AI Memory and Conversation Management Framework - Simple as mem0, Powerful as MemU
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers



Project description

MemU
A Future-Oriented Agentic Memory System





MemU is an agentic memory framework for LLM and AI agent backends. It receives multimodal inputs (conversations, documents, images), extracts them into structured memory, and organizes them into a hierarchical file system that supports both embedding-based (RAG) and non-embedding (LLM) retrieval.
✨ Core Features
| Feature | Description |
|---|---|
| 🗂️ Hierarchical File System | Three-layer architecture: Resource → Item → Category with full traceability |
| 🔍 Dual Retrieval Methods | RAG (embedding-based) for speed, LLM (non-embedding) for deep semantic understanding |
| 🎨 Multimodal Support | Process conversations, documents, images, audio, and video |
| 🔄 Self-Evolving Memory | Memory structure adapts and improves based on usage patterns |
🗂️ Hierarchical File System
MemU organizes memory using a three-layer architecture inspired by hierarchical storage systems:

| Layer | Description | Examples |
|---|---|---|
| Resource | Raw multimodal data warehouse | JSON conversations, text documents, images, videos |
| Item | Discrete extracted memory units | Individual preferences, skills, opinions, habits |
| Category | Aggregated textual memory with summaries | preferences.md, work_life.md, relationships.md |
Key Benefits:
- Full Traceability: Track from raw data → items → categories and back
- Progressive Summarization: Each layer provides increasingly abstracted views
- Flexible Organization: Categories evolve based on content patterns
🎨 Multimodal Support
MemU processes diverse content types into unified memory:
| Modality | Input | Processing |
|---|---|---|
conversation |
JSON chat logs | Extract preferences, opinions, habits, relationships |
document |
Text files (.txt, .md) | Extract knowledge, skills, facts |
image |
PNG, JPG, etc. | Vision model extracts visual concepts and descriptions |
video |
Video files | Frame extraction + vision analysis |
audio |
Audio files | Transcription + text processing |
All modalities are unified into the same three-layer hierarchy, enabling cross-modal retrieval.
🚀 Quick Start
Option 1: Cloud Version
Try MemU instantly without any setup:
👉 memu.so - Hosted cloud service with full API access
For enterprise deployment and custom solutions, contact info@nevamind.ai
Option 2: Self-Hosted
Installation
pip install -e .
Basic Example
Requirements: Python 3.13+ and an OpenAI API key
Test with In-Memory Storage (no database required):
export OPENAI_API_KEY=your_api_key
cd tests
python test_inmemory.py
Test with PostgreSQL Storage (requires pgvector):
# Start PostgreSQL with pgvector
docker run -d \
--name memu-postgres \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=postgres \
-e POSTGRES_DB=memu \
-p 5432:5432 \
pgvector/pgvector:pg16
# Run the test
export OPENAI_API_KEY=your_api_key
cd tests
python test_postgres.py
Both examples demonstrate the complete workflow:
- Memorize: Process a conversation file and extract structured memory
- Retrieve (RAG): Fast embedding-based search
- Retrieve (LLM): Deep semantic understanding search
See tests/test_inmemory.py and tests/test_postgres.py for the full source code.
📖 Core APIs
memorize() - Extract and Store Memory
Processes input resources and extracts structured memory:

result = await service.memorize(
resource_url="path/to/file.json", # File path or URL
modality="conversation", # conversation | document | image | video | audio
user={"user_id": "123"} # Optional: scope to a user
)
# Returns:
{
"resource": {...}, # Stored resource metadata
"items": [...], # Extracted memory items
"categories": [...] # Updated category summaries
}
retrieve() - Query Memory
Retrieves relevant memory based on queries. MemU supports two retrieval strategies:

RAG-based Retrieval (method="rag")
Fast embedding vector search using cosine similarity:
- ✅ Fast: Pure vector computation
- ✅ Scalable: Efficient for large memory stores
- ✅ Returns scores: Each result includes similarity score
LLM-based Retrieval (method="llm")
Deep semantic understanding through direct LLM reasoning:
- ✅ Deep understanding: LLM comprehends context and nuance
- ✅ Query rewriting: Automatically refines query at each tier
- ✅ Adaptive: Stops early when sufficient information is found
Comparison
| Aspect | RAG | LLM |
|---|---|---|
| Speed | ⚡ Fast | 🐢 Slower |
| Cost | 💰 Low | 💰💰 Higher |
| Semantic depth | Medium | Deep |
| Tier 2 scope | All items | Only items in relevant categories |
| Output | With similarity scores | Ranked by LLM reasoning |
Both methods support:
- Context-aware rewriting: Resolves pronouns using conversation history
- Progressive search: Categories → Items → Resources
- Sufficiency checking: Stops when enough information is retrieved
Usage
result = await service.retrieve(
queries=[
{"role": "user", "content": {"text": "What are their preferences?"}},
{"role": "user", "content": {"text": "Tell me about work habits"}}
],
where={"user_id": "123"} # Optional: scope filter
)
# Returns:
{
"categories": [...], # Relevant categories (with scores for RAG)
"items": [...], # Relevant memory items
"resources": [...], # Related raw resources
"next_step_query": "..." # Rewritten query for follow-up (if applicable)
}
Scope Filtering: Use where to filter by user model fields:
where={"user_id": "123"}- exact matchwhere={"agent_id__in": ["1", "2"]}- match any in list- Omit
whereto retrieve across all scopes
📚 For complete API documentation, see SERVICE_API.md - includes all methods, CRUD operations, pipeline configuration, and configuration types.
💡 Use Cases
Example 1: Conversation Memory
Extract and organize memory from multi-turn conversations:
export OPENAI_API_KEY=your_api_key
python examples/example_1_conversation_memory.py
What it does:
- Processes multiple conversation JSON files
- Extracts memory items (preferences, habits, opinions, relationships)
- Generates category markdown files (
preferences.md,work_life.md, etc.)
Best for: Personal AI assistants, customer support bots, social chatbots
Example 2: Skill Extraction from Logs
Extract skills and lessons learned from agent execution logs:
export OPENAI_API_KEY=your_api_key
python examples/example_2_skill_extraction.py
What it does:
- Processes agent logs sequentially
- Extracts actions, outcomes, and lessons learned
- Demonstrates incremental learning - memory evolves with each file
- Generates evolving skill guides (
log_1.md→log_2.md→skill.md)
Best for: DevOps teams, agent self-improvement, knowledge management
Example 3: Multimodal Memory
Process diverse content types into unified memory:
export OPENAI_API_KEY=your_api_key
python examples/example_3_multimodal_memory.py
What it does:
- Processes documents and images together
- Extracts memory from different content types
- Unifies into cross-modal categories (
technical_documentation,visual_diagrams, etc.)
Best for: Documentation systems, learning platforms, research tools
📊 Performance
MemU achieves 92.09% average accuracy on the Locomo benchmark across all reasoning tasks.
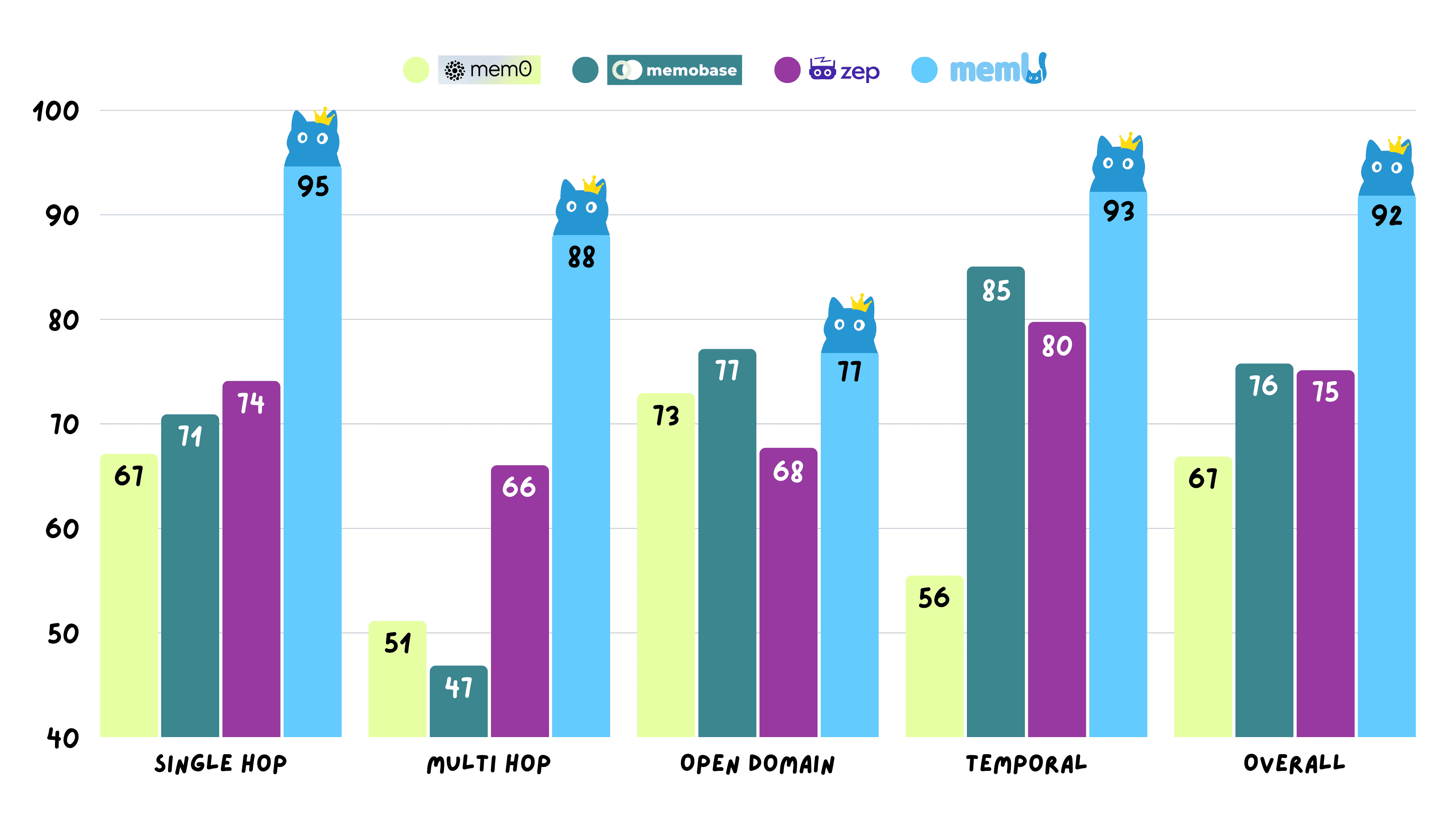
View detailed experimental data: memU-experiment
🧩 Ecosystem
| Repository | Description | Use Case |
|---|---|---|
| memU | Core algorithm engine | Embed AI memory into your product |
| memU-server | Backend service with CRUD, user system, RBAC | Self-host a memory backend |
| memU-ui | Visual dashboard | Ready-to-use memory console |
Quick Links:
🤝 Partners
📄 License
🌍 Community
- GitHub Issues: Report bugs & request features
- Discord: Join the community
- X (Twitter): Follow @memU_ai
- Contact: info@nevamind.ai
⭐ Star us on GitHub to get notified about new releases!
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file memu_py-0.9.0.tar.gz.
File metadata
- Download URL: memu_py-0.9.0.tar.gz
- Upload date:
- Size: 9.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
632e53f388eb4590d435662e5ba4494ed6d0ec750e17d3bc281b7b5cf2cf843f
|
|
| MD5 |
b275c254327ba83e2ba87a122a5b3cc4
|
|
| BLAKE2b-256 |
e3ec2a3ab820cdf3d145dc09ee92a093e6f08edae9f1e7f57ab0b3783fdd150c
|
Provenance
The following attestation bundles were made for memu_py-0.9.0.tar.gz:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.9.0.tar.gz -
Subject digest:
632e53f388eb4590d435662e5ba4494ed6d0ec750e17d3bc281b7b5cf2cf843f - Sigstore transparency entry: 790698372
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a15429a7903c900212c906400d3b8044083d12a4 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a15429a7903c900212c906400d3b8044083d12a4 -
Trigger Event:
push
-
Statement type:
File details
Details for the file memu_py-0.9.0-cp313-abi3-win_amd64.whl.
File metadata
- Download URL: memu_py-0.9.0-cp313-abi3-win_amd64.whl
- Upload date:
- Size: 218.0 kB
- Tags: CPython 3.13+, Windows x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
507d04cb7abbaa0658fa8d546e4c4f76fe8638203d99c475023ffe648820cf94
|
|
| MD5 |
7edfb966c6baa0cffb54abb662d78038
|
|
| BLAKE2b-256 |
835682d33b8ea4b788da95565f2cf462cec0303e633138f6e816162c4ad87c47
|
Provenance
The following attestation bundles were made for memu_py-0.9.0-cp313-abi3-win_amd64.whl:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.9.0-cp313-abi3-win_amd64.whl -
Subject digest:
507d04cb7abbaa0658fa8d546e4c4f76fe8638203d99c475023ffe648820cf94 - Sigstore transparency entry: 790698373
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a15429a7903c900212c906400d3b8044083d12a4 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a15429a7903c900212c906400d3b8044083d12a4 -
Trigger Event:
push
-
Statement type:
File details
Details for the file memu_py-0.9.0-cp313-abi3-manylinux_2_39_x86_64.whl.
File metadata
- Download URL: memu_py-0.9.0-cp313-abi3-manylinux_2_39_x86_64.whl
- Upload date:
- Size: 354.8 kB
- Tags: CPython 3.13+, manylinux: glibc 2.39+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6fcdd1115887ec31d55e17db16efbce2d4af86a9126821353ad66a105dd230bc
|
|
| MD5 |
f4ddc658380d1dac354f6c59eace096b
|
|
| BLAKE2b-256 |
5951cdec275c40d146264801dc3a44b3d2ba7408283601a0bf2a3cc9f6099af2
|
Provenance
The following attestation bundles were made for memu_py-0.9.0-cp313-abi3-manylinux_2_39_x86_64.whl:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.9.0-cp313-abi3-manylinux_2_39_x86_64.whl -
Subject digest:
6fcdd1115887ec31d55e17db16efbce2d4af86a9126821353ad66a105dd230bc - Sigstore transparency entry: 790698375
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a15429a7903c900212c906400d3b8044083d12a4 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a15429a7903c900212c906400d3b8044083d12a4 -
Trigger Event:
push
-
Statement type:
File details
Details for the file memu_py-0.9.0-cp313-abi3-macosx_11_0_arm64.whl.
File metadata
- Download URL: memu_py-0.9.0-cp313-abi3-macosx_11_0_arm64.whl
- Upload date:
- Size: 323.7 kB
- Tags: CPython 3.13+, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0de0e6e2a1a1b4be2b2c56b35fc36db78cf609db585a973c85338c00a825fb87
|
|
| MD5 |
e99272607ea449dd04b2fbda38016a45
|
|
| BLAKE2b-256 |
5cb7eebf0fe601285a589928e36ed903bd354805f9952772189dc2770da46da7
|
Provenance
The following attestation bundles were made for memu_py-0.9.0-cp313-abi3-macosx_11_0_arm64.whl:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.9.0-cp313-abi3-macosx_11_0_arm64.whl -
Subject digest:
0de0e6e2a1a1b4be2b2c56b35fc36db78cf609db585a973c85338c00a825fb87 - Sigstore transparency entry: 790698387
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a15429a7903c900212c906400d3b8044083d12a4 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a15429a7903c900212c906400d3b8044083d12a4 -
Trigger Event:
push
-
Statement type:
File details
Details for the file memu_py-0.9.0-cp313-abi3-macosx_10_12_x86_64.whl.
File metadata
- Download URL: memu_py-0.9.0-cp313-abi3-macosx_10_12_x86_64.whl
- Upload date:
- Size: 326.2 kB
- Tags: CPython 3.13+, macOS 10.12+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
20915985eeabe0a1f313e51841ec2b4ae931252ae00d7aa3577df8495ede311c
|
|
| MD5 |
7b20dfe7d04bf98de9c435c997705b7b
|
|
| BLAKE2b-256 |
d86f064768b8bce43f3b937489b9d73003d4e8f57ef80e1586178a7b38394fc5
|
Provenance
The following attestation bundles were made for memu_py-0.9.0-cp313-abi3-macosx_10_12_x86_64.whl:
Publisher:
release-please.yml on NevaMind-AI/memU
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
memu_py-0.9.0-cp313-abi3-macosx_10_12_x86_64.whl -
Subject digest:
20915985eeabe0a1f313e51841ec2b4ae931252ae00d7aa3577df8495ede311c - Sigstore transparency entry: 790698374
- Sigstore integration time:
-
Permalink:
NevaMind-AI/memU@a15429a7903c900212c906400d3b8044083d12a4 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/NevaMind-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release-please.yml@a15429a7903c900212c906400d3b8044083d12a4 -
Trigger Event:
push
-
Statement type:







