Modern difference-in-differences estimators.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

A scalable, GPU-accelerated difference-in-differences library for Python.
Docs · API Reference · Tutorials · Changelog














ModernDiD is a scalable, GPU-accelerated difference-in-differences library for Python. It consolidates modern DiD estimators from leading econometric research and various R and Stata packages into a single framework with a consistent API. Runs on a single machine, NVIDIA GPUs, and distributed Spark and Dask clusters.
Features
- Staggered DiD, Doubly Robust DiD, Continuous DiD, Triple DiD, Intertemporal DiD, and Honest DiD.
- Works with any Arrow-compatible DataFrame (polars, pandas, pyarrow, duckdb, and more) via narwhals.
- Distributed computing with Spark and Dask backends.
- Polars for internal data wrangling, NumPy vectorization, Numba JIT computations, and threaded parallel compute.
- Optional CuPy GPU acceleration with multi-GPU support in distributed mode.
- plotnine-based plots that return
ggplotobjects you can customize. - Result objects plug directly into maketables for LaTeX, HTML, Word, and Typst tables.
- Analytical SEs, weighted and multiplier bootstrap, simultaneous confidence bands.
For detailed documentation, see ModernDiD Documentation.
Installation
uv pip install moderndid # Core estimators (did, drdid, didinter, didtriple)
Some estimators and features require additional dependencies that are not installed by default. Extras are additive and build on the base install, so you always get the core estimators (att_gt(), drdid(), did_multiplegt(), ddd()) plus whatever extras you specify:
didcont- Continuous treatment DiD (cont_did())didhonest- Sensitivity analysis (honest_did())plots- Batteries-included plotsnumba- Faster bootstrap inferencespark- Distributed estimation via PySparkdask- Distributed estimation via Daskgpu- GPU-accelerated estimation (requires CUDA)
uv pip install "moderndid[all]" # All extras except gpu and spark
uv pip install "moderndid[didcont,plots]" # Combine specific extras
uv pip install "moderndid[gpu,spark]" # GPU + distributed
To install the latest development version directly from GitHub:
uv pip install "moderndid[all] @ git+https://github.com/jordandeklerk/moderndid.git"
See the Installation guide for troubleshooting and GPU-specific setup.
Quick Start
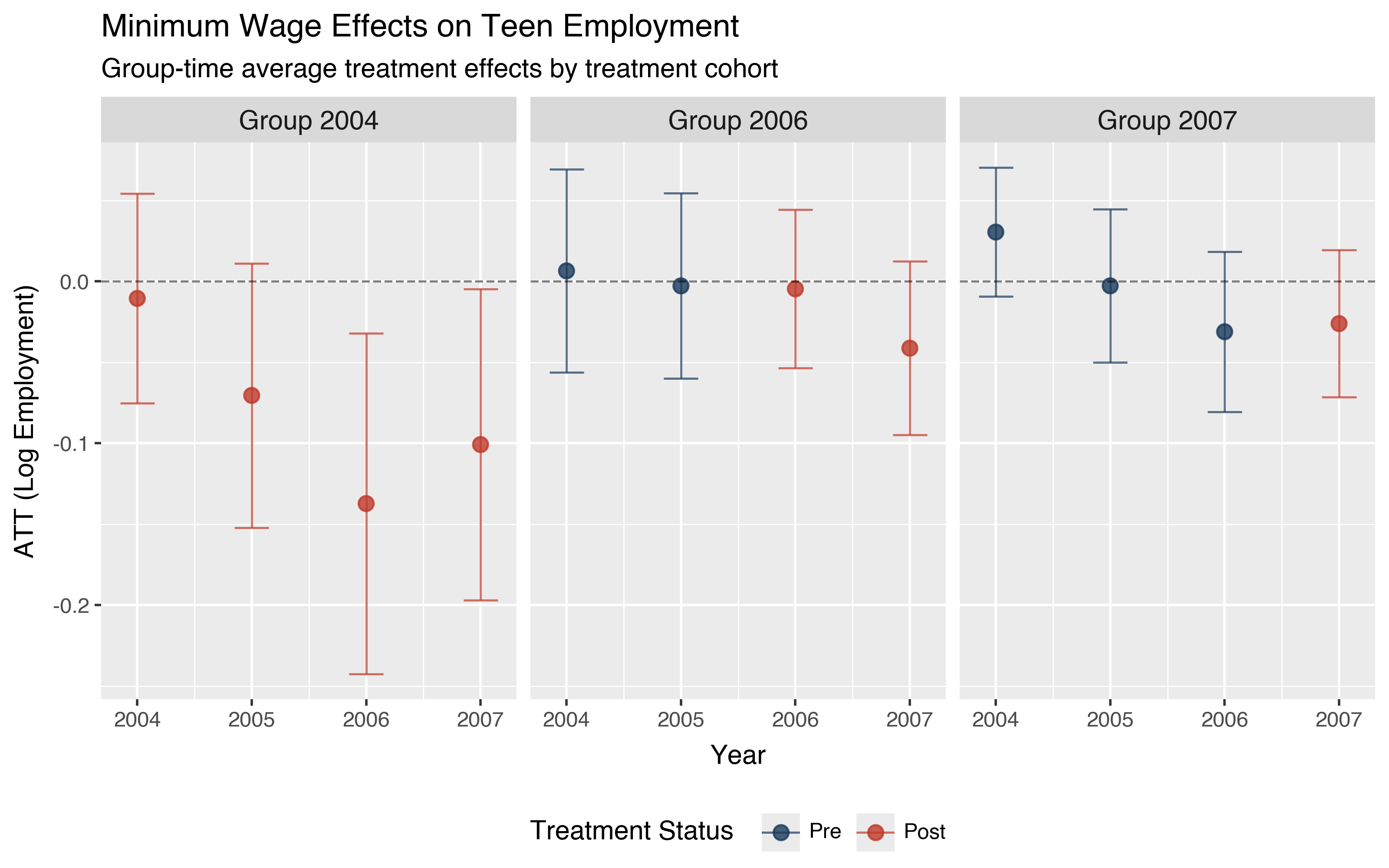
Using county-level panel data from Callaway and Sant'Anna (2021) to estimate the effect of minimum wage increases on teen employment:
import moderndid as did
from plotnine import element_text, labs, theme, theme_gray
data = did.load_mpdta()
# Group-time ATTs
result = did.att_gt(
data=data,
yname="lemp",
tname="year",
idname="countyreal",
gname="first.treat",
xformla="~1",
est_method="dr",
boot=True,
)
# Use grammar of graphics to customize plots
p = did.plot_gt(result, ncol=3)
p = (p
+ labs(
x="Year",
y="ATT (Log Employment)",
title="Minimum Wage Effects on Teen Employment",
subtitle="Group-time average treatment effects by treatment cohort",
)
+ theme_gray()
+ theme(
legend_position="bottom",
strip_text=element_text(size=11, weight="bold"),
)
)
p.save("att.png", dpi=200, width=8, height=5)
The User Guide has tutorials for every estimator. See also the Plotting Guide.
Consistent API
All estimators use the same naming conventions for core arguments:
result = did.att_gt(data, yname="y", tname="t", idname="id", gname="g", ...)
result = did.ddd(data, yname="y", tname="t", idname="id", gname="g", pname="p", ...)
result = did.cont_did(data, yname="y", tname="t", idname="id", gname="g", dname="dose", ...)
result = did.drdid(data, yname="y", tname="t", idname="id", treatname="treat", ...)
result = did.did_multiplegt(data, yname="y", tname="t", idname="id", dname="treat", ...)
Publication Tables
Result objects plug into maketables. Pass them to ETable and estimates, SEs, CIs, and metadata are extracted automatically:
import maketables as mt
# Aggregate results from earlier into an event study
event_study = did.aggte(result, type="dynamic")
tab = mt.ETable(
[event_study],
coef_fmt="b:.3f* \\n (se:.3f)",
keep=[r"^Event "],
model_stats=["N", "se_type"],
caption="Dynamic Treatment Effects",
)
tab.make("tex") # or "html", "docx", "typst"
See the Publication Tables guide for MTable layouts and more examples.
Scaling Up
Pass a Spark or Dask DataFrame and estimation distributes automatically. See the Distributed guide.
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]").getOrCreate()
result = did.att_gt(data=spark.read.parquet("panel.parquet"),
yname="y",
tname="t",
idname="id",
gname="g")
For GPUs, pass backend="cupy". See the GPU guide and benchmarks.
result = did.att_gt(data,
yname="lemp",
tname="year",
idname="countyreal",
gname="first.treat",
backend="cupy")
Example Datasets
Datasets from published studies and synthetic data generators for simulations:
did.load_mpdta() # County teen employment
did.load_nsw() # NSW job training program
did.load_ehec() # Medicaid expansion
did.load_engel() # Household expenditure
did.load_favara_imbs() # Bank lending
did.load_cai2016() # Crop insurance
did.gen_did_scalable() # Staggered DiD panel
did.gen_cont_did_data() # Continuous treatment DiD
did.gen_ddd_2periods() # Two-period triple DiD
did.gen_ddd_mult_periods() # Staggered triple DiD
did.gen_ddd_scalable() # Large-scale triple DiD
Planned Development
moderndid.didml— Machine learning approaches to DiD (Hatamyar et al., 2023)moderndid.drdidweak— Robust to weak overlap (Ma et al., 2023)moderndid.didcomp— Compositional changes in repeated cross-sections (Sant'Anna & Xu, 2025)moderndid.didimpute— Imputation-based estimators (Borusyak, Jaravel, & Spiess, 2024)moderndid.didbacon— Goodman-Bacon decomposition (Goodman-Bacon, 2019)moderndid.didlocal— Local projections DiD (Dube et al., 2025)moderndid.did2s— Two-stage DiD (Gardner, 2021)moderndid.etwfe— Extended two-way fixed effects (Wooldridge, 2021; Wooldridge, 2023)moderndid.diddynamic— Dynamic covariate balancing for time-varying treatments (Viviano & Bradic, 2026)moderndid.functional— Specification tests (Roth & Sant'Anna, 2023)
Acknowledgements
ModernDiD would not be possible without the researchers who developed the underlying econometric methods and implemented them in various R and Stata packages. See our Acknowledgements page for a full list of the software, packages, and papers that have influenced this project.
Citation
If you use ModernDiD in your research, please cite it as:
@software{moderndid,
author = {{The ModernDiD Authors}},
title = {{ModernDiD: Scalable, GPU-Accelerated Difference-in-Differences for Python}},
year = {2025},
url = {https://github.com/jordandeklerk/moderndid}
}
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file moderndid-0.2.0.tar.gz.
File metadata
- Download URL: moderndid-0.2.0.tar.gz
- Upload date:
- Size: 1.4 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7dc4b89319aa3da619c98b19c5f592cec1ca2939748c481b240b5f43946e3a58
|
|
| MD5 |
30450d53d45e0f7f46cdca10504d19d8
|
|
| BLAKE2b-256 |
51d880415c3418dd00258444cf37dddf0fd4e27c077159dd077adef6a8562abc
|
Provenance
The following attestation bundles were made for moderndid-0.2.0.tar.gz:
Publisher:
publish.yml on jordandeklerk/moderndid
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
moderndid-0.2.0.tar.gz -
Subject digest:
7dc4b89319aa3da619c98b19c5f592cec1ca2939748c481b240b5f43946e3a58 - Sigstore transparency entry: 1109276615
- Sigstore integration time:
-
Permalink:
jordandeklerk/moderndid@82cb7fa7e6a4fc18added04eace1b934e80ff61c -
Branch / Tag:
refs/tags/v0.2.0 - Owner: https://github.com/jordandeklerk
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@82cb7fa7e6a4fc18added04eace1b934e80ff61c -
Trigger Event:
push
-
Statement type:
File details
Details for the file moderndid-0.2.0-py3-none-any.whl.
File metadata
- Download URL: moderndid-0.2.0-py3-none-any.whl
- Upload date:
- Size: 1.6 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8a734e115194af3f6121edb3c4807f169b2645ecb7538ca943185750630408b3
|
|
| MD5 |
d99fa598ae787e074d6cf94f74e7d7bc
|
|
| BLAKE2b-256 |
6427207ac83406535ca6afed0ed8c628a91da636cf1aa1d7fce604f87135e364
|
Provenance
The following attestation bundles were made for moderndid-0.2.0-py3-none-any.whl:
Publisher:
publish.yml on jordandeklerk/moderndid
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
moderndid-0.2.0-py3-none-any.whl -
Subject digest:
8a734e115194af3f6121edb3c4807f169b2645ecb7538ca943185750630408b3 - Sigstore transparency entry: 1109276618
- Sigstore integration time:
-
Permalink:
jordandeklerk/moderndid@82cb7fa7e6a4fc18added04eace1b934e80ff61c -
Branch / Tag:
refs/tags/v0.2.0 - Owner: https://github.com/jordandeklerk
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@82cb7fa7e6a4fc18added04eace1b934e80ff61c -
Trigger Event:
push
-
Statement type:







