Recency-Frequency based recommendation scoring

Project description
RFscorer



rfscorer is a Python package for Recency-Frequency based recommendation scoring.
It estimates product-choice probabilities — the preference score for each user-item pair, forming a matrix equivalent to a rating matrix — from interaction history using two key signals: recency (how recently a user interacted with an item) and frequency (how often). You can configure which events to predict (revisits, purchases, conversions, etc.) using your evaluation data.
The package is designed for product recommendation, especially when you prefer interpretable recommendations based on interaction history over black-box models.
Note: In this package, RF stands for Recency-Frequency, not Random Forest.
Features
- scikit-learn-style API — familiar
fit()/transform()interface makes it easy to integrate into existing data science workflows - Minimal data requirements — works with any interaction log with three columns: user, item, and timestamp; no ratings or explicit feedback required
- Explainable scoring — probabilities are computed using optimization with Recency-Frequency monotonicity constraints, making every score fully traceable and auditable; 3D surface visualization further supports intuitive understanding
- Probabilistic output — product-choice probabilities work as preference scores, enabling expected value calculations and probabilistic ranking of recommendations
- Extensible — the probability matrix from
transform()can be directly used as input to collaborative filtering or other downstream recommendation models - Calibration-free probabilities — unlike typical ML models, probabilities are computed directly from interaction frequency without requiring calibration, making them reliable and easy to interpret.
Installation
pip install rfscorer
Usage
Below is a minimal example of building a model and scoring recommendations from an interaction log. For complete, working code with data loading and evaluation, see examples/basic_usage.ipynb.
Minimal Example
import pandas as pd
from rfscorer import RecencyFrequencyScorer, split_by_date
# Load your interaction log
df = ... # columns: user, item, datetime
# Split by target date
target_date = "2026-07-07"
df_obs, df_eval = split_by_date(df, target_date) # default: obs=28 days, eval=7 days
# Fit and optimize
scorer = RecencyFrequencyScorer()
scorer.fit(df_obs, df_eval)
scorer.optimize(kind="mono")
# Score recommendations (on test data)
df_test = ... # test data (columns: user, item, datetime)
df_test_obs, _ = split_by_date(df_test, target_date)
df_scores = scorer.transform(df_test_obs, target_date, kind="mono")
| user | item | recency | frequency | probability | order |
|---|---|---|---|---|---|
| u_001 | i_032 | 1 | 4 | 0.1167 | 1 |
| u_001 | i_017 | 2 | 3 | 0.0789 | 2 |
| u_001 | i_045 | 3 | 1 | 0.0248 | 3 |
| u_002 | i_011 | 1 | 2 | 0.0621 | 1 |
| u_002 | i_058 | 4 | 1 | 0.0182 | 2 |
The probability score determines recommendation rank. For each user, recommend items from highest to lowest probability. Because each score is a probability, you can also calculate expected values (e.g., expected revenue per recommendation). The order column makes it easy to implement business rules (e.g., "recommend top 2 items per user").
Visualization: Comparing Optimization Approaches
While the package supports many optimization approaches, here we visualize three representative methods:
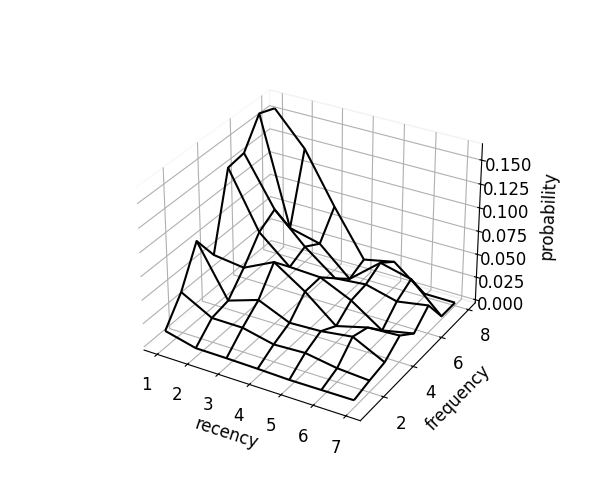
scorer.plot_probability_surface(kind="emp") # empirical (raw rates)
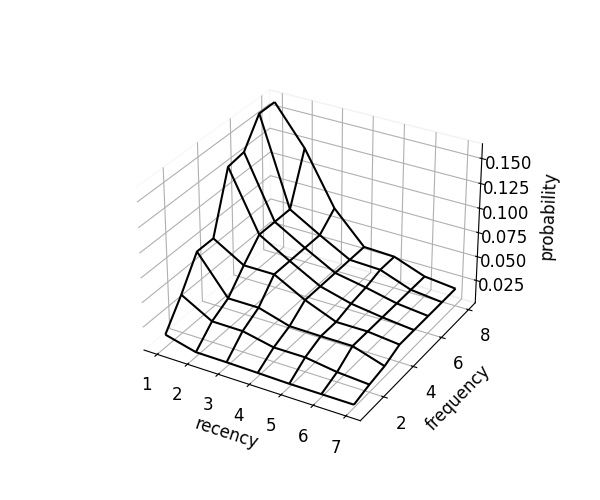
scorer.optimize(kind="mono") # RF monotonicity
scorer.plot_probability_surface(kind="mono")
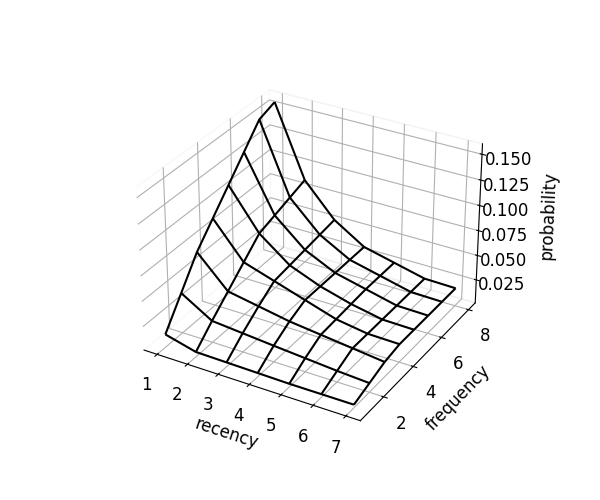
scorer.optimize(kind="mcc") # convex in R, concave in F
scorer.plot_probability_surface(kind="mcc")
 |
 |
 |
| Empirical | Monotonicity | Monotonicity-Convex-Concave |
Each surface reflects different assumptions about recency (time since a user interacted with an item) and frequency (number of interactions):
- Empirical: Raw product-choice probabilities without constraints; noisy and may violate monotonicity, sometimes recommending products in unnatural order.
- Monotonicity: Enforces monotonic relationships, ensuring products are recommended in natural and stable order.
- Monotonicity-Convex-Concave: Adds smoothness constraints with monotonically decreasing slopes in recency, producing the smoothest surface. Note: stronger constraints may overfit to training data; validate on test data.
Examples
- examples/basic_usage.ipynb — end-to-end walkthrough: load data, fit, optimize, visualize, transform, and evaluate recommendation quality (precision, recall, F1 at each rank cutoff)
References
Citation
If you use rfscorer in academic work, you can cite it as follows in the body of your paper:
We used
rfscorer(Iwanaga et al., 2016), a Python library for Recency-Frequency based recommendation scoring for product recommendation.¹
The full reference is:
@article{Iwanaga2016,
author = {Jiro Iwanaga and Naoki Nishimura and Noriyoshi Sukegawa and Yuichi Takano},
title = {Estimating product-choice probabilities from recency and frequency of page views},
journal = {Knowledge-Based Systems},
volume = {99},
pages = {157--167},
year = {2016},
url = {https://www.sciencedirect.com/science/article/abs/pii/S0950705116000848}
}
If you additionally use the probability matrix as input to a collaborative filtering model, please also cite:
@article{Iwanaga2019,
author = {Jiro Iwanaga and Naoki Nishimura and Noriyoshi Sukegawa and Yuichi Takano},
title = {Improving collaborative filtering recommendations by estimating user preferences from clickstream data},
journal = {Electronic Commerce Research and Applications},
volume = {37},
pages = {100877},
year = {2019},
url = {https://www.sciencedirect.com/science/article/abs/pii/S1567422319300547}
}
License
MIT License
RFScorer (日本語README)
rfscorer は、Recency-Frequency(最新度・頻度)に基づく商品推薦スコアリングを提供する Python パッケージです。
ユーザーとアイテムのペアごとの選好スコア(商品選択確率による評価値行列と等価)を、ユーザーの行動履歴から推定します。スコアは、最新度(recency)(ユーザーがアイテムに最後に接触してからの経過時間)と 頻度(frequency)(接触の回数)に基づいて計算されます。予測対象のイベント(再閲覧、購買、コンバージョンなど)は評価データを通じて自由に設定できます。
本パッケージは、商品推薦を目的としており、特に「ブラックボックスなモデルではなく、行動履歴に基づく解釈可能な商品推薦」を重視する場合に有用です。
注:本パッケージにおいて RF は Recency-Frequency(最新度・頻度) を意味し、Random Forest(ランダムフォレスト)ではありません。
特徴
- scikit-learn 風の API — 馴染みのある
fit()/transform()インターフェースにより、既存のデータサイエンスワークフローに簡単に組み込めます - 最小限のデータ要件 —
user、item、timestampの3列さえあれば、どんなインタラクションログでも動作します。評価値や明示的なフィードバックは不要です - 説明可能なスコアリング — 確率は Recency-Frequency 単調性制約のもとで最適化により計算されるため、すべてのスコアが完全にトレース可能・監査可能です。さらに3Dサーフェスによる可視化が直感的な理解を支援します
- 確率的な出力 — 商品選択確率を選好スコアとして利用でき、期待値計算や確率に基づく推薦順序付けが可能です
- 拡張性 —
transform()が返す確率行列は、協調フィルタリングなど他の下流の推薦モデルへの入力として直接利用できます - キャリブレーション不要の確率値 — 一般的な機械学習モデルとは異なり、確率はインタラクション頻度から直接計算されるため、キャリブレーション不要で、信頼性が高く解釈しやすい値となります
インストール
pip install rfscorer
使い方
以下は、インタラクションログ(閲覧履歴)からモデル構築と推薦スコア(商品選択確率)の算出までを行う最小限の例です。 データロードから評価までを含む動作コードについては、examples/basic_usage.ipynb を参照してください。
最小限の例
import pandas as pd
from rfscorer import RecencyFrequencyScorer, split_by_date
# インタラクションログの読み込み
df = ... # カラム: user, item, datetime
# 基準日で観測期間・評価期間に分割
target_date = "2026-07-07"
df_obs, df_eval = split_by_date(df, target_date) # デフォルト:観測28日、評価7日
# モデル構築と最適化
scorer = RecencyFrequencyScorer()
scorer.fit(df_obs, df_eval)
scorer.optimize(kind="mono")
# 推薦スコアを算出(テストデータ)
df_test = ... # test data (columns: user, item, datetime)
df_test_obs, _ = split_by_date(df_test, target_date)
df_scores = scorer.transform(df_test_obs, target_date, kind="mono")
| user | item | recency | frequency | probability | order |
|---|---|---|---|---|---|
| u_001 | i_032 | 1 | 4 | 0.1167 | 1 |
| u_001 | i_017 | 2 | 3 | 0.0789 | 2 |
| u_001 | i_045 | 3 | 1 | 0.0248 | 3 |
| u_002 | i_011 | 1 | 2 | 0.0621 | 1 |
| u_002 | i_058 | 4 | 1 | 0.0182 | 2 |
probability スコアが推薦順位を決定します。各ユーザーに対して、商品選択確率の高い順にアイテムを推薦します。各スコアが確率値であるため、期待値計算(例:推薦結果に対する期待収益の計算)も可能です。order 列を使えば、業務ルール(例:「各ユーザーに上位2個の商品を推薦する」)を簡単に実装できます。
可視化:最適化手法の比較
本パッケージは多くの最適化アプローチをサポートしています。ここでは代表的な3つの手法を可視化します。
scorer.plot_probability_surface(kind="emp") # empirical (raw rates)
scorer.optimize(kind="mono") # RF monotonicity
scorer.plot_probability_surface(kind="mono")
scorer.optimize(kind="mcc") # convex in R, concave in F
scorer.plot_probability_surface(kind="mcc")
|
|
|
| Empirical | Monotonicity | Monotonicity-Convex-Concave |
各グラフ、最新度(recency)(ユーザーが商品に接触してからの経過時間)と 頻度(frequency)(接触回数)について、それぞれ異なる仮定を反映しています:
- Empirical(生データによる集計): 制約なしの生の商品選択確率。ノイズを含み、単調性を満たさない場合があり、商品を不自然な順序で推薦してしまうことがあります。
- Monotonicity(単調性): 単調性制約を適用し、商品が自然で安定した順序で推薦されることを保証します。
- Monotonicity-Convex-Concave(単調性+凸凹): 最新度に対して傾きが単調に減少する平滑性制約を追加し、最も滑らかなグラフを生成します。注意:制約が強くなるほど学習データに過剰適合するリスクがあるため、テストデータでの検証が重要です。
サンプル
- examples/basic_usage.ipynb — データロードからモデル構築、最適化、可視化、推薦スコア算出、推薦品質の評価までのコードを紹介します。
参考文献
引用について
学術論文等で rfscorer を利用する場合は、論文の引用と本Githubへのリンクを脚注を加え、本文中で以下のように引用できます:
We used
rfscorer(Iwanaga et al., 2016), a Python library for Recency-Frequency based recommendation scoring for product recommendation.¹
参考文献とBibTexは以下のとおりです:
@article{Iwanaga2016,
author = {Jiro Iwanaga and Naoki Nishimura and Noriyoshi Sukegawa and Yuichi Takano},
title = {Estimating product-choice probabilities from recency and frequency of page views},
journal = {Knowledge-Based Systems},
volume = {99},
pages = {157--167},
year = {2016},
url = {https://www.sciencedirect.com/science/article/abs/pii/S0950705116000848}
}
さらに、商品選択確率行列を協調フィルタリングモデルの入力として利用する場合は、以下の文献も併せて引用してください:
@article{Iwanaga2019,
author = {Jiro Iwanaga and Naoki Nishimura and Noriyoshi Sukegawa and Yuichi Takano},
title = {Improving collaborative filtering recommendations by estimating user preferences from clickstream data},
journal = {Electronic Commerce Research and Applications},
volume = {37},
pages = {100877},
year = {2019},
url = {https://www.sciencedirect.com/science/article/abs/pii/S1567422319300547}
}
ライセンス
MIT License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rfscorer-0.4.2.tar.gz.
File metadata
- Download URL: rfscorer-0.4.2.tar.gz
- Upload date:
- Size: 588.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7412ce788a907bb52d20d5ca5c37325b64d3efc7559bc46da82007dc00e67e57
|
|
| MD5 |
4d6f68bf495fa03f21a40ef330882fdd
|
|
| BLAKE2b-256 |
9a279b9dcc89825d30256aec3c58d0dbb92a092245fbcf73d151e2596fd8e12a
|
File details
Details for the file rfscorer-0.4.2-py3-none-any.whl.
File metadata
- Download URL: rfscorer-0.4.2-py3-none-any.whl
- Upload date:
- Size: 28.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a4704ccb6111cb61906ce5d09002c4489572bc8d29fc8d5a8d7d9035b83f1e02
|
|
| MD5 |
456fd8d9b370f42ede1e7507c3623c99
|
|
| BLAKE2b-256 |
6ad647fa0024902063e075bea5b4c26e178b383fd66e3516e31f584647e38b00
|







