Time Robustness Audit for RL agents — measures timing reliance, deployment robustness, and stress resilience
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
deltatau-audit





Find and fix timing failures in RL agents.
RL agents silently break when deployment timing differs from training — frame drops, variable inference latency, sensor rate changes. deltatau-audit finds these failures and fixes them in one command.
Try it in 30 seconds
pip install "deltatau-audit[demo]"
python -m deltatau_audit demo cartpole
# Faster: python -m deltatau_audit demo cartpole --workers auto
No GPU. No MuJoCo. Just pip install and run. You'll see a Before/After comparison:
| Scenario | Before (Baseline) | After (Speed-Randomized) | Change |
|---|---|---|---|
| 5x speed | 12% | 49% | +37pp |
| Speed jitter | 66% | 115% | +49pp |
| Observation delay | 82% | 95% | +13pp |
| Mid-episode spike | 23% | 62% | +39pp |
| Deployment | FAIL (0.23) | DEGRADED (0.62) | +0.39 |
The standard agent collapses under timing perturbations. Speed-randomized training dramatically improves robustness. Full HTML reports with charts are generated in demo_report/.
The same pattern at MuJoCo scale: HalfCheetah PPO
A PPO agent trained to reward ~990 on HalfCheetah-v5 shows even more catastrophic timing failures — all 4 scenarios statistically significant (95% bootstrap CI):
| Scenario | Return (% of nominal) | 95% CI | Drop |
|---|---|---|---|
| Observation delay (1 step) | 3.8% | [2.4%, 5.2%] | -96% |
| Speed jitter (2 +/- 1) | 25.4% | [23.5%, 27.8%] | -75% |
| 5x speed (unseen) | -9.3% | [-10.6%, -8.4%] | -109% |
| Mid-episode spike (1->5->1) | 90.9% | [86.3%, 97.8%] | -9% |
A single step of observation delay destroys 96% of performance. The agent goes negative at 5x speed.
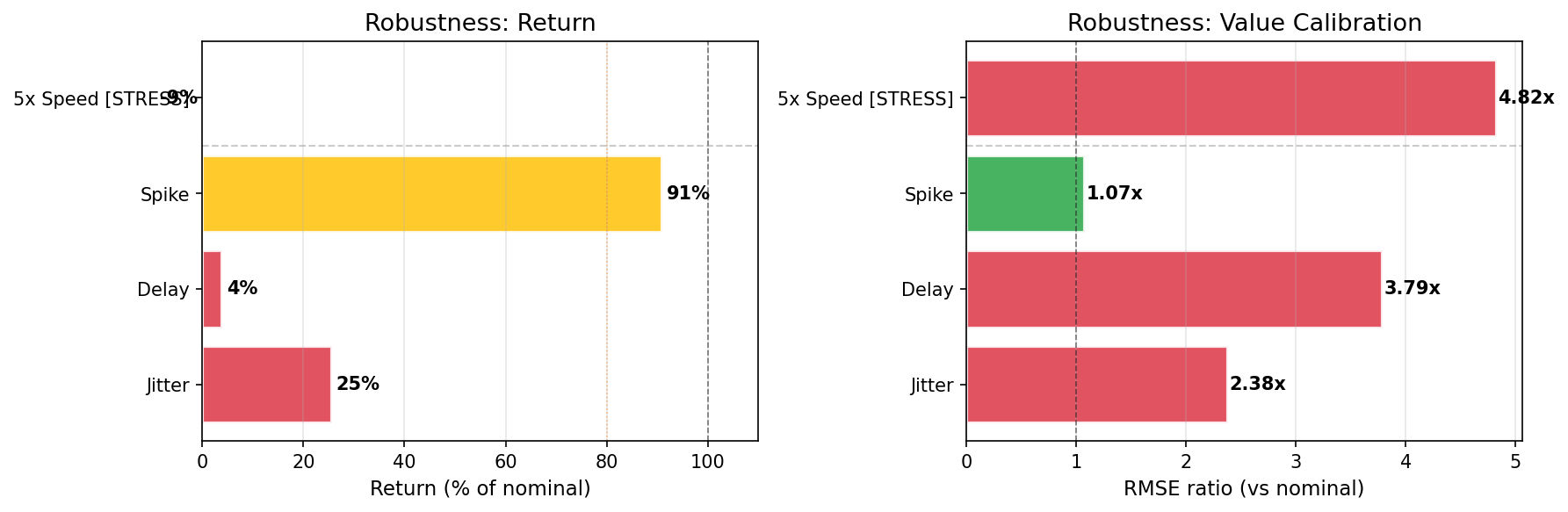
View interactive report | Download report ZIP
Speed-randomized training fixes the problem
| Scenario | Before (Standard) | After (Speed-Randomized) | Change |
|---|---|---|---|
| Observation delay | 2% | 148% | +146pp |
| Speed jitter | 28% | 121% | +93pp |
| 5x speed (unseen) | -12% | 38% | +50pp |
| Mid-episode spike | 100% | 113% | +13pp |
| Deployment | FAIL (0.02) | PASS (1.00) | |
| Quadrant | deployment_fragile | deployment_ready |
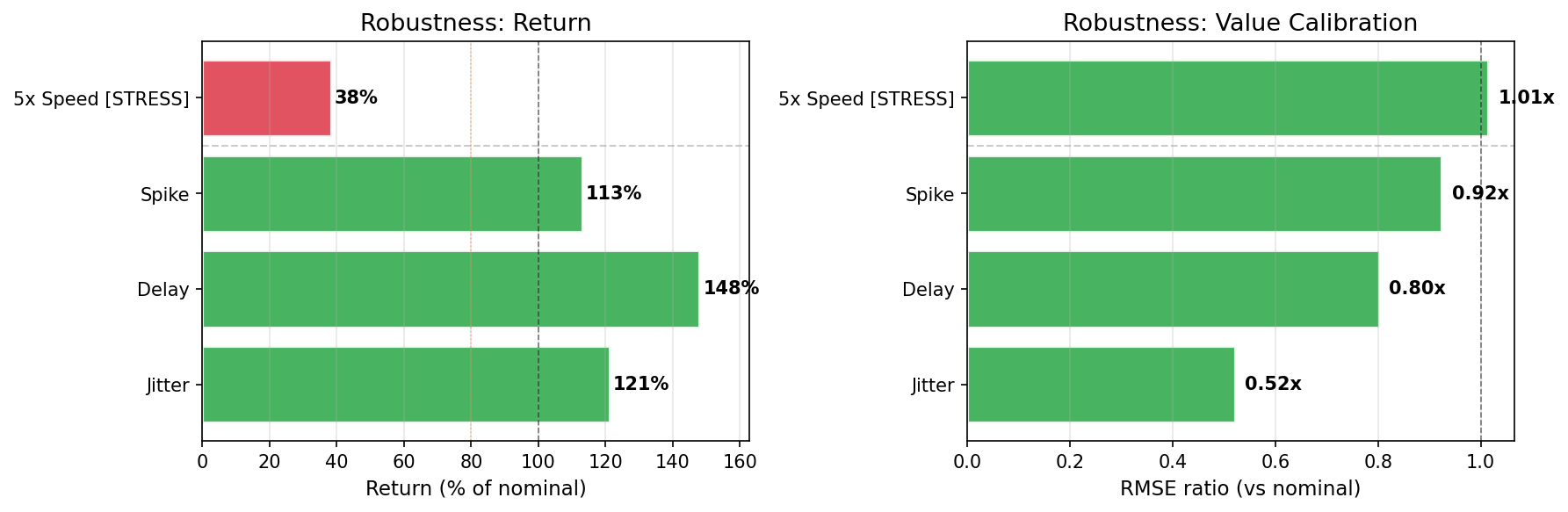
View Before report | View After report
Reproduce HalfCheetah results
pip install "deltatau-audit[sb3,mujoco]"
git clone https://github.com/maruyamakoju/deltatau-audit.git
cd deltatau-audit
python examples/audit_halfcheetah.py # standard PPO audit (~30 min)
python examples/train_robust_halfcheetah.py # train robust PPO (~30 min)
python examples/audit_before_after.py # Before/After comparison
Or download pre-trained models from Releases.
Install
pip install deltatau-audit # core
pip install "deltatau-audit[demo]" # + CartPole demo (recommended start)
pip install "deltatau-audit[sb3,mujoco]" # + SB3 + MuJoCo environments
Find and Fix in One Command
pip install "deltatau-audit[sb3]"
deltatau-audit fix-sb3 --algo ppo --model my_model.zip --env HalfCheetah-v5
This single command:
- Audits your model (finds timing failures)
- Retrains with speed randomization (the fix)
- Re-audits the fixed model (verifies the fix)
- Generates Before/After comparison report
BEFORE vs AFTER
Scenario Before After Change
------------ ---------- ---------- ----------
speed_5x 12.7% 76.6% + 63.9pp
jitter 43.7% 100.0% + 56.3pp
delay 100.0% 100.0% + 0.0pp
spike 26.7% 91.9% + 65.2pp
Deployment: FAIL (0.27) -> MILD (0.92)
Quadrant: deployment_fragile -> deployment_ready
Output: fixed model (.zip) + HTML reports + comparison.html (+ comparison.md).
Options: --timesteps (training budget), --speed-min/--speed-max (speed range), --workers (parallel episodes), --seed (reproducible), --ci (pipeline gate).
Audit Your Own SB3 Model
Just want the diagnosis? Use audit-sb3:
deltatau-audit audit-sb3 --algo ppo --model my_model.zip --env HalfCheetah-v5 --out my_report/
# Faster — use all CPU cores:
deltatau-audit audit-sb3 --algo ppo --model my_model.zip --env HalfCheetah-v5 --workers auto
# Reproducible:
deltatau-audit audit-sb3 --algo ppo --model my_model.zip --env HalfCheetah-v5 --seed 42
No model handy? Try with a sample:
gh release download assets -R maruyamakoju/deltatau-audit -p cartpole_ppo_sb3.zip
deltatau-audit audit-sb3 --algo ppo --model cartpole_ppo_sb3.zip --env CartPole-v1
Supported algorithms: ppo, sac, td3, a2c. Any Gymnasium environment ID works.
Python API (for custom workflows)
# Audit only
from deltatau_audit.adapters.sb3 import SB3Adapter
from deltatau_audit.auditor import run_full_audit
from deltatau_audit.report import generate_report
from stable_baselines3 import PPO
import gymnasium as gym
model = PPO.load("my_model.zip")
adapter = SB3Adapter(model)
result = run_full_audit(
adapter,
lambda: gym.make("HalfCheetah-v5"),
speeds=[1, 2, 3, 5, 8],
n_episodes=30,
n_workers=4, # parallel episode collection
seed=42, # reproducible results
)
generate_report(result, "my_audit/", title="My Agent Audit")
# Full fix pipeline
from deltatau_audit.fixer import fix_sb3_model
result = fix_sb3_model("my_model.zip", "ppo", "HalfCheetah-v5",
output_dir="fix_output/")
# result["fixed_model_path"] -> "fix_output/ppo_fixed.zip"
What It Measures
| Badge | What it tests | How |
|---|---|---|
| Reliance | Does the agent use internal timing? | Tampers with internal Δτ, measures value prediction error |
| Deployment | Does the agent survive realistic timing changes? | Speed jitter, observation delay, mid-episode spikes, sensor noise |
| Stress | Does the agent survive extreme timing changes? | 5× speed (unseen during training) |
Deployment scenarios (4): jitter (speed 2±1), delay (1-step obs lag), spike (1→5→1), obs_noise (Gaussian σ=0.1 on observations). All four run automatically.
Agents without internal timing (standard PPO, SAC, etc.) get Reliance: N/A — only Deployment and Stress are tested.
Rating Scale
| Rating | Return Ratio | Meaning |
|---|---|---|
| PASS | > 95% | Production ready |
| MILD | > 80% | Minor degradation |
| DEGRADED | > 50% | Significant loss |
| FAIL | <= 50% | Agent breaks |
All return ratios include bootstrap 95% confidence intervals with significance testing.
Performance
By default all episodes run serially. Use --workers to parallelize:
# Auto-detect CPU core count (recommended for local runs)
deltatau-audit audit-sb3 --algo ppo --model model.zip --env HalfCheetah-v5 --workers auto
# Explicit count
deltatau-audit demo cartpole --workers 4
| Workers | 30 episodes × 5 scenarios | Speedup |
|---|---|---|
| 1 (default) | ~3 min (CartPole) | — |
| 4 | ~50 sec | ~3.5× |
| auto (8 cores) | ~30 sec | ~6× |
--workers auto maps to os.cpu_count(). Works with all audit-* and demo subcommands. For reproducibility, pair with --seed 42 (parallel order is non-deterministic but per-episode seeds are fixed).
CI Mode
python -m deltatau_audit demo cartpole --ci --out ci_report/
# exit 0 = pass, exit 1 = warn (stress), exit 2 = fail (deployment)
Outputs ci_summary.json and ci_summary.md for pipeline gates and PR comments.
GitHub Action (one line)
- uses: maruyamakoju/deltatau-audit@main
with:
command: audit-sb3
model: model.zip
algo: ppo
env: CartPole-v1
extras: sb3
Outputs status, deployment-score, stress-score for downstream steps. Exit code 0/1/2 for pass/warn/fail.
Full workflow examples
CartPole demo gate (zero config):
- uses: maruyamakoju/deltatau-audit@main
- uses: actions/upload-artifact@v4
if: always()
with:
name: timing-audit
path: audit_report/
Audit your own SB3 model:
- uses: maruyamakoju/deltatau-audit@main
id: audit
with:
command: audit-sb3
model: model.zip
algo: ppo
env: HalfCheetah-v5
extras: "sb3,mujoco"
- run: echo "Deployment score: ${{ steps.audit.outputs.deployment-score }}"
Manual install (if you prefer):
- run: pip install "deltatau-audit[sb3]"
- run: deltatau-audit audit-sb3 --algo ppo --model model.zip --env CartPole-v1 --ci
Speed-Randomized Training (the fix)
The fix for timing failures is simple: train with variable speed. Use JitterWrapper during SB3 training:
import gymnasium as gym
from stable_baselines3 import PPO
from deltatau_audit.wrappers import JitterWrapper
# Wrap env with speed randomization (speed 1-5)
env = JitterWrapper(gym.make("CartPole-v1"), base_speed=3, jitter=2)
model = PPO("MlpPolicy", env)
model.learn(total_timesteps=100_000)
model.save("robust_model")
This is exactly what fix-sb3 does under the hood. Use the wrapper directly when you want more control over training.
Available wrappers: JitterWrapper (random speed), FixedSpeedWrapper (constant speed), PiecewiseSwitchWrapper (scheduled speed changes), ObservationDelayWrapper (sensor delay), ObsNoiseWrapper (Gaussian observation noise).
Audit CleanRL Agents
CleanRL agents are plain nn.Module subclasses — no framework wrapper needed.
deltatau-audit audit-cleanrl \
--checkpoint runs/CartPole-v1/agent.pt \
--agent-module ppo_cartpole.py \
--agent-class Agent \
--agent-kwargs obs_dim=4,act_dim=2 \
--env CartPole-v1
Or via Python API:
from deltatau_audit.adapters.cleanrl import CleanRLAdapter
# Agent class must implement get_action_and_value(obs)
adapter = CleanRLAdapter(agent, lstm=False)
result = run_full_audit(adapter, env_factory, speeds=[1, 2, 3, 5, 8])
LSTM agents: pass --lstm (CLI) or CleanRLAdapter(agent, lstm=True) (API).
See examples/audit_cleanrl.py for a complete runnable example.
Sim-to-Real Transfer
Timing failures are one of the main causes of sim-to-real gaps. A policy that runs at 50 Hz in simulation may be deployed at 30 Hz or with variable latency in the real world — and collapse.
Simulation → Reality
50 Hz → 30 Hz (0.6x speed)
Fixed dt → Variable dt (jitter)
Instant obs → Observation delay (network/sensor lag)
Stable → Mid-episode spikes (system load)
deltatau-audit measures exactly these failure modes. If your agent passes Deployment ≥ MILD, it is likely to survive real-world timing variation.
IsaacLab / RSL-RL
For policies trained with IsaacLab (RSL-RL format):
from deltatau_audit.adapters.torch_policy import TorchPolicyAdapter
# Define your actor/critic architectures (same as training)
actor = MyActorNet(obs_dim=48, act_dim=12)
critic = MyCriticNet(obs_dim=48)
# Loads RSL-RL checkpoint format automatically
adapter = TorchPolicyAdapter.from_checkpoint(
"model.pt",
actor=actor,
critic=critic,
is_discrete=False, # continuous actions
)
result = run_full_audit(adapter, env_factory, speeds=[1, 2, 3, 5])
Supported checkpoint formats:
{"model_state_dict": {"actor.*": ..., "critic.*": ...}}(RSL-RL){"actor": state_dict, "critic": state_dict}(explicit split)- Raw
state_dict(actor-only)
Or use a callable — no checkpoint loading needed:
# Works with any framework's inference API
def my_act(obs):
action = runner.alg.actor_critic.act(obs)
value = runner.alg.actor_critic.evaluate(obs)
return action, value
adapter = TorchPolicyAdapter(my_act)
See examples/isaaclab_skeleton.py for a complete IsaacLab skeleton.
