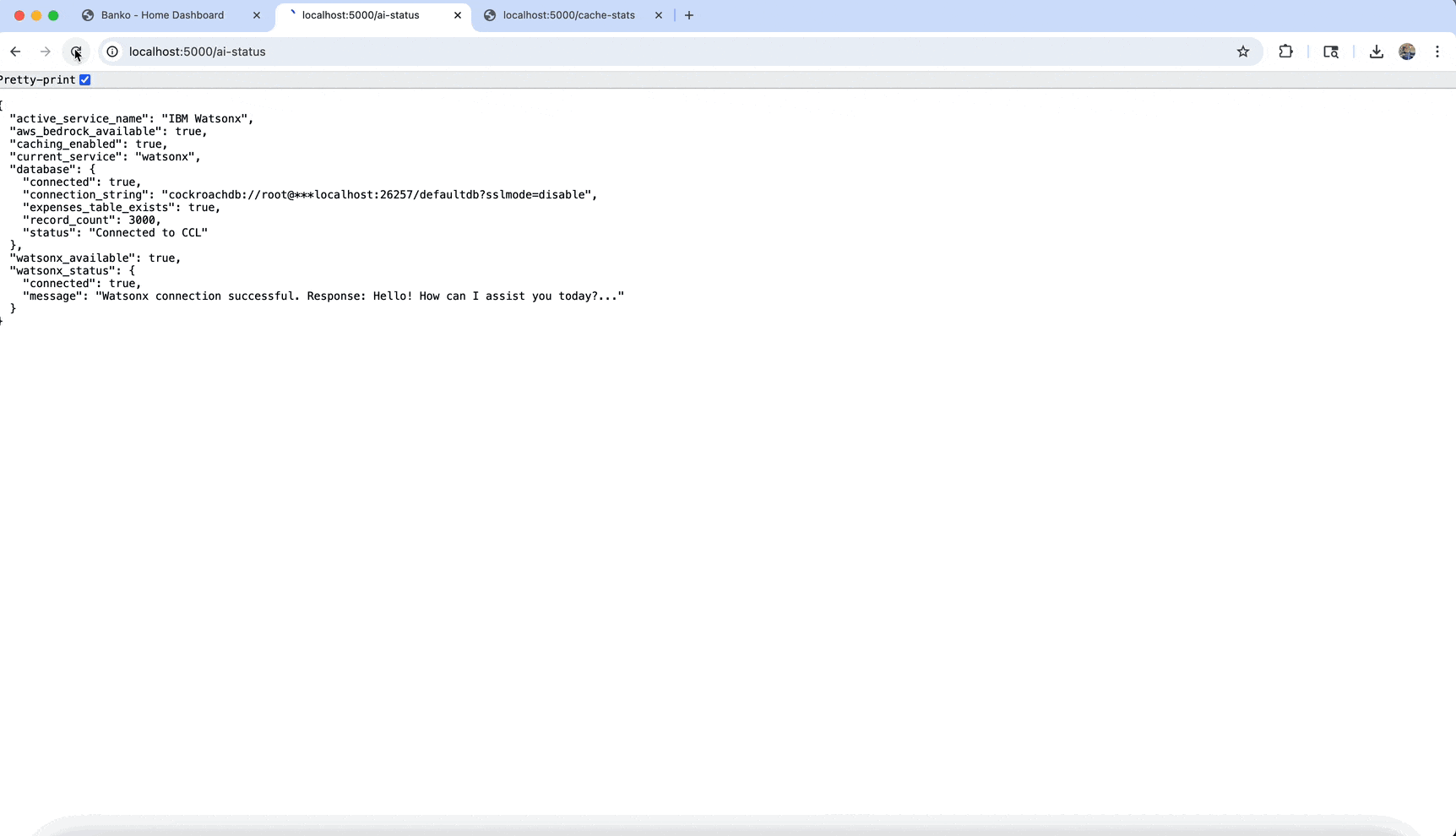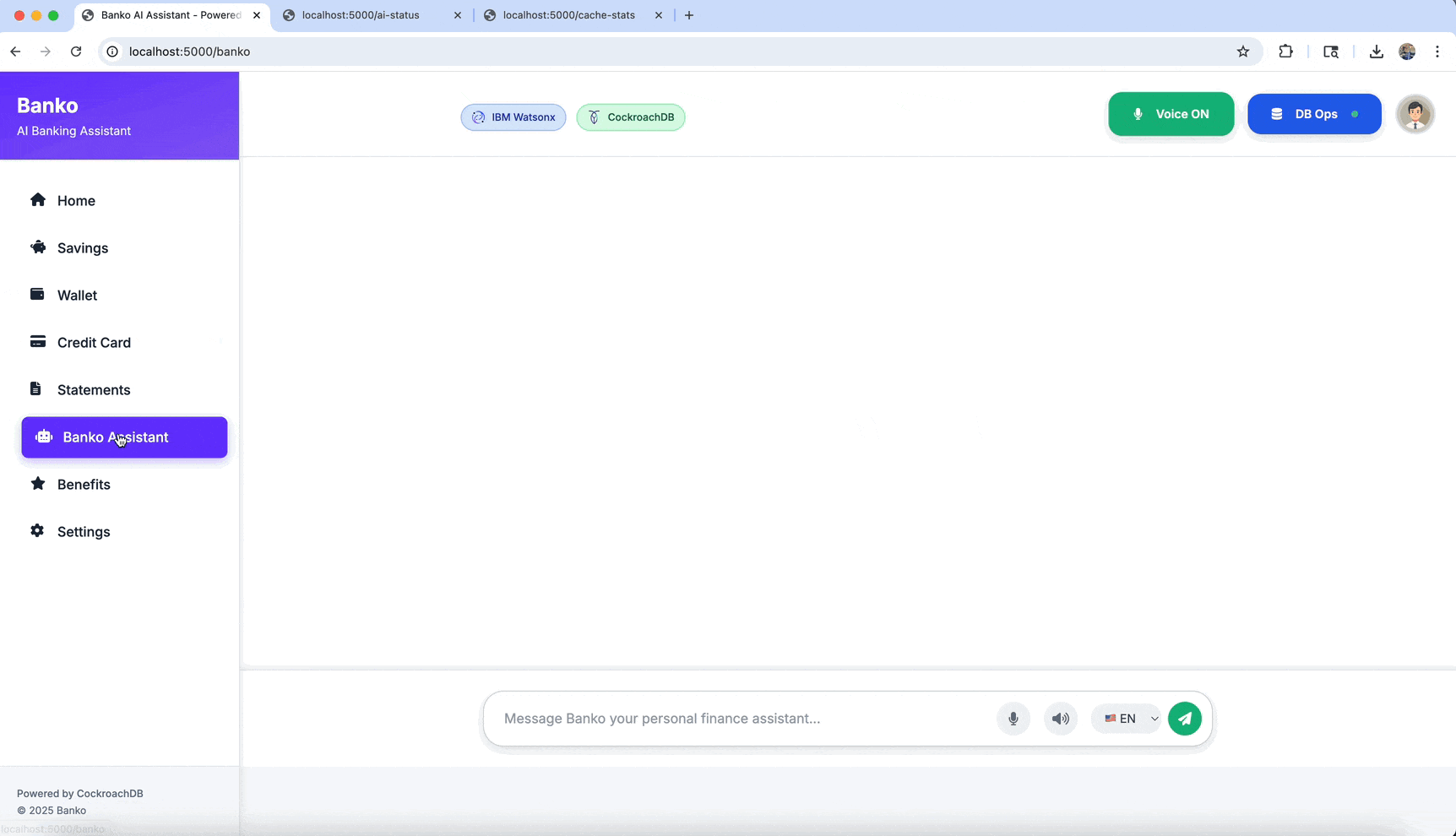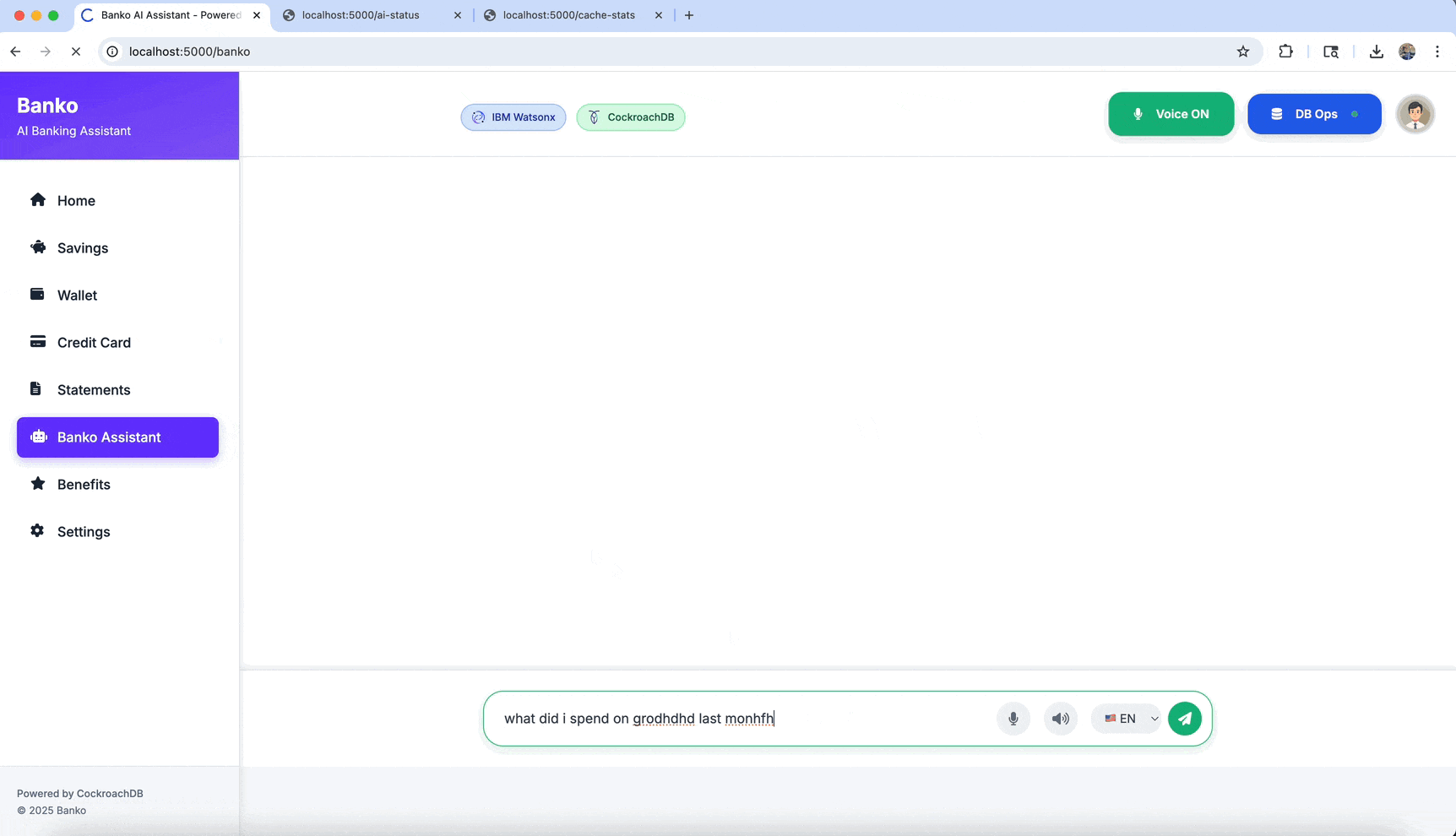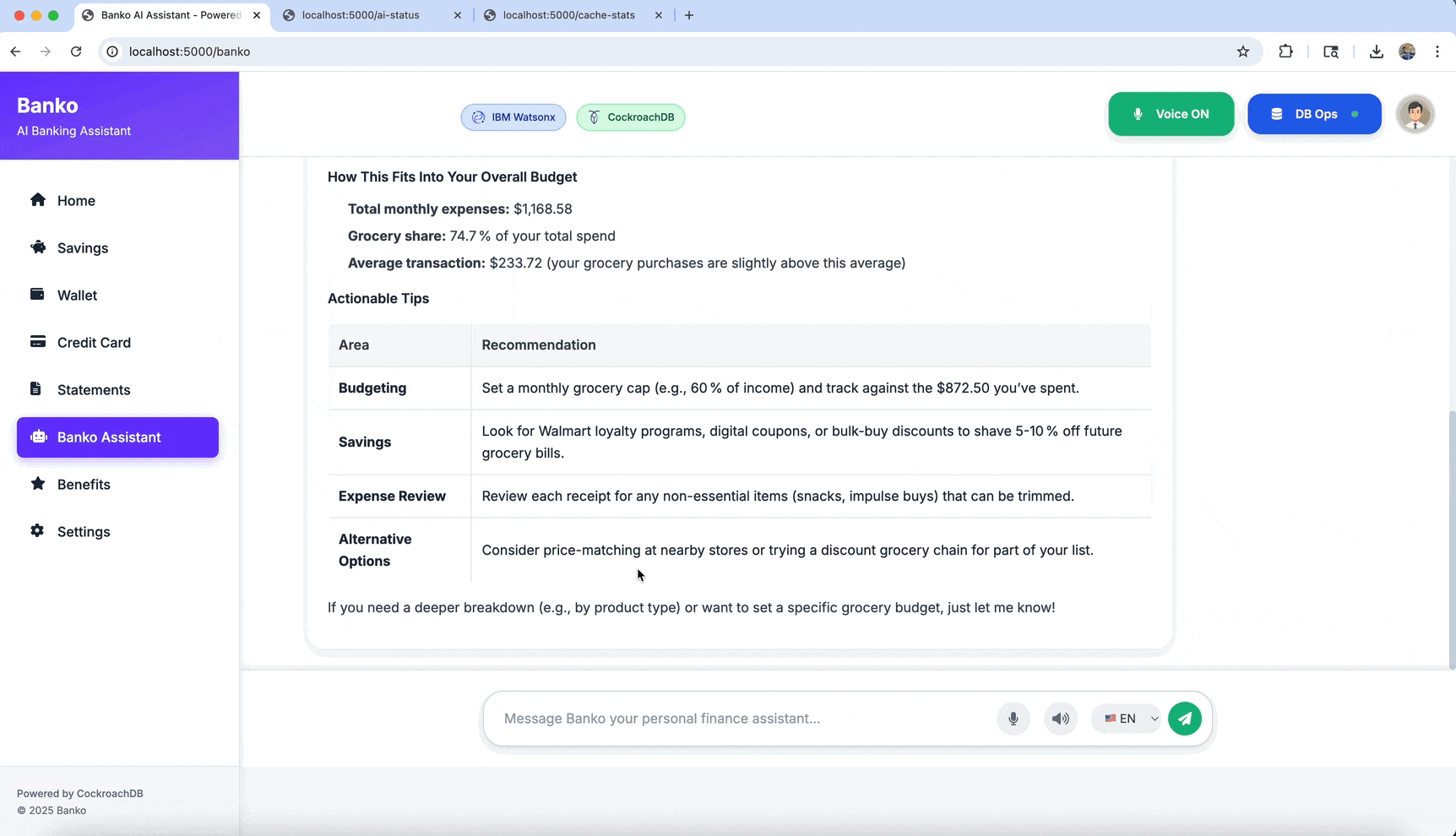
🔌 API Endpoints
| Endpoint | Method | Description |
|---|---|---|
/ |
GET | Web interface |
/api/health |
GET | System health check |
/api/ai-providers |
GET | Available AI providers |
/api/models |
GET | Available models for current provider |
/api/search |
POST | Vector search expenses |
/api/rag |
POST | RAG-based Q&A |
API Examples
# Health check
curl http://localhost:5000/api/health
# Search expenses
curl -X POST http://localhost:5000/api/search \
-H "Content-Type: application/json" \
-d '{"query": "food delivery", "limit": 5}'
# RAG query
curl -X POST http://localhost:5000/api/rag \
-H "Content-Type: application/json" \
-d '{"query": "What are my biggest expenses this month?", "limit": 5}'
🏗️ Architecture
Database Schema
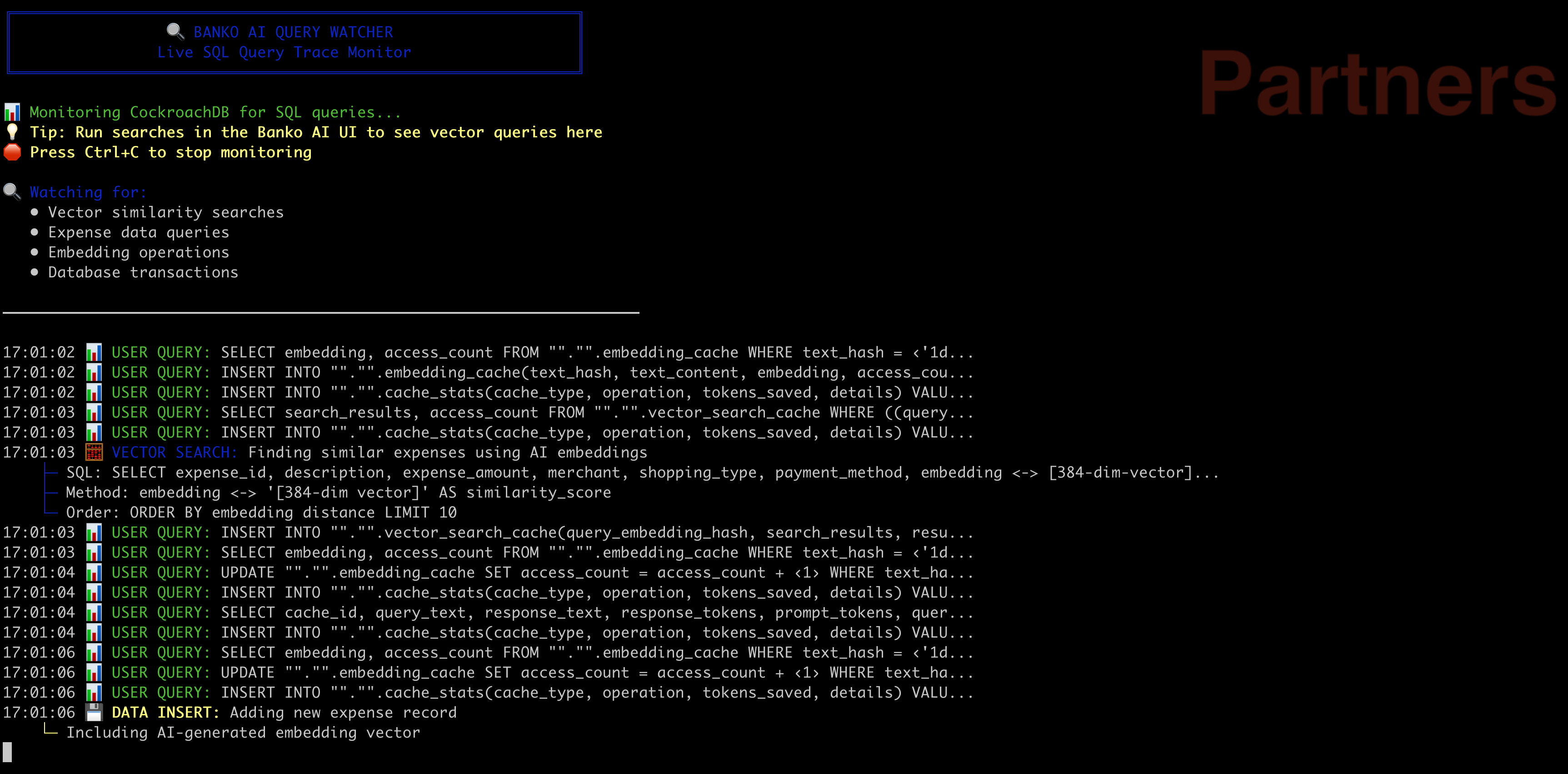
- expenses: Main expense table with vector embeddings
- query_cache: Cached search results
- embedding_cache: Cached embeddings
- vector_search_cache: Cached vector search results
- cache_stats: Cache performance statistics
Vector Indexes
-- User-specific vector index for personalized search
CREATE INDEX idx_expenses_user_embedding ON expenses
USING cspann (user_id, embedding vector_l2_ops);
-- General vector index for global search
CREATE INDEX idx_expenses_embedding ON expenses
USING cspann (embedding vector_l2_ops);
-- Note: Regional partitioning syntax may vary by CockroachDB version
-- CREATE INDEX idx_expenses_regional ON expenses
-- USING cspann (user_id, embedding vector_l2_ops)
-- LOCALITY REGIONAL BY ROW AS region;
Benefits:
- User-specific queries: Faster search within user's data
- Contextual results: Enhanced merchant and amount information
- Scalable performance: Optimized for large datasets
- Multi-tenant support: Isolated user data with shared infrastructure
🔄 AI Provider Switching
Switch between AI providers and models dynamically:
- Go to Settings in the web interface
- Select your preferred AI provider
- Choose from available models
- Changes take effect immediately
Supported Providers
- OpenAI: GPT-4o-mini (default), GPT-4o, GPT-4 Turbo, GPT-4, GPT-3.5 Turbo
- AWS Bedrock: Claude 3.5 Sonnet (default), Claude 3.5 Haiku, Claude 3 Opus, Claude 3 Sonnet
- IBM Watsonx: GPT-OSS-120B (default), Llama 2 (70B, 13B, 7B), Granite models
- Google Gemini: Gemini 1.5 Pro (default), Gemini 1.5 Flash, Gemini 1.0 Pro
📈 Performance Features
Caching System
- Query Caching: Caches search results for faster responses
- Embedding Caching: Caches vector embeddings to avoid recomputation
- Insights Caching: Caches AI-generated insights
- Multi-layer Optimization: Intelligent cache invalidation and refresh
Vector Search Optimization
- User-Specific Indexes: Faster search for individual users
- Regional Partitioning: Optimized for multi-region deployments
- Data Enrichment: Enhanced descriptions improve search accuracy
- Batch Processing: Efficient data loading and processing
🛠️ Development
Project Structure
banko_ai/
├── ai_providers/ # AI provider implementations
├── config/ # Configuration management
├── static/ # Web assets and images
├── templates/ # HTML templates
├── utils/ # Database and cache utilities
├── vector_search/ # Vector search and data generation
└── web/ # Flask web application
Adding New AI Providers
- Create a new provider class in
ai_providers/ - Extend the
BaseAIProviderclass - Implement required methods
- Add to the factory in
ai_providers/factory.py
🐛 Troubleshooting
Common Issues
CockroachDB Version Issues
# Check CockroachDB version (must be v25.2.4+)
cockroach version
# If version is too old, download v25.3.3:
# https://www.cockroachlabs.com/docs/releases/v25.3#v25-3-3
Vector Index Feature Not Enabled
# Connect to database and enable vector index feature
cockroach sql --url="cockroachdb://root@localhost:26257/defaultdb?sslmode=disable"
# Enable vector index feature
SET CLUSTER SETTING feature.vector_index.enabled = true;
# Verify it's enabled
SHOW CLUSTER SETTING feature.vector_index.enabled;
Database Connection Error
# Start CockroachDB single node
cockroach start-single-node \
--insecure \
--store=./cockroach-data \
--listen-addr=localhost:26257 \
--http-addr=localhost:8080 \
--background
# Verify database exists
cockroach sql --url="cockroachdb://root@localhost:26257/defaultdb?sslmode=disable" --execute "SHOW TABLES;"
AI Provider Disconnected
- Verify API keys are set correctly
- Check network connectivity
- Ensure the selected model is available
No Search Results
- Ensure sample data is loaded:
banko-ai generate-data --count 1000 - Check vector indexes are created
- Verify search query format
Debug Mode
# Run with debug logging
banko-ai run --debug
# Check application status
banko-ai status
Built with ❤️ using CockroachDB, Flask, and modern AI technologies such as watsonx.ai
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file banko_ai_assistant-1.0.33.tar.gz.
File metadata
- Download URL: banko_ai_assistant-1.0.33.tar.gz
- Upload date:
- Size: 8.9 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0f5b4229df622706668b94268f4bfea7dd7edbd046aeb17493e39b1635d9b255
|
|
| MD5 |
d13465f7de87f44b6b2944a7b0779c3d
|
|
| BLAKE2b-256 |
27d4d718ba7b9a80e8e53a1c2e4ceb60ff36d2dc629509152904524892e96252
|
File details
Details for the file banko_ai_assistant-1.0.33-py3-none-any.whl.
File metadata
- Download URL: banko_ai_assistant-1.0.33-py3-none-any.whl
- Upload date:
- Size: 8.9 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
042f92025976cfe74f6fd889f89f969d910cae16980ac56e4eccb5d1f7389264
|
|
| MD5 |
be12c9c8b1f3a2cb9e09a8f6f4a68bfb
|
|
| BLAKE2b-256 |
87ceadc9c2bd229471ef0e19510532e43778730c267d99ca6b1009b83d0b8a92
|







