Scrapers for extracting articles from Finnish journalistic media websites.

Project description
Finnish Media Scrapers



Scrapers for extracting articles from Finnish journalistic media websites by the University of Helsinki Human Sciences – Computing Interaction research group. Included are scrapers for YLE, Helsingin Sanomat, Iltalehti and Iltasanomat.
The scrapers have been designed for researchers needing a local corpus of news article texts matching a specified set of query keywords as well as temporal limitations. As a design principle, these scrapers have been designed to extract the articles in as trustworthy a manner as possible, as required for content-focused research targetting the text of those articles (for an example of such research, see e.g. here). Thus, the scrapers will complain loudly for example if your search query matches more articles than the APIs are willing to return, or if the plain text extractors encounter new article layouts that have not yet been verified to extract correctly. Further, the process is split into distinct parts that 1) query, 2) fetch, 3) convert to text and 4) post-filter the articles separately. Each of these steps also records its output as separate files. Each of these steps also records its output as separate files. This way, the tools can be used in a versatile manner. Further, a good record is maintained of the querying and filtering process for reproducibility as well as error analysis.
Installation
Install the scripts (and Python module) using pip install finnish-media-scrapers. After this, the scripts should be useable from the command line, and the functionality importable from Python. Or, if you have pipx and just want the command line scripts, use pipx install finnish-media-scrapers instead.
General workflow
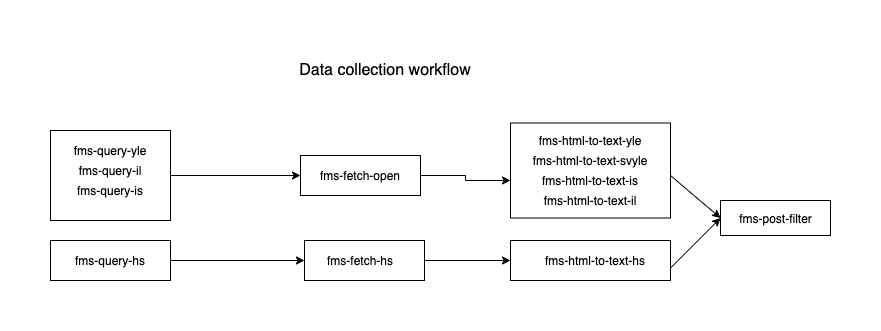
The general workflow for using the scrapers is as follows:
- Query YLE/HS/IL/IS APIs for matching articles using the scripts
fms-query-{yle|hs|il|is}, which output all matching articles with links into CSVs. - Fetch the matching articles using
fms-fetch-{hs|open}. These save the articles as HTML files in a specified directory. - Extract the plain text from the article HMTL using
fms-html-to-text-{yle|svyle|hs|il|is}. - Optionally refilter the results using
fms-post-filter.
Important to know when applying the workflow is that due to the fact that all the sources use some kind of stemming for their search, they can often return also spurious hits. Further, if searching for multiple words, the engines often perform a search for either word instead of the complete phrase. The post-filtering script above exists to counteract this by allowing the refiltering of the results more rigorously and uniformly locally.
At the same time and equally importantly, the stemming for a particular media may not cover e.g. all inflectional forms of words. Thus, it often makes sense to query for at least all common inflected variants and merge the results. For a complete worked up example of this kind of use, see the members_of_parliament folder, which demonstrates how one can collect and count how many articles in each media mention chairperson of National Coalition Party (Petteri Orpo) or alternatively all members of the Finnish Parliament.
To be a good netizen, when using the scripts, by default there is a one second delay between each web request to the media websites to ensure that scraping will not cause undue load on their servers. This is however configurable using command line parameters.
Apart from using the scripts, the functionality of the package is also provided as a python module that you may use programmatically from within Python. For the functionalities thus provided, see the module documentation.
Media-specific instructions and caveats
Helsingin Sanomat
First, query the articles you want using fms-query-hs. For example, fms-query-hs -f 2020-02-16 -t 2020-02-18 -o hs-sdp.csv -q SDP.
For downloading articles, use fms-fetch-hs with adding credentials. For example fms-fetch-hs -i hs-sdp.csv -o hs-sdp -u username -p password. This scraper requires paid Helsingin Sanomat credentials (user id and password). You can create them in https://www.hs.fi/ with clicking "Kirjaudu" button and following the instructions for a news subscription.
Technically, the scraper uses pyppeteer to control a headless Chromium browser to log in and ensure the dynamically rendered content in HS articles is captured. To ensure a compatible Chromium, when first running the tool, pyppeteer will download an isolated version of Chromium for itself, causing some ~150MB of network traffic and disk space usage.
After fetching the articles, extract texts with e.g. fms-html-to-text-hs -o hs-sdp-output hs-sdp.
Known special considerations:
- The search engine used seems to be employing some sort of stemming/lemmatization, so e.g. the query string
kokseems to matchkokki,kokoandkoki. - A single query can return at most 9,950 hits. This can be sidestepped by invoking the script multiple times with smaller query time spans.
Yle
example: fms-query-yle -f 2020-02-16 -t 2020-02-18 -o yle-sdp.csv -q SDP + fms-fetch-open -i yle-sdp.csv -o yle-sdp + fms-html-to-text-yle -o yle-sdp-output yle-sdp (or fms-html-to-text-svyle -o svyle-sdp-output svyle-sdp if articles come from Svenska YLE)
Known special considerations:
- A single query can return at most 10,000 hits. This can be sidestepped by invoking the script multiple times with smaller query time spans.
Iltalehti
example: fms-query-il -f 2020-02-16 -t 2020-02-18 -o il-sdp.csv -q SDP + fms-fetch-open -i il-sdp.csv -o il-sdp + fms-html-to-text-il -o il-sdp-output il-sdp
Iltasanomat
example: fms-query-is -f 2020-02-16 -t 2020-02-18 -o is-sdp.csv -q SDP + fms-fetch-open -i is-sdp.csv -o is-sdp + fms-html-to-text-is -o is-sdp-output is-sdp
Known special considerations:
- The search engine used seems to be employing some sort of stemming/lemmatization, so e.g. the query string
kokseems to matchkokki,kokoandkoki. - A single query can return at most 9,950 hits. This can be sidestepped by invoking the script multiple times with smaller query time spans.
Using the fms-post-filter script
For example, after collecting texts from Helsingin Sanomat with the example above, run:
fms-post-filter -i hs-sdp.csv -t hs-sdp-output/ -o hs-sdp-filtered.csv -q SDP
where -i parameter specifies the query output file, -t the folder name to search extracted texts, -o the output filename and -q search word to filter.
There is also an option -ci for configuring the case-insensitiveness (default false).
Contact
For more information on the scrapers, please contact associate professor Eetu Mäkelä. For support on using them or for reporting problems or issues, we suggest you to use the facilities provided by GitHub.
Development
Pull requests welcome! To set up a development environment, you need poetry. Then, use poetry to install and manage the dependencies and build process (poetry install).
Citation

@article{Mäkelä2021,
doi = {10.21105/joss.03504},
url = {https://doi.org/10.21105/joss.03504},
year = {2021},
publisher = {The Open Journal},
volume = {6},
number = {68},
pages = {3504},
author = {Eetu Mäkelä and Pihla Toivanen},
title = {Finnish Media Scrapers},
journal = {Journal of Open Source Software}
}
Related work
For a more general library for crawling media articles, have a look at newspaper3k as well as news-please, which has been built on top of it. Do note however that at the time of writing this, it is unclear whether newspaper3k is being maintained any more. More importantly for content research purposes, note that 1) newspaper3k does not handle the Finnish news sources targeted by this crawler very well and 2) it is based more on a best-effort principle (suitable for extracting masses of data for e.g. NLP training) as opposed to completeness and verisimilitude (required for trustworthy content-focused research targetting a particular set of news). Thus, given an article URL, newspaper3k will happily try to return something from it, but not guarantee completeness. This crawler on the other hand has been designed to be conservative, and to complain loudly through logging whenever it encounters problems that may hinder extracting the actual text of the article, such as article layouts that haven't been yet handled and verified to extract correctly.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file finnish-media-scrapers-1.1.4.tar.gz.
File metadata
- Download URL: finnish-media-scrapers-1.1.4.tar.gz
- Upload date:
- Size: 17.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.1.12 CPython/3.10.1 Darwin/19.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
83ce4e218f9fb97fac47ce70c816cc084103f9534c791911ac959cabc63b8ddc
|
|
| MD5 |
af79258a5df914f1a27927583f841ad4
|
|
| BLAKE2b-256 |
90ed6d37c9281f1b1b95fb836a54b8eaf796b6fb8b57d6d9833e41baab6cc1c2
|
File details
Details for the file finnish_media_scrapers-1.1.4-py3-none-any.whl.
File metadata
- Download URL: finnish_media_scrapers-1.1.4-py3-none-any.whl
- Upload date:
- Size: 23.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.1.12 CPython/3.10.1 Darwin/19.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6789c4f3f115fb42c7ccae9eecb22ecd8e3a22e0277a65859fa15e15e9f47ae4
|
|
| MD5 |
6cee3491f8abea724105eb3d16121898
|
|
| BLAKE2b-256 |
6b87c82b995b7aa17236b42be2ab591c992a1a37a60419f580bc9a8f16582656
|







