for creating fast and easy llm apps

Project description
LLMService

LLMService is a framework designed for building applications that leverage large language models (LLMs). It aims to provide a text generation library that adheres to established software development best practices. With a strong focus on Modularity and Separation of Concerns, Robust Error Handling, and Modern Software Engineering Principles, LLMService delivers a well-structured alternative to more monolithic frameworks like LangChain.
"LangChain isn't a library, it's a collection of demos held together by duct tape, fstrings, and prayers."
- Designed with 'Result Monad' design. This way while we are minimazing the expose, user can implement their control mechanism for all key events via returned dataclass
- Supports ratelimit aware async request. This is possible because of the usage of baseservice class logic. ALl llm generation logic is passing through one class enable us to keep track of ratelimits internally. And this info is used to dynamically alter asnyc workers at any moment.
- Supports batch requests
Architecture
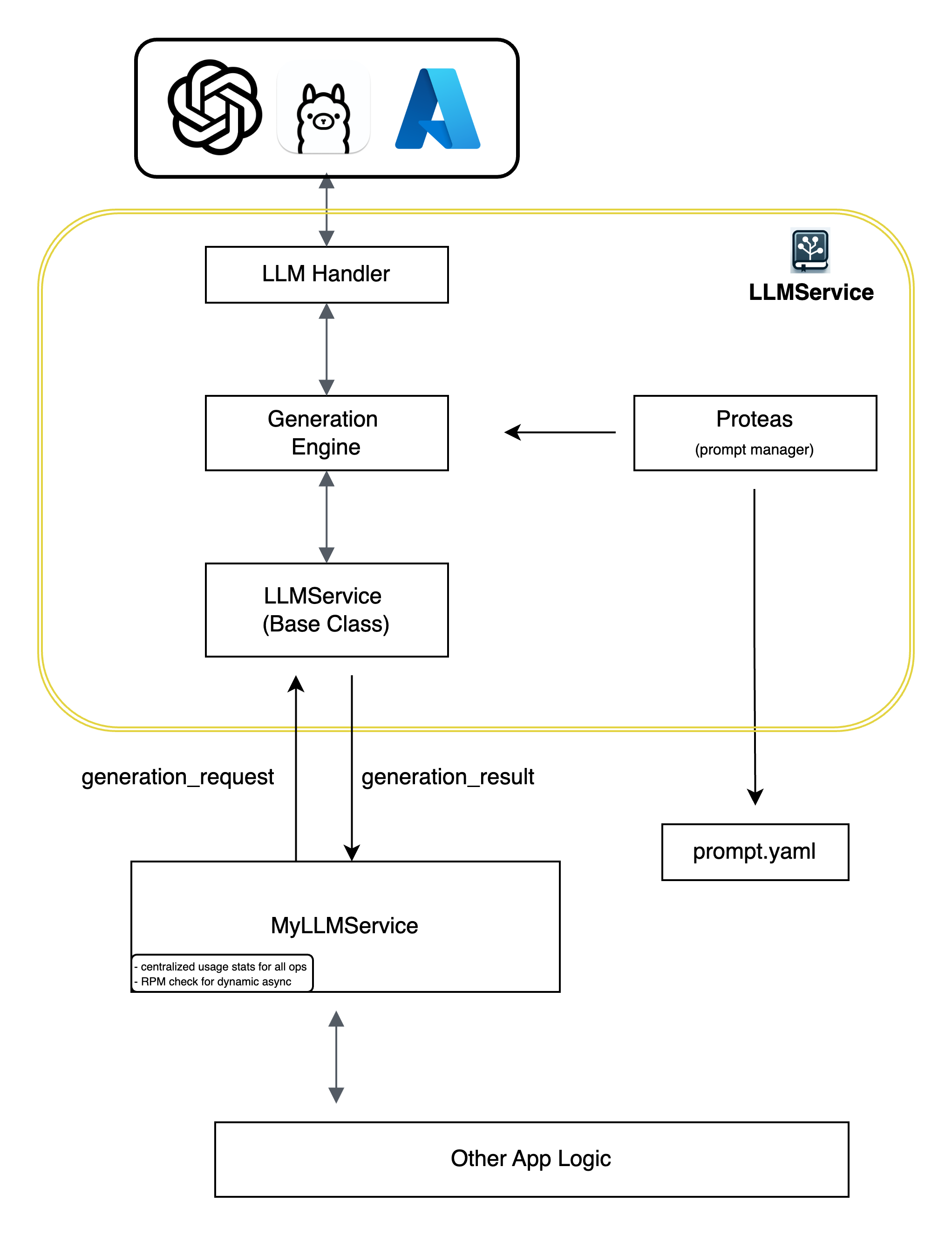
- LLM Handler: Manages interaction with different LLM providers (e.g., OpenAI, Ollama, Azure).
- Generation Engine: Orchestrates the generation process, including prompt crafting, invoking the LLM through llm handler, and post-processing.
- Proteas: A sophisticated prompt management system that loads and manages prompt templates from YAML files (
prompt.yaml). - LLMService (Base Class): A base class that serves as a template for users to implement their custom service logic.
- App: The application that consumes the services provided by LLMService, receiving structured
generation_resultresponses for further processing.
Features
Advanced Error Handling
LLMService incorporates sophisticated error handling mechanisms to ensure robust and reliable interactions with LLMs:
- Retry Mechanisms: Utilizes the
tenacitylibrary to implement retries with exponential backoff for handling transient errors like rate limits or network issues. - Custom Exception Handling: Provides tailored responses to specific errors (e.g., insufficient quota), enabling graceful degradation and clearer insights into failure scenarios.
Proteas: The Main Prompt Management System
Proteas serves as LLMService's core prompt management system, offering powerful tools for crafting, managing, and reusing prompts:
- Prompt Crafting: Utilizes
PromptTemplateto create consistent and dynamic prompts based on placeholders and data inputs. - Unit Skeletons: Supports loading and managing prompt templates from YAML files, promoting reusability and organization.
BaseLLMService Class
LLMService provides an abstract BaseLLMService class to guide users in implementing their own service layers:
- Modern Software Development Practices: Encourages adherence to best practices through a well-defined interface.
- Customization: Allows developers to tailor the service layer to their specific application needs while leveraging the core functionalities provided by LLMService.
- Extensibility: Facilitates the addition of new features and integrations without modifying the core library.
Installation
Install LLMService via pip:
pip install llmservice
Quick Start
Core Components
LLMService provides the following core modules:
llmhandler: Manages interactions with different LLM providers.generation_engine: Handles the process of prompt crafting, LLM invocation, and post-processing.base_service: Provides an abstract class that serves as a blueprint for building custom services.
Creating a Custom LLMService
To create your own service layer, follow these steps:
Step 0: Create your prompts.yaml file
Proteas uses a yaml file to load and manage your prompts. Prompts are encouraged to store as prompt template units where component of a prompt is decomposed into prompt template units and store in such way. To read more go to proteas docs (link here)
Create a new Python file (e.g., prompts.yaml)
add these lines
main:
- name: "input_paragraph"
statement_suffix: "Here is"
question_suffix: "What is "
placeholder_proclamation: input text to be translated
placeholder: "input_paragraph"
- name: "translate_to_russian"
info: >
take above text and translate it to russian with a scientific language, Do not output any additiaonal text.
Step 1: Subclass BaseLLMService
Create a new Python file (e.g., my_llm_service.py) and extend the BaseLLMService class.
In your app all llm generation data flow will go through this class. This is a good way of not coupling rest of your
app logic with LLM relevant logics.
You simply arange the names of your prompt template units in a list and pass this to generation engine.
from llmservice.base_service import BaseLLMService
from llmservice.generation_engine import GenerationEngine
import logging
class MyLLMService(BaseLLMService):
def __init__(self, logger=None):
self.logger = logger or logging.getLogger(__name__)
self.generation_engine = GenerationEngine(logger=self.logger, model_name="gpt-4o-mini")
def translate_to_russian(self, input_paragraph: str):
data_for_placeholders = {'input_paragraph': input_paragraph}
order = ["input_paragraph", "translate_to_russian"]
unformatted_prompt = self.generation_engine.craft_prompt(data_for_placeholders, order)
generation_result = self.generation_engine.generate_output(
unformatted_prompt,
data_for_placeholders,
response_type="string"
)
return generation_result.content
Step 2: Use the Custom Service
# app.py
from my_llm_service import MyLLMService
if __name__ == '__main__':
service = MyLLMService()
result = service.translate_to_russian("Hello, how are you?")
print(result)
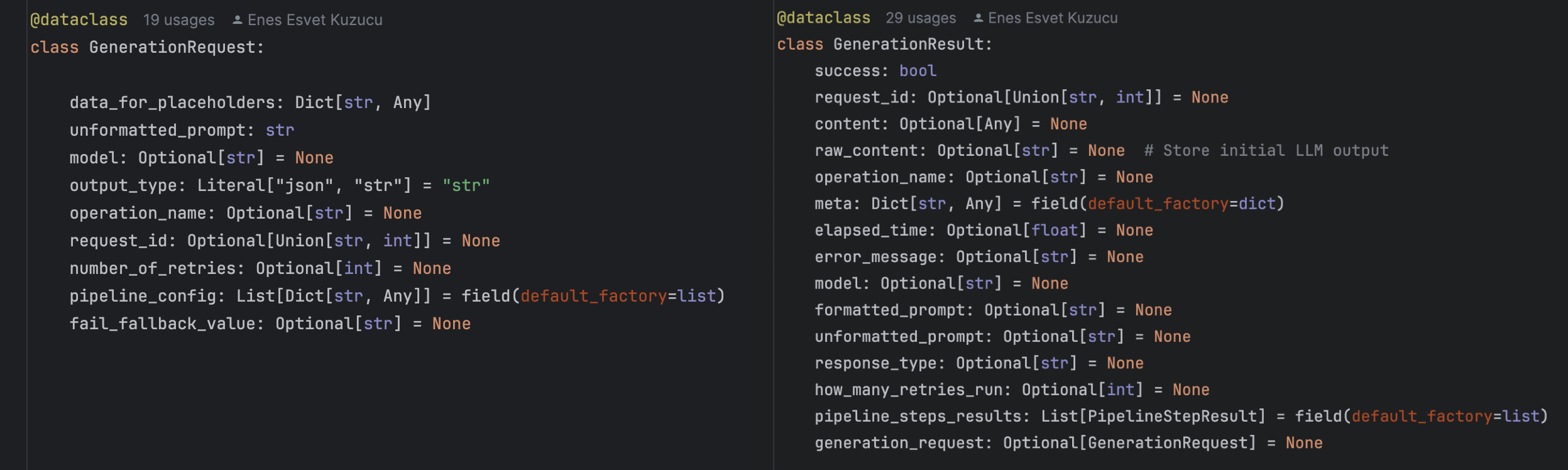
Result will be a generation_result object which inludes all the information you need.
some notes to add to future
The Result Monad enhances error management by providing detailed insights into why a particular operation might have failed, enhancing the robustness of systems that interact with external data. As evident from the examples, each of these monads facilitates the creation of function chains, employing a paradigm often referred to as a “railroad approach.” This approach visualizes the sequence of functions as a metaphorical railroad track, where the code smoothly travels along, guided by the monadic structure. The beauty of this railroad approach lies in its ability to elegantly manage complex computations and transformations, ensuring a structured and streamlined flow of operations.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file llmservice-0.1.7.tar.gz.
File metadata
- Download URL: llmservice-0.1.7.tar.gz
- Upload date:
- Size: 17.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.22
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7d14ce53881dedc74546bc44db8340b572ad569f5a4774777f2e8ef84d4200fa
|
|
| MD5 |
3f6944fa3681a53a2614517c4b104aec
|
|
| BLAKE2b-256 |
a3996ae50ca8023b02a09be37669f00333e673eb254673ed31ac1211aff47f8a
|
File details
Details for the file llmservice-0.1.7-py3-none-any.whl.
File metadata
- Download URL: llmservice-0.1.7-py3-none-any.whl
- Upload date:
- Size: 16.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.22
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f80cbb8dbd4e2dd86fc4bd13eebe34d324959b770da3c646aaba626d69a225e8
|
|
| MD5 |
4b6bebf4e62923253d2555dbcfcfda8c
|
|
| BLAKE2b-256 |
1703c03248c6713768a4acba0fb916488758133d8c4f8fd2b9f64bc47f67ab73
|







