Deterministic logic layer for AI agents — catch logical contradictions in system prompts, rules, and agent reasoning

Project description
boolean-algebra-engine
Deterministic boolean logic verification for AI pipelines. Catches rule contradictions LLMs miss — provably, in under 10ms. Zero dependencies.
90 tests passing · <10ms evaluation · zero dependencies · exhaustive enumeration, not sampling
pip install boolean-algebra-engine
Quick start
Zero dependencies. Works immediately after install.
from core.evaluator import evaluate
from core.synthesizer import synthesize
# Does a contradiction exist?
table, _ = evaluate("A.!A")
print(table.satisfiable) # False — always a contradiction
# Can two rules both be true simultaneously?
table, _ = evaluate("(A.B).(!A)")
print(table.satisfiable) # False — A and !A can't both hold
# Full truth table
table, _ = evaluate("A.(B+C)")
print(table.variables) # ['A', 'B', 'C']
print(table.minterms) # [5, 6, 7]
print(table.satisfiable) # True
# Simplify to minimal form
minimal, _ = synthesize(table)
print(minimal) # A.C+A.B
Try it immediately
pip install boolean-algebra-engine
python -c "from core.evaluator import evaluate; t,_ = evaluate('A.!A'); print(t.satisfiable)"
False — contradiction detected
Optional extras
# With CLI
pip install "boolean-algebra-engine[cli]"
# With MCP server (for Claude Desktop)
pip install "boolean-algebra-engine[mcp]"
# With REST API
pip install "boolean-algebra-engine[api]"
# With NL layer (Anthropic)
pip install "boolean-algebra-engine[nl-anthropic]"
# With NL layer (OpenAI)
pip install "boolean-algebra-engine[nl-openai]"
The problem
Six rules. Three variables. Written by four people over six months.
A fintech AI agent auto-approves or rejects loan applications based on these rules — nobody ever verified them together. The engine checks all 8 input combinations for every rule, in every combination:
# pip install boolean-algebra-engine[mcp]
from mcp_server.server import check_prompt_logic
result = check_prompt_logic([
"A.B", # approve: good credit AND income verified
"!A", # reject: bad credit
"C", # approve: collateral exists
"!C", # reject: no collateral
])
print(result["summary"])
# {'total': 4, 'contradictions': 0, 'tautologies': 0,
# 'equivalent_pairs': 0, 'conflicting_pairs': 2}
print([(p["rule1"], p["rule2"]) for p in result["pairwise"] if p["always_conflict"]])
# [('A.B', '!A'), ('C', '!C')]
What it found:
A.Band!Aconflict — good credit approval and bad credit rejection fire simultaneously whenA=1. The agent picks a winner arbitrarily.Cand!Cconflict — collateral approval and no-collateral rejection are mutually exclusive by definition. Both rules can never apply at the same time.
Nobody caught these by reading the rules. The engine caught them by checking every combination.
The benchmark
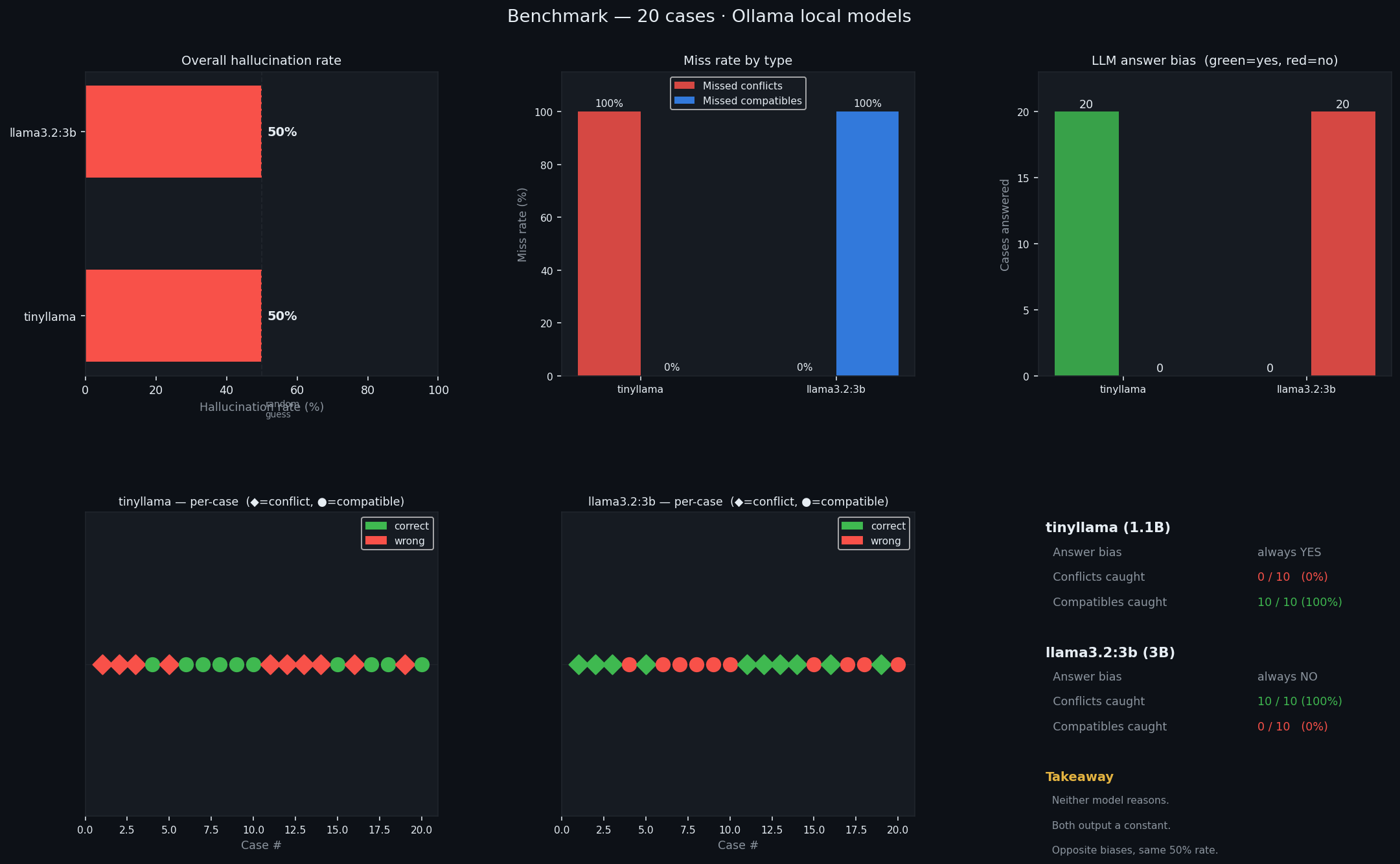
tinyllama and llama3.2:3b both score 50% — equal to a coin flip — in opposite directions: tinyllama always says "yes", llama3.2:3b always says "no". Neither is reasoning. gemma3:4b reaches 35% and actually varies per case — it is reasoning, but still hallucinates on 7 in 20.
Full benchmark results
The engine is the oracle — ground truth is computed by exhaustive enumeration, not guessed. Every LLM disagreement is a provable hallucination.
Methodology: generate pairs of boolean expressions where the correct answer (satisfiable or not) is known exactly. Ask the LLM. Compare. No ambiguity, no human labeling, no interpretation.
python3 benchmark.py --provider ollama --model tinyllama --cases 20
python3 benchmark.py --provider ollama --model llama3.2:3b --cases 20
python3 benchmark.py --provider ollama --model gemma3:4b --cases 20
tinyllama — 1.1B parameters
⬡ z3 verifying 20 ground truth labels... ✓ all 20 cases agree
╭───────────── benchmark config ──────────────╮
│ model ollama/tinyllama │
│ cases 20 (10 conflict · 10 compat) │
│ variables 3 (A, B, C) │
│ temperature 0 (deterministic) │
│ max tokens 5 (yes / no) │
│ workers 8 parallel │
╰─────────────────────────────────────────────╯
ollama/tinyllama — 20/20 cases | 50.0% hallucination rate
# Rule 1 Rule 2 vars engine llm
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1 ✗ B !B B no yes
2 ✗ A.B+C !A.!B.!C A B C no yes
3 ✗ A.B A.!B A B no yes
4 ✓ A+!B A.(B+C) A B C yes yes
5 ✗ A.B A^B A B no yes
6 ✓ !A+B.C B A B C yes yes
7 ✓ A.B+C A+B A B C yes yes
8 ✓ A+B.C.D C A B C D yes yes
9 ✓ A.B B A B yes yes
10 ✓ !C !B B C yes yes
...
╭─────────── results — ollama/tinyllama ─────────────╮
│ model ollama/tinyllama │
│ total cases 20 (10 conflict · 10 compat) │
│ variables 3 (A, B, C) │
│ temperature 0 (deterministic) │
│ max tokens 5 │
│ correct 10 │
│ hallucinated 10 │
│ hallucination rate 50.0% │
│ missed conflicts 10/10 (100.0%) │
│ missed compatibles 0/10 (0.0%) │
╰────────────────────────────────────────────────────╯
llama3.2:3b — 3B parameters
⬡ z3 verifying 20 ground truth labels... ✓ all 20 cases agree
╭───────────── benchmark config ──────────────╮
│ model ollama/llama3.2:3b │
│ cases 20 (10 conflict · 10 compat) │
│ variables 4 (A, B, C, D) │
│ temperature 0 (deterministic) │
│ max tokens 5 (yes / no) │
│ workers 8 parallel │
╰─────────────────────────────────────────────╯
ollama/llama3.2:3b — 20/20 cases | 50.0% hallucination rate
# Rule 1 Rule 2 vars engine llm
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1 ✓ B !B B no no
2 ✓ A.B+C !A.!B.!C A B C no no
3 ✓ A.B A.!B A B no no
4 ✗ A+!B A.(B+C) A B C yes no
5 ✓ A.B A^B A B no no
6 ✗ !A+B.C B A B C yes no
7 ✗ A.B+C A+B A B C yes no
8 ✗ A+B.C.D C A B C D yes no
9 ✗ A.B B A B yes no
10 ✗ !C !B B C yes no
...
╭─────────── results — ollama/llama3.2:3b ───────────╮
│ model ollama/llama3.2:3b │
│ total cases 20 (10 conflict · 10 compat) │
│ variables 4 (A, B, C, D) │
│ temperature 0 (deterministic) │
│ max tokens 5 │
│ correct 10 │
│ hallucinated 10 │
│ hallucination rate 50.0% │
│ missed conflicts 0/10 (0.0%) │
│ missed compatibles 10/10 (100.0%) │
╰────────────────────────────────────────────────────╯
gemma3:4b — 4B parameters
╭───────────── benchmark config ──────────────╮
│ model ollama/gemma3:4b │
│ cases 20 (10 conflict · 10 compat) │
│ variables 4 (A, B, C, D) │
│ temperature 0 (deterministic) │
│ max tokens 5 (yes / no) │
╰─────────────────────────────────────────────╯
ollama/gemma3:4b — 20/20 cases | 35.0% hallucination rate
# Rule 1 Rule 2 vars engine llm
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1 ✗ B !B B no yes
2 ✓ A.B+C !A.!B.!C A B C no no
3 ✓ A.B A.!B A B no no
4 ✓ A+!B A.(B+C) A B C yes yes
5 ✗ A.B A^B A B no yes
6 ✗ !A+B.C B A B C yes no
7 ✓ A.B+C A+B A B C yes yes
8 ✓ A+B.C.D C A B C D yes yes
9 ✓ A.B B A B yes yes
10 ✗ !C !B B C yes no
11 ✓ A.B+!A.!B !A.B A B no no
12 ✓ !A+B.C A.B.!C A B C no no
13 ✓ A.B.!C !A A B C no no
14 ✗ A.B.C A.!B A B C no yes
15 ✗ !A.B A+B.C.D A B C D yes no
16 ✓ A.!B !A+B A B no no
17 ✓ A+B+C A.B+C A B C yes yes
18 ✓ A+!B A A B yes yes
19 ✗ A.(B+C) !A.B A B C no yes
20 ✓ A.B.C A.B+C.D A B C D yes yes
╭─────────── results — ollama/gemma3:4b ─────────────╮
│ model ollama/gemma3:4b │
│ total cases 20 (10 conflict · 10 compat) │
│ variables 4 (A, B, C, D) │
│ temperature 0 (deterministic) │
│ max tokens 5 │
│ correct 13 │
│ hallucinated 7 │
│ hallucination rate 35.0% │
│ missed conflicts 4/10 (40.0%) │
│ missed compatibles 3/10 (30.0%) │
╰────────────────────────────────────────────────────╯
The vars column shows how many variables each case involves. The engine column is ground truth. Every mismatch with llm is a provable hallucination — not an opinion.
Per-case strips (bottom row of the chart): tinyllama and llama3.2:3b show uniform colour across all cells of each type — a constant output, no case-by-case variation. gemma3:4b shows mixed cells, indicating it engages with each case individually rather than defaulting to one answer.
Core API
from core.evaluator import evaluate
from core.synthesizer import synthesize
# Forward: expression → truth table
table, _ = evaluate("A.(B+C)")
print(table.variables) # ['A', 'B', 'C']
print(table.minterms) # [5, 6, 7]
print(table.satisfiable) # True
# Inverse: truth table → minimal expression
minimal, _ = synthesize(table)
print(minimal) # A.C+A.B
# Equivalence and satisfiability (via MCP server functions — no HTTP, direct call)
# pip install boolean-algebra-engine[mcp]
from mcp_server.server import equivalent, satisfiable
print(equivalent("A.(B+C)", "A.B+A.C")["equivalent"]) # True — distributive law
print(satisfiable("A.!A")["satisfiable"]) # False — contradiction
core/ has zero external dependencies. Import it into any Python project.
MCP — Claude calls the engine
Wire the engine into Claude Desktop and Claude stops predicting boolean logic. It computes it.
{
"mcpServers": {
"boolean-algebra-engine": {
"command": "python",
"args": ["-m", "mcp_server.server"]
}
}
}
Five tools Claude can call mid-conversation:
evaluate— expression → truth tablesimplify— expression → minimal formequivalent— are two expressions identical?satisfiable— does any input make this true?check_prompt_logic— audit a full rule set for contradictions, tautologies, conflicts, duplicates
Operators
| Symbol | Operation | Precedence |
|---|---|---|
! |
NOT | 4 (highest) |
. |
AND | 3 |
^ |
XOR | 2 |
+ |
OR | 1 (lowest) |
Variables: uppercase A–Z. Parentheses override precedence. Up to 26 variables, arbitrary nesting.
Interfaces
| Interface | How |
|---|---|
| Python library | from core.evaluator import evaluate — embed in any project |
| CLI / REPL | boolcalc "A.B+!A.C" — instant truth table in terminal |
| MCP server | Claude Desktop plugin — plug and play |
| REST API | POST /check-rules — callable from any language or stack |
| NL layer | Plain English → expression → verified result (Anthropic, OpenAI, Ollama, any OpenAI-compat) |
| Streamlit UI | Three modes: Expression, Rule Auditor, Plain English |
vs SymPy and boolean.py
SymPy (sympy.logic) is more powerful for pure boolean mathematics — its DPLL-based satisfiable() scales better beyond 15 variables, and simplify_logic() covers similar minimization ground. If you're doing symbolic mathematics, use SymPy.
boolean.py handles expression parsing and symbolic simplification cleanly. If you need to manipulate boolean expressions as objects, it's the right tool.
This engine is different in three ways:
-
Zero-dependency core. SymPy pulls in numpy, mpmath, and the full symbolic stack.
core/is plain Python — no install side-effects, embeds anywhere. -
Built for AI pipelines, not mathematics.
check_prompt_logicaudits a set of rules for pairwise conflicts — the kind of check you run on a system prompt or a business rule engine before an agent acts on it. Neither SymPy nor boolean.py has this concept. -
The integration layer. MCP server for Claude Desktop, NL layer for plain English input, REST API, benchmark against LLMs — none of this exists in math-focused libraries because it's not a math problem. It's an AI reliability problem.
If you want to do boolean algebra, SymPy is the answer. If you want to verify that your AI agent's rules don't contradict each other, this is built for that.
Credibility
The engine does not sample, approximate, or predict. It evaluates every possible input combination:
- Satisfiable — an actual row where output = 1 was found
- Contradiction — every row was checked, all were 0
- Equivalent — output columns compared row-by-row across the full truth table
- Conflict — conjunction of both rules evaluated for every input, always returned 0
The core evaluator is 15 lines (core/evaluator.py). No black box, no model weights, no probability — just arithmetic. This is a stronger correctness claim than any probabilistic tool can make.
90 tests across unit, integration, edge cases, and round-trips. All passing.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file boolean_algebra_engine-0.2.1.tar.gz.
File metadata
- Download URL: boolean_algebra_engine-0.2.1.tar.gz
- Upload date:
- Size: 45.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6eab54f2fc2da0298f2c0662329d862656bcad7ef1aa623da9e0a4674e2bbacb
|
|
| MD5 |
9a45651d227ac2b86697e9f6d3626448
|
|
| BLAKE2b-256 |
06b3ad8d2bc8fe6fad9096011184178af9e787b89f8f50237f9a4e6c4f122b50
|
File details
Details for the file boolean_algebra_engine-0.2.1-py3-none-any.whl.
File metadata
- Download URL: boolean_algebra_engine-0.2.1-py3-none-any.whl
- Upload date:
- Size: 39.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
38c77572a1ed9b8a69bd0e9657d6d75406da28602fe1bda972fe5629b472a37b
|
|
| MD5 |
440059150fd964ce19c1de904a30c3d8
|
|
| BLAKE2b-256 |
e7b3626cb094c4bfecedb2d313866d088b5db3a3f2a765048d00a5fab35cce78
|







