Modern difference-in-differences estimators.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description











ModernDiD is a scalable, GPU-accelerated difference-in-differences library for Python. It consolidates modern DiD estimators from leading econometric research and various R and Stata packages into a single framework with a consistent API. Runs on a single machine, NVIDIA GPUs, and distributed Dask and Spark clusters.
[!WARNING] This package is currently in active development with core estimators and some sensitivity analysis implemented. The API is subject to change.
Features
- DiD Estimators - Staggered DiD, Doubly Robust DiD, Continuous DiD, Triple DiD, Intertemporal DiD, Honest DiD.
- Dataframe agnostic - Pass any Arrow-compatible DataFrame such as polars, pandas, pyarrow, duckdb, and more powered by narwhals.
- Distributed computing - Scale DiD estimators to billions of observations across multi-node Dask and Spark clusters with automatic dispatch. Simply pass a Dask or Spark DataFrame to supported estimators and the distributed backend activates transparently.
- Fast computation - Polars for internal data wrangling, NumPy vectorization, Numba JIT compilation, and threaded parallel compute.
- GPU acceleration - Optional CuPy-accelerated regression and propensity score estimation across all doubly robust and IPW estimators on NVIDIA GPUs, with multi-GPU scaling in distributed environments.
- Native plots - Built-in visualizations powered by plotnine, returning standard
ggplotobjects you can customize with the full grammar of graphics. - Robust inference - Analytical standard errors, bootstrap (weighted and multiplier), and simultaneous confidence bands.
For detailed documentation, including user guides and API reference, see moderndid.readthedocs.io.
Installation
The base installation includes core DiD estimators that share the same dependencies (did, drdid, didinter, didtriple):
uv pip install moderndid
For full functionality including all estimators, plotting, and performance optimizations:
uv pip install moderndid[all]
Optional Extras
Extras are additive. They add functionality to the base install, so you always get the core estimators plus whatever extras you specify.
didcont- Base + continuous treatment DiD (cont_did)didhonest- Base + sensitivity analysis (honest_did)plots- Base + visualization (plot_gt,plot_event_study, ...)numba- Base + faster bootstrap inferencedask- Base + distributed estimation via Daskspark- Base + distributed estimation via PySparkgpu- Base + GPU-accelerated estimation (requires CUDA)all- Everything (exceptgpu, which requires specific infrastructure)
uv pip install moderndid[didcont] # Base estimators + cont_did
uv pip install moderndid[didhonest] # Base estimators + sensitivity analysis
uv pip install moderndid[numba] # Base estimators with faster computations
uv pip install moderndid[dask] # Base estimators with Dask distributed
uv pip install moderndid[spark] # Base estimators with Spark distributed
uv pip install moderndid[gpu] # Base estimators with GPU acceleration
uv pip install moderndid[gpu,dask] # Combine multiple extras
Or install from source:
uv pip install git+https://github.com/jordandeklerk/moderndid.git
Distributed Computing
For datasets that exceed single-machine memory, pass a Dask or Spark dataFrame to att_gt() or ddd() and the distributed backend activates automatically. All computation happens on workers via partition-level sufficient statistics. Only small summary matrices return to the driver. Results are numerically identical to the local estimators.
Dask
import dask.dataframe as dd
from dask.distributed import Client
import moderndid as did
ddf = dd.read_parquet("panel_data.parquet")
client = Client()
result = did.att_gt(
data=ddf,
yname="y",
tname="time",
idname="id",
gname="group",
est_method="dr",
n_partitions=64, # partitions per cell (default: total cluster threads)
max_cohorts=4, # cohorts to process in parallel
backend="cupy", # run worker linear algebra on GPUs (optional)
)
event_study = did.aggte(result, type="dynamic")
Add backend="cupy" to run worker-side linear algebra on GPUs. For multi-GPU machines, use dask-cuda with a LocalCUDACluster to pin one worker per GPU.
Spark
from pyspark.sql import SparkSession
import moderndid as did
spark = SparkSession.builder.master("local[*]").getOrCreate()
sdf = spark.read.parquet("panel_data.parquet")
result = did.att_gt(
data=sdf,
yname="y",
tname="time",
idname="id",
gname="group",
est_method="dr",
n_partitions=64, # partitions per cell (default: Spark parallelism)
max_cohorts=4, # cohorts to process in parallel
backend="cupy", # run partition linear algebra on GPUs (optional)
)
event_study = did.aggte(result, type="dynamic")
See the Distributed Estimation guide for usage and the Distributed Backend Architecture for details on the design.
GPU Acceleration
On machines with NVIDIA GPUs, install the gpu extra and pass backend="cupy" to offload regression and propensity score estimation to the GPU. The backend activates only for that call and reverts automatically. See the GPU troubleshooting section below for guidance on common issues:
import moderndid as did
result = did.att_gt(data,
yname="lemp",
tname="year",
idname="countyreal",
gname="first.treat",
backend="cupy")
You can also set the backend globally with did.set_backend("cupy") and revert with did.set_backend("numpy"). For multi-GPU scaling, combine with a Dask DataFrame as shown above.
See the GPU guide for details and GPU benchmark results for performance comparisons across several NVIDIA GPUs.
Consistent API
All estimators share a unified interface for core parameters, making it easy to switch between methods:
# Staggered DiD
result = did.att_gt(data, yname="y", tname="t", idname="id", gname="g", ...)
# Triple DiD
result = did.ddd(data, yname="y", tname="t", idname="id", gname="g", pname="p", ...)
# Continuous DiD
result = did.cont_did(data, yname="y", tname="t", idname="id", gname="g", dname="dose", ...)
# Doubly robust 2-period DiD
result = did.drdid(data, yname="y", tname="t", idname="id", treatname="treat", ...)
# Intertemporal DiD
result = did.did_multiplegt(data, yname="y", tname="t", idname="id", dname="treat", ...)
Example Datasets
Several classic datasets from the DiD literature are included for experimentation:
did.load_mpdta() # County teen employment
did.load_nsw() # NSW job training program
did.load_ehec() # Medicaid expansion
did.load_engel() # Household expenditure
did.load_favara_imbs() # Bank lending
did.load_cai2016() # Crop insurance
Synthetic data generators are also available for simulations and benchmarking:
did.gen_did_scalable() # Staggered DiD panel
did.simulate_cont_did_data() # Continuous treatment DiD
did.gen_dgp_2periods() # Two-period triple DiD
did.gen_dgp_mult_periods() # Staggered triple DiD
did.gen_dgp_scalable() # Large-scale triple DiD
Quick Start
This example uses county-level teen employment data to estimate the effect of minimum wage increases. States adopted higher minimum wages at different times (2004, 2006, or 2007), making this a staggered adoption design.
The att_gt() function is a core ModernDiD estimator that estimates the average treatment effect for each group $g$ (defined by when units were first treated) at each time period $t$ in multi-period, staggered adoption designs. We use the doubly robust estimator, which combines outcome regression and propensity score weighting to provide consistent estimates if either model is correctly specified.
import moderndid as did
# County teen employment data
data = did.load_mpdta()
# Estimate group-time average treatment effects
attgt_result = did.att_gt(
data=data,
yname="lemp",
tname="year",
idname="countyreal",
gname="first.treat",
est_method="dr",
)
print(attgt_result)
The output shows treatment effects for each group-time pair, along with pointwise confidence bands that account for multiple testing:
==============================================================================
Group-Time Average Treatment Effects
==============================================================================
┌───────┬──────┬──────────┬────────────┬────────────────────────────┐
│ Group │ Time │ ATT(g,t) │ Std. Error │ [95% Pointwise Conf. Band] │
├───────┼──────┼──────────┼────────────┼────────────────────────────┤
│ 2004 │ 2004 │ -0.0105 │ 0.0233 │ [-0.0561, 0.0351] │
│ 2004 │ 2005 │ -0.0704 │ 0.0310 │ [-0.1312, -0.0097] * │
│ 2004 │ 2006 │ -0.1373 │ 0.0364 │ [-0.2087, -0.0658] * │
│ 2004 │ 2007 │ -0.1008 │ 0.0344 │ [-0.1682, -0.0335] * │
│ 2006 │ 2004 │ 0.0065 │ 0.0233 │ [-0.0392, 0.0522] │
│ 2006 │ 2005 │ -0.0028 │ 0.0196 │ [-0.0411, 0.0356] │
│ 2006 │ 2006 │ -0.0046 │ 0.0178 │ [-0.0394, 0.0302] │
│ 2006 │ 2007 │ -0.0412 │ 0.0202 │ [-0.0809, -0.0016] * │
│ 2007 │ 2004 │ 0.0305 │ 0.0150 │ [ 0.0010, 0.0600] * │
│ 2007 │ 2005 │ -0.0027 │ 0.0164 │ [-0.0349, 0.0294] │
│ 2007 │ 2006 │ -0.0311 │ 0.0179 │ [-0.0661, 0.0040] │
│ 2007 │ 2007 │ -0.0261 │ 0.0167 │ [-0.0587, 0.0066] │
└───────┴──────┴──────────┴────────────┴────────────────────────────┘
------------------------------------------------------------------------------
Signif. codes: '*' confidence band does not cover 0
P-value for pre-test of parallel trends assumption: 0.1681
------------------------------------------------------------------------------
Data Info
------------------------------------------------------------------------------
Control Group: Never Treated
Anticipation Periods: 0
------------------------------------------------------------------------------
Estimation Details
------------------------------------------------------------------------------
Estimation Method: Doubly Robust
------------------------------------------------------------------------------
Inference
------------------------------------------------------------------------------
Significance level: 0.05
Analytical standard errors
==============================================================================
Reference: Callaway and Sant'Anna (2021)
Rows where the confidence band excludes zero are marked with *. The pre-test p-value tests whether pre-treatment effects are jointly zero, providing a diagnostic for the parallel trends assumption.
We can plot these results using the plot_gt() functionality:
did.plot_gt(attgt_result)
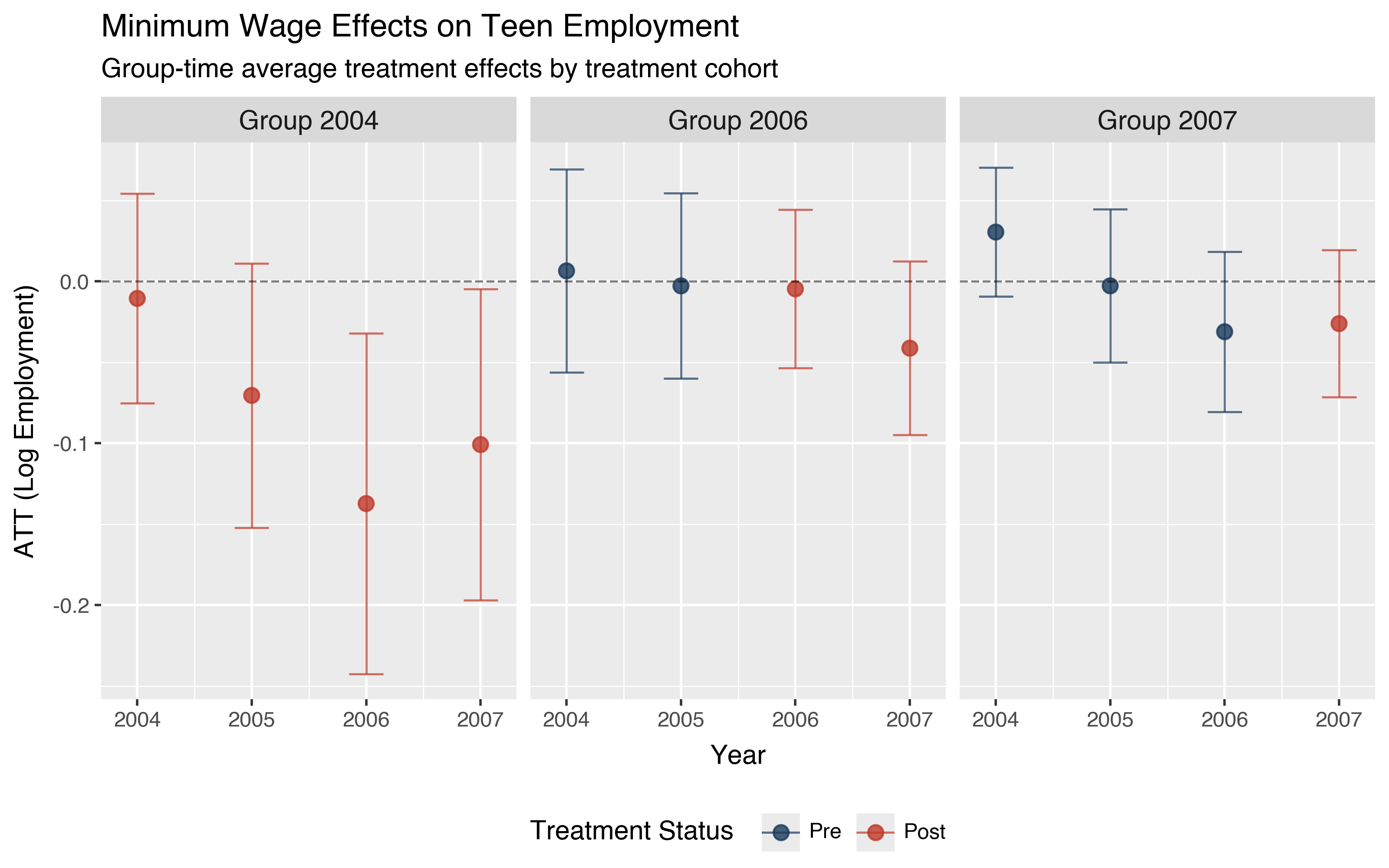
While group-time effects are useful, they can be difficult to summarize when there are many groups and time periods. The aggte function aggregates these into more interpretable summaries. Setting type="dynamic" produces an event study that shows how effects evolve relative to treatment timing:
event_study = did.aggte(attgt_result, type="dynamic")
print(event_study)
==============================================================================
Aggregate Treatment Effects (Event Study)
==============================================================================
Overall summary of ATT's based on event-study/dynamic aggregation:
┌─────────┬────────────┬────────────────────────┐
│ ATT │ Std. Error │ [95% Conf. Interval] │
├─────────┼────────────┼────────────────────────┤
│ -0.0772 │ 0.0200 │ [ -0.1164, -0.0381] * │
└─────────┴────────────┴────────────────────────┘
Dynamic Effects:
┌────────────┬──────────┬────────────┬────────────────────────────┐
│ Event time │ Estimate │ Std. Error │ [95% Pointwise Conf. Band] │
├────────────┼──────────┼────────────┼────────────────────────────┤
│ -3 │ 0.0305 │ 0.0150 │ [-0.0078, 0.0688] │
│ -2 │ -0.0006 │ 0.0133 │ [-0.0344, 0.0333] │
│ -1 │ -0.0245 │ 0.0142 │ [-0.0607, 0.0118] │
│ 0 │ -0.0199 │ 0.0118 │ [-0.0501, 0.0102] │
│ 1 │ -0.0510 │ 0.0169 │ [-0.0940, -0.0079] * │
│ 2 │ -0.1373 │ 0.0364 │ [-0.2301, -0.0444] * │
│ 3 │ -0.1008 │ 0.0344 │ [-0.1883, -0.0133] * │
└────────────┴──────────┴────────────┴────────────────────────────┘
------------------------------------------------------------------------------
Signif. codes: '*' confidence band does not cover 0
------------------------------------------------------------------------------
Data Info
------------------------------------------------------------------------------
Control Group: Never Treated
Anticipation Periods: 0
------------------------------------------------------------------------------
Estimation Details
------------------------------------------------------------------------------
Estimation Method: Doubly Robust
------------------------------------------------------------------------------
Inference
------------------------------------------------------------------------------
Significance level: 0.05
Analytical standard errors
==============================================================================
Reference: Callaway and Sant'Anna (2021)
Event time 0 is the period of first treatment, e.g., the on-impact effect, negative event times are pre-treatment periods, and positive event times are post-treatment periods. Pre-treatment effects near zero lean in support of the parallel trends assumption (but do not confirm it), while post-treatment effects reveal how the treatment impact evolves over time. The overall ATT at the top provides a single summary measure across all post-treatment periods.
We can also use built-in plotting functionality to plot the event study results with plot_event_study():
did.plot_event_study(event_study)
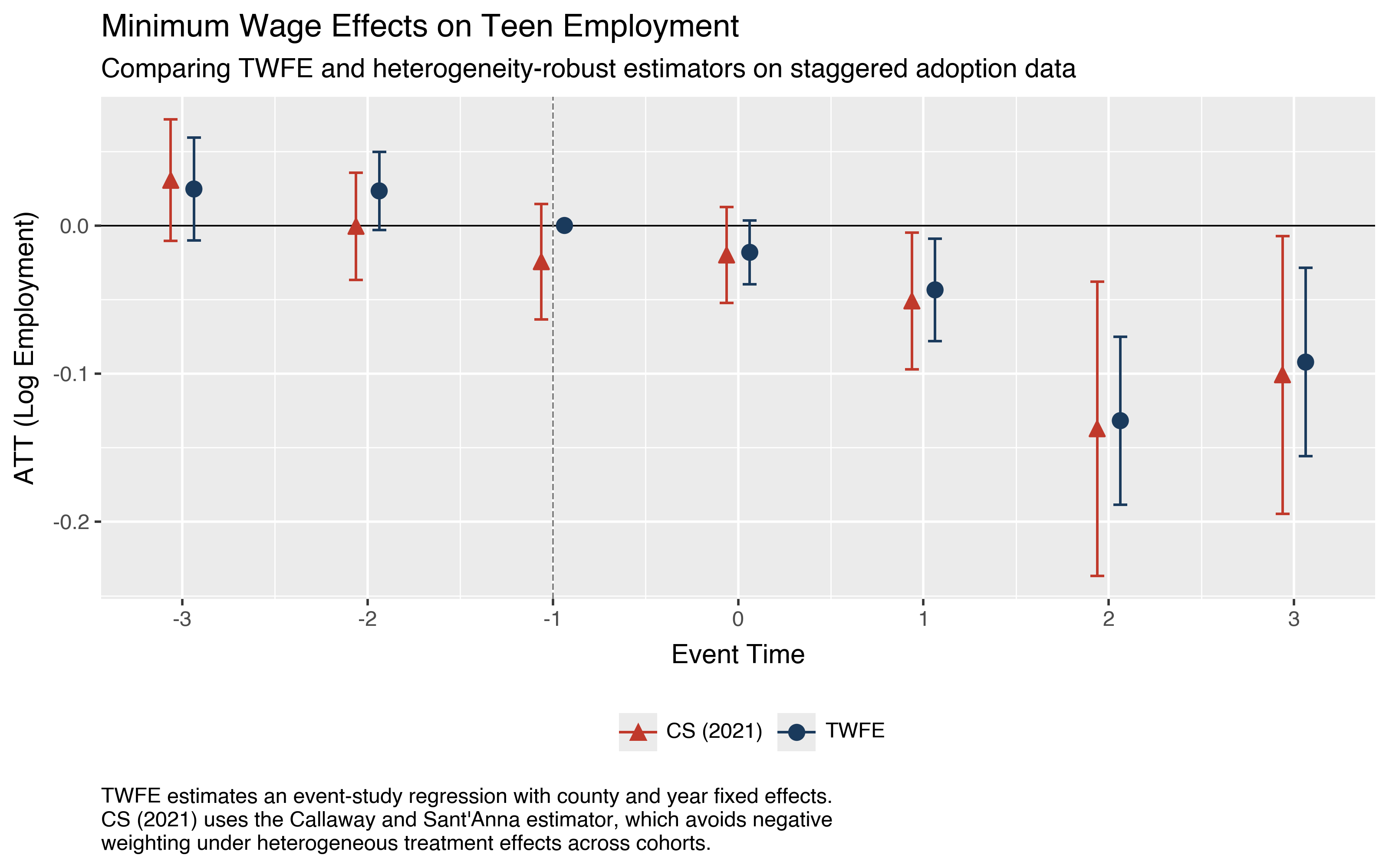
Common Troubleshooting for GPU
If set_backend("cupy") raises CuPy is not installed, the most common cause is installing the generic cupy package, which tries to compile from source. Instead, install a prebuilt wheel that matches your CUDA driver version:
uv pip install cupy-cuda12x # CUDA 12.x
uv pip install cupy-cuda11x # CUDA 11.x
Run nvidia-smi to check which CUDA version your driver supports. After installing, restart your Python process (or notebook runtime) before importing ModernDiD (CuPy availability is checked once at import time).
If you see cudaErrorInsufficientDriver, the installed CuPy wheel expects a newer CUDA version than your driver provides. Check nvidia-smi and switch to the matching wheel.
If you see No CUDA GPU is available, make sure nvidia-smi shows a device. In cloud notebooks, verify that a GPU runtime is selected.
Available Methods
Each core module includes a dedicated walkthrough covering methodology background, API usage, and guidance on interpreting results.
Core Implementations
| Module | Description | Reference |
|---|---|---|
moderndid.did |
Staggered DiD with group-time effects | Callaway & Sant'Anna (2021) |
moderndid.drdid |
Doubly robust 2-period estimators | Sant'Anna & Zhao (2020) |
moderndid.didhonest |
Sensitivity analysis for parallel trends | Rambachan & Roth (2023) |
moderndid.didcont |
Continuous/multi-valued treatments | Callaway et al. (2024) |
moderndid.didtriple |
Triple difference-in-differences | Ortiz-Villavicencio & Sant'Anna (2025) |
moderndid.didinter |
Intertemporal DiD with non-absorbing treatment | Chaisemartin & D'Haultfœuille (2024) |
Planned Development
| Module | Description | Reference |
|---|---|---|
moderndid.didml |
Machine learning approaches to DiD | Hatamyar et al. (2023) |
moderndid.drdidweak |
Robust to weak overlap | Ma et al. (2023) |
moderndid.didcomp |
Compositional changes in repeated cross-sections | Sant'Anna & Xu (2025) |
moderndid.didimpute |
Imputation-based estimators | Borusyak, Jaravel, & Spiess (2024) |
moderndid.didbacon |
Goodman-Bacon decomposition | Goodman-Bacon (2019) |
moderndid.didlocal |
Local projections DiD | Dube et al. (2025) |
moderndid.did2s |
Two-stage DiD | Gardner (2021) |
moderndid.etwfe |
Extended two-way fixed effects | Wooldridge (2021), Wooldridge (2023) |
moderndid.functional |
Specification tests | Roth & Sant'Anna (2023) |
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file moderndid-0.1.0.tar.gz.
File metadata
- Download URL: moderndid-0.1.0.tar.gz
- Upload date:
- Size: 1.4 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
31c3fc2e14ef1acffed6fa404e809ad95765009cceee32cb89d48eb8ea1dc533
|
|
| MD5 |
665c20098dd151cbcaaa7c4a6e35064f
|
|
| BLAKE2b-256 |
3d2d588801c949f6beb003c958626d8cfef9d0d74860867d280df3100d813143
|
Provenance
The following attestation bundles were made for moderndid-0.1.0.tar.gz:
Publisher:
publish.yml on jordandeklerk/moderndid
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
moderndid-0.1.0.tar.gz -
Subject digest:
31c3fc2e14ef1acffed6fa404e809ad95765009cceee32cb89d48eb8ea1dc533 - Sigstore transparency entry: 992406098
- Sigstore integration time:
-
Permalink:
jordandeklerk/moderndid@db02a2c2cd476e6bcec59358c355fe640ee8190d -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/jordandeklerk
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@db02a2c2cd476e6bcec59358c355fe640ee8190d -
Trigger Event:
push
-
Statement type:
File details
Details for the file moderndid-0.1.0-py3-none-any.whl.
File metadata
- Download URL: moderndid-0.1.0-py3-none-any.whl
- Upload date:
- Size: 1.5 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cb56327da64add20d99879339cca7ae2333c4cc07d355d757c9e80f580c2d110
|
|
| MD5 |
b1d87325bf0e8cc4e62463f3b7e52d76
|
|
| BLAKE2b-256 |
bf08a9036d4a5bf5bc55c220d97517f463f1d3e4d274b00c041b7ef982559dda
|
Provenance
The following attestation bundles were made for moderndid-0.1.0-py3-none-any.whl:
Publisher:
publish.yml on jordandeklerk/moderndid
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
moderndid-0.1.0-py3-none-any.whl -
Subject digest:
cb56327da64add20d99879339cca7ae2333c4cc07d355d757c9e80f580c2d110 - Sigstore transparency entry: 992406100
- Sigstore integration time:
-
Permalink:
jordandeklerk/moderndid@db02a2c2cd476e6bcec59358c355fe640ee8190d -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/jordandeklerk
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@db02a2c2cd476e6bcec59358c355fe640ee8190d -
Trigger Event:
push
-
Statement type:







