Static Hash-Based Lookup for Google Ngram Frequencies

Project description
gngram-lookup






How common is this word? O(1) answer. 500 years of books. 5 million words.
Word frequency, commonness scores, and part-of-speech tags derived from the Google Books Ngram corpus, the largest longitudinal word-frequency dataset ever compiled.
Quick Start
pip install gngram-lookup
python -m gngram_lookup.download_data # frequency data, ~110 MB
python -m gngram_lookup.download_pos_data # POS tag data, optional
import gngram_lookup as ng
# Does this word exist in 500 years of print?
ng.exists('computer') # True
ng.exists('xyznotaword') # False
# How common is it? (1=most common, 100=least common)
ng.word_score('the') # 1
ng.word_score('computer') # 18
ng.word_score('rucksack') # 58
ng.word_score('xyznotaword') # None
# Full frequency data
ng.frequency('computer')
# {'peak_tf': 2000, 'peak_df': 2000, 'sum_tf': 892451, 'sum_df': 312876}
# Part-of-speech tags
ng.pos('fast') # ['ADJ', 'ADV', 'VERB']
ng.has_pos('sing', ng.PosTag.VERB) # True
Features
- O(1) Lookups - Hash-bucketed parquet files, no full scan
- 5 Million Words - Broadest vocabulary coverage of any static lookup package
- 500 Years of Data - 1500s through 2000s, decade-by-decade
- Word Score - 1–100 commonness scale, log-normalized against the corpus
- Peak Decade - Know when a word was most used in print
- POS Tags - Part-of-speech tags from Google's own tag set
- Batch Lookup - Efficient multi-word queries grouped by hash prefix
- Possessive & Hyphen Fallback -
ship's→ship,north-west→north - Unicode Normalization - Smart quotes, accents, and Unicode apostrophes handled
Word Score Zones
Words are scored 1–100 based on their total corpus frequency, log-normalized against the (the most frequent word). The scale compresses the Zipfian spike at the top and gives meaningful resolution across the rest of the vocabulary.
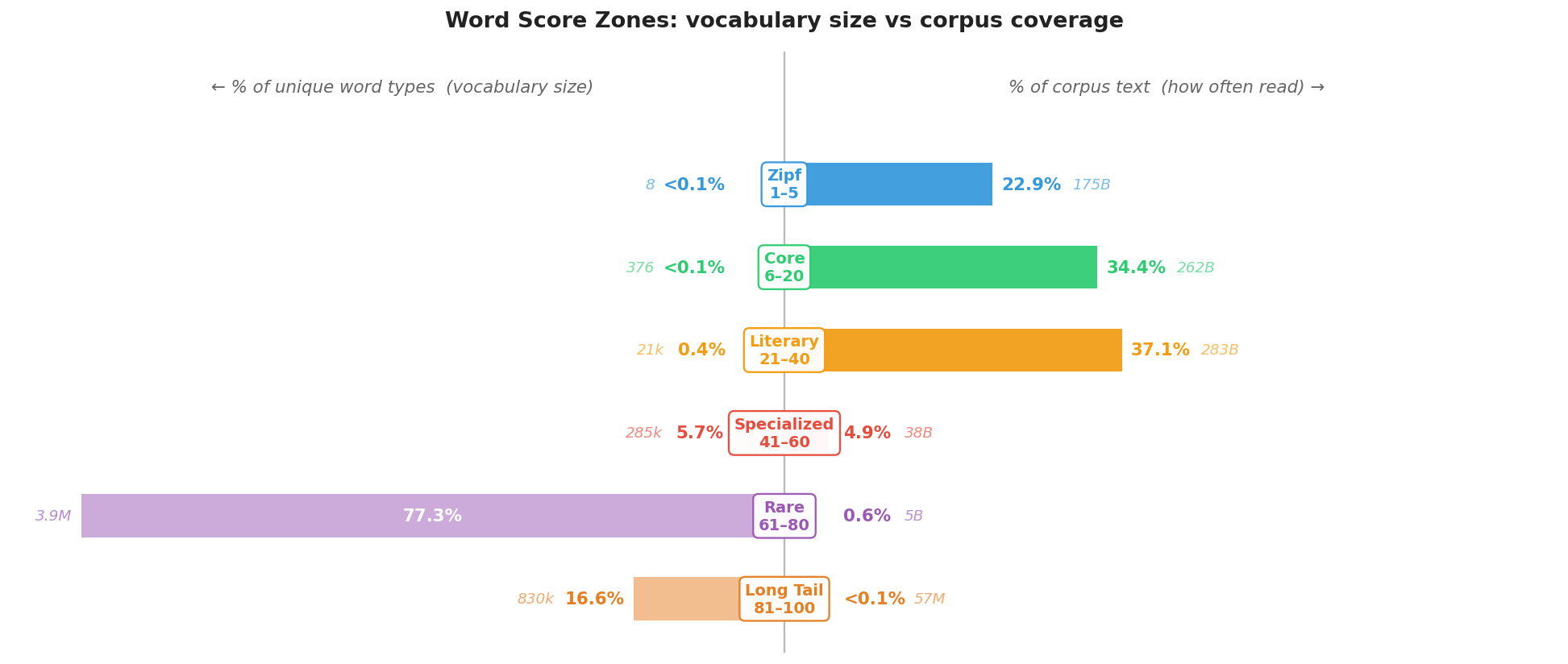
| Score | Zone | Description | Examples |
|---|---|---|---|
| 1–5 |  |
Function words dominating millions of books | the, of, and, to, a |
| 6–20 |  |
Everyday words known by all speakers | computer, walk, beautiful |
| 21–40 |  |
Vocabulary of books, not everyday speech | algorithm, philosophy, synthesis |
| 41–60 |  |
Domain-specific but attested | rucksack, carbonate, heliotrope |
| 61–80 |  |
Infrequent but legitimate | arcane technical and literary terms |
| 81–100 |  |
Extremely low frequency | niche, archaic, or highly specialized |
import gngram_lookup as ng
# Score a word
ng.word_score('the') # 1 (Zipfian summit)
ng.word_score('computer') # 18 (Core vocabulary)
ng.word_score('algorithm') # 40 (Educated vocabulary)
ng.word_score('rucksack') # 58 (Specialized vocabulary)
# Filter to common words only
def is_common(word):
score = ng.word_score(word)
return score is not None and score <= 30
The Problem This Solves
In NLP, you frequently need to know not just whether a token is a word, but how common it is.
Not "what does it mean?" Not "what's its etymology?" Just: is this a word real people actually write, and how often?
No other static lookup package gives you this from a corpus spanning 500 years of print at 5 million word coverage with O(1) access.
Why Google Books Ngrams?
The Google Books Ngram corpus isn't a dictionary (too narrow). It isn't a web crawl (too noisy). It isn't limited to a single decade or language register.
It's a statistical analysis of over 8 million books spanning the 1500s to the 2000s, one of the largest datasets ever assembled for studying how language changes over time. The frequency data captures real written usage at a scale no other freely available corpus matches.
If a word appears in this corpus with meaningful frequency, it's a word that real writers actually used.
When to Use This
- Vocabulary filtering - Score words to keep common ones, discard rare ones
- NLP preprocessing - Filter candidates before expensive model calls
- Content analysis - Measure the reading level or register of a text
- Spell-check pre-filtering - Reject low-scoring tokens before fuzzy matching
- Temporal analysis - Find when a word peaked in usage
- POS disambiguation - Resolve ambiguous tokens using corpus-attested tags
What This Doesn't Do
- No definitions, synonyms, or semantic relationships (use spaCy or WordNet for that)
- No spell-checking or suggestions (just existence and frequency)
- No real-time or web data (this is a static corpus snapshot)
CLI
exists computer # True, exit 0
exists xyznotaword # False, exit 1
score computer # 18
score xyznotaword # None, exit 1
freq computer
# peak_tf_decade: 2000
# peak_df_decade: 2000
# sum_tf: 892451
# sum_df: 312876
pos fast # ADJ ADV VERB
pos-freq corn # ADJ: 1,433,642 / NOUN: 11,722,803 / VERB: 85,411
has-pos sing VERB # True, exit 0
has-pos fast NOUN # False, exit 1
Documentation
Development
git clone https://github.com/craigtrim/gngram-lookup.git
cd gngram-lookup
make install # Install dependencies
make test # Run tests
make all # Full pipeline
See Also
- bnc-lookup - O(1) lookup for British National Corpus (669k words, zero setup)
- wordnet-lookup - O(1) lookup for WordNet
Attribution
Data derived from the Google Books Ngram dataset.
License
This package is dual-licensed:
- Software: MIT License
- Ngram Data: Creative Commons Attribution 3.0 Unported (CC BY 3.0)
See LICENSE for complete terms.
Links
- Repository: github.com/craigtrim/gngram-lookup
- PyPI: pypi.org/project/gngram-lookup
- Author: Craig Trim (craigtrim@gmail.com)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file gngram_lookup-1.2.6.tar.gz.
File metadata
- Download URL: gngram_lookup-1.2.6.tar.gz
- Upload date:
- Size: 15.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.3.2 CPython/3.11.9 Darwin/25.3.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0c44da4a78c69c5b8540d0020cfbe759847674ac08f51e8897bcd95e2177ca60
|
|
| MD5 |
6b423b2842fe6e53481c0758c5c24517
|
|
| BLAKE2b-256 |
772aa615bddcbe102bb8a814bc69d32efd1dec0dbbdedefbffa590d677902c22
|
File details
Details for the file gngram_lookup-1.2.6-py3-none-any.whl.
File metadata
- Download URL: gngram_lookup-1.2.6-py3-none-any.whl
- Upload date:
- Size: 16.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.3.2 CPython/3.11.9 Darwin/25.3.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9256a77f04a45297efb19f9ee56dc4fcb6ad65ee27f296ba67ef6748a5ff0ba0
|
|
| MD5 |
5d363431e516ca1855d5ed6e59ea6e4f
|
|
| BLAKE2b-256 |
dd524055fedf4c318a1c4942ca9d30fb19457e4c8e606265ba0829d9ef8c3c00
|







