Recency-Frequency based recommendation scoring

Project description
RFscorer



rfscorer is a Python package for Recency-Frequency based recommendation scoring.
It estimates recommendation scores (product-choice probabilities) for items a user has interacted with, based on two signals: recency (time since last interaction) and frequency (number of interactions). You can choose any event as the prediction target (revisits, purchases, conversions, etc.).
The package is useful not only for recommending items a user has interacted with in natural order based on product-choice probabilities, but also as input to downstream systems — as a rating matrix for collaborative filtering or as features for ML models.
Note: In this package, RF stands for Recency-Frequency, not Random Forest.
Features
- scikit-learn style —
fit()/transform()interface - Minimal data — works with any behavior history with three columns:
user,item,datetime - Explainable — probabilities are optimized under RF monotonicity constraints; 3D visualization for intuitive understanding
- Calibration-free — probabilities are computed directly from recency and frequency, no calibration needed
- Probabilistic output — expected value calculations (e.g., revenue) are straightforward
Installation
pip install rfscorer
Usage
Below is a minimal example of building a model and scoring recommendations from a behavior history. For complete, working code, see Examples.
Minimal Example
import pandas as pd
from rfscorer import RecencyFrequencyScorer, split_by_date
# Load your behavior history
df = ... # columns: user, item, datetime
# Split by target date
target_date = "2026-07-07"
df_obs, df_gt = split_by_date(df, target_date, 7, 1) # observation: 7 days, ground truth: 1 day
# Fit and optimize
scorer = RecencyFrequencyScorer()
scorer.fit(df_obs, df_gt)
scorer.optimize(kind="mono")
# Score recommendations (on test data)
df_test = ... # test data (columns: user, item, datetime)
df_test_obs, _ = split_by_date(df_test, target_date, 7, 1)
df_scores = scorer.transform(df_test_obs, target_date, kind="mono")
| user | item | recency | frequency | probability | order |
|---|---|---|---|---|---|
| u_001 | i_032 | 1 | 4 | 0.1167 | 1 |
| u_001 | i_017 | 2 | 3 | 0.0789 | 2 |
| u_001 | i_045 | 3 | 1 | 0.0248 | 3 |
| u_002 | i_011 | 1 | 2 | 0.0621 | 1 |
| u_002 | i_058 | 4 | 1 | 0.0182 | 2 |
Recommend items to each user from highest to lowest probability. Since scores are probabilities, expected value calculations are straightforward (e.g., expected revenue per recommendation). Use the order column to apply business rules (e.g., recommend the top 2 items per user).
Visualization: Comparing Optimization Approaches
The package supports many optimization approaches. Here we visualize three representative methods:
scorer.plot_probability_surface(kind="emp") # empirical (raw rates)
scorer.optimize(kind="mono") # RF monotonicity
scorer.plot_probability_surface(kind="mono")
scorer.optimize(kind="mcc") # convex in R, concave in F
scorer.plot_probability_surface(kind="mcc")
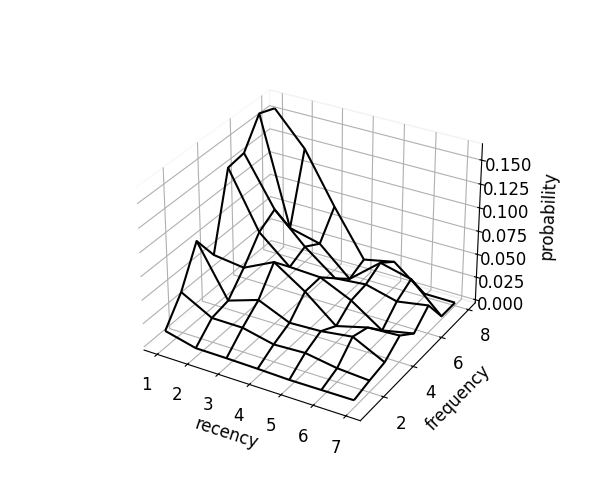 |
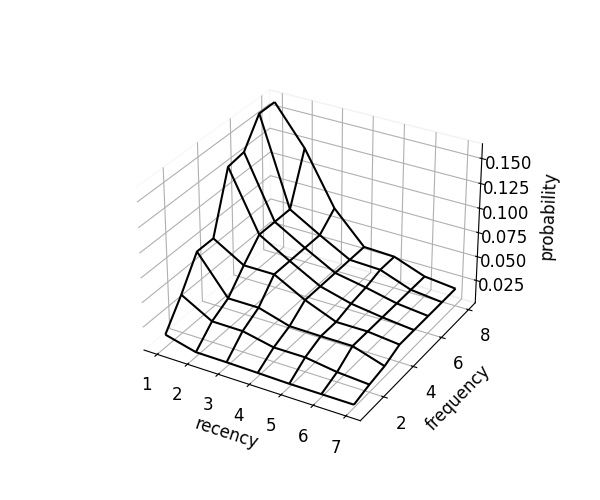 |
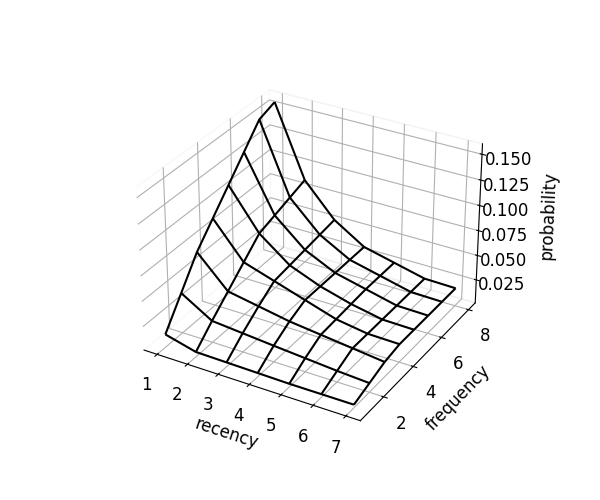 |
| Empirical | Monotonicity | Monotonicity-Convex-Concave |
Each surface shows different assumptions about recency (time since last interaction) and frequency (number of interactions):
- Empirical: Raw probabilities without constraints. Noisy and may violate monotonicity, sometimes recommending items in unnatural order.
- Monotonicity: Probabilities with RF monotonicity constraints. Guarantees items are recommended in natural order.
- Monotonicity-Convex-Concave: Probabilities with RF monotonicity and convexity-concavity constraints. Produces the smoothest surface.
Examples
- examples/tutorial_beginner_en.ipynb — end-to-end walkthrough: load data, fit, optimize, visualize, transform, and evaluate
- examples/tutorial_practical_en.ipynb — practical workflow: chronological train/test split, build all 9 models, compare accuracy, and save/load the model
- examples/tutorial_advanced_fit_rolling_en.ipynb — advanced workflow: time-series rolling training with
fit_rolling()to stabilize empirical probabilities across multiple reference dates
References
Citation
If you use rfscorer in academic work, you can cite it as follows in the body of your paper:
We used
rfscorer(Iwanaga et al., 2016), a Python library for Recency-Frequency based recommendation scoring for product recommendation.¹
The full reference is:
@article{Iwanaga2016,
author = {Jiro Iwanaga and Naoki Nishimura and Noriyoshi Sukegawa and Yuichi Takano},
title = {Estimating product-choice probabilities from recency and frequency of page views},
journal = {Knowledge-Based Systems},
volume = {99},
pages = {157--167},
year = {2016},
url = {https://www.sciencedirect.com/science/article/abs/pii/S0950705116000848}
}
If you also use the probability matrix as input to a collaborative filtering model or as ML features, please also cite:
@article{Iwanaga2019,
author = {Jiro Iwanaga and Naoki Nishimura and Noriyoshi Sukegawa and Yuichi Takano},
title = {Improving collaborative filtering recommendations by estimating user preferences from clickstream data},
journal = {Electronic Commerce Research and Applications},
volume = {37},
pages = {100877},
year = {2019},
url = {https://www.sciencedirect.com/science/article/abs/pii/S1567422319300547}
}
License
MIT License
RFscorer (日本語README)
rfscorer は、Recency-Frequency(最新度・頻度)に基づく商品推薦スコアリングを提供する Python パッケージです。
ユーザーの行動履歴から、ユーザーが過去に接触した商品の推薦スコア(商品選択確率)を推定します。スコアは、最新度(recency)(ユーザーが商品に最後に接触してからの経過時間)と 頻度(frequency)(接触の回数)に基づいて計算されます。予測対象のイベント(再閲覧、購買、コンバージョンなど)は自由に設定できます。
本パッケージは、ユーザーが過去に接触した商品を商品選択確率に基づく自然な順序で推薦できるだけでなく、推薦システムの入力(協調フィルタリングの評価値行列や機械学習モデルの特徴量)にも有用です。
注:本パッケージにおいて RF は Recency-Frequency(最新度・頻度) を意味し、Random Forest(ランダムフォレスト)ではありません。
特徴
- scikit-learn ライク — 一般的な機械学習ライブラリが提供する
fit()/transform()によるインターフェースを提供 - 最小のデータ要件 —
user、item、datetimeの3カラムをもつ行動履歴で動作 - 説明可能性 — RF単調性制約のもとで最適化された商品選択確率は説明が容易。可視化により直感的な理解を支援
- キャリブレーション不要 — 一般的な機械学習と異なり、商品選択確率がRecencyとFrequencyから直接計算されるため補正が不要
- 確率的な出力 — 商品選択確率を用いるため収益などの期待値計算が容易
インストール
pip install rfscorer
使い方
以下は、行動履歴からモデル構築と推薦スコア(商品選択確率)の算出までを行う最小限の例です。 動作するコードについては、サンプルを参照してください。
最小限の例
import pandas as pd
from rfscorer import RecencyFrequencyScorer, split_by_date
# 行動履歴の読み込み
df = ... # カラム: user, item, datetime
# 基準日で観測データ・正解データに分割
target_date = "2026-07-07"
df_obs, df_gt = split_by_date(df, target_date, 7, 1) # 観測データ7日間・正解データ1日間
# モデル構築と最適化
scorer = RecencyFrequencyScorer()
scorer.fit(df_obs, df_gt)
scorer.optimize(kind="mono")
# 推薦スコアを算出(テストデータ)
df_test = ... # テストデータ(カラム: user, item, datetime)
df_test_obs, _ = split_by_date(df_test, target_date, 7, 1)
df_scores = scorer.transform(df_test_obs, target_date, kind="mono")
| user | item | recency | frequency | probability | order |
|---|---|---|---|---|---|
| u_001 | i_032 | 1 | 4 | 0.1167 | 1 |
| u_001 | i_017 | 2 | 3 | 0.0789 | 2 |
| u_001 | i_045 | 3 | 1 | 0.0248 | 3 |
| u_002 | i_011 | 1 | 2 | 0.0621 | 1 |
| u_002 | i_058 | 4 | 1 | 0.0182 | 2 |
各ユーザーに対して、商品選択確率(probability )の高い順に商品を推薦します。推薦スコアが確率値であるため、期待値計算(例:推薦結果に対する期待収益の計算)が容易です。order 列を使えば、業務ルール(例:「各ユーザーに上位2個の商品を推薦する」)を簡単に実装できます。
可視化:最適化手法の比較
本パッケージは多くの最適化アプローチをサポートしています。ここでは代表的な3つの手法を可視化します。
scorer.plot_probability_surface(kind="emp") # empirical (raw rates)
scorer.optimize(kind="mono") # RF monotonicity
scorer.plot_probability_surface(kind="mono")
scorer.optimize(kind="mcc") # convex in R, concave in F
scorer.plot_probability_surface(kind="mcc")
|
|
|
| Empirical | Monotonicity | Monotonicity-Convex-Concave |
各グラフの最新度(recency)(ユーザーが商品に接触してからの経過時間)と 頻度(frequency)(接触回数)は次の仮定を反映しています:
- Empirical(生データ): 制約なしの商品選択確率。ノイズにより単調性を満たさず、不自然な順序で商品を推薦する場合がある。
- Monotonicity(単調性): RF単調性制約を課した商品選択確率。商品を自然な順序で推薦することを保証する。
- Monotonicity-Convex-Concave(単調性+凸凹): RF単調性制約と凹凸性制約を課した商品選択確率。最も滑らかなグラフを生成する
サンプル
- examples/tutorial_beginner_ja.ipynb — 初級編:データロード、モデル構築・最適化・可視化、推薦スコア算出、精度評価までのコードを紹介します。
- examples/tutorial_practical_ja.ipynb — 実践編:時系列での訓練・テスト分割、全9種のモデル構築と精度比較、モデルの保存・ロードを紹介します。
- examples/tutorial_advanced_fit_rolling_ja.ipynb — 応用編:
fit_rolling()で複数の基準日にわたるローリング集計を行うことで経験的商品選択確率を安定させます。全9種モデルの精度比較も含みます。
参考文献
引用について
学術論文等で rfscorer を利用する場合は、論文の引用と本Githubへのリンクを脚注を加え、本文中で以下のように引用できます:
We used
rfscorer(Iwanaga et al., 2016), a Python library for Recency-Frequency based recommendation scoring for product recommendation.¹
参考文献とBibTexは以下のとおりです:
@article{Iwanaga2016,
author = {Jiro Iwanaga and Naoki Nishimura and Noriyoshi Sukegawa and Yuichi Takano},
title = {Estimating product-choice probabilities from recency and frequency of page views},
journal = {Knowledge-Based Systems},
volume = {99},
pages = {157--167},
year = {2016},
url = {https://www.sciencedirect.com/science/article/abs/pii/S0950705116000848}
}
さらに、商品選択確率行列を協調フィルタリングモデルの入力として利用する場合や機械学習の特徴量として利用する場合には、以下の文献も併せて引用してください:
@article{Iwanaga2019,
author = {Jiro Iwanaga and Naoki Nishimura and Noriyoshi Sukegawa and Yuichi Takano},
title = {Improving collaborative filtering recommendations by estimating user preferences from clickstream data},
journal = {Electronic Commerce Research and Applications},
volume = {37},
pages = {100877},
year = {2019},
url = {https://www.sciencedirect.com/science/article/abs/pii/S1567422319300547}
}
ライセンス
MIT License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rfscorer-0.5.0.tar.gz.
File metadata
- Download URL: rfscorer-0.5.0.tar.gz
- Upload date:
- Size: 3.1 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
183c2cd6aebd69fdbf198045cea0bd667c55162af91320fc85ec3972e9474848
|
|
| MD5 |
b7f97194c291a0dee7ad3f551484ba62
|
|
| BLAKE2b-256 |
ffe95b41fc121b80f4998d7db2881401ea08f4d697521a9a7a350d502a184924
|
File details
Details for the file rfscorer-0.5.0-py3-none-any.whl.
File metadata
- Download URL: rfscorer-0.5.0-py3-none-any.whl
- Upload date:
- Size: 35.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f308cca4e6dcb844aa0590a6155e1ba3c21541ce6404effa0bcd020e24cbe862
|
|
| MD5 |
17696180273b0af623eaf3e87aacfd0b
|
|
| BLAKE2b-256 |
f0dbb661a1622896f373337a4e95df8c0a2897286ddb7c6215f2ba1c76529ae1
|