Custom Adapters
Implement AgentAdapter (see deltatau_audit/adapters/base.py):
from deltatau_audit.adapters.base import AgentAdapter
class MyAdapter(AgentAdapter):
def reset_hidden(self, batch=1, device="cpu"):
return torch.zeros(batch, hidden_dim)
def act(self, obs, hidden):
# Returns: (action, value, hidden_new, dt_or_None)
...
return action, value, hidden_new, None
Built-in adapters: SB3Adapter (PPO/SAC/TD3/A2C), SB3RecurrentAdapter (RecurrentPPO), CleanRLAdapter (CleanRL MLP/LSTM), TorchPolicyAdapter (IsaacLab/RSL-RL/custom), InternalTimeAdapter (Dt-GRU models).
Compare Two Audits
After auditing a fixed model, compare to a previous result in one command:
# Generate comparison.html alongside the new audit
deltatau-audit audit-sb3 --algo ppo --model fixed.zip --env HalfCheetah-v5 \
--compare before_audit/summary.json --out after_audit/
Or use the diff subcommand directly (writes both .md and .html):
python -m deltatau_audit diff before/summary.json after/summary.json --out comparison.md
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file deltatau_audit-0.4.9.tar.gz.
File metadata
- Download URL: deltatau_audit-0.4.9.tar.gz
- Upload date:
- Size: 249.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
13c25a53c81285043a2a869a4f4e6a114647b025c71a645222979d04c9445809
|
|
| MD5 |
3dd3330340e2ccfe6fc2eea87fee9a1b
|
|
| BLAKE2b-256 |
174bd4644b8e880e7df8e89a4faa90886e164d763e76b76ec0876dd4e821d758
|
Provenance
The following attestation bundles were made for deltatau_audit-0.4.9.tar.gz:
Publisher:
release.yml on maruyamakoju/deltatau-audit
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
deltatau_audit-0.4.9.tar.gz -
Subject digest:
13c25a53c81285043a2a869a4f4e6a114647b025c71a645222979d04c9445809 - Sigstore transparency entry: 968023735
- Sigstore integration time:
-
Permalink:
maruyamakoju/deltatau-audit@edee9387ab7cd4537ae08fa430ed4e2ff6fca396 -
Branch / Tag:
refs/tags/v0.4.9 - Owner: https://github.com/maruyamakoju
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@edee9387ab7cd4537ae08fa430ed4e2ff6fca396 -
Trigger Event:
push
-
Statement type:
File details
Details for the file deltatau_audit-0.4.9-py3-none-any.whl.
File metadata
- Download URL: deltatau_audit-0.4.9-py3-none-any.whl
- Upload date:
- Size: 236.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2700594cbb7d70eb7fa0d9a9ba2914d4d1eba1ba0203ddabde6e013f0e5e13cc
|
|
| MD5 |
00fe886d47b19515df4e6feac76a26cc
|
|
| BLAKE2b-256 |
1e1e59c58fa47a11274f8de6c02b6e1375ef37c6d3df6f203f1a21cf62329fb5
|
Provenance
The following attestation bundles were made for deltatau_audit-0.4.9-py3-none-any.whl:
Publisher:
release.yml on maruyamakoju/deltatau-audit
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
deltatau_audit-0.4.9-py3-none-any.whl -
Subject digest:
2700594cbb7d70eb7fa0d9a9ba2914d4d1eba1ba0203ddabde6e013f0e5e13cc - Sigstore transparency entry: 968023774
- Sigstore integration time:
-
Permalink:
maruyamakoju/deltatau-audit@edee9387ab7cd4537ae08fa430ed4e2ff6fca396 -
Branch / Tag:
refs/tags/v0.4.9 - Owner: https://github.com/maruyamakoju
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@edee9387ab7cd4537ae08fa430ed4e2ff6fca396 -
Trigger Event:
push
-
Statement type:







