A domain-specific language for Mixture-of-Experts scheduling policies

Project description
MoE-PolicyLang
A scheduling language for Mixture-of-Experts models.
Author: Jesse Pokora · License: MIT
What Is This?
Large language models like Mixtral, DeepSeek, and Qwen use Mixture-of-Experts (MoE) — instead of one giant network, they have dozens of smaller "expert" networks and a router that picks which ones to use for each token. By design, only a fraction of experts are active at any time, so the rest are offloaded to CPU memory — this is intentional, not a limitation.
But managing that offloading is complex. Which experts to keep on GPU? When to prefetch the next ones? Where to run cache misses — wait for the GPU transfer, or fall back to CPU? And how to adapt as the workload shifts?
Every existing system hardcodes these decisions inside its runtime — modifying any strategy requires understanding and rewriting the system's expert-management module. MoE-PolicyLang lifts the policy out of the runtime into a small, declarative language that compiles to the same cache/evict/prefetch hooks these systems consume internally.
The Language
A MoE-PolicyLang policy is a .moe file with four composable blocks:
policy balanced {
cache {
capacity = 16
eviction = lfu
frequency_decay = 0.9
}
prefetch {
strategy = history
budget = 4
}
schedule { mode = hybrid }
adapt {
when hit_rate < 0.4 for 100 accesses
{ eviction = lru }
}
}
| Block | Controls | Options |
|---|---|---|
| cache | Which experts stay on GPU | LRU, LFU, score-based, frequency-threshold |
| prefetch | Proactive loading | History, affinity, lookahead |
| schedule | Where to run cache misses | GPU-only, CPU-fallback, hybrid |
| adapt | Runtime self-tuning | Conditional rules that hot-swap components |
Switching from LRU to LFU? Change one word. Adding prefetching? Two lines.
Two Lines to Attach
import moe_policylang
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("allenai/OLMoE-1B-7B-0924")
# Auto-generate a tuned policy from your model + GPU, attach it
mgr = moe_policylang.auto_attach(model)
output = model.generate(...)
print(mgr.get_stats()) # hit rate, transfers, evictions
Or write a policy explicitly:
mgr = moe_policylang.attach(model, """
policy aggressive {
cache { capacity = 8 eviction = lru }
}
""")
Or load a .moe file:
mgr = moe_policylang.attach(model, open("my_policy.moe").read())
Why a Language, Not YAML?
The cache, prefetch, and schedule blocks are key-value config — a JSON schema with Pydantic could handle them. What pushes this beyond declarative config is the adapt block: a small embedded rule language that monitors runtime metrics and hot-swaps policy components conditionally.
adapt {
when hit_rate < 0.4 for 100 accesses { eviction = lru }
}
This is not key-value config — it's a conditional rule with a metric, a threshold, a window, and a rewrite target. The grammar constrains what you can write (no arbitrary code in a scheduling policy), and 20 semantic rules catch bad policies at parse time, not mid-inference.
We also ship a Python eDSL (@sched.policy decorator) and an auto-attach API — three surfaces because the use cases differ: .moe files for sharing/diffing policies, the eDSL for programmatic policy construction, and auto_attach for zero-config deployment. The standalone grammar is load-bearing for the adapt semantics; the other two are convenience wrappers.
Results
Dispatch overhead
Per-layer dispatch (the Python hook that decides cache/evict/prefetch) adds < 3.2% of MoE forward-pass time on A100 (6–47 µs/layer vs. 1,459 µs baseline). This measures the policy decision overhead, not the cost of cache misses or weight transfers — those depend on the policy and workload.
Policy authoring effort
To implement a new policy variant in each system, a developer must understand and modify the system's expert-management module. MoE-PolicyLang replaces that authoring effort with a short .moe file — the 14–40× reduction measures lines a user writes to express a policy, not total system code (MoE-PolicyLang's own runtime is ~4,300 LOC).
| System | Expert-mgmt module | DSL equivalent | Authoring reduction |
|---|---|---|---|
| Fiddler | 280 LOC | 7 lines | 40× |
| HybriMoE | ~500 LOC | 14 lines | 36× |
| MoE-Infinity | 520 LOC | 16 lines | 33× |
| vLLM | 300 LOC | 12 lines | 25× |
| ExpertFlow | ~400 LOC | 16 lines | 25× |
| FineMoE | ~350 LOC | 25 lines | 14× |
Methodology: non-blank, non-comment lines in the primary expert-management module. Measured sources: Fiddler — set_expert_loc() + execute_fiddler() in src/fiddler/mixtral.py (280 LOC); MoE-Infinity — expert_prefetcher.py + expert_cache.py (520 LOC); vLLM — MixtralMoE expert dispatch in vllm/model_executor/ (300 LOC). Counts marked ~ are estimated from paper descriptions of closed-source systems. Switching between strategies (e.g., LRU → LFU) requires changing one word in the DSL vs. rewriting cache data structures in the hand-coded approach.
Policy selection matters when the cache can't hold the working set
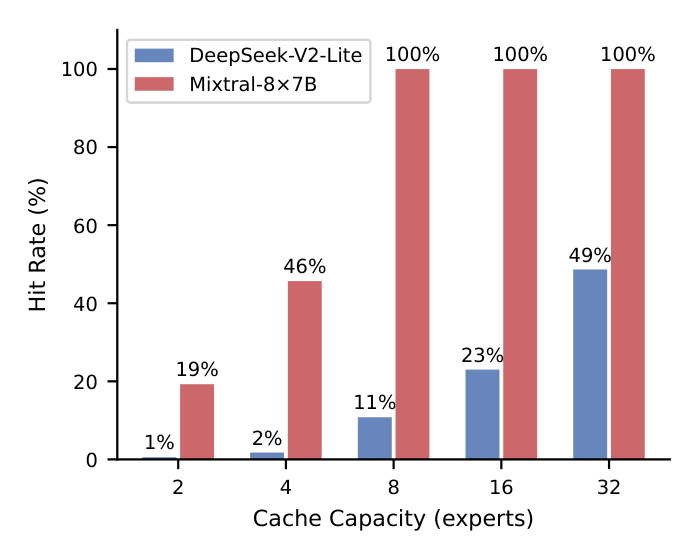
Capacity sweeps on offline traces show the architecture dependence clearly:
- Mixtral-8×7B (8 experts, top-2): saturates at cap=8 (~100% hit rate — all experts fit). Policy choice barely matters here.
- DeepSeek-V2-Lite (64 experts, top-6): reaches only 51% hit rate at cap=32 (half the experts). LFU consistently outperforms LRU across all budgets because DeepSeek has significant frequency skew (some experts activated 3–5× more often). This is the regime where policy selection and per-layer budgeting (below) make a real difference.
EPCB: Per-layer cache budgeting (with a negative result)
Not all layers see the same routing pattern — some concentrate on a few experts, others spread across many. Empirical Per-layer Cache Budgeting (EPCB) has two findings, one positive and one negative:
1. The regime caveat (read this first). Per-layer caching only helps when the per-layer budget covers each layer's active working set. On 16 GB consumer hardware — the regime most readers care about — per-layer caching hurts throughput by 16% because the per-layer budgets are too small to cover each layer's working set, and the aggregated cache pushes the CUDA allocator to the VRAM ceiling. Flat shared caching is the default recommendation for memory-constrained deployments. Per-layer wins when there is VRAM headroom and high expert counts (DeepSeek-V2-Lite on A100; see below).
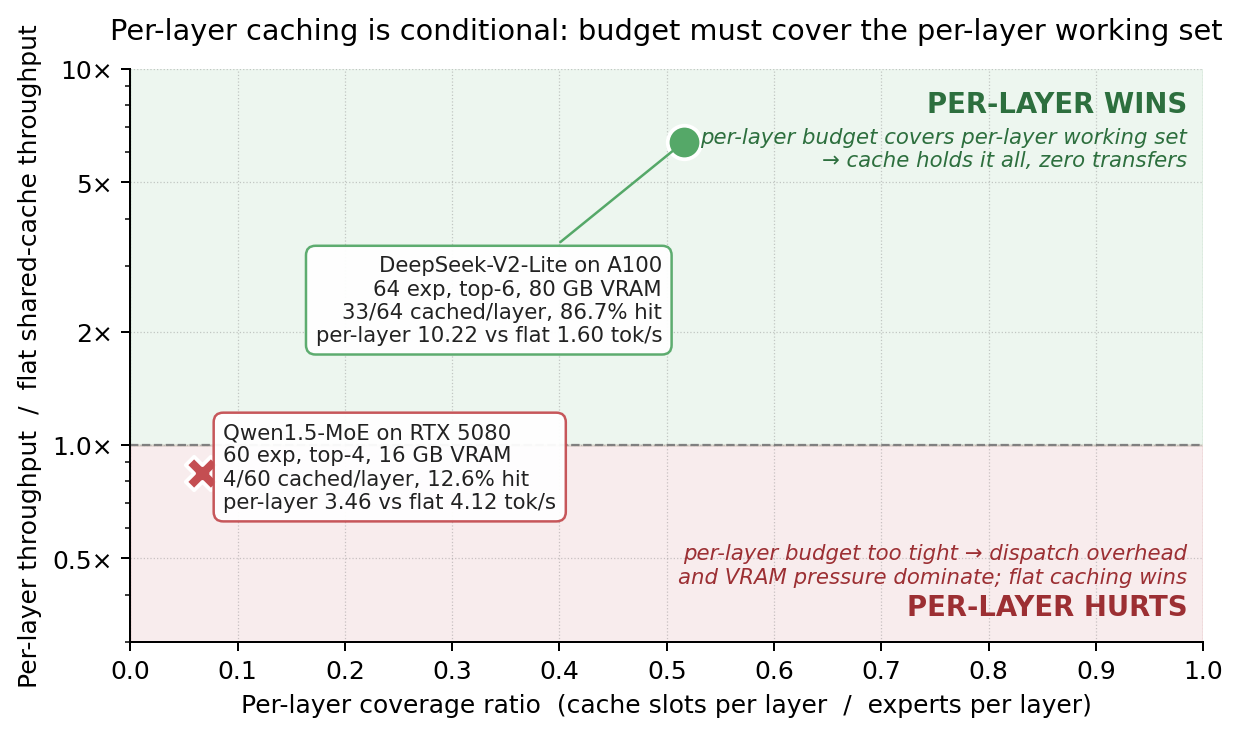
2. Per-layer cache structure is the load-bearing lever (when the regime permits). At matched total budget on DeepSeek-V2-Lite (A100-80GB), replacing a shared cache with per-layer caches yields +14.7pp hit rate in offline trace replay and eliminates all CPU↔GPU transfers in steady state. Bit-identical output verified against fully-resident baseline.
The headline throughput gain is large — 1.60 → 10.22 tok/s (+540%) — but this compares shared-32 to per-layer-864 (27× more total slots). The matched-budget +14.7pp hit rate and transfer elimination are the load-bearing findings; the 540% wall-clock number includes the capacity expansion.
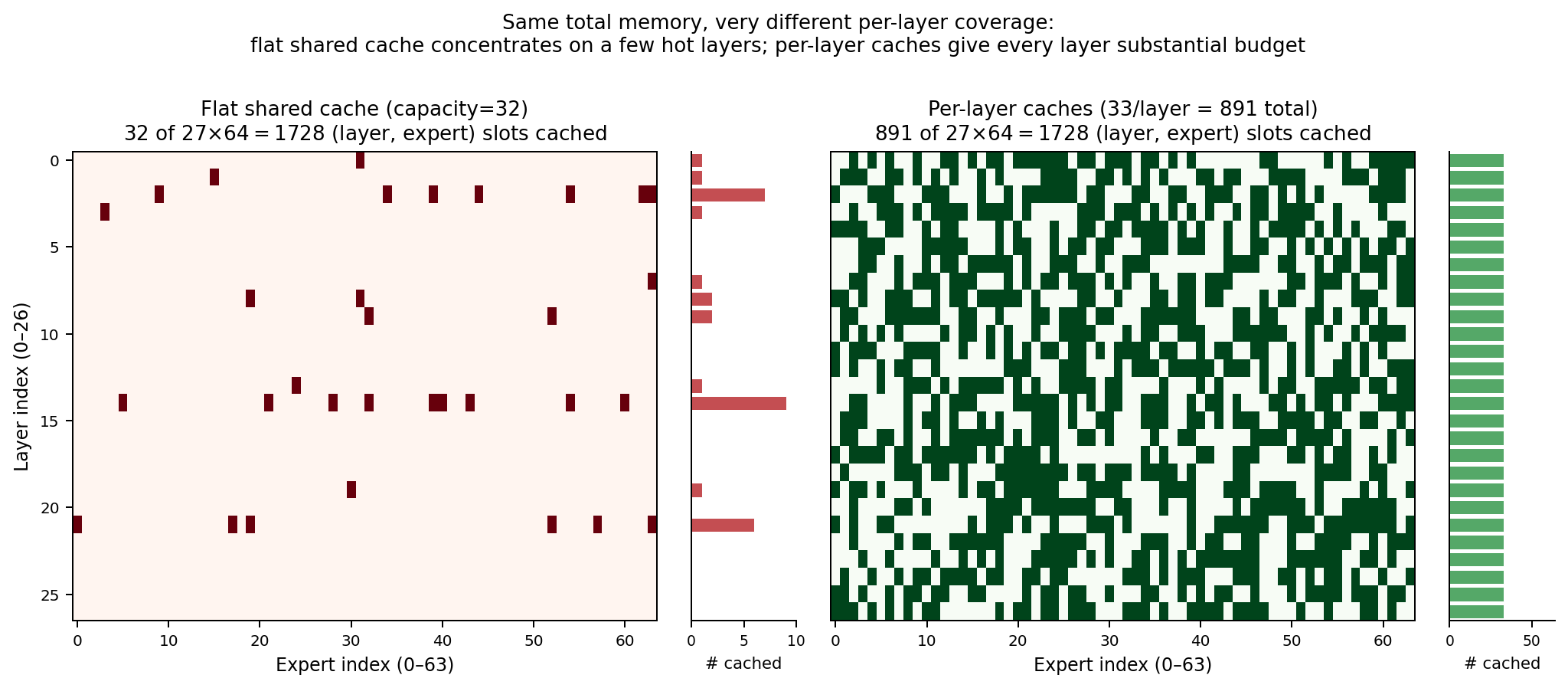
This structural difference maps directly to MoE-aware baselines. Fiddler's expert placement is a hardcoded global popularity ranking — structurally equivalent to the flat cache on the left. On an A100-80GB where 85% of Mixtral's experts fit on-device (217/256), the ranking barely matters because almost everything is resident. On a constrained GPU where only a fraction of experts fit, a global ranking starves cold layers (left heatmap) while MoE-PolicyLang's per-layer policy maintains coverage at every layer (right heatmap). The structural lever is the DSL's defense: it enables cache topologies that flat global rankings cannot express. The physical payoff is PCIe stall elimination — expert offloading is memory-bandwidth-bound, so every cache miss costs a CPU→GPU transfer. Per-layer caches that cover each layer's working set reduce misses to zero in steady state, which is how a hit-rate improvement translates directly into 6.4× wall-clock throughput (10.22 vs 1.60 tok/s on DeepSeek-V2-Lite at matched total budget).
Fiddler head-to-head (A100-80GB, Mixtral-8x7B)
We ran Fiddler and MoE-PolicyLang on the same hardware, model, prompt, and methodology (n=5, greedy decoding, 64 tokens):
| Config | tok/s (±σ) | 95% CI | GPU Peak | Hit Rate | Transfers |
|---|---|---|---|---|---|
| Fiddler | 4.17 ± 0.02 | [4.16, 4.18] | 80.6 GB | 88.3% | — |
| MPL fiddler_equiv (cap=2) | 0.18 ± 0.00 | [0.18, 0.18] | 6.4 GB | 19.5% | 4,283 |
| MPL balanced (cap=4) | 0.29 ± 0.00 | [0.29, 0.29] | 39.5 GB | 46.4% | 2,665 |
| MPL generous (cap=6) | 0.45 ± 0.00 | [0.45, 0.45] | 61.7 GB | 71.0% | 1,726 |
All MPL configs produce bit-identical output. Fiddler is 9–23× faster.
The gap is mechanism, not policy. Fiddler uses an optimized C++/CUDA transfer pipeline with pre-allocated GPU memory slots and direct DMA. MoE-PolicyLang dispatches through Python-level Tensor.to() calls in the HuggingFace forward pass. At Fiddler's 85% GPU residency (217/256 experts on-device), the placement strategy is not load-bearing — the model mostly fits. MoE-PolicyLang is a policy specification layer, not a serving system: it specifies which experts to cache, evict, and prefetch, but does not implement the physical mechanism that moves expert tensors between devices. Integrating MoE-PolicyLang's policy layer into an optimized transfer pipeline (e.g., via vLLM or a C++/CUDA backend) is future work.
3. The allocation signal does not matter. We tested six signals (Shannon entropy, inverse top-k mass, inverse variance, inverse KL, inverse Gini, uniform) and none differentiates from uniform by more than 2.5pp in hit rate, and all six collapse to within noise of uniform in wall-clock on two models. Uniform allocation is the default. Shannon entropy is available as an opt-in for models with high inter-layer entropy spread (ΔH ≳ 1 nat), but we measured it to be within noise of uniform on every model tested end-to-end.
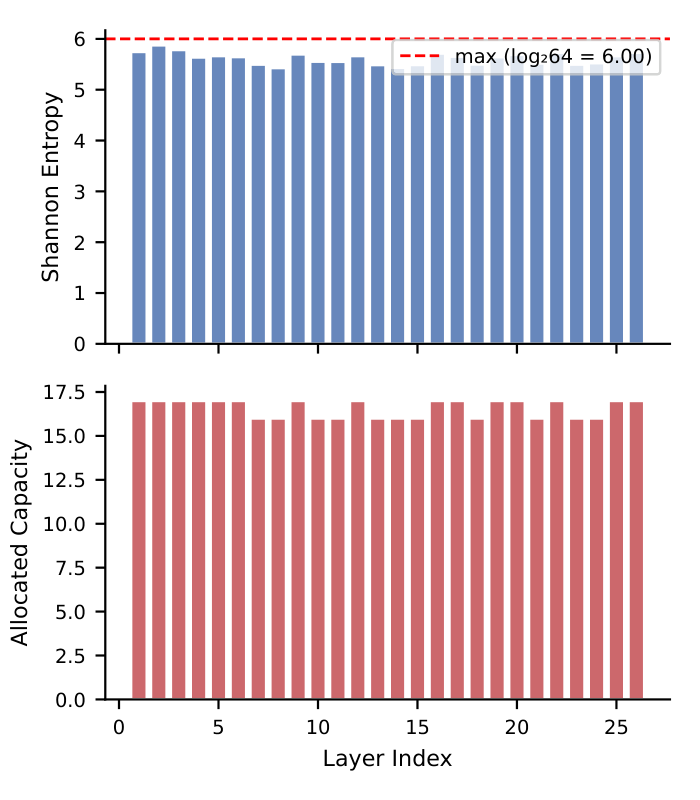
| Strategy | Total slots | Hit Rate | Δ vs shared | Wall-clock (A100) |
|---|---|---|---|---|
| Shared cache | 32 | 48.6% | baseline | 1.60 tok/s |
| Per-layer uniform | 864 (27×) | 63.3% | +14.7pp | 10.22 tok/s |
| Per-layer entropy | 864 (27×) | 65.5% | +16.9pp | 10.17 tok/s (≈ uniform) |
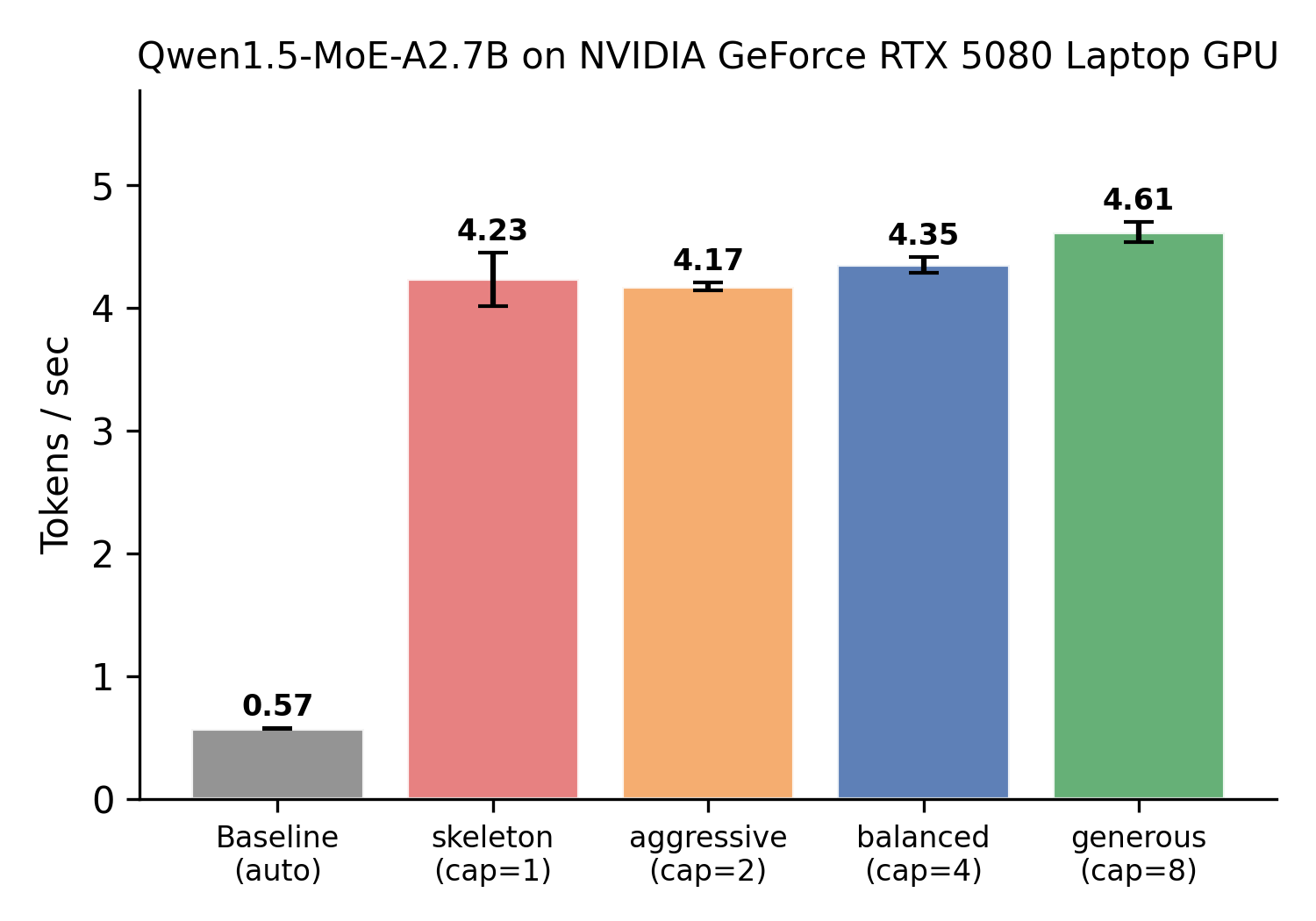
Live inference on consumer GPU
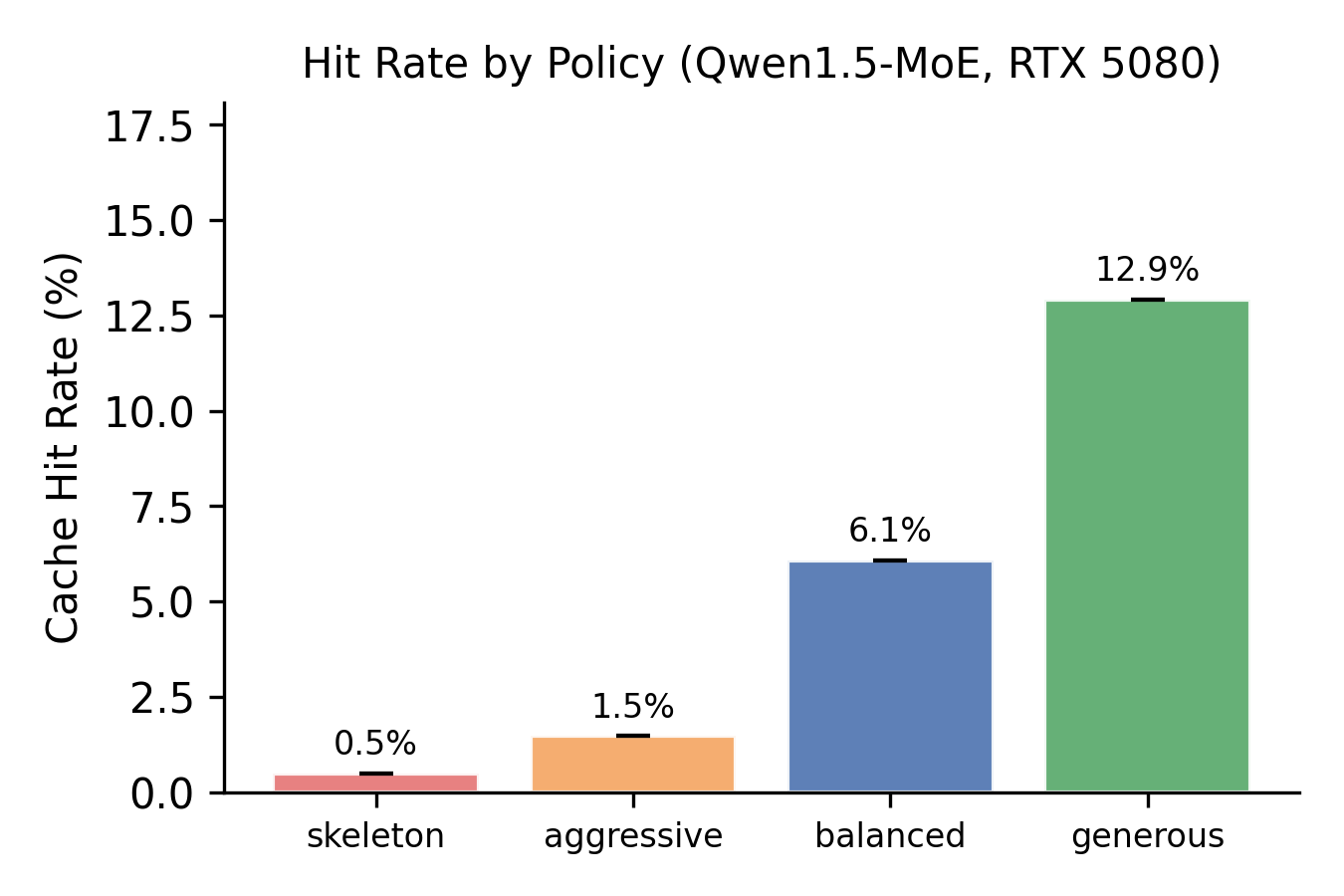
When the model doesn't fit: Qwen1.5-MoE-A2.7B (~28.6 GB fp16) on RTX 5080 (16 GB VRAM). Without MoE-PolicyLang, the only option is device_map="auto" at 0.48 tok/s. With a 4-line DSL policy:
| Config | Strategy | Cap | VRAM | tok/s | 95% CI |
|---|---|---|---|---|---|
Baseline (auto) |
— | — | 12.0 GB | 0.48±0.22 | — |
| Aggressive | LRU | 2 | 4.3 GB | 3.90±0.24 | [3.69, 4.05] |
| Balanced | LFU+hist. | 4 | 5.7 GB | 4.12±0.08 | [4.05, 4.18] |
| Generous | LFU+hist. | 8 | 7.1 GB | 4.35±0.05 | [4.31, 4.40] |
Decomposition: ~90% of the 9.1× speedup comes from expert-aware loading (skeleton on GPU, experts on CPU) — even a capacity-1 "every dispatch is a miss" config reaches 3.95 tok/s (8.2×). Caching adds the remaining +0.40 tok/s. The DSL's contribution is not the loading mechanism (which any system could implement) but making the remaining 10% — the policy layer that chooses what to cache, evict, and prefetch — accessible without runtime modification, composable across strategies, and adaptable at runtime via adapt rules that no static config can express. On higher-expert-count models, the policy layer's share grows: on DeepSeek (A100), matched-budget per-layer allocation gains +14.7pp hit rate over flat caching with the same total slot count — a pure policy-structure effect with no capacity confound.
n=5, bootstrap 95% CIs. Output correctness: greedy decoding (do_sample=False) produces bit-identical token sequences across all policy configs vs. device_map="auto" baseline (4 prompts × 3 policies = 12 comparisons); perplexity on wikitext-2 matches within 0.024%.
When the model fits (overhead measurement): OLMoE-1B-7B (~14 GB) fits entirely on 16 GB VRAM. Here, vanilla (no hooks) is fastest at 39.2 tok/s — the policy hooks add 12–14% overhead. This is not the target scenario for offloading — it measures overhead when there is nothing to offload. MoE-PolicyLang is for models that don't fit.
Installation
From PyPI:
pip install moe-policylang # DSL only (no GPU deps)
pip install moe-policylang[gpu] # + torch, transformers, accelerate
pip install moe-policylang[all] # everything
From source (development):
git clone https://github.com/jesse-pokora/MoE-PolicyLang.git
cd MoE-PolicyLang
pip install -e ".[dev,gpu]"
Cython fast path (for complex policies):
pip install moe-policylang[cython]
python setup_cython.py build_ext --inplace
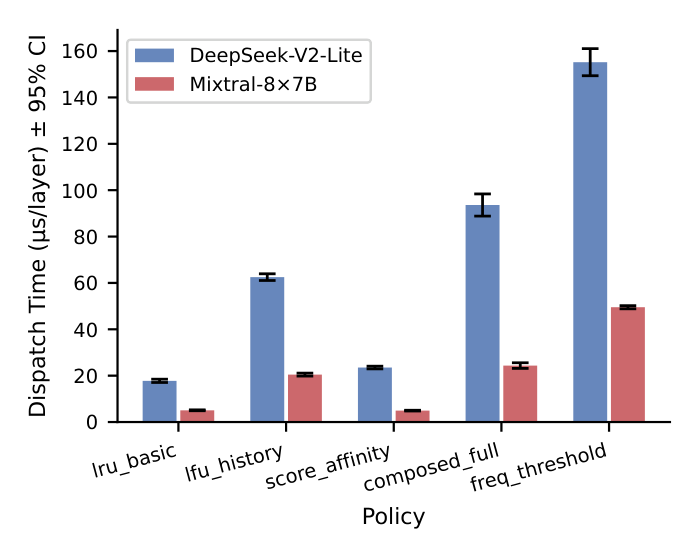
Python dispatch ranges from 6 µs/layer (simple LRU) to 47 µs/layer (composed policies with triggers). The Cython path targets the high end — freq_threshold and composed_full drop from 28–47 µs to < 10 µs/layer. Simple policies like lru_basic (6 µs) see no benefit.
Tested Models
MoE-PolicyLang auto-detects MoE structure from any HuggingFace model — no model-specific code required. We have evaluated on:
| Model | Experts × Layers | Routing | Hardware |
|---|---|---|---|
| Mixtral-8×7B-Instruct | 8 × 32 | top-2 | A100-80 GB |
| DeepSeek-V2-Lite | 64 × 27 | top-6 | A100-80 GB |
| Qwen1.5-MoE-A2.7B | 60 × 24 | top-4 | RTX 5080 (16 GB) |
| OLMoE-1B-7B | 64 × 16 | top-8 | RTX 5080 (16 GB) |
Project Structure
moe_policylang/
├── grammar.lark # Lark LALR grammar (62 productions)
├── parser.py # Grammar → PolicyIR
├── ir.py # Intermediate representation
├── validator.py # 20 semantic validation rules
├── compiler.py # IR → CompiledPolicy
├── auto.py # Auto-generate policies from model + GPU
├── dsl.py # Python eDSL (@sched.policy decorator)
├── adaptive.py # Adaptive policies (adapt blocks)
├── autotuner.py # Grid-search policy optimizer
├── cli.py # CLI: validate, compile, run
├── runtime/
│ ├── hooks.py # 5-step per-layer dispatch protocol
│ ├── cache.py # LRU / LFU / Score / FreqThreshold
│ ├── prefetch.py # Affinity / History / Lookahead
│ ├── scheduler.py # GPU-only / CPU-fallback / Hybrid
│ ├── per_layer.py # EPCB — entropy-proportional caching
│ ├── triggers.py # Memory-pressure & TTL eviction
│ └── _fast/ # Cython-accelerated paths
└── integrations/
├── __init__.py # attach() — main user API
├── huggingface.py # HuggingFace Transformers hooks
├── weight_placement.py # Expert offloading manager
└── async_transfer.py # CUDA stream async transfers
Running Experiments
# Offline trace replay (no GPU needed)
python scripts/run_eval.py
python scripts/run_sweep.py
# Live inference on consumer GPU
python scripts/run_dsl_demo.py
python scripts/run_constrained_e2e.py
# Generate all paper figures
python scripts/generate_figures.py
# Benchmarks & evaluations (requires CUDA GPU + model weights)
python scripts/bench_qwen_multirun.py # Qwen throughput (Table 4)
python scripts/bench_coldstart.py # Cold-start throughput analysis
python scripts/bench_power.py # Power/energy measurement
python scripts/eval_quality.py # Perplexity evaluation (wikitext-2)
python scripts/ablation_epcb_sensitivity.py # EPCB hyperparameter sweep
python scripts/plot_coldstart.py # Generate cold-start figure
Tests
python -m pytest tests/ -q
398+ tests covering parsing, validation, compilation, runtime dispatch, adaptive policies, per-layer EPCB, and integration hooks.
Documentation
See docs/MANUAL.md for the full language reference,
runtime API, and policy authoring guide.
Citation
@misc{pokora2026moepolicylang,
title={MoE-PolicyLang: A Domain-Specific Language for Mixture-of-Experts Scheduling Policies},
author={Pokora, Jesse},
year={2026},
url={https://github.com/jesse-pokora/MoE-PolicyLang}
}
License
MIT License — Copyright (c) 2026 Jesse Pokora
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file moe_policylang-1.2.3.tar.gz.
File metadata
- Download URL: moe_policylang-1.2.3.tar.gz
- Upload date:
- Size: 84.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a7812c6937e7a043ef0b3e0d133662d2cc36195fb665488206a7e4d74509c26a
|
|
| MD5 |
9004b8e23de4a89281b3bbed196edd33
|
|
| BLAKE2b-256 |
d5dcd2a3a4ee5e52a3f6911ddb15660f129b3a30b82d78706061835f476b580e
|
File details
Details for the file moe_policylang-1.2.3-py3-none-any.whl.
File metadata
- Download URL: moe_policylang-1.2.3-py3-none-any.whl
- Upload date:
- Size: 94.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5c0b99c8a1769d3800ce96b63a91d60e1b049bb5505a2facb9575f251e107189
|
|
| MD5 |
baa8f7bfa7110613225164522ad6e9a4
|
|
| BLAKE2b-256 |
e51e8325df04fdfb3aa1c233cd4c9a53899e5d06bedd3b3bcc917deeb6bb2aca
|







