Batch processing for AI models with cost tracking and state persistence

Project description
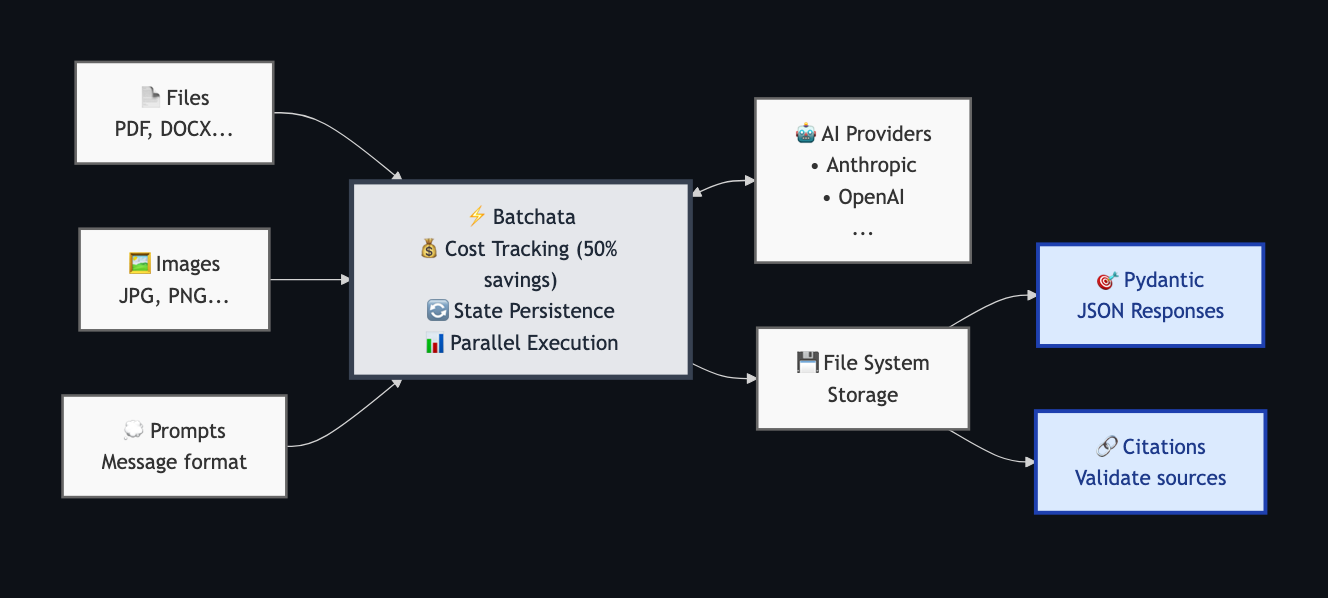
Batchata


Unified Python API for AI Batch requests with cost tracking, Pydantic responses, citation mapping and parallel execution.
This library is currently in alpha - so there will be breaking changes
Why AI-batching?
AI providers offer batch APIs that process requests asynchronously at 50% reduced cost compared to real-time APIs. This is ideal for workloads like document processing, data analysis, and content generation where immediate responses aren't required. However, managing batch jobs across providers, tracking costs, handling failures, and mapping citations back to source documents quickly becomes complex - that's where Batchata comes in.
Batchata Features
- Native batch processing (50% cost savings via provider APIs)
- Set
max_cost_usdlimits for batch requests - Time limit control with
.add_time_limit(seconds=, minutes=, hours=) - State persistence in case of network interruption
- Structured output
.jsonformat with Pydantic models - Citation support and field mapping (Anthropic only)
- Multiple provider support (Anthropic, OpenAI)
Installation
pip
pip install batchata
uv
uv add batchata
Quick Start
from batchata import Batch
# Simple batch processing
batch = Batch(results_dir="./output")
.set_default_params(model="claude-sonnet-4-20250514") # or "gpt-4.1-2025-04-14"
.add_cost_limit(usd=5.0)
for file in files:
batch.add_job(file=file, prompt="Summarize")
run = batch.run()
results = run.results() # {"completed": [JobResult], "failed": [JobResult], "cancelled": [JobResult]}
Complete Example
from batchata import Batch
from pydantic import BaseModel
from dotenv import load_dotenv
load_dotenv() # Load API keys from .env
# Define structured output
class InvoiceAnalysis(BaseModel):
invoice_number: str
total_amount: float
vendor: str
payment_status: str
# Create batch configuration
batch = Batch(
results_dir="./invoice_results",
max_parallel_batches=1,
items_per_batch=3
)
.set_state(file="./invoice_state.json", reuse_state=False)
.set_default_params(model="claude-sonnet-4-20250514", temperature=0.0)
.add_cost_limit(usd=5.0)
.add_time_limit(minutes=10) # Time limit of 10 minutes
.set_verbosity("warn")
# Add jobs with structured output and citations
invoice_files = ["path/to/invoice1.pdf", "path/to/invoice2.pdf", "path/to/invoice3.pdf"]
for invoice_file in invoice_files:
batch.add_job(
file=invoice_file,
prompt="Extract the invoice number, total amount, vendor name, and payment status.",
response_model=InvoiceAnalysis,
enable_citations=True
)
# Execute with rich progress display
print("Starting batch processing...")
run = batch.run(print_status=True)
# Or use custom progress callback
run = batch.run(
on_progress=lambda s, t, b: print(
f"\rProgress: {s['completed']}/{s['total']} jobs | "
f"Batches: {s['batches_completed']}/{s['batches_total']} | "
f"Cost: ${s['cost_usd']:.3f}/{s['cost_limit_usd']} | "
f"Time: {t:.1f}s",
end=""
)
)
# Get results
results = run.results()
# Process successful results
for result in results["completed"]:
analysis = result.parsed_response
citations = result.citation_mappings
print(f"\nInvoice: {analysis.invoice_number} (page: {citations.get("invoice_number").page})")
print(f" Vendor: {analysis.vendor} (page: {citations.get("vendor").page})")
print(f" Total: ${analysis.total_amount:.2f} (page: {citations.get("total_amount").page})")
print(f" Status: {analysis.payment_status} (page: {citations.get("payment_status").page})")
# Process failed/cancelled results
for result in results["failed"]:
print(f"\nJob {result.job_id} failed: {result.error}")
for result in results["cancelled"]:
print(f"\nJob {result.job_id} was cancelled: {result.error}")
Interactive Progress Display
Batchata provides an interactive real-time progress display when using print_status=True:
run = batch.run(print_status=True)

The interactive display shows:
- Job Progress: Completed/total jobs with progress bar
- Batch Status: Provider batch completion status
- Real-time Cost: Current spend vs limit (if set)
- Elapsed Time: Time since batch started
- Live Updates: Refreshes automatically as jobs complete
File Structure
./results/
├── job-abc123.json
├── job-def456.json
├── job-ghi789.json
└── raw_files/
└── responses/
├── job-abc123_raw.json
├── job-def456_raw.json
└── job-ghi789_raw.json
./batch_state.json # Batch state
Supported Providers
| Feature | Anthropic | OpenAI |
|---|---|---|
| Models | All Claude models | All GPT models |
| Batch Discount | 50% | 50% |
| Polling Interval | 1s | 5s |
| Citations | ✅ | ❌ |
| Structured Output | ✅ | ✅ |
| File Types | PDF, TXT, DOCX, Images | PDF, Images |
Configuration
Set your API keys as environment variables:
export ANTHROPIC_API_KEY="your-key"
export OPENAI_API_KEY="your-key"
You can also use a .env file in your project root (requires python-dotenv):
from dotenv import load_dotenv
load_dotenv()
from batchata import Batch
# Your API keys will now be loaded from .env
Limitations
- Field/citation mapping is heuristic, which means it isn't perfect.
- Citation mapping only works with flat Pydantic models (no nested BaseModel fields).
- No Gemini or Groq support yet.
- Cost tracking is not precise as the actual usage is only known after the batch is complete, try setting
items_per_batchto a lower value for more accurate cost tracking.
License
MIT License - see LICENSE file for details.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file batchata-0.3.7.tar.gz.
File metadata
- Download URL: batchata-0.3.7.tar.gz
- Upload date:
- Size: 239.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a69c91958ed42b51b426311d4dc033b5c07909e345e4c8f2516024763bb2c2d6
|
|
| MD5 |
6f29b1026050bcdb0a8b324b38b4e9f7
|
|
| BLAKE2b-256 |
322286a41606fc75df8154dc10527354d122fce9c346351d1d2f37fda6145ba2
|
Provenance
The following attestation bundles were made for batchata-0.3.7.tar.gz:
Publisher:
publish.yml on agamm/batchata
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
batchata-0.3.7.tar.gz -
Subject digest:
a69c91958ed42b51b426311d4dc033b5c07909e345e4c8f2516024763bb2c2d6 - Sigstore transparency entry: 299669742
- Sigstore integration time:
-
Permalink:
agamm/batchata@e6b463115c54ce48877681b23672278ecaacf9b0 -
Branch / Tag:
refs/tags/v0.3.7 - Owner: https://github.com/agamm
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@e6b463115c54ce48877681b23672278ecaacf9b0 -
Trigger Event:
release
-
Statement type:
File details
Details for the file batchata-0.3.7-py3-none-any.whl.
File metadata
- Download URL: batchata-0.3.7-py3-none-any.whl
- Upload date:
- Size: 58.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4357fcfef3a027af612251f22fcec9bb2643a8699b33a9c849623283b778c48d
|
|
| MD5 |
5107baad04fdb8d2938b6ab63cdc47b1
|
|
| BLAKE2b-256 |
e0225cc21fd8a228191db6ed5c4316776698bd4345879a1fa915c260e10de00a
|
Provenance
The following attestation bundles were made for batchata-0.3.7-py3-none-any.whl:
Publisher:
publish.yml on agamm/batchata
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
batchata-0.3.7-py3-none-any.whl -
Subject digest:
4357fcfef3a027af612251f22fcec9bb2643a8699b33a9c849623283b778c48d - Sigstore transparency entry: 299669760
- Sigstore integration time:
-
Permalink:
agamm/batchata@e6b463115c54ce48877681b23672278ecaacf9b0 -
Branch / Tag:
refs/tags/v0.3.7 - Owner: https://github.com/agamm
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@e6b463115c54ce48877681b23672278ecaacf9b0 -
Trigger Event:
release
-
Statement type:







