AI Memory and Conversation Management Framework - Simple as mem0, Powerful as MemU
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers



Project description

MemU: A Future-Oriented Agentic Memory System





MemU is an agentic memory framework for LLM and AI agent backends. It receive multi-modal inputs, extracts them into memory items, and then organizes and summarizes these items into structured memory files.
Unlike traditional RAG systems that rely solely on embedding-based search, MemU supports non-embedding retrieval through direct file reading. The LLM comprehends natural language memory files directly, enabling deep search by progressively tracking from categories → items → original resources.
MemU offers several convenient ways to get started right away:
-
One call = response + memory 👉 memU Response API: https://memu.pro/docs#responseapi
-
Try it instantly 👉 https://app.memu.so/quick-start
⭐ Star Us on GitHub
Star MemU to get notified about new releases and join our growing community of AI developers building intelligent agents with persistent memory capabilities.
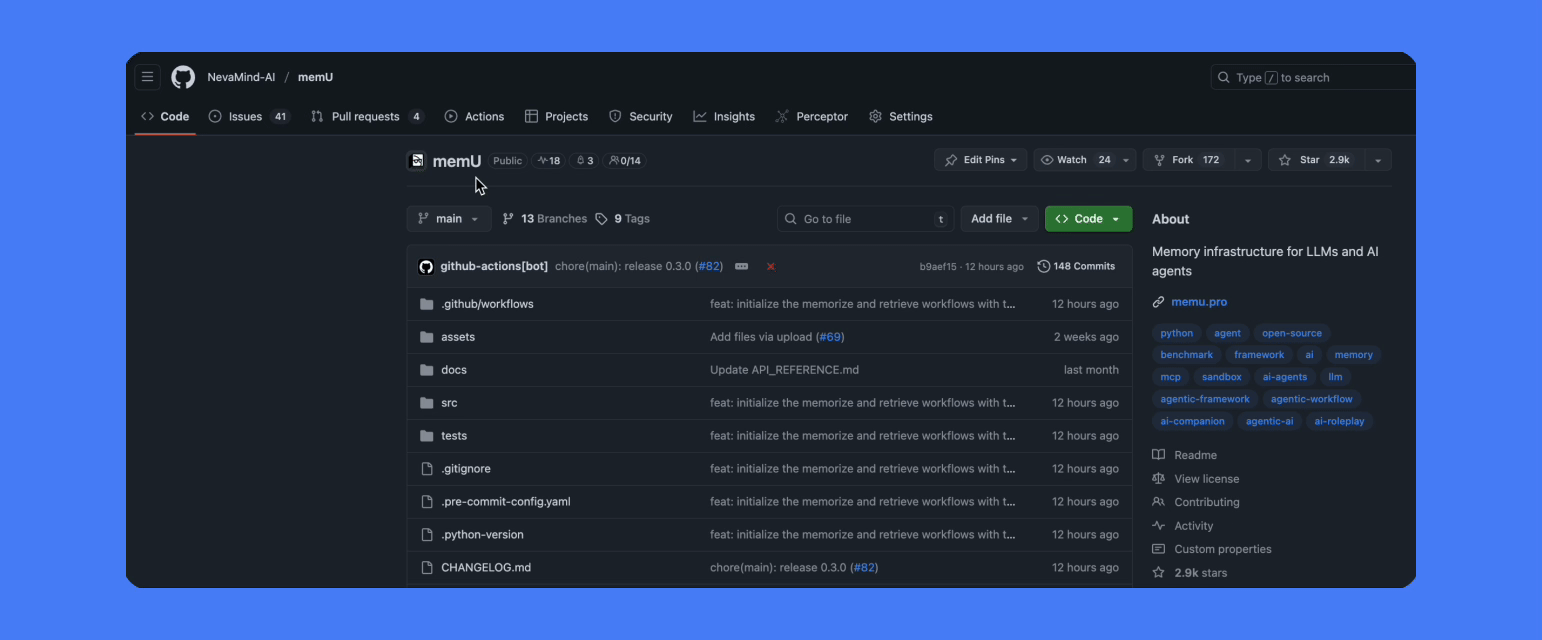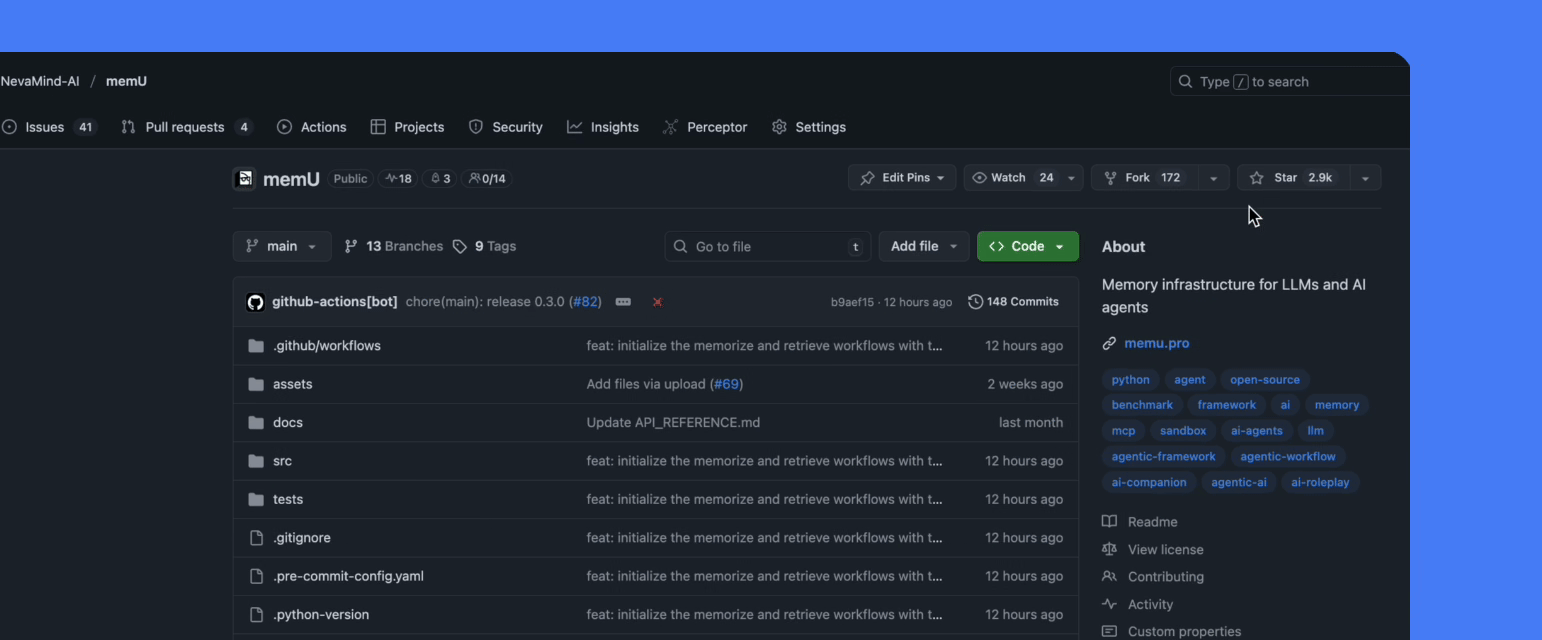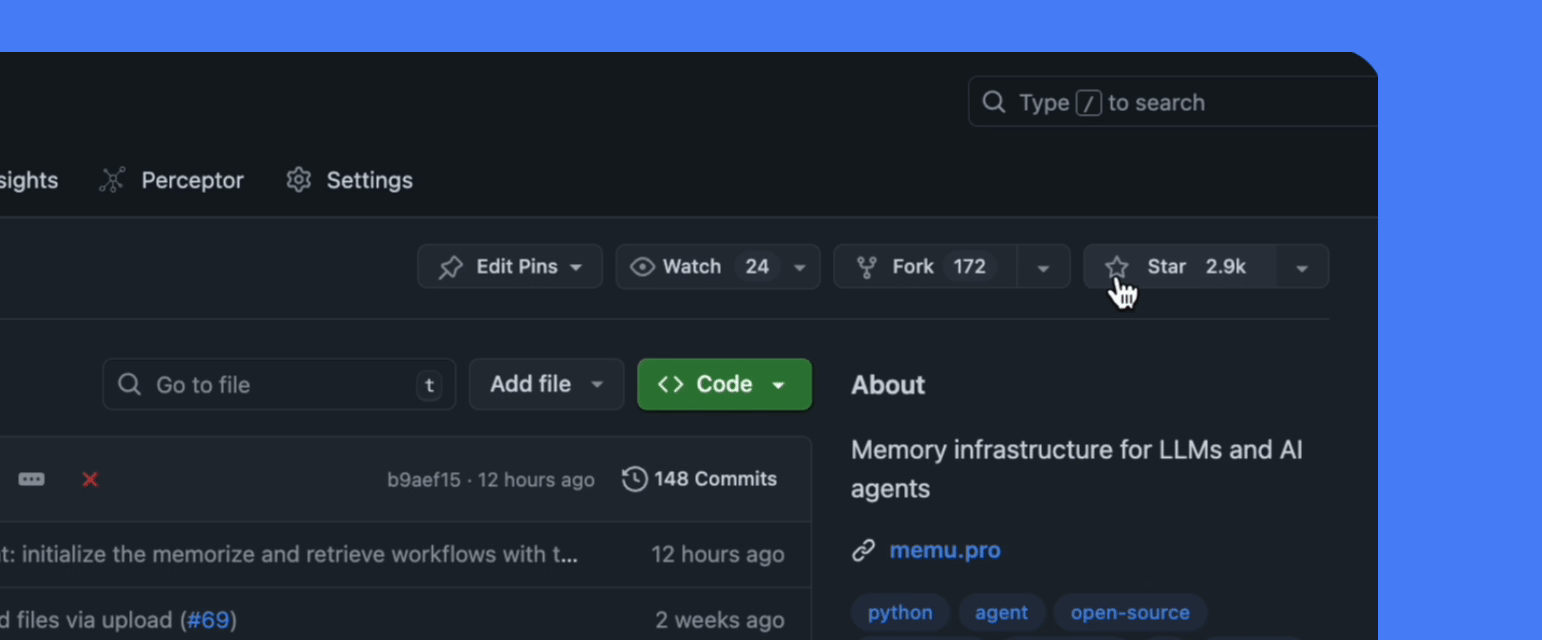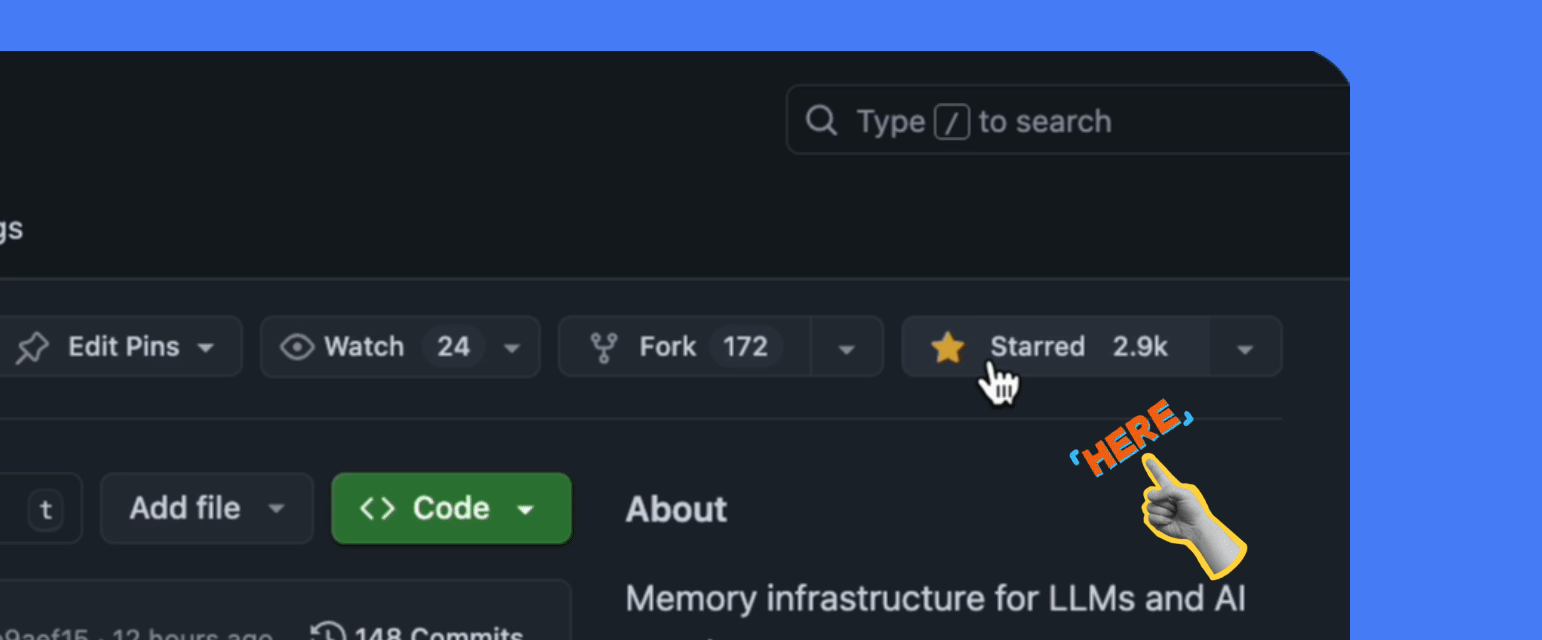
💬 Join our Discord community: https://discord.gg/memu
Roadmap
MemU v0.3.0 has been released! This version initializes the memorize and retrieve workflows with the new 3-layer architecture.
Starting from this release, MemU will roll out multiple features in the short- to mid-term:
Core capabilities iteration
- Multi-modal enhancements – Support for images, audio, and video
- Intention – Higher-level decision-making and goal management
- Multi-client support – Switch between OpenAI, Deepseek, Gemini, etc.
- Data persistence expansion – Support for Postgres, S3, DynamoDB
- Benchmark tools – Test agent performance and memory efficiency
- ……
Upcoming open-source repositories
- memU-ui – The web frontend for MemU, providing developers with an intuitive and visual interface
- memU-server – Powers memU-ui with reliable data support, ensuring efficient reading, writing, and maintenance of agent memories
🧩 Why MemU?
Most memory systems in current LLM pipelines rely heavily on explicit modeling, requiring manual definition and annotation of memory categories. This limits AI’s ability to truly understand memory and makes it difficult to support diverse usage scenarios.
MemU offers a flexible and robust alternative, inspired by hierarchical storage architecture in computer systems. It progressively transforms heterogeneous input data into queryable and interpretable textual memory.
Its core architecture consists of three layers: Resource Layer → Memory Item Layer → MemoryCategory Layer.
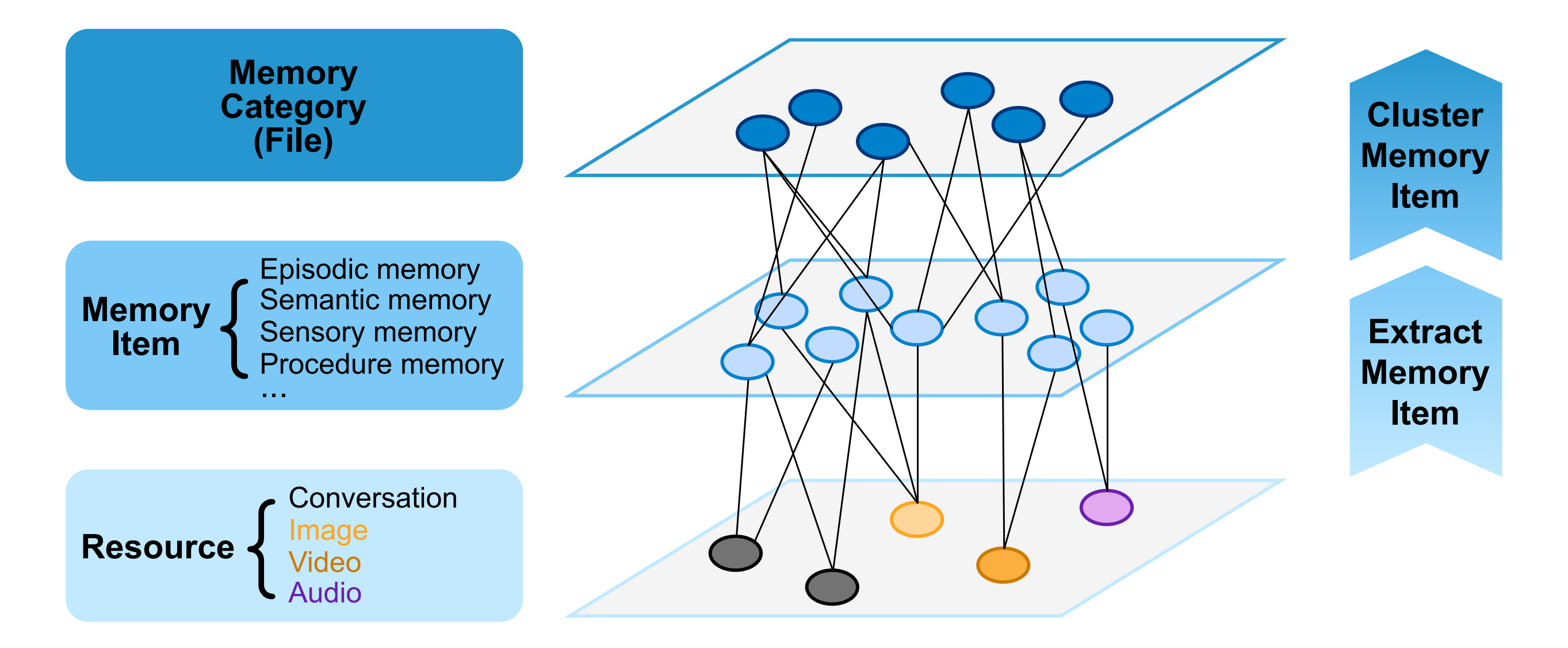
-
Resource Layer: A multimodal raw data warehouse, also serving as the ground truth layer, providing a semantic foundation for the memory system.
-
Memory Item Layer: A unified semantic abstraction layer, functioning as the system’s semantic cache, supplying high-density semantic vectors for downstream retrieval and reasoning.
-
MemoryCategory Layer: A thematic document layer, mimicking human working memory mechanisms, balancing short-term response efficiency and long-term information completeness.
Through this three-layer design, MemU brings genuine memory into the agent layer, achieving:
-
Full Traceability: Complete traceability across the three layers—from raw data → memory items → aggregated documents. Enables bidirectional tracking of each knowledge piece’s source and evolution, ensuring transparency and interpretability.
-
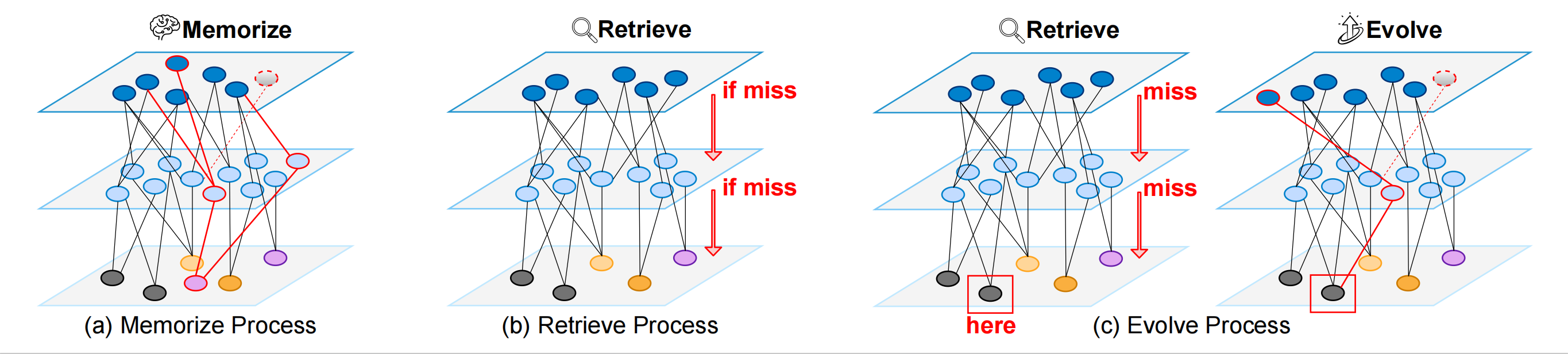
End-to-End Memory Lifecycle Management: The three core processes correspond to the memory lifecycle: Memorization → Retrieval → Self-evolution.
-
Coherent and Scalable Memorization: During memorization, the system maintains memory coherence while automatically managing resources to support sustainable expansion.
-
Efficient and Interpretable Retrieval: Retrieves information efficiently while preserving interpretability, supporting cross-theme and cross-modal semantic queries and reasoning. The system offers two retrieval methods:
- RAG-based Retrieval: Fast embedding-based vector search for efficient large-scale retrieval
- LLM-based Retrieval: Direct file reading through natural language understanding, allowing deep search by tracking step-by-step from categories → items → original resources without relying on embedding search
-
Self-Evolving Memory: A feedback-driven mechanism continuously adapts the memory structure according to real usage patterns.
🚀Get Started
Installation
pip install memu-py
Basic Usage
from memu.app import MemoryService
import logging
async def test_memory_service():
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(name)s: %(message)s",
)
logger = logging.getLogger("memu")
logger.setLevel(logging.DEBUG)
# Initialize MemoryService with your OpenAI API key
service = MemoryService(llm_config={"api_key": "your-openai-api-key"})
# Memorize a conversation
memory = await service.memorize(
resource_url="tests/example/example_conversation.json",
modality="conversation"
)
# Test 1: RAG-based Retrieval with query context
# Multiple queries enable automatic query rewriting with context
print("\n[Test 1] RAG-based Retrieval with query context")
queries_with_context = [
{"role": "user", "content": {"text": "Tell me about the user's preferences"}},
{"role": "assistant", "content": {"text": "I can help you with that. Let me search the memory."}},
{"role": "user", "content": {"text": "What are their habits?"}},
]
retrieved_rag = await service.retrieve(queries=queries_with_context)
print(f"Needs retrieval: {retrieved_rag.get('needs_retrieval')}")
print(f"Original query: {retrieved_rag.get('original_query')}")
print(f"Rewritten query: {retrieved_rag.get('rewritten_query')}")
print(f"Next step query: {retrieved_rag.get('next_step_query')}")
print(f"Results: {len(retrieved_rag.get('categories', []))} categories, "
f"{len(retrieved_rag.get('items', []))} items")
# Test 2: Single query without context (no rewriting)
print("\n[Test 2] Single query without context")
queries_no_context = [
{"role": "user", "content": {"text": "What are their habits?"}}
]
retrieved_single = await service.retrieve(queries=queries_no_context)
print(f"Needs retrieval: {retrieved_single.get('needs_retrieval')}")
print(f"Original query: {retrieved_single.get('original_query')}")
print(f"Rewritten query: {retrieved_single.get('rewritten_query')}")
print(f"Next step query: {retrieved_single.get('next_step_query')}")
print(f"Results: {len(retrieved_single.get('categories', []))} categories, "
f"{len(retrieved_single.get('items', []))} items")
if __name__ == "__main__":
import asyncio
asyncio.run(test_memory_service())
Understanding Retrieval Methods
MemU provides two distinct retrieval approaches, each optimized for different scenarios:
Query Structure
Queries are passed as a list of message objects in the format:
[
{"role": "user", "content": {"text": "Tell me about the user's preferences"}},
{"role": "assistant", "content": {"text": "I can help you with that."}},
{"role": "user", "content": {"text": "What are their habits?"}}
]
- Roles can be
user,assistant, or other custom roles - The last query in the list is the current query
- Previous queries (with their roles) provide context for automatic query rewriting
- If only one query is provided, no rewriting occurs
- The system returns a
next_step_queryto suggest the next retrieval step
1. RAG-based Retrieval (method="rag")
Fast embedding-based vector search using cosine similarity. Ideal for:
- Large-scale datasets
- Real-time performance requirements
- Cost-effective retrieval at scale
The system progressively searches through three layers:
- Category Layer: Searches category summaries
- Item Layer: Searches memory items within relevant categories
- Resource Layer: Tracks back to original multimodal resources (conversations, documents, videos, etc.)
At each tier, the system judges if sufficient information has been found and dynamically rewrites the query with context for deeper search.
2. LLM-based Retrieval (method="llm")
Direct file reading through natural language understanding. Ideal for:
- Complex semantic queries requiring nuanced understanding
- Deep contextual reasoning
- Scenarios where interpretability is critical
This method uses the LLM to:
- Read and comprehend natural language memory files directly
- Rank results based on semantic relevance
- Provide reasoning for each ranked result
- Track step-by-step from categories → items → original resources without relying on embeddings
Both methods support:
- Full traceability: Each retrieved item includes its
resource_id, allowing you to trace back to the original source - Context-aware rewriting: Automatically resolves pronouns and references using previous queries as context
- Pre-retrieval decision: Intelligently determines if memory retrieval is needed for the query
- Progressive search: Stops early if sufficient information is found at higher layers
- Next step suggestion: Returns
next_step_queryfor iterative multi-turn retrieval
📄 License
By contributing to MemU, you agree that your contributions will be licensed under the Apache License 2.0.
🌍 Community
For more information please contact info@nevamind.ai
-
GitHub Issues: Report bugs, request features, and track development. Submit an issue
-
Discord: Get real-time support, chat with the community, and stay updated. Join us
-
X (Twitter): Follow for updates, AI insights, and key announcements. Follow us
🤝 Ecosystem
We're proud to work with amazing organizations:
Development Tools
Interested in partnering with MemU? Contact us at contact@nevamind.ai
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file memu_py-0.6.0.tar.gz.
File metadata
- Download URL: memu_py-0.6.0.tar.gz
- Upload date:
- Size: 2.9 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8ccfa005cce9603128f90a282d38494b3db1a1eb1a1a2f8b29bc7bf3ef5c5109
|
|
| MD5 |
aa7632b5115ce7c0b5f503c1ff928a7b
|
|
| BLAKE2b-256 |
d2793b6ee40521ec82c897c21e258d4d38dddb106d7012990ccb13d4992f3f3b
|
Provenance
The following attestation bundles were made for memu_py-0.6.0.tar.gz:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.6.0.tar.gz -
Subject digest:
8ccfa005cce9603128f90a282d38494b3db1a1eb1a1a2f8b29bc7bf3ef5c5109 - Sigstore transparency entry: 710271125
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a968d48177b0409db5f72bce9a384d502d68cc61 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a968d48177b0409db5f72bce9a384d502d68cc61 -
Trigger Event:
push
-
Statement type:
File details
Details for the file memu_py-0.6.0-cp313-abi3-win_amd64.whl.
File metadata
- Download URL: memu_py-0.6.0-cp313-abi3-win_amd64.whl
- Upload date:
- Size: 140.5 kB
- Tags: CPython 3.13+, Windows x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8975d147333cba8673858cf9ac449af845661f94ba384a597c747ae8ee9bcca3
|
|
| MD5 |
10dfc4546bfa8202d8e62bdd17665a5e
|
|
| BLAKE2b-256 |
50fc9c3c35431008ff0e792c48f92fc586f57f9bf77bde26c3ea6db653e6df75
|
Provenance
The following attestation bundles were made for memu_py-0.6.0-cp313-abi3-win_amd64.whl:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.6.0-cp313-abi3-win_amd64.whl -
Subject digest:
8975d147333cba8673858cf9ac449af845661f94ba384a597c747ae8ee9bcca3 - Sigstore transparency entry: 710271237
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a968d48177b0409db5f72bce9a384d502d68cc61 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a968d48177b0409db5f72bce9a384d502d68cc61 -
Trigger Event:
push
-
Statement type:
File details
Details for the file memu_py-0.6.0-cp313-abi3-manylinux_2_35_x86_64.whl.
File metadata
- Download URL: memu_py-0.6.0-cp313-abi3-manylinux_2_35_x86_64.whl
- Upload date:
- Size: 279.5 kB
- Tags: CPython 3.13+, manylinux: glibc 2.35+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5e3e866dfb4d35eefdc72509d18ed28cf378d5dc97a1ccc6f0edc42130195f5f
|
|
| MD5 |
15192535f5bd6650e5795ab7b7b22d43
|
|
| BLAKE2b-256 |
427e61c7c1a509b834c1c9da0f4f539f48c589f7bf497dfc0f901c62aca84c6d
|
Provenance
The following attestation bundles were made for memu_py-0.6.0-cp313-abi3-manylinux_2_35_x86_64.whl:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.6.0-cp313-abi3-manylinux_2_35_x86_64.whl -
Subject digest:
5e3e866dfb4d35eefdc72509d18ed28cf378d5dc97a1ccc6f0edc42130195f5f - Sigstore transparency entry: 710271348
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a968d48177b0409db5f72bce9a384d502d68cc61 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a968d48177b0409db5f72bce9a384d502d68cc61 -
Trigger Event:
push
-
Statement type:
File details
Details for the file memu_py-0.6.0-cp313-abi3-macosx_11_0_arm64.whl.
File metadata
- Download URL: memu_py-0.6.0-cp313-abi3-macosx_11_0_arm64.whl
- Upload date:
- Size: 247.1 kB
- Tags: CPython 3.13+, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c9ba2c500a7b2c8ae8eef1dbec49e1fbe7b93e3b764ca821a987869349ddd5e0
|
|
| MD5 |
238149e3a57c05daf99c302ba2b63210
|
|
| BLAKE2b-256 |
24636b97f047631df2e082b296c84eba05cba52ecb3803057b35c7cd3cbede9a
|
Provenance
The following attestation bundles were made for memu_py-0.6.0-cp313-abi3-macosx_11_0_arm64.whl:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.6.0-cp313-abi3-macosx_11_0_arm64.whl -
Subject digest:
c9ba2c500a7b2c8ae8eef1dbec49e1fbe7b93e3b764ca821a987869349ddd5e0 - Sigstore transparency entry: 710271420
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a968d48177b0409db5f72bce9a384d502d68cc61 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a968d48177b0409db5f72bce9a384d502d68cc61 -
Trigger Event:
push
-
Statement type:
File details
Details for the file memu_py-0.6.0-cp313-abi3-macosx_10_12_x86_64.whl.
File metadata
- Download URL: memu_py-0.6.0-cp313-abi3-macosx_10_12_x86_64.whl
- Upload date:
- Size: 250.1 kB
- Tags: CPython 3.13+, macOS 10.12+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cc0e77b6985a9d2f4aacdde84cfa3937bfcb4382ce471f5a2ba73a17299e1e1f
|
|
| MD5 |
ede116caba04f0920a5b111c710446bf
|
|
| BLAKE2b-256 |
487fb5ac01c7c6f156c88cf662421bcc942dcc8fb2d20b72c47fd98ab0230822
|
Provenance
The following attestation bundles were made for memu_py-0.6.0-cp313-abi3-macosx_10_12_x86_64.whl:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.6.0-cp313-abi3-macosx_10_12_x86_64.whl -
Subject digest:
cc0e77b6985a9d2f4aacdde84cfa3937bfcb4382ce471f5a2ba73a17299e1e1f - Sigstore transparency entry: 710271484
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a968d48177b0409db5f72bce9a384d502d68cc61 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a968d48177b0409db5f72bce9a384d502d68cc61 -
Trigger Event:
push
-
Statement type:







