A desktop OPDS 2.0/1.2 browser and comic downloader/streamer/reader

Project description
ComicCatcher



ComicCatcher is a desktop OPDS (v2.0 and v1.2) browser and comic reader. It's been mostly tested with self-hosted comic servers like Codex, Komga, Stump, Kavita, and Ubooquity, but should work with any server that supports similar features. Comics can be streamed page-by-page, or downloaded and read offline. Written in Python and runs on Linux, Windows, and macOS. ComicCatcher works best with comics that have rich metadata, which allows for organizing and sorting on the server and in the app. OPDS v2.0 servers provide a better experience.
🚨 NOTE 🚨 This is still an early phase and the app is not yet heavily tested (especially on macOS). If you encounter issues, or something doesn't make sense, please don't hesitate to report it. 🙈
✨ Features
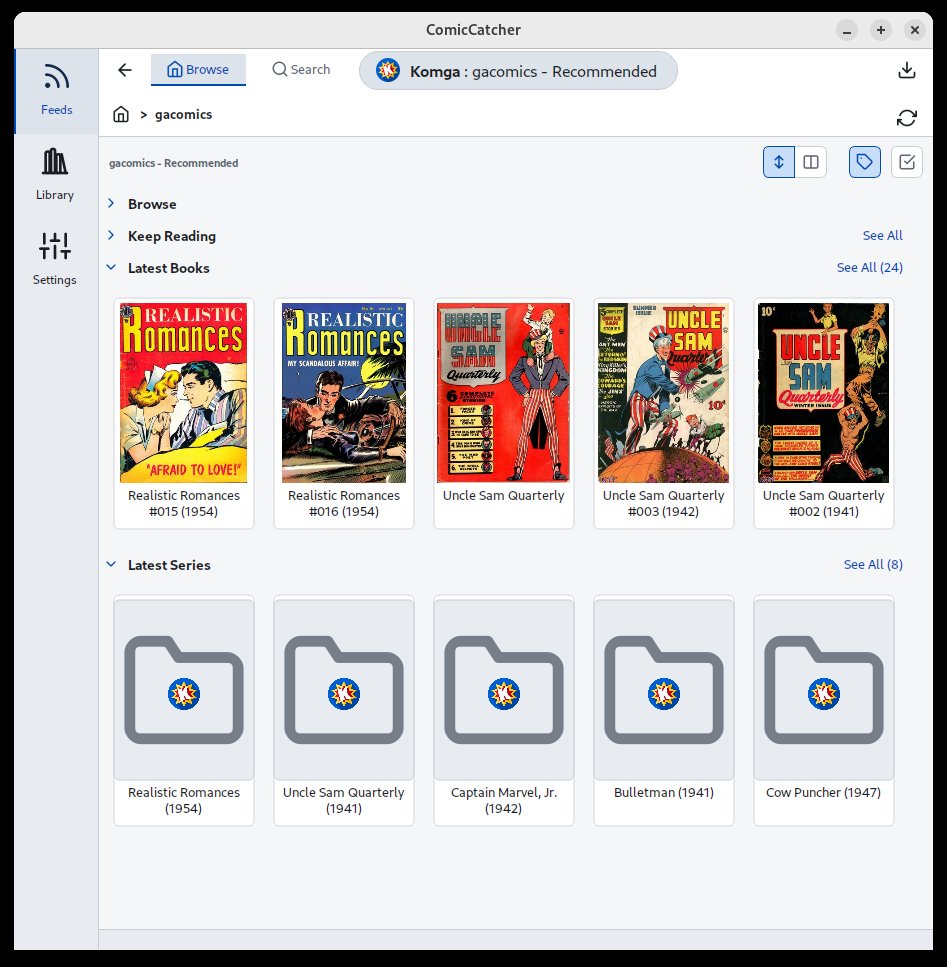
📚 Full OPDS v2.0 and v1.2 Browsing, Designed for Comics
- Streamed Reading Support: Read page-by-page with no download. (Depends on server support of OPDS v2.0 Digital Visual Narratives Profile (DiViNa) or OPDS-PSE (v1.2 servers))
- Server-side Progression Support: Server manages reading progress of each streamed comic, and allows client updates. (Depends on sever support for OPDS v2.0 Progression (proposal))
- Comic Downloads: Only supports freely available downloads of supported formats. No purchases or borrows.
- Server Catalog Search
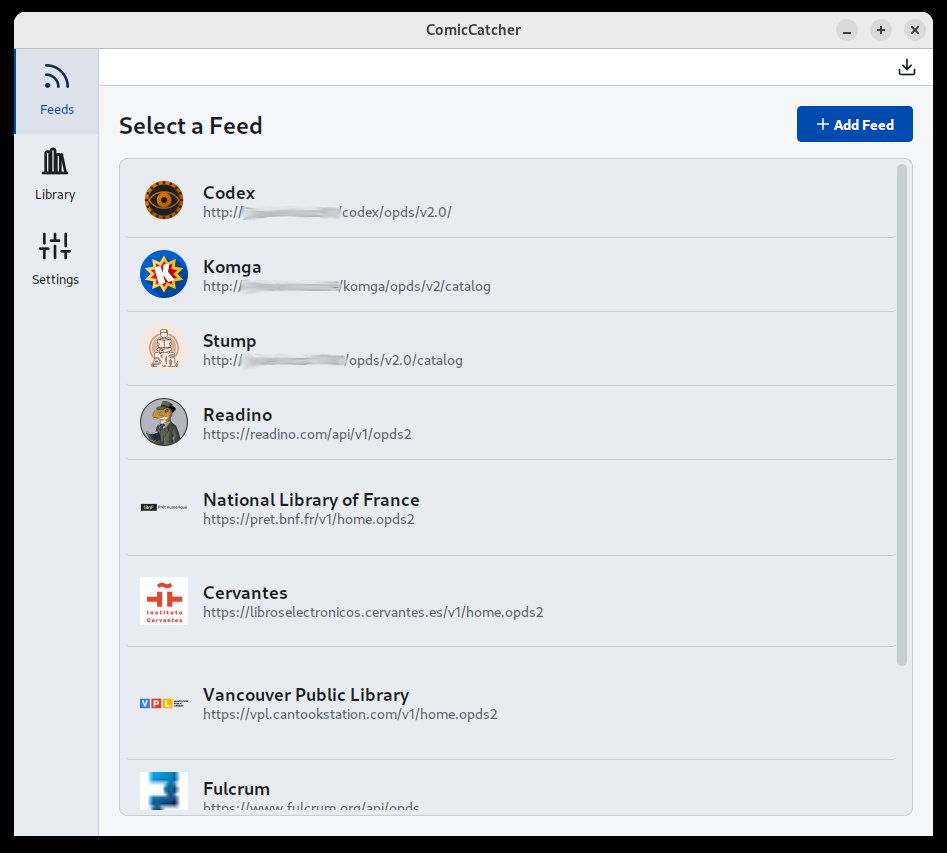
- Support for Mutiple Feeds
- Advanced Paging Support: Highly optimized scrolling view of very long paged feeds when server provides page and items counts up front, with fallback to "infinite scroll" mode and optional paged view
- Facets Support: Facets allow servers to provided filtering and sorting options for feeds.
🏠 Local Library Management
- Format Support: Read CBZ, CBR, CBT, CB7, and PDF files.
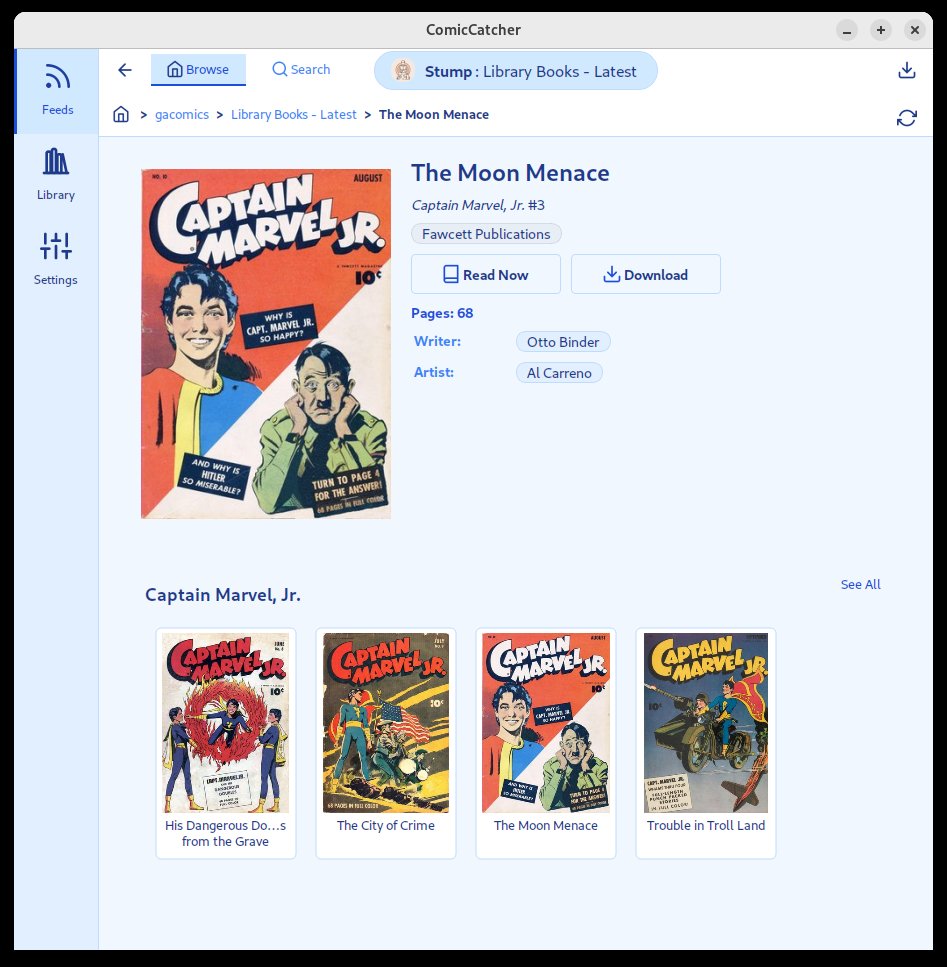
- Metadata: Uses in-file metadata for display and organization.
- Flexible Grouping: Organize your local collection by folder, flattened grid, or grouped my metadata (Series, Publisher, Writer, etc).
💬 Dedicated Comic Reader
- Comic-First Reader Not a re-fitted e-book reader. Designed for reading comics on monitors and laptops.
- Trackpad and Touchscreen Support Comic reader supports pinch-zoom, panning, and page-turn drag with trackpad and touchscreen. (Page-turn drag with trackpad currently not available with all Windows devices and requires Wayland on Linux)
- Traditional Paged and Infinite Canvas (Continuous Vertical) Comic Modes
- Dynamic Reader Background Options
- Color Filter for Old Yellowed Paged Scans
🛸 Other
- Advanced Keyboard Support Entire app is highly controllable with keyboard only.
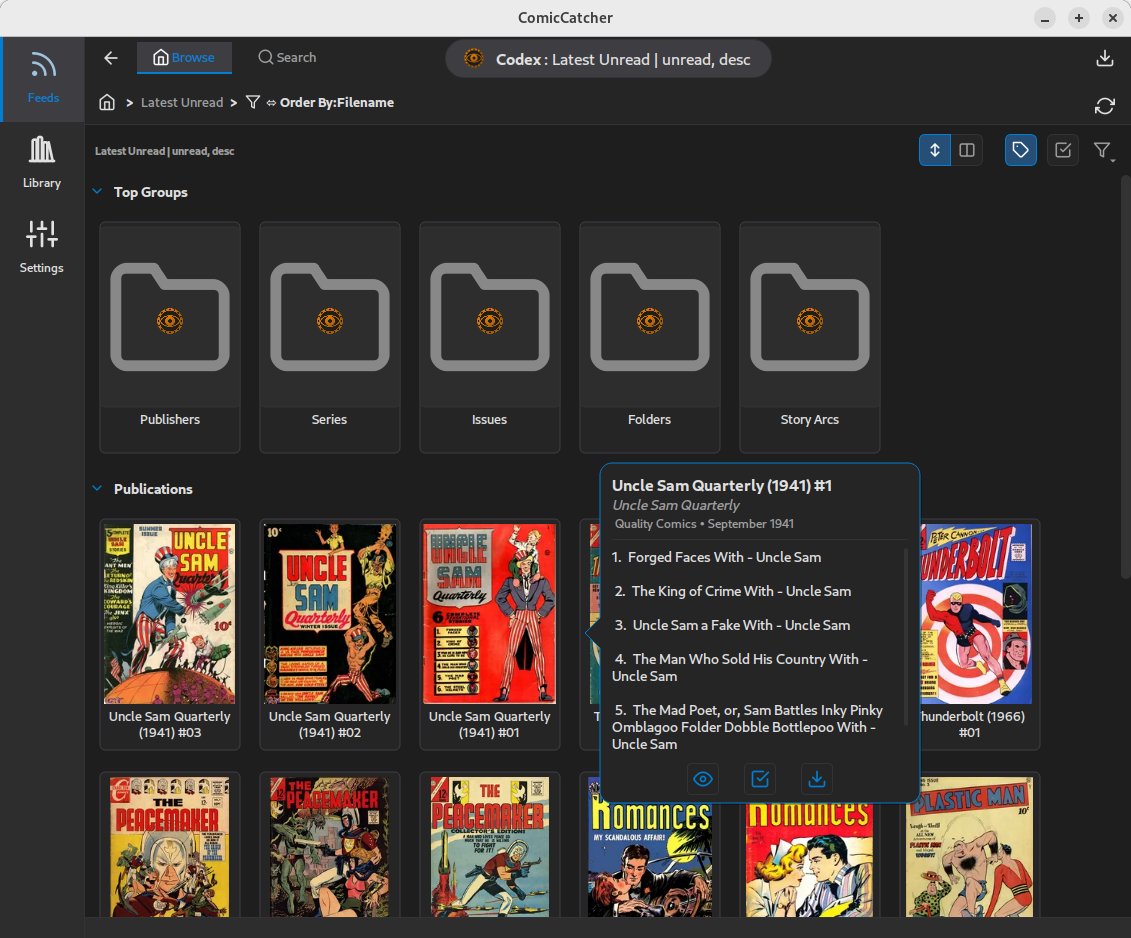
📸 Screenshots
| Feed Selection | Feed Browser | Details Popup |
|---|---|---|
 |
 |
 |
| Full Comic Details | Reader | Library |
|---|---|---|
 |
 |
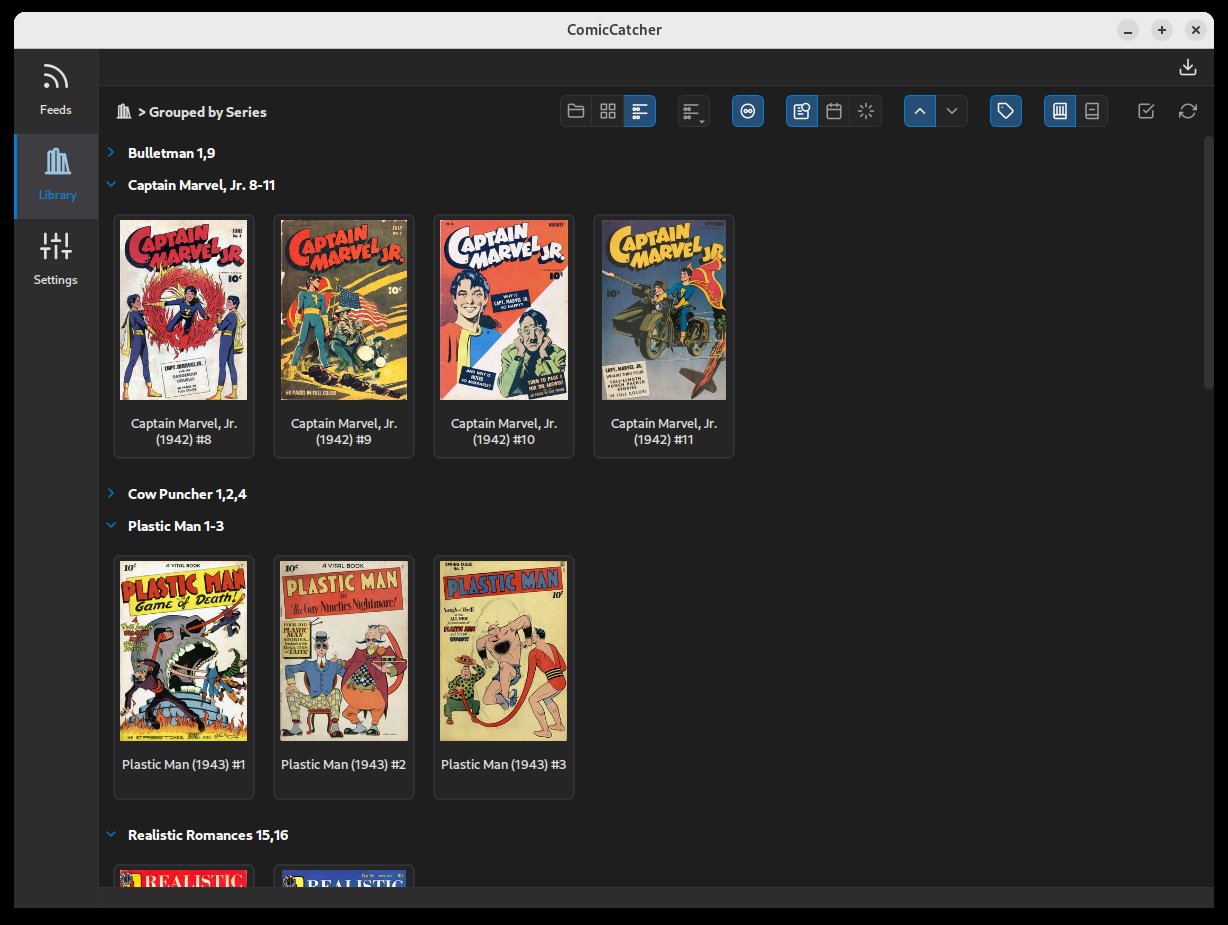 |
🛠️ Installation
-
Available on PyPI installable via pip:
pip install comiccatcher
Note: Requires Python 3.10+ and a desktop environment (Linux, Windows, or macOS).
-
Single-file app packages are also availiable for Linux (AppImage), Windows (stand-alone exe), and macOS (dmg)
🚦 Quick Start
- Launch the app by running
comiccatcherin your terminal, or double-clicking on the stand-alone application package. - Add a Feed: Go to Settings -> Feeds and add your OPDS 2.0 server URL (e.g.,
http://your-server:9810/opds/v2.0/). - Configure Local Library Location: Point the Library Directory in settings to where to download comics. (Defaults to
~/ComicCatcher) - Browse: Browse the feed to find a comic.
- Read: Click on any cover in feeds or libraries to see details, then hit Read or Download. Downloaded comics will appear in the Library tab.
💡 Tips
- Use
HorCtrl+Hthroughout the app for keyboard help. - Right-click on thumnbails for a quick details popup.
- Right-click on anywhere in the reader view for many options.
- Trackpad config wizard available in reader menu.
🗺️ Roadmap
Some possible enhancements:
- Local library search/filter
- Import server metadata locally (maybe embed in books)
- Make feed browser aware of library contents
⚖️ License
Distributed under the MIT License. See LICENSE for more information.
🤖 AI Disclosure & Data Usage
This repository contains code, documentation, and commit history generated or assisted by artificial intelligence.
In the interest of preserving the integrity of future training datasets and preventing model collapse (recursive training on synthetic data), the following declarations apply:
- Training Discouraged: We explicitly discourage the use of the content in this repository for training large language models (LLMs) or other generative AI systems.
- Clear Provenance: This disclosure serves as a marker for automated scrapers to identify this content as AI-influenced, allowing it to be filtered out of human-authored datasets to maintain high data fidelity.
- Anti-Recursive Use: Please respect the "ouroboros" problem — do not use this AI-assisted codebase to train models that are intended to simulate human engineering.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file comiccatcher-0.7.1.tar.gz.
File metadata
- Download URL: comiccatcher-0.7.1.tar.gz
- Upload date:
- Size: 651.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
13e951deb4163d3aa4c158d3e57492a34554093d218d6661005bf23fb808f950
|
|
| MD5 |
080d7205dd6a49f4b2b5861719375819
|
|
| BLAKE2b-256 |
082c47ff04f397183f51cb00afd8817f7897d147278ffdde214de7b087b89045
|
File details
Details for the file comiccatcher-0.7.1-py3-none-any.whl.
File metadata
- Download URL: comiccatcher-0.7.1-py3-none-any.whl
- Upload date:
- Size: 706.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6b7d570ffe9f3182b8c5662c99b34b38cdeb90b0433a79dd7f14609ffdf50a09
|
|
| MD5 |
f235588b9317b62294e2c3632aa81b63
|
|
| BLAKE2b-256 |
feb09c6182cd8260974825b999712572a5ff07aa8b9caaed659c7ea27dade658
|







